










 本文深入探讨了JavaSE进阶知识,包括final关键字的使用、抽象类与接口的区别、多态的实现、数组操作及常用算法概述。详细解析了final变量、方法、类的特性,抽象类与接口的定义与应用场景,以及如何利用数组进行数据存储与遍历,还介绍了冒泡排序等算法的基本思想。
本文深入探讨了JavaSE进阶知识,包括final关键字的使用、抽象类与接口的区别、多态的实现、数组操作及常用算法概述。详细解析了final变量、方法、类的特性,抽象类与接口的定义与应用场景,以及如何利用数组进行数据存储与遍历,还介绍了冒泡排序等算法的基本思想。
JavaSE进阶
第一篇文章的连接: (超详细笔记整理)动力节点_老杜 | JavaSE零基础 :P329(方法) - P479.
文章目录
- JavaSE进阶
- final关键字
- 抽象类和接口以及抽象类和接口的区别
- 接口
- 接口的基础语法
- 1、接口是一种“引用数据类型”。
- 2、接口是完全抽象的。
- 3、接口怎么定义:[修饰符列表] interface 接口名{}
- 4、接口支持多继承。
- 5、接口中只有常量+抽象方法。
- 6、接口中所有的元素都是public修饰的
- 7、接口中抽象方法的public abstract可以省略。
- 8、接口中常量的public static final可以省略。
- 9、接口中方法不能有方法体。
- 10.类和类之间叫做继承,类和接口之间叫做实现,仍然可以将实现看作继承,继承使用extends,实现使用implements
- 11.当一个非抽象的类实现接口的话,必须将接口中所有的抽象方法全部实现。
- 12.一个类可以实现多个接口
- 13.继承和实现都存在的话:extends关键字在前,implements关键字在后。
- 14.使用接口,写代码的时候,可以使用多态(父类型引用指向子类型对象)。
- 接口在开发中的作用
- is a 、has a、like a
- 抽象类和接口有什么区别?
- package 和 import
- 访问控制权限
- JDK类库的根类:Object
- Object类中常用的方法
- 内部类
- 数组
- 常用类
- 异常类
- 集合
- I/O流
- 多线程
- 反射机制
final关键字
1. final是Java语言中的关键字
2. final表示最终的,不可变的
3. final可以修饰变量以及方法还有类等
4. final修饰的变量
5. final修饰的局部变量无法重新赋值,final修饰的变量只能赋一次值
6. final修饰的方法
final修饰的方法无法覆盖
7. final修饰的类
final修饰的类无法继承
package Final;
/*
final
1. final是Java语言中的关键字
2. final表示最终的,不可变的
3. final可以修饰变量以及方法还有类等
4. final修饰的变量
final修饰的局部变量无法重新赋值,final修饰的变量只能赋一次值
5. final修饰的方法
final修饰的方法无法覆盖
6. final修饰的类
final修饰的类无法继承
*/
public class Test01 {
public static void main(String[] args){
//局部变量
int i = 100;
i = 200;
/*
final int k = 100;
k = 0;
*/
}
}
//继承
//如果你不希望别人对A类进行扩展,那么可以给A类加上final
final class A{
}
/*
final修饰的类无法继承
class B extends A{
}*/
//方法覆盖
class C{
public final void doSome(){
System.out.println("C");
}
}
class D extends C{
//无法被覆盖
/*public void doSome(){
System.out.println("D");
}*/
}
8. final修饰的引用
该引用只能指向一个对象,并且它只能永远指向该对象。无法再指向其他对象。并且再该方法执行过程中,该引用指向对象之后,该对象不会被垃圾回收器接收直到当前方法结束,才会释放空间。虽然final的引用指向对象A后,不能再重新指向对象B,但是对象内部的值可以修改
package Final;
/*
final修饰的变量,如果fianl修饰的变量是一个”引用“怎么办?
