







Adam

通过改变计算顺序,算法1的效率可以提高,将最后三行替换为:
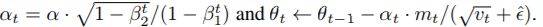
Radma
我们主要的贡献有两方面,我们识别了自适应学习率的方差问题,并给出了warm-up的理论依据。结果表明,收敛性问题是由于模型训练初期自适应学习速率变化过大造成的。另一方面,我们提出了一种新的Adam变体,它不仅显著的修正了方差,而且理论上是健全的,而且比启发式warm-up相比也更好。
我们在图2上观察到,在不进行warm-up的时候,梯度分布被扭曲在10个更新范围内有一个相对较小的质量中心。这种梯度意味着vanilla adam在最初几次更新之后陷入了不好的局部最佳状态。warm-up从根本上减少了这些有问题的更新的影响,以避免收敛问题。


3 VARIANCE OF ADAPTIVE RATE
由于训练早期缺乏样本,自适应学习率存在着不太理想的大方差,从而导致了局部最优。
首先,我们分析一个特殊情况,当t=1时,有:
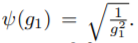
(个人理解,由于初始化为正态分布)我们认为以下梯度为正太分布,

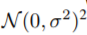
因此,
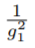 服从 scaled inverse chi-quared distribution,即:
服从 scaled inverse chi-quared distribution,即:
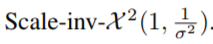
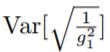
所以上式为发散的,这意味着在学习的第一阶段,自适应率可能会过大,同时,在早期设置较小的学习率可以降低方差:
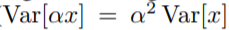
从而缓解了这一问题。因此,我们认为是自适应学习率在早期阶段的无界方差导致了问题的更新。
3.1 WARMUP AS VARIANCE REDUCTION
与其他方法相比,它的迭代是从-1999而不是1开始索引的,在获得这些额外的两千个样本以估计自适应学习速率后,adam-2k避免了adam的收敛问题,此外,比较图2和图3,获得足够大的样本可以防止梯度分布被扭曲。这些观测结果证实了我们的假设,即早期缺乏足够的数据样本是收敛问题的根本原因。我们进一步证明,通过减小自适应学习速率的方差,可以避免收敛问题。
减少方差的简单方法是增加:
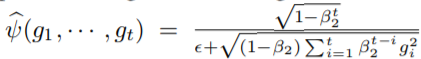
如果我们假设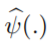 服从均匀分布,它的方差等于
服从均匀分布,它的方差等于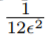
因此,我们设计了Adam-eps,从10e-8变为10e-4,我们观察到它没有受到vanillaAdam的严重收敛问题的影响,这表明通过降低自适应学习速率的方差可以缓解收敛问题,同时也解释了为什么tuning 在实践中是非常重要的。此外,它很像adam-2k,它防止梯度分布被扭曲,但是与adam-2k和adam-warm-up相比,它的性能要差很多,我们推测,这是因为较大的偏差会导致自适应学习速率产生较大的偏差,从而减缓了优化过程。因此,我们需要一种更有原则和更严格的方法来控制自适应学习率的变化。
3.2 ANALYSIS OF ADAPTIVE LEARNING RATE VARIANCE
正如前面提到的,ADAM使用指数平均移动来计算自适应学习率,对于梯度来说,它们的指数移动平均比它们的简单平均具有更大的方差。在早期,梯度的指数weights之间的不同相对较小。
中间略。
结果表明,由于早期缺乏训练样本,早期的Var大于后期的Var。
4 RECTIFIED ADAPTIVE LEARNING RATE
4.1 ESTIMATION OF ρ
4.2 VARIANCE ESTIMATION AND RECTIFICATION
模型对学习率不敏感,鲁棒性很好
















 3005
3005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









