







举个例子
用超级计算机(超算)跑模型代码指南_超算平台如何激活虚拟环境-CSDN博客
先看上面的链接,但是安装mobaxtern比较好用,登录你自己的账号,这些教程比较简单。
然后装好anaconda和配置虚拟环境,上面的链接里也讲了。然后是账号里面文件夹要整齐整洁,文件命名不要中文,服务器无法识别中文。之后就是如何用sbatch提交作业或者saloc直接进入GPU运行作业。我相信,你的所有疑问都能在这篇文章找到答案。
常见的几个linux指令要熟悉:
1.sinfo: 这个命令用于显示当前计算集群中的系统信息和节点状态。它将显示节点的状态、可用资源和负载情况等信息。
2.mkdir: 该命令用于创建一个新的目录。例如,mkdir myfolder 将在当前目录下创建一个名为 "myfolder" 的新目录。
3.mv: 该命令用于移动文件或目录,也可以用于重命名文件或目录。例如,mv file.txt folder/ 将文件 "file.txt" 移动到 "folder" 目录中。
touch: 这个命令用于在指定路径下创建一个空文件。例如,touch /path/to/file.txt 将在 /path/to/ 目录下创建一个名为 "file.txt" 的空文件
echo: 这个命令可以将文本内容输出到文件中,从而创建文件并写入内容。例如,echo "Hello, World!" > /path/to/file.txt 将创建一个名为 "file.txt" 的文件,并将字符串 "Hello, World!" 写入该文件。
mkdir -p /path/to/directory 命令来创建多级目录,并使用 touch /path/to/directory/file.txt 命令来创建文件