final修饰的引用:
该引用只能指向一个对象,并且它只能永远指向该对象。无法再指向其他对象。
并且再该方法执行过程中,该引用指向对象之后,该对象不会被垃圾回收器接收
直到当前方法结束,才会释放空间
虽然final的引用指向对象A后,不能再重新指向对象B,但是对象内部的值可以修改
*/
public class Test02 {
public static void main(String[] args){
P p = new P(20);
System.out.println(p.age);
//-------------------------------------
final P p1 = new P(30);
System.out.println(p.age);
p.age = 60;
System.out.println(p.age);
//p1 = new P(); 不可以重新new
}
}
class P{
int age;
public P() {
}
public P(int age) {
this.age = age;
}
}
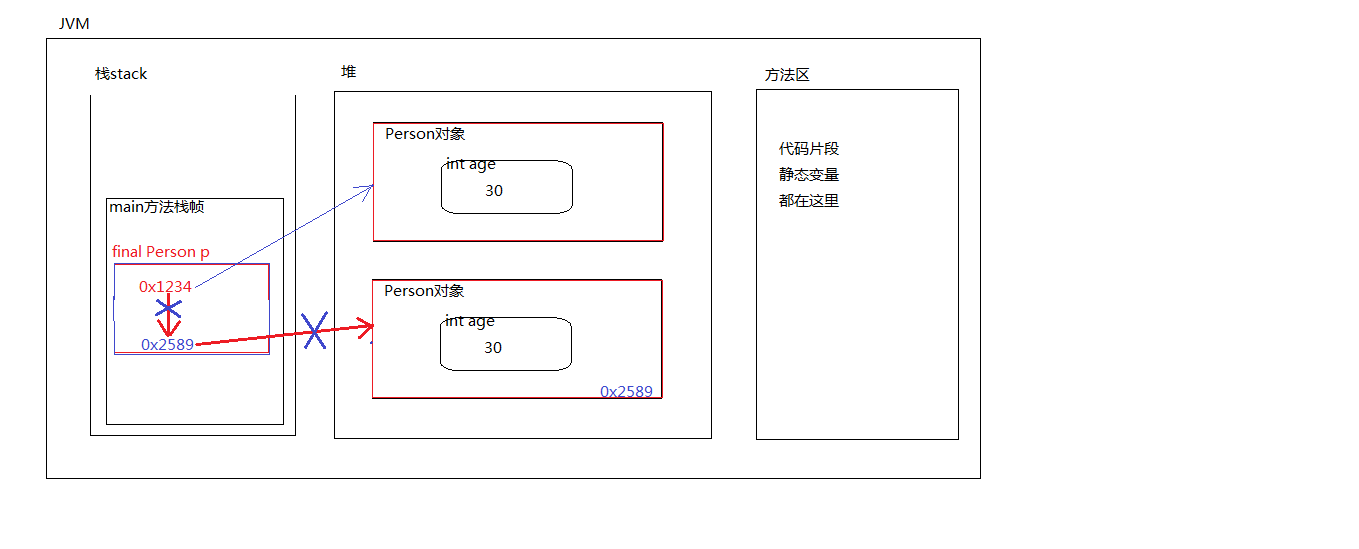
9. final修饰的实例变量
final修饰的变量只能赋值一次
fianl修饰的实例变量,系统不管赋默认值,要求程序员必须手动赋值。这个手动复制,在变量后面直接赋值或者在构造方法中进行赋值也可以。
实例变量在什么时候赋值?
在构造方法执行中进行赋值,(new的时候)
package Final;
/*
final修饰的实例变量
final修饰的变量只能赋值一次
fianl修饰的实例变量,系统不管赋默认值,要求程序员必须手动赋值
这个手动复制,在变量后面直接赋值或者在构造方法中进行赋值也可以。
实例变量在什么时候赋值?
