








内容说明:
- HashSet 去重与保证元素不重复概念的理解
- HashMap 和 ConcurrentHashMap 的简单整理
起因:在总结 HashSet 相关知识点的时候,发现有些内容网上说不通,然后通过 debug + 分析源码,找到自己的理解
前置知识点:
① HashSet 和 HashMap 的关系:
-
HashSet 实现 Set接口,内部含有 HashMap 类型的属性 map
-
添加元素为 add(), 会调用 map.put(),
由于 set 是单元素的,所以会有一个 Object 类型的 PRESENT 属性用来占位
-
没有 get() 方法,可通过 iterator 遍历,本质上是调用 map.keySet().iterator()
② HashSet 如何保证元素不重复?
-
HashSet 添加元素本质是调用 map.putVal(key, PRESENT)
-
若添加相同元素,key 是相同的,。。
如上所示,编到第二条的时候发现编不下去了,按照 HashMap 的逻辑,怎么就 key 相同时不能再添加 key 了,key 相同时不是去更新 value 嘛,更新 value 返回旧值,怎么再次添加时返回 false 了?
1. HashSet 去重
测试案例:主要说明,不要在 Junit 的测试方法中 debug ,不然 D 出来的是啥呀,罢辽,本人无知
public static void main(String[] args) {
HashSet<Integer> hashSet = new HashSet<>();
System.out.println(hashSet.add(1));// true
System.out.println(hashSet.add(1));// true
}
1.2 hashSet.add(var)
注意看:这就是问题所在,按照 hashmap.put(key, value) 的逻辑,key 存在时返回的是 previousValue
首次添加时 value == null 返回 true
再次添加时,由于 PRESENT = new Object 显然不为 null 故而返回 false
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
1.3 去重理解
以下摘自网上普遍说法:
Set调用 add 方法时,调用了添加对象的 hashCode方法和 equals 方法:如果Set集合中没有与该元素 hashCode 值相同的元素,则说明该元素是新元素,可以添加到 Set 集合中;如果两个元素的 hashCode 值相同,再使用 equals 方法比较,如果返回值为 true,就说明两个元素相同,新元素不会被添加到 Set 集合中;如果 hashCode 值相同,但是 equals 方法比较后,返回值为 false ,就说明两个元素不相同,新元素会被添加到 Set 集合中。
好像没错,好像又有点问题,好像说到 set 集合上去了,set 集合确实有这个性质
但从实现类 HashSet 理解,这就有问题了
原因是 HashSet 添加元素本质上是基于 HashMap 实现的
HashMap 有去重一说嘛?没有啊,人家只是key 相同时更新 key, key 不同时解决 hash 冲突
所以,额,我仅仅是给出自己的理解
① HashSet 在 HashMap 的基础上把 key 相等时更新 value 的功能架空了,PRESENT = new Object() 更新啥呀
② 添加相同的 key 时,利用是否存在映射对象 PRESENT 返回添加是否成功
③ 相当于还是走了一遍更新 key 对应的 value 的流程,但返回 null 不是因为调用 hashmap.putVal(…) 而是占位符 PRESENT != null
2. HashMap
2.1 数据结构
JDK 1.7 数组 + 链表:采用头插法
JDK 1.8 数组 + 链表/红黑树:采用尾插法
API 角度:put() 哈希冲突, get(), resize() 扩容机制
2.2 put()
HashMap put() 方法的执行过程:若数组为空或者长度为 0 则先扩容
- 计算 key 的 hash 值,根据 hash 值确认在 table 中存储的位置 tab[(n - 1) & hash]
- 若该位置没有元素则直接插入
- 该位置有元素,判断是否为更新键值,若两元素的 hash 值相等且 key 相等则为更新键值
- 否则判断是否为树节点,若为树节点则转化为树节点则执行 putTreeVal() 操作
- 若不是树节点也不是更新操作,则为哈希冲突,遍历当前链表找到空闲位置插入
- 插入后判断是否需要树化【树化的条件:链表长度大于 8 ,且数组长度大于 64】
2.3 get()
- get() 方法会调用 getNode() 方法,参数值为节点的 hash 和 key
- 若桶非空,则定位该节点在桶内的位置 tab[(n - 1) & hash]
- 判断桶上的元素是否为待查找的节点,若是则直接返回
- 否则若桶上的链表非空,则先判断是否为树节点,若为树节点则调用 getTreeNode() 否则遍历链表
2.4 resize()
-
获取从旧的数组容量和阈值 oldCap, oldThr 若数组为空则旧容量为 0
-
若旧容量大于最大值 2^30,则仅将阈值更新为 2^32 ,并返回旧数组【数组元素为Node】
-
否则若旧容量扩容2倍后的值小于最大值 2^30,且旧容量大于 16,则将新阈值设置为旧阈值的 2 倍