4.rm: 该命令用于删除文件。例如,rm file.txt 将删除名为 "file.txt" 的文件。rm-r 是删除文件
5.vi: 这是一个文本编辑器,在终端中使用。您可以使用该命令打开文件并进行编辑。例如,vi myfile.txt 将使用 vi 编辑器打开名为 "myfile.txt" 的文件。
6.ls: 该命令用于列出目录中的文件和子目录。例如,ls 将显示当前目录中的文件和目录列表。
7.ls -a: 这个命令与 ls 类似,但它会显示所有文件,包括隐藏文件。例如,ls -a 将显示当前目录中的所有文件和目录,包括以点 "." 开头的隐藏文件。
8.ls -al: 这个命令与前面的 ls -a 类似,但它以长格式显示文件和目录的详细信息。例如,ls -al 将显示当前目录中的所有文件和目录,并显示它们的权限、所有者、大小等详细信息。
9.:wq: 这是在 vi 编辑器中保存并退出的命令。当您完成对文件的编辑后,可以按 Esc 键,然后输入 :wq 并按 Enter 键,以保存文件并退出 vi 编辑器。编辑时先按i进入编辑。
10.:q: 这是在 vi 编辑器中退出而不保存的命令。如果您对文件的修改不想保存,可以输入 :q 并按 Enter 键,以退出 vi 编辑器。
11.cd: 该命令用于更改当前工作目录。例如,cd myfolder 将切换到名为 "myfolder" 的目录。
12.sbatch: 这个命令用于提交一个批处理作业到集群调度系统。它将根据作业的需求和资源可用性,在集群上启动一个作业。
13.squeue: 这个命令用于显示当前正在运行和等待运行的作业队列。它将列出作业的 ID、状态、运行时间等信息。
14.sacct: 这个命令用于查看作业的账户信息。它可以显示有关作业资源使用情况、运行时间、内存消耗等详细信息。