在构造方法执行中进行赋值,(new的时候)
*/
public class Test03 {
public static void main(String[] args){
}
}
class User{
//不可以这么修饰变量 final int i;
//手动赋值可以
final int age = 1;
//以下代码需要组合使用 weight只赋值一次
final double weight;
/*public User(){
weight = 80;//赶在系统赋默认值之前赋值就行
}*/
//这样也可以
public User(double D){
this.weight = D;
}
}
10. final和static联合修饰的变量-常量(每个单词都大写)
结论:
static final 联合修饰的变量称为“常量”。
每一个单词建议使用大写,每个单词之间使用下划线链接
实际上常量和静态变量医用,区别在于:常量值不能变
常量和静态变量,都是存储在方法区,并且都是在类加载时初始化。
常量一般都是公开的,因为公开也不可以改变
package Final;
/*
final修饰的变量一边添加在static修饰
结论:
static final 联合修饰的变量称为“常量”。
每一个单词建议使用大写,每个单词之间使用下划线链接
实际上常量和静态变量医用,区别在于:常量值不能变
常量和静态变量,都是存储在方法区,并且都是在类加载时初始化。
*/
public class Test04 {
public static void main(String[] args){
System.out.println(Chiness.COUNTRY);
}
}
class Chiness{
String idCard;
String name;
String birth;
//实例变量,在堆中,
//实例变量被final修饰了,说明该实例变量的值不会随着对象的变量而变化
//final修饰的实例变量,一般添加static修饰。
//即使是不会发生改变,最好声明为静态的,节省内存空间
final static String COUNTRY = "China"; //类级别
}
class MyMath{
//常量一般都是公开的
public static final double PI = 3.1415926;
}
总结
1.1、final修饰的类无法继承。
1.2、final修饰的方法无法覆盖。
1.3、final修饰的变量只能赋一次值。
1.4、final修饰的引用一旦指向某个对象,则不能再重新指向其它对象,但该引用指向的对象内部的数据是可以修改的。
1.5、final修饰的实例变量必须手动初始化,不能采用系统默认值。
1.6、final修饰的实例变量一般和static联合使用,称为常量。
public static final double PI = 3.1415926;
抽象类和接口以及抽象类和接口的区别
抽象类的理解
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YVk85nKx-1634041323675)(C:/Users/77/Downloads/Documents/09-JavaSE进阶每章课堂画图/01-面向对象/001-抽象类的理解.png)]
1. 什么是抽象类?
类和类之间具有共同特征,将这些类的共同特征提取出来,形成的就是抽象类
类本身是不存在,所以抽象类无法创建对象
2. 抽象类属于什么类型?
抽象类也属于引用数据类型
3. 抽象类怎么定义?
语法:
[修饰符列表] abstract class 类名{
类体;
}
4. 抽象类是无法实例化的,是无法创建对象的,所以抽象类是用来被子类继承的
5. final和abstract是不可以联合使用的
这两个关键字是对立的
6. 抽象类的子类也可以是抽象类
7. 抽象类虽然无法实例化,但是抽象类有构造方法,这个构造方法是供子类使用的。
8.抽象类关联到一个概念,抽象方法的概念
抽象方法表示没有实现的方法,没有方法体的方法。
pubilic abstract void doSome();
抽象方法的特点:
1.没有方法体,以分号结尾;
2.前面修饰符列表中有abstract关键字
9.抽象类中不一定有抽象方法,抽象方法必须在抽象类中
package Abstract;
/*
抽象类:
1.什么是抽象类?
类和类之间具有共同特征,将这些类的共同特征提取出来,形成的就是抽象类
类本身是不存在,所以抽象类无法创建对象
2.抽象类属于什么类型?
抽象类也属于引用数据类型
3.抽象类怎么定义?
语法:
[修饰符列表] abstract class 类名{
类体;
}
4.抽象类是无法实例化的,是无法创建对象的,所以抽象类是用来被子类继承的
5.final和abstract是不可以联合使用的
6.抽象类的子类也可以是抽象类
7.抽象类虽然无法实例化,但是抽象类有构造方法,这个构造方法是供子类使用的。
8.抽象类关联到一个概念,抽象方法的概念
抽象方法表示没有实现的方法,没有方法体的方法
pubilic abstract void doSome();
抽象方法的特点:
1.没有方法体,以分号结尾;
2.前面修饰符列表中有abstract关键字
9.抽象类中不一定有抽象方法,抽象方法必须在抽象类中
*/
public class Test01 {
public static void main(String[] args){
//无法实例化,不可以创建对象
//Account account = new Account();
}
}
//final和abstract是不可以联合使用的
/*final abstract class Account{
}*/
abstract class Account{
public Account(String s){
}
//不可以不写
public Account(){
}
abstract public void A();
}
//子类继承抽象类,子类可以实例化对象
/*class CreditAccount extends Account{
}*/
//抽象类的子类可以是抽象类
//构造方法里默认有一个无参构造
//无参构造的第一行为super,super调用父类的无参构造,如果父类没有无参构造(直接提供了一个有参构造,默认没有无参构造),那么会报错
abstract class CreditAccount extends Account{
}
//抽象方法必须在抽象方法中
/*
class B{
abstract public void A();
}*/
10.抽象方法怎么定义?