即当旧容量大于 16 且扩容后值小于最大值时,分别将旧阈值和旧容量扩容为 2 倍
-
若旧容量为 0 若旧阈值大于 0,则设置新容量为旧阈值
-
若旧容量和旧阈值均为 0,则设置新容量为默认初始值 16,新阈值为默认装载因子 * 默认初始值
-
若新阈值为 0,即第 4 步中的旧容量为 0 而旧阈值大于 0 的情况,设置新阈值为 新容量*装载因子或最大值
-
若旧数组非空,则迁移旧数组指定位置上的链表到新数组,若新元素hash 与旧容量相与后的结果为 0 则放到新数组的低位,否则迁移到新数组的高位【与之对应的扩容后数组的高位部分】这也是二次幂的优点,扩容后链表节点要么在原位置要么在 2 倍的位置处。只需要看增加的那位是否为1,即可判断是否在原位置上还是2倍位置上。优点是:省去了重新计算 hash 值的时间
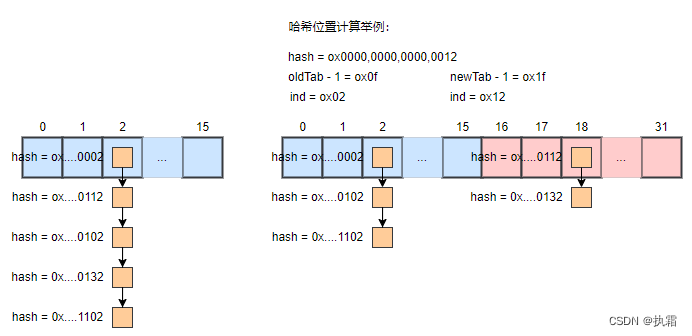
补充:hashmap 的 size 为何必须为 2 倍?① 桶位置计算的时候:通过 hash & (n - 1) 计算桶的位置,位运算性能较优
② 扩容时,根据 扩容后的高位值 hash & oldcap 【注意此处没有oldcap全0,仅高位为1】若高位为1 则扩容到数组的新位置上
2.5 与其他类的对比
① Hashtable
- Hashtable 的很多功能都与 HashMap 类似,不同的是它继承自 Dictionary 类,且线程安全
- Hashtable 在不需要线程安全的场合可由 hashmap 替代,线程安全场合可由 concurrentHashmap 替代
② LinkedHashMap
保存了记录的插入顺序,使用 Iterator 遍历时,得到的是先插入的,可以在构造参数中带参数按访问次序排序
③ TreeMap
实现 SortedMap 接口,能把保存的记录根据键排序,默认按键值升序排序
其他问题:
① HashMap 的 get 方法能否判断某个元素是否在 map 中?
不能,因 HashMap 允许存放 null 值,若存储 null,则返回 null,而 get 未找到元素时也会返回 null
② Hashtable 能否存放 null 值?
Hashtable 既不允许 key == null, 也不允许 value == null
但仅判断了 value == null的情况,value == null的时候抛出异常
原因是:key.hashCode() 会抛出异常,异常来源于 InvocationTargetException
③ Hashtable 和 HashMap 的关系?
Hashtable 继承 Dictionary 实现了 Map,没啥关系,只是功能类似,hashtable 基于数组 + 链表,hash 映射的方式也不同,hashtable 中的 put 和 get 方法并没有重用 hashmap 的,而是根据自身的数据结构
3. ConcurrentHashMap
3.1 数据结构
-
JDK 7 数据结构:segment数组 + hashtable 结构【数组 + 链表】 其中 segment 通过继承 ReentrantLock 来进行加锁
ConcurrentHashMap 包含 16 个 segments ,最多支持 16 个线程并发写
put 的基本思路:
- 通过hash值计算带存放的 segment 的位置
- 执行 segment 内部的 put 操作,先获取锁,再执行添加操作
-
JDK 8 数据结构:HashMap 1.8 结构:数组 + 链表 + 红黑树,加锁采用 CAS + Synchronized
3.2 put() 函数
调用 putVal(…) 方法
- concurrentHashMap 不允许 key, value 为 null
- 检查 key,value 是否为 null, 为 null 则抛出 NullPointerException 异常
- 计算 hash 值
- 若 table 未初始化或为空,则先初始化 table
- 若根据 hash 值计算出 table 位置上的元素为空,则通过 CAS 方式在该位置上添加新节点
- 若当前 table 位置非空,且处于扩容【移动】状态【hash = -1】,则调用 helpTransfer 帮助数据迁移
- 若当前 table 位置非空,则以当前位置上的链表首节点为锁对象通过 synchronized 关键字加锁
- 若当前位置头节点 hash > 0 说明为链表,采取和hashmap相同的遍历链表若找到相同 hash 和 key 的节点则替换旧元素,否则包装成新节点插入链表末尾
- 若当前位置头节点 hash <= 0, 说明为红黑树,调用 putTreeVal 的方法插入新树节点
- 插入新节点后,判断是否要将链表转换为红黑树
3.3 initTable() 初始化数组
- 若已有线程在执行初始化,则调用 Thread.yield() 让出 CPU 执行权
- 否则通过 CAS 设置 sizeCtl = -1 表示获取到锁
- 若 tab 未初始化或为空,则初始化为默认长度 16, 设置 sizeCtl【阈值】 为 0.75 * 当前容量
④ 扩容操作和数据迁移:sizeCtl 的概念还不是很确定,有时间把代码看一下
sizeCtl : 用于 table 初始化 和 扩容控制
RESIZE_STAMP_BITS : 用于生成 sizeCtl 的bit戳















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