15.conda list: 这个命令用于显示当前环境中安装的所有 Conda 软件包的列表。
16.conda info -e: 这个命令用于列出当前系统上所有可用的 Conda 环境。它将显示环境的名称、路径和安装日期等信息。
17.conda activate skin: 这个命令用于激活名为 "skin" 的 Conda 环境。一旦激活,该环境中的软件包将优先使用。
18.sed -i 's/\r//' zjfcpu.sh: 这个命令使用 sed 工具来从文件 "zjfcpu.sh" 中删除 Windows 换行符(\r)。这个命令可以处理文件在不同操作系统上的换行符格式问题。
19.pwd: 这个命令用于显示当前工作目录的绝对路径。
20.dos2unix: 这个命令用于将文本文件从 Windows/DOS 格式转换为 Unix/Linux 格式,以解决换行符问题。
21.logout: 这个命令用于退出当前用户的会话。
22.scontrol: 这个命令用于管理 Slurm 调度系统,它提供了对作业、节点和其他资源的控制和查询功能。
23.salloc -p gpu_128G -N 1 -w gpu4: 这个命令用于在 GPU_128G 分区请求一个 GPU 资源,并在 GPU4 节点上启动一个作业。该命令将为作业分配一个节点,并分配相应的资源供作业使用。
24.squeue -u lxtai //产看你正在运行和排队的项目
scontrol show node gpu5
查看节点详情
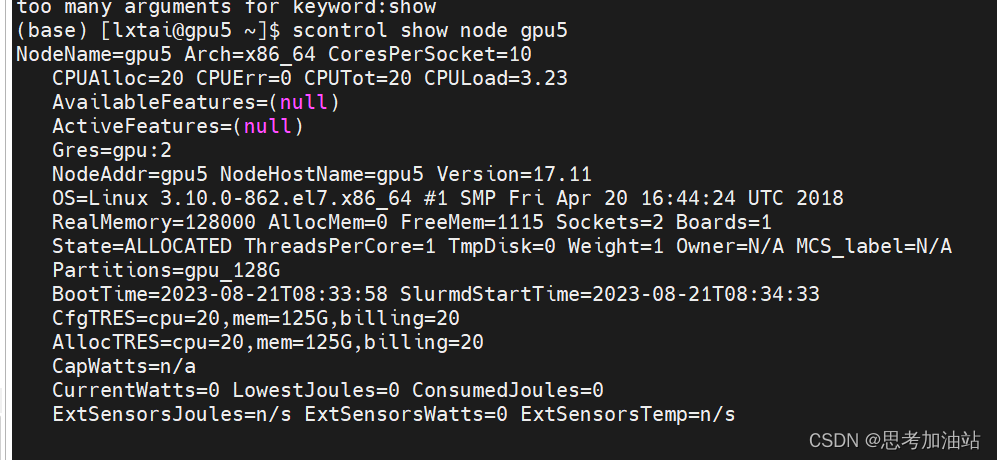
25.要查看 Linux 系统中 GPU 是否被使用,你可以使用以下命令:
1.nvidia-smi: 这是一个用于 NVIDIA GPU 的命令行实用程序。运行 nvidia-smi 命令会显示当前所有 NVIDIA GPU 的状态和使用情况,包括 GPU 型号、驱动版本、显存使用情况以及运行在 GPU 上的进程等信息。
2.lspci: 这个命令用于列出系统中所有 PCI 设备的信息,包括 GPU。你可以运行 lspci | grep -i nvidia 命令来过滤出 NVIDIA GPU 相关的信息。
3.glxinfo: 这个命令用于获取有关 OpenGL 系统和 GPU 的信息。你可以运行 glxinfo | grep "OpenGL renderer" 命令来查看当前使用的 OpenGL 渲染器。
4.top 或 htop: 这些命令用于监视系统资源使用情况。通过运行 top 或 htop 命令,你可以查看 CPU 使用情况、内存使用情况,并找到占用 GPU 资源的进程。
这些命令将提供有关 GPU 状态和使用情况的信息。请注意,这些命令的可用性和输出可能会根据你的系统配置和所使用的 GPU 型号而有所不同。如果你使用的是非 NVIDIA GPU,可能需要相应的命令或工具来查看 GPU 的使用情况。
请注意,这些命令的具体用法可能会因操作系统、软件版本和环境的不同而有所变化。建议在使用这些命令时参考相关文档或使用命令的帮助选项来获取更详细的信息。
然后登录账号只是进入了服务器,只有CPU,没有GPU,GPU的资源需要自己申请。所以得用sbatch提交作业后,排队等待资源。具体怎么提交作业下面讲。
然后我必须将我的项目文件夹(目录)放在我的虚拟环境的目录下(当然)才能执行项目。
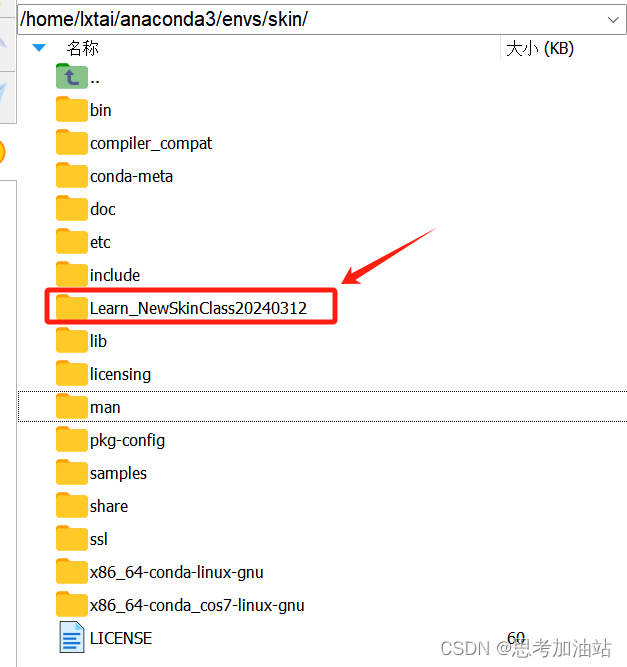
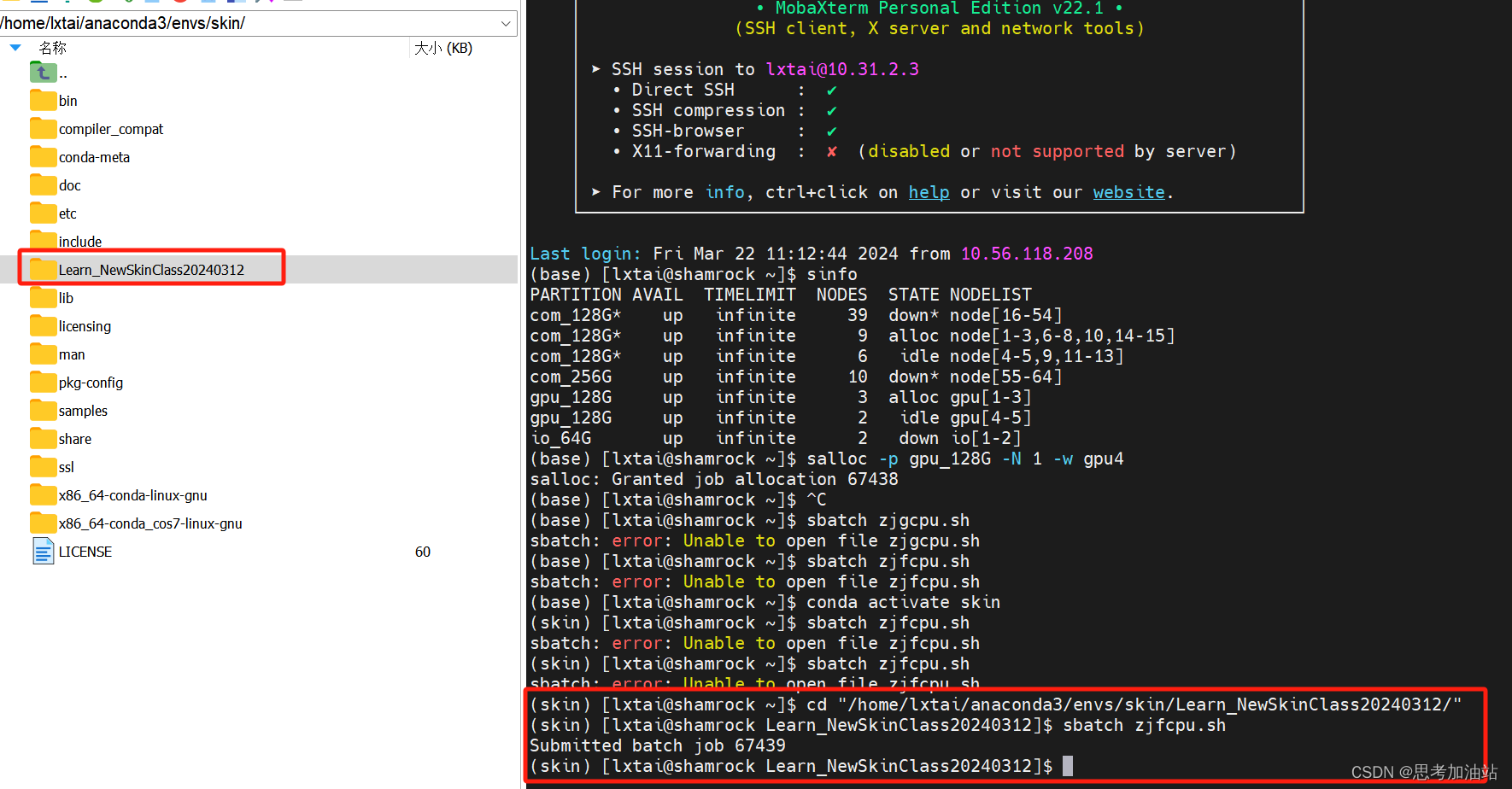