public abstract void doSome();
11.(五颗星):一个非抽象的类,继承抽象类,必须将抽象类中的抽象方法进行覆盖/重写/实现。
package Abstract;
/*
抽象类:
1.抽象类不一定有抽象方法,抽象方法必须出现在抽象类中
2.重要结论:一个非抽象的类继承抽象类,必须将抽象类中的抽象方法进行实现
这里的覆盖或者说重写,也可以叫做实现
*/
public class Test02 {
//父类型为抽象类,子类型为非抽象类,这里是否可以使用多态
//面向抽象编程
//a的类型Animal,Animal是抽象的,以后调用的都是a.××
// 面向抽象编程,不要面向具体变成,降低程序的耦合度,提高程序的扩展能力
//这种编程思想符合OCP原则
public static void main(String[] args){//对代码不是很理解的时候,能用多态就用多态
Animal a = new Brid(); //向下转型
a.move();
}
}
//抽象类
abstract class Animal{
public abstract void move();//抽象方法
}
//子类非抽象类
//子类继承父类,父类中有抽象方法,那么子类一定会是抽象类
class Brid extends Animal{
//需要将从父类继承过来的方法进行覆盖/重写,或者也可以叫做“实现”
//把抽象方法实现了
public void move(){
System.out.println("move");
};
}
面试题(判断题):java语言中凡是没有方法体的方法都是抽象方法。
不对,错误的。
Object类中就有很多方法都没有方法体,都是以“;”结尾的,但他们
都不是抽象方法,例如:
public native int hashCode();
这个方法底层调用了C++写的动态链接库程序。
前面修饰符列表中没有:abstract。有一个native。表示调用JVM本地程序。
接口
接口的基础语法
1、接口是一种“引用数据类型”。
2、接口是完全抽象的。
3、接口怎么定义:[修饰符列表] interface 接口名{}
4、接口支持多继承。
5、接口中只有常量+抽象方法。
6、接口中所有的元素都是public修饰的
7、接口中抽象方法的public abstract可以省略。
8、接口中常量的public static final可以省略。
9、接口中方法不能有方法体。
package Interface;
/*
接口:
1.也是一种引用数据类型,编译之后也是class字节码文件
2.接口是完全抽象的。(抽象类是半抽象的),或者也可以说接口是特殊的抽象类
3.接口是怎么定定义,语法是什么?
[修饰符列表] interface 接口名(
)
定义类 [修饰符列表] class 类名{}
定义抽象类 [修饰符列表] abstract class 类名{}
4.接口支持多继承,一个接口可以继承多个接口
5.接口中只包含两部分内容,一部分是常量,一部分是抽象方法,接口中没有其他内容
6.接口中所有的元素都是public修饰的,接口中所有的东西都是公开的
7.接口中的抽象方法,public abstra 是可以省略的
8.接口中的方法都是抽象方法,接口中的方法不能有方法体。
10.接口中常量的public static final 可以省略
*/
public class Test01 {
public static void main(String[] args){
// 接口中随便写一个变量就是常量
System.out.println( MyMath.PI);
}
}
interface A {
}
interface B{
}
//接口支持多继承
interface C extends A,B{
}
interface MyMath{
//常量
public static final double PI = 3.14;
//可以省略public static final
double K = 3.1;
// public abstract int sum(int a, int b);//抽象方法
//接口当中都是抽象发放,那么在编写代码的时候,public static'可以省略么?
int sum(int a, int b);
//接口中的方法可以有方法体么?