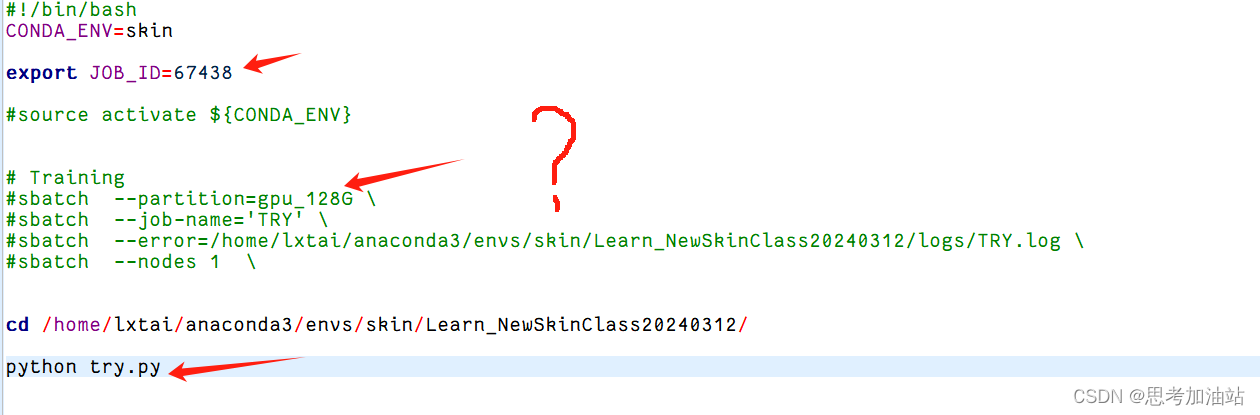
项目文件是"/home/lxtai/anaconda3/envs/skin/Learn_NewSkinClass20240312/try.py"我的虚拟环境的项目文件夹里的trian.py。salloc -p gpu_128G -N 1 -w gpu4然后我请求GPU资源。
这是命令的输出结果,表示分配的作业号为 67438。然后我创建一个zjfcpu.sh的文件,代码如下
#!/bin/bash
CONDA_ENV=skin
#source activate ${CONDA_ENV}
# Training
#sbatch --partition=gpu_128G \
#sbatch --job-name='Train.py' \
#sbatch --error=/home/lxtai/anaconda3/envs/skin/Learn_NewSkinClass20240312/logs/TRY.log \
#sbatch --nodes 1 \
cd /home/lxtai/anaconda3/envs/skin/Learn_NewSkinClass20240312/
python trian.py然后我切换目录到虚拟环境下的项目文件并且激活了虚拟环境后(必须切换),提交作业:sbtach zjfcpu.sh后,得到bacth job是37439。
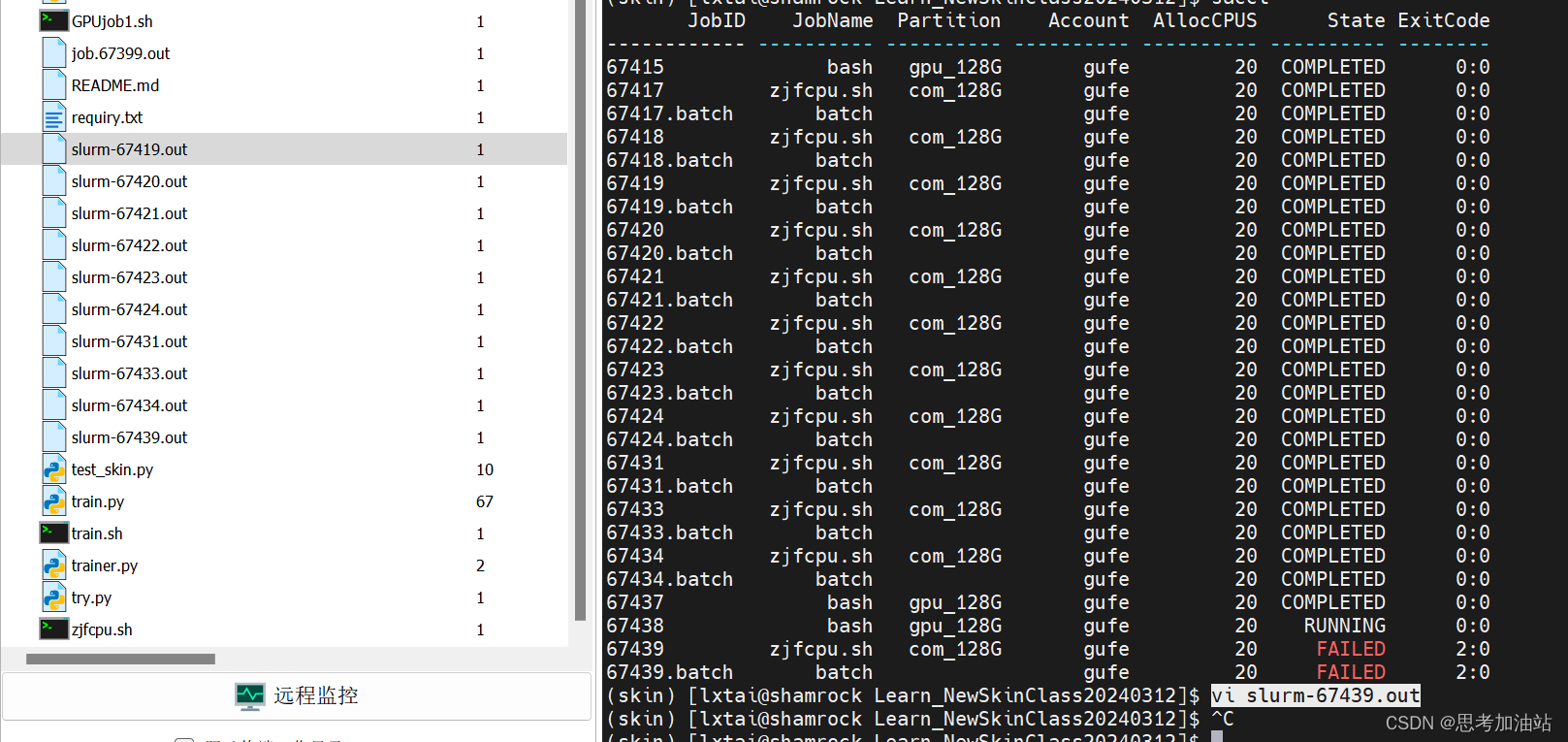
然后,我查看作业状态,用sacct。显示我的作业号66438在运行,66439失败了。
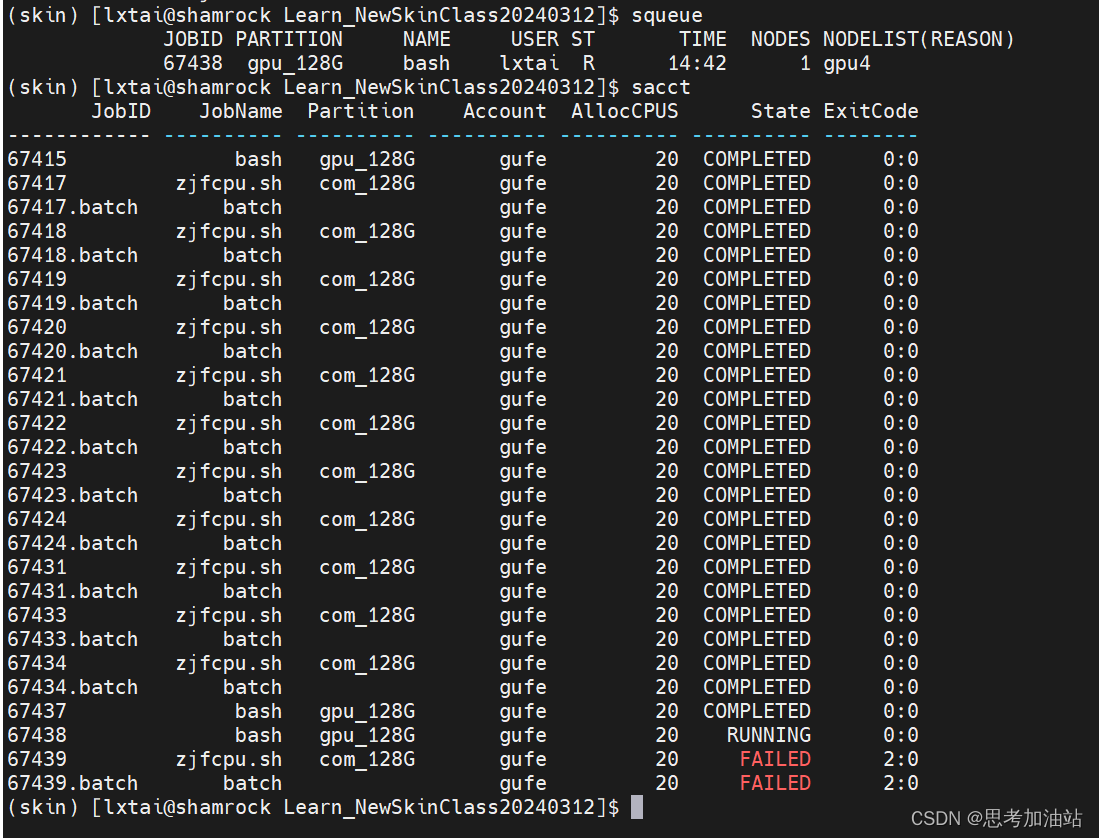
我用vi slurm-67439.out打开67419作业的输出文件。发现是我的文件名弄错了。然后我按下i,然后:q就直接退出文本。
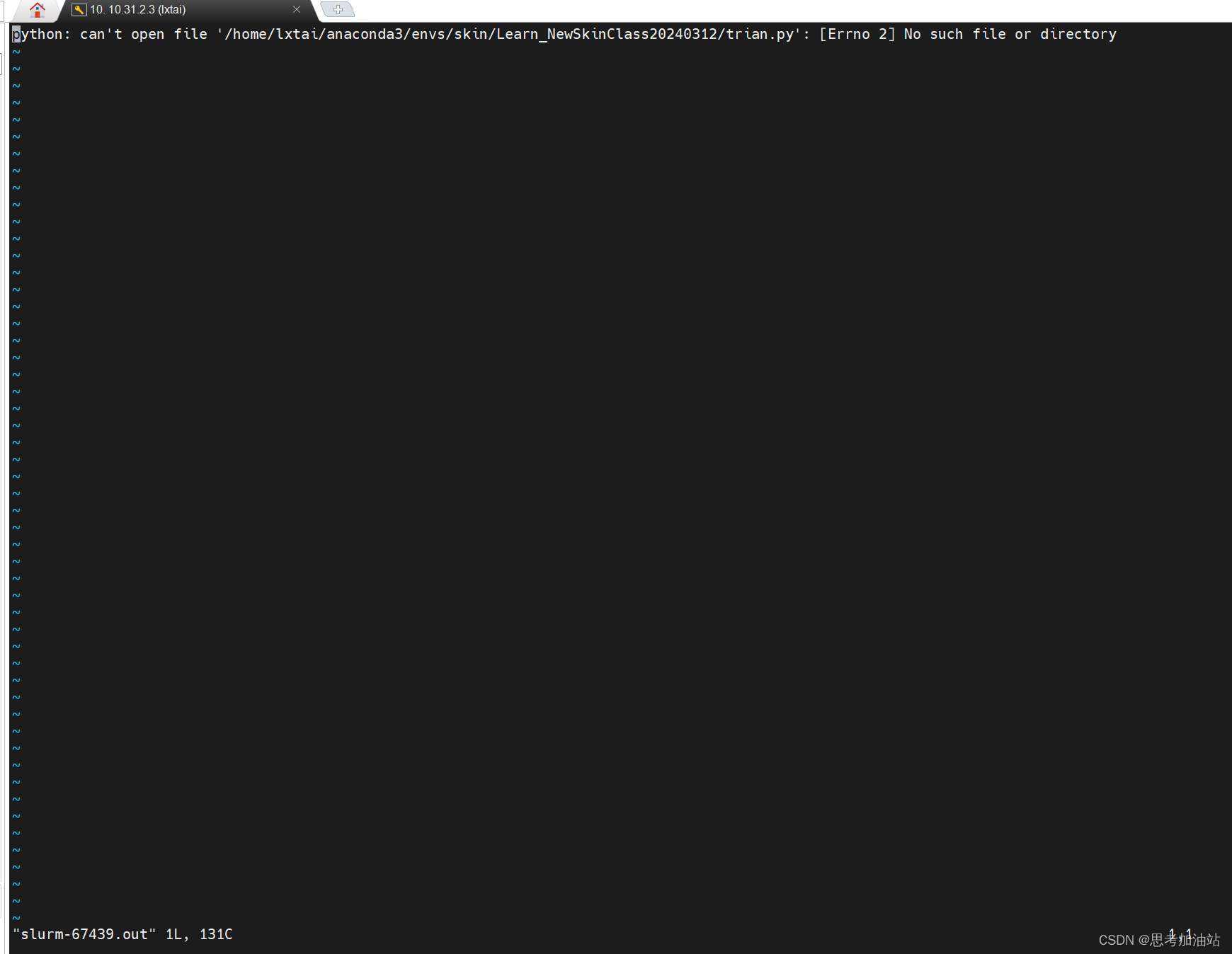
修改保存后。我再次提交作业。显示在运行。但在之后看报错说我没有cuda。

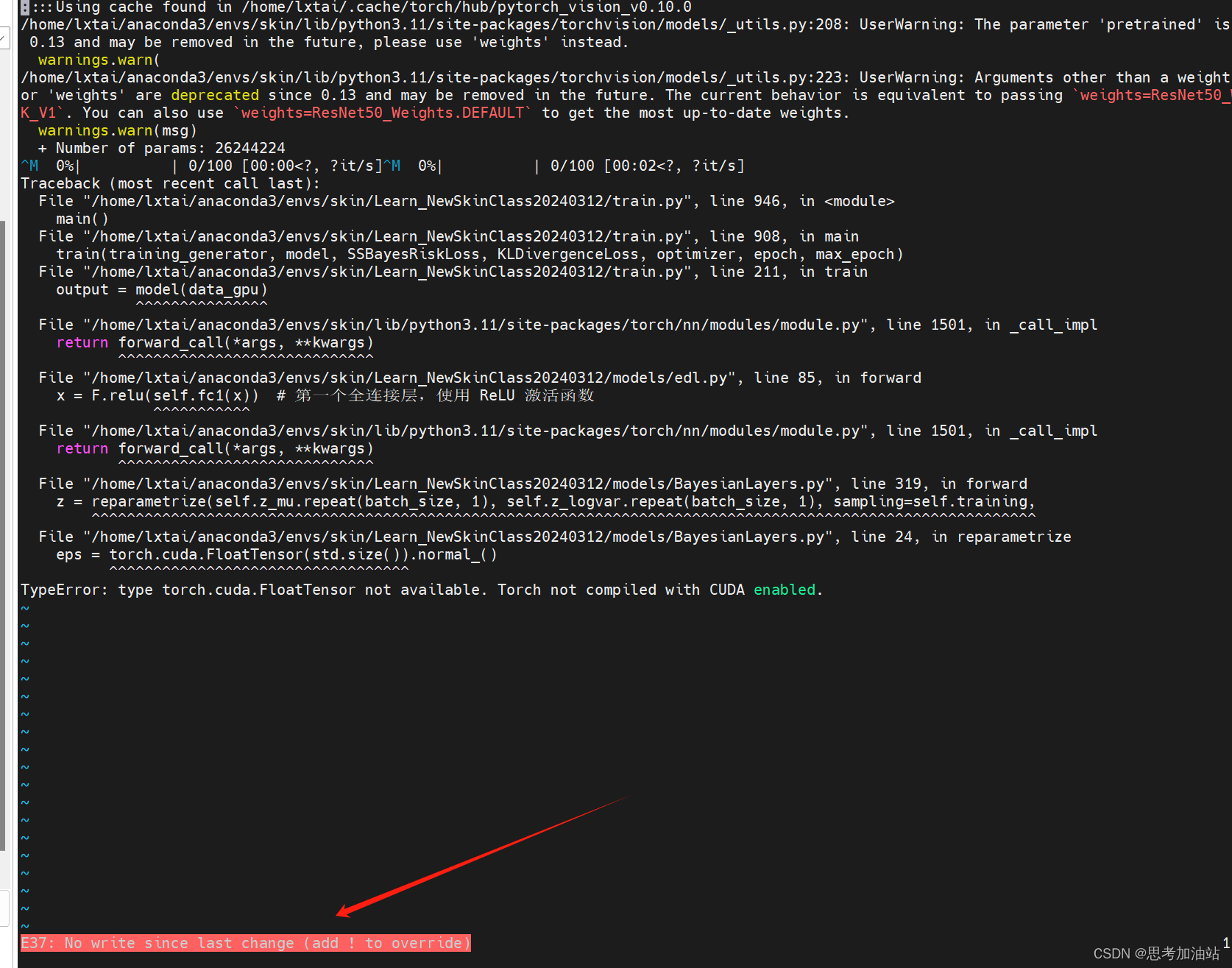
然后我运行一个不需要cuda的try.py文件。而且我按下i后,esc,然后:q显示报错,然后:wq就退出了。行一个不需要cuda的try.py文件没有报错。但是我的.sh脚本就只改了try.py。仔细观察发现刚才的任务都没有用上GPU。都是用的cpu。
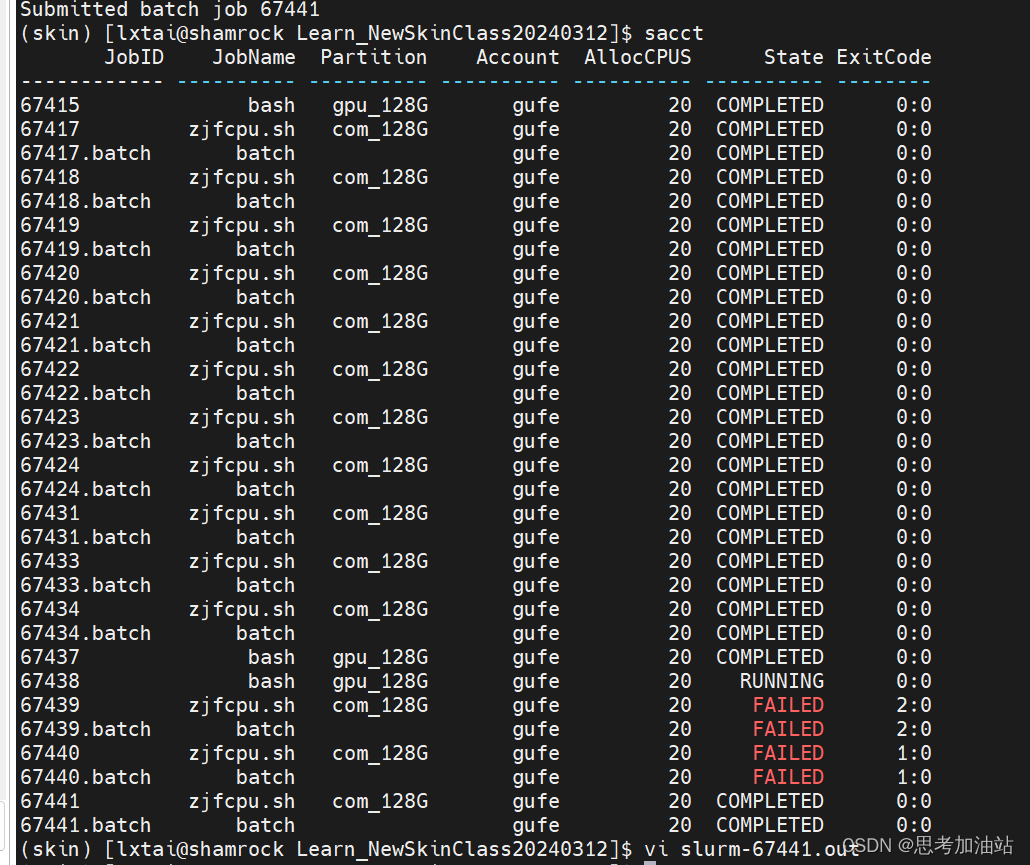
所以怎么才能使用上GPU?然后输入ssh gpu4, nvidia-smi发现cuda=11.6.我的环境是11.8,所以

但是我觉得不是这个问题。我没有用上GPU。这是最主要的。于是我安装cuda,驱动和cudatoolkit
linux系统安装cuda
在Linux系统中安装CUDA通常涉及以下步骤:
-
确认你的NVIDIA显卡支持CUDA。
-
前往NVIDIA官网下载对应你显卡和Linux版本的CUDA Toolkit。
-
安装CUDA Toolkit前,请确保已经安装了NVIDIA驱动。
-
运行CUDA安装脚本,并遵循提示进行安装。
以下是一个基本的安装示例:
# 1. 下载CUDA Toolkit(以CUDA 11.2为例)
wget https://developer.download.nvidia.com/compute/cuda/11.2.0/local_installers/cuda_11.2.0_460.27.04_linux.run