//错误:抽象方法不可以带有主体
/*void doSome(){
}*/
//sub方法
int sub(int a,int b);
}
10.类和类之间叫做继承,类和接口之间叫做实现,仍然可以将实现看作继承,继承使用extends,实现使用implements
11.当一个非抽象的类实现接口的话,必须将接口中所有的抽象方法全部实现。
package Interface;
/*
接口:
1.类和类之间叫做继承,类和接口之间叫做实现,仍然可以将实现看作继承,继承使用extends,实现使用implements
2.当一个非抽象的类实现接口的话,必须将接口中所有的抽象方法全部实现。
*/
public class Test02 {
public static void main(String[] args){
//接口使用多态
MyMath2 mm = new Ab();
System.out.println(mm.PI);
int re = mm.sub(4,3);
System.out.println(re);
}
}
interface MyMath2{
public static final double PI = 3.14;
int sum(int a, int b);
int sub(int a,int b);
}
//编写一个类(这个类是非抽象类)
//需要重写方法,因为Ab不是抽象类
class Ab implements MyMath2{
//实现接口中的方法
public int sum(int a, int b){
return a+b;
};
public int sub(int a, int b){
return a-b;
};
}
//抽象类实现,可以编译通过
abstract class Ac implements MyMath2{
}
12.一个类可以实现多个接口
接口和接口之间虽然后没有继承关系,但是可以强制转换,但是运行时可能会出现ClassCastException异常,需要于类和类之间的强制转换一样,加上instanceof判断。
package Interface;
/*
一个类可以同时实现多个接口
java中的类和类之间只允许单继承,实际上单继承是为了简单出现的
很多情况下会存在多继承,接口弥补了这个缺陷
接口A和接口B虽然没有继承关系,但是可以互相强制转换,但是运行时可能出现ClassCastException异常
无论是向下转型还是向上转向,都必须要有继承关系
没有继承关系,编译器会报错(接口不会)
都需要加上instanceof进行判断,转型之前先进行判断。
*/
public class Test03 {
public static void main(String[] args){
//多态
AA a = new D();
BB b = new D();
//向下转型
BB b1 = (BB)a;
b1.m2();
//向下转型直接转成D
D d = (D) a;
d.m2();
M m = new E();
//经过测试,接口和接口郑伊健在进行强制类型转换的时候,没有继承关系,也可以强转
//但是运行时可能会出现ClassCastException异常,编译没问题,运行有问题
if(m instanceof K)
{
K k = (K)m;
}
}
}
interface M{
}
interface K{
}
class E implements M,K{
}
interface AA{
void m1();
}
interface BB{
void m2();
}
interface CC{
void m3();
}
//类和接口之间可以进行多实现
//需要对接口中的类进行重写
//类似于多继承
class D implements AA,BB,CC{
//实现A接口的m1
public void m1(){};
public void m2(){};
public void m3(){};
}
13.继承和实现都存在的话:extends关键字在前,implements关键字在后。
package Interface;
/*
继承和实现都存在的话:extends关键字在前,implements关键字在后。
*/
public class Test04 {
public static void main(String[] args){
//创建对象
Flyable f = new Cats();//多态
f.fly();
Flyable f1 = new fish();
f1.fly();
}
}
class Animal{
}
interface Flyable{
void fly();
}
class Cats extends Animal implements Flyable{
@Override
//重写接口的抽象方法
public void fly() {
System.out.println("飞猫");
}
}
//没有实现接口
class Snake extends Animal{
}
class fish extends Animal implements Flyable{
public void fly() {
System.out.println("飞🐟");
}
}
14.使用接口,写代码的时候,可以使用多态(父类型引用指向子类型对象)。
接口在开发中的作用
接口在开发中的作用,类似于多态在开发中的作用。
多态:面向抽象编程,不要面向具体编程,提高程序的扩展力,降低程序的耦合度。
/*
public class Master{
public void feed(Dog d){}
public void feed(Cat c){}
//假设又要养其它的宠物,那么这个时候需要再加1个方法。(需要修改代码了)
//这样扩展力太差了,违背了OCP原则(对扩展开放,对修改关闭。)
}
*/
public class Master{
public void feed(Animal a){
// 面向Animal父类编程,父类是比子类更抽象的。
//所以我们叫做面向抽象编程,不要面向具体编程。
//这样程序的扩展力就强。
}
}
接口在开发中的作用:
接口是完全抽象的,以后面向抽象编程可以改为:面向接口编程
有了接口,就代表扩展里很强,这是高扩展性,低耦合度。
接口在现实世界中是不是到处都是呢?