# 2. 给安装文件赋予执行权限
chmod +x cuda_11.2.0_460.27.04_linux.run
# 3. 运行安装程序
sudo ./cuda_11.2.0_460.27.04_linux.run
# 4. 按照提示进行安装,可能需要接受许可协议,选择安装组件等。
安装完成后,你可能需要配置环境变量,以便在任何位置使用CUDA相关工具。你可以通过在你的.bashrc或.zshrc文件中添加以下行来配置环境变量:
export PATH=/usr/local/cuda-11.2/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-11.2/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
然后,你可以通过运行nvcc --version来验证CUDA是否安装成功。
但是运行nvcc --version,不安装也行呀。所以我改了脚本
#!/bin/bash
#SBATCH -o job.%j.out
#SBATCH --partition=gpu_128G
#SBATCH -J myFirstGPUJob
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=6
export=gpu4
CONDA_ENV=skin
#source activate ${CONDA_ENV}
#sbatch --job-name='TRY'
#sbatch --error=/home/lxtai/anaconda3/envs/skin/Learn_NewSkinClass20240312/logs/TRY.log
#sbatch --nodes 1
cd /home/lxtai/anaconda3/envs/skin/Learn_NewSkinClass20240312/
python train.py用上GPU了。
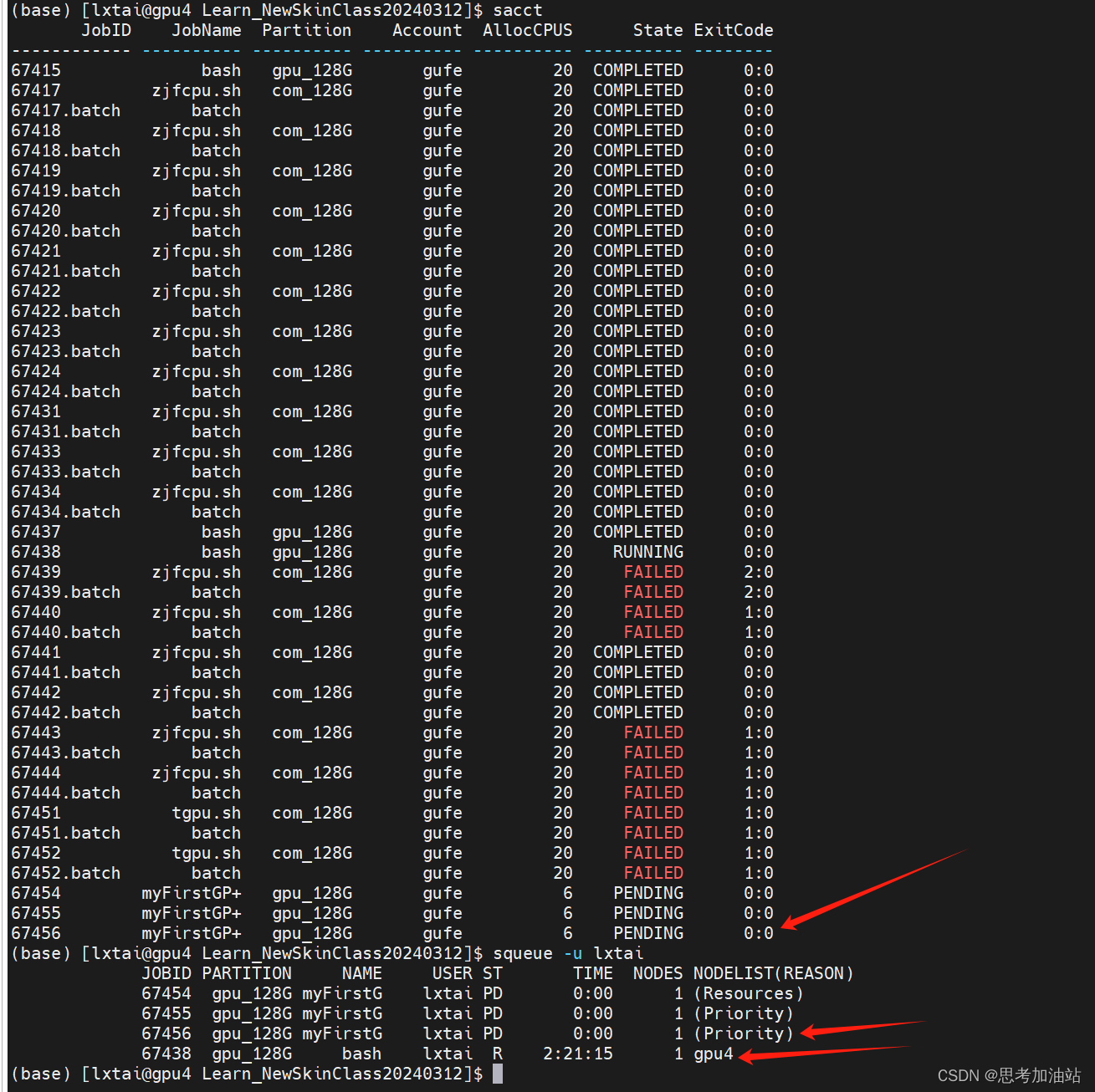
但是我的gpu4不是自己在用么,为什么我自己用不了,还要排队。
#!/bin/bash
#SBATCH -o job.%j.out
#SBATCH --partition=gpu_128G
#SBATCH -J myFirstGPUJob
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
#SBATCH --nodelist=gpu4
CONDA_ENV=skin
#source activate ${CONDA_ENV}
#sbatch --error=/home/lxtai/anaconda3/envs/skin/Learn_NewSkinClass20240312/logs/TRY.log
cd /home/lxtai/anaconda3/envs/skin/Learn_NewSkinClass20240312/
python train.py然后我改了,作业ID是67459.根据
【4.1】sbatch提交作业 · Doc (pku.edu.cn)
然后提交了作业,所以这个sbatch脚本还是得学习。但是我不知道会不会报错说没有,cuda。

但是我的作业有好几个。我用salloc占用了资源为什么还排队。所以我准备取消占用。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