螺栓和螺母之间有接口
灯泡和灯口之间有接口
笔记本电脑和键盘之间有接口(usb接口,usb接口是不是某个计算机协会制定的协议/规范。)
接口有什么用?扩展性好。可插拔。
接口是一个抽象的概念。
总结:面向接口编程,可以降低程序的耦合度,提高程序的扩展力。符合OCP开发原则。
接口的使用离不开多态机制。(接口+多态才可以达到降低耦合度。)
接口可以解耦合,解开的是谁和谁的耦合!!!
任何一个接口都有调用者和实现者。
接口可以将调用者和实现者解耦合。
调用者面向接口调用。
实现者面向接口编写实现。
以后进行大项目的开发,一般都是将项目分离成一个模块一个模块的,
模块和模块之间采用接口衔接。降低耦合度。
is a 、has a、like a
is a:
Cat is a animal
凡是能满足is a 都是表示“继承关系”
has a:
Student has a pen
凡是能够满足has a 都表示“关联关系”,关联关系通常以“属性”的形式存在
A{
B b;
}
like a:
Cooker like a menu
凡是满足like a 表示”实现关系“,实现关系通常是:类实现接口
A implements B
抽象类和接口有什么区别?
抽象类是半抽象的,接口是完全抽象的;
抽象类有构造方法,接口中没有构造方法;
接口和接口支持多继承,抽象类之间只能单继承;
一个类可以同时实现接口,一个抽象类只能继承一个类;
接口中只允许出现在常量和抽象方法;
以后接口使用的比抽象类多。一般抽象类使用的还是少。
接口一般都是对“行为”的抽象。
package 和 import
package
1. package是Java中的包机制,包机制的作用是为了方便程序的关系
不同功能的类分别存放在不同的包下。(按照功能的划分,不同的软件包具有不同的功能。)
2. package是一个关键字。例如:
package demo.src.packageandimport;package语句只允许出现在源代码的第一行
3. 包名的命名规范:一般都采用公司域名倒序的方式(公司的域名具有全球唯一性)
包名的命名规范:
公司域名倒序 + 项目名 + 模块名+ 功能名
4. 带有包名怎么编译?
javac -d . xxx.java
5. 怎么运行?
java 完整类名
补充:以后说类名的时候,如果带着包名描述,表示完整类名。
如果没有带包,描述的话,表示简类名。
java.util.Scanner 完整类名。
Scanner 简类名
import
1. import什么时候不需要?
java.lang不需要。
同包下不需要。
其它一律都需要。
2. 怎么用?
import 完整类名;
import 包名.*;
import java.util.Scanner; // 完整类名。
// 同学的疑问:这样是不是效率比较低。
// 这个效率不低,因为编译器在编译的时候,会自动把*变成具体的类名。
import java.util. * ;
// 想省懒劲你不能太省了。
import java.* ; 这是不允许的,因为在java语言中规定,这里的*只代表某些类的名字。
访问控制权限
访问控制权限的种类
private 私有的 只能在本类中访问
public 公开的 在任何位置都能访问
protected 受保护的 表示只能在本类、同包以及子类中访问
默认的 表示只能在本类以及同包下访问
修饰符列表 本类 同包 子类 任意位置
public 可以 可以 可以 可以
protected 可以 可以 可以
默认 可以 可以
private 可以
范围从大到小排序:public > protected > 默认 > private
访问控制权限修饰符可以修饰什么?
属性 4个都能用
方法 4个都能用
类 public和默认
接口 public和默认
JDK类库的根类:Object
1.Object类中的方法
这个类中的方法都是所有子类通用的,任何一个类都是默认继承Object,就算没有直接继承,最终也会间接继承
Object类中常用的方法
第一种方法:去源代码当中。(比较麻烦)
第二种方法:去查阅Java的帮助文档
什么是API?
API是应用程序编程接口,整个JDK的类库就是一个javase的API,每一个API都会配置一套API帮助文档。SUN公司提前写好的类库叫做API
目前为止我们只需要知道:
protected Object clone()
//负责对象克隆
int hashcode()
// 获取对象的哈希值的一个方法
在Object中hashcode的方法的源码
public native int hashcode();
这个方法不是抽象方法,带有native关键字,底层调用c++程序
hashchode()返回哈希值,实际上就是一个Java对象的内存地址,经过哈希算法,得出的一个值
所以hashcode()方法的执行结果可以等同看作是一个Java对象的内存地址。
package ObjectJDK;
/*
hashcode方法
1. 在Object中hashcode的方法的源码
public native int hashcode();
这个方法不是抽象方法,带有native关键字,底层调用c++程序
hashchode()返回哈希值,实际上就是一个Java对象的内存地址,经过哈希算法,得出的一个值
所以hashcode()方法的执行结果可以等同看作是一个Java对象的内存地址。
*/
public class Test07 {
public static void main(String[] args){
Object o = new Object();
int hashCodeValue = o.hashCode();
System.out.println(hashCodeValue);//295530567
Myclass myclass = new Myclass();
int hashCodeValue2 = myclass.hashCode();
System.out.println(hashCodeValue2);//1324119927
}
}
class Myclass{
}
boolean euqals(Object obj)
// 判断对象是否相等
以后所有类的equals方法也需要重写,因为Object中的equals方法比较的是两个对象的内存地址,我们应该比较内容,所以需要重写。
重写规则:自己定,主要看是什么和什么相等时表示两个对象相等。
基本数据类型比较实用:==
对象和对象比较:调用equals方法
String类是SUN编写的,所以String类的equals方法重写了。
以后判断两个字符串是否相等,最好不要使用==,要调用字符串对象的equals方法。
注意:重写equals方法的时候要彻底。
总结:
1.String类已经重写了equals方法;
2.String类已经重写了toString方法;
java中基本数据类型比较是否相等使用”==“
java中引用数据类型使用equals方法来判断相等
package ObjectJDK;
/*
关于euqals方法
1.源代码
public boolean equals(Object obj) {
return (this == obj);
}
以上这个方法是Object的类默认实现
在Object中equals方法当中,默认使用的是==“判断两个对象是否相等,而”==“判断的是两个Java对象的内存地址,我们应该判断两个Java对象的内容是否相等
2.SUN公司设计equals方法的目的:
以后的编程过程中,要通过equals方法来判断两个对象是否相等。
3.判断两个Java对象不能使用“==”,“==”判断的是两个对象的内存地址
*/
public class Test02 {
public static void main(String[] args){
//判断两个基本数据类型的数据是否相等,可以直接使用“==”
// == 是判断a中的100和b中的100是否相等,保存的是a、b中的变量
int a = 100;
int b = 100;
System.out.println(a == b); //true
//判断两个java对象是否相等 使用equals
MyTime t1 = new MyTime(2008,8,8);//内存地址1
MyTime t2 = new MyTime(2008,8,8);//内存地址2
//测试一下,两个对象的相等可以不可以使用双等号
//这里的双等号判断的是:t1中保存的对象内存地址和t2中保存的对象内存地址是否相等
//System.out.println(t1 == t2);
boolean B = t1.equals(t2);
System.out.println(B);
MyTime t3 = new MyTime(2008,8,9);
System.out.println(t1.equals(t3));
MyTime t4 = null;
System.out.println(t1.equals(t4));
}
}
class MyTime{
private int year;
private int month;
private int day;
public MyTime() {
}
public MyTime(int year, int month, int day) {
this.year = year;
this.month = month;
this.day = day;
}
public int getYear() {
return year;
}
public int getMonth() {
return month;
}
public int getDay() {
return day;
}
public void setYear(int year) {
this.year = year;
}
public void setMonth(int month) {
this.month = month;
}
public void setDay(int day) {
this.day = day;
}
/*
要重写toString方法,越简洁越好,可读性越强越好
向简洁的、详实的、易读方法发展
*/
/* public String toString(){
return year + "年" + month + "月" + day + "日";
}*/
/*
默认的equals
public boolean equals(Object obj) {
return (this == obj);
}
*/
//重写equals方法
/*public boolean equals(Object obj) {
if (obj instanceof MyTime) {
MyTime mt = (MyTime) obj;
if (this.year == mt.year && this.month == mt.month && this.day == mt.day) {
return true;
}
}
return false;
}*/
//改良equals方法
/*public boolean equals(Object obj){
//如果是空
if(obj == null){
return false;
}//如果不是MyTime
if(!(obj instanceof MyTime)){
return false;
}//如果内存地址相同 比如 t1.equals(t1)
if (this == obj){
return true;
}
MyTime mt = (MyTime) obj;
if (this.year == mt.year && this.month == mt.month && this.day == mt.day) {
return true;
}
//执行到此,说明obj不是null,obj是MyTime
return false;
}*/
//再次改良
public boolean equals(Object obj){
//如果是空
if(obj == null || !(obj instanceof MyTime)){
return false;
}//如果不是MyTime
//如果内存地址相同 比如 t1.equals(t1)
if (this == obj){
return true;
}
MyTime mt = (MyTime) obj;
return this.year == mt.year && this.month == mt.month && this.day == mt.day;
}
package ObjectJDK;
/*
java重写了toString和equals方法
总结:
1.String类已经重写了equals方法;
2.String类已经重写了toString方法;
java中基本数据类型比较是否相等使用”==“
java中引用数据类型使用equals方法来判断相等
*/
public class Test03 {
public static void main(String[] args){
//大部分情况下,我们采用这样的方式来创建字符串对象
String s1 = "Hello";
String s2 = "ABC";
//实际上String属于一个类,不属于基本数据类型
//既然String是一个类,那么存在基本构造方法
String s3 = new String("test1");//内存地址是不同的
String s4 = new String("test1");
//String类已经重写equals方法
System.out.println(s3.equals(s4));
//String已经重写了toString方法
String x = new String("xx");
System.out.println(x.toString());
}
}
package ObjectJDK;
public class Test05 {
public static void main(String[] args){
Address a1 = new Address("1","2","3");
User u1 = new User("yx",a1);
User u2 = new User("yx",a1);
User u3 = new User("yy",new Address("1","2","1"));
System.out.println(u1.addr);
boolean flag = u1.equals(u2);
System.out.println(flag);
System.out.println(u1.equals(u3));
}
}
class User{
String name;
Address addr;
public User() {
}
public User(String name, Address addr) {
this.name = name;
this.addr = addr;
}
public boolean equals(Object obj){
if(obj == null || !(obj instanceof User)){
return false;
}
if (this == obj){
return true;
}
User u = (User)obj;
if(this.addr.equals(u.addr) && this.name.equals(u.name)){
return true;
}
return false;
}
}
class Address{
String city;
String street;
String zipcode;
public Address() {
}
public Address(String city, String street, String zipcode) {
this.city = city;
this.street = street;
this.zipcode = zipcode;
}
public String toString(){
return "CITY:" + city + ",STREET:" + street + ",ZIPCODE:" + zipcode;
}
public boolean equals(Object obj){
if(obj == null || !(obj instanceof Address)){
return false;
}
if (this == obj){
return true;
}
Address A = (Address) obj;
if(this.city.equals(A.city) && this.street.equals(A.street) && this.zipcode.equals(A.zipcode)){
return true;
}
return false;
}
}
String toString()
以后所有类的toString()方法是需要重写的。
重写规则,越简单越明了就好。
System.out.println(引用); 这里会自动调用“引用”的toString()方法。
String类是SUN写的,toString方法已经重写了。
package ObjectJDK;
/*
关于Object类中的toSting()方法
1. 源代码、
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
源代码上toString方法的默认实现为: 类名@对象的内存地址转换为十六进制的形式
2.SUN公司设计toString方法的作用
toString方法的设计目的是:通过调用这个方法可以将Java对象转换成字符串的表达形式
3.其实SUN公司开发java语言的时候,建议所有的子类都去重写toString方法
toString方法应该是一个简洁的、详实的、易阅读的
*/
public class Test01 {
public static void main(String[] args){
MyTime t = new MyTime(1970,1,1);
String s = t.toString();
//注意输出引用的时候,会自动调用toString方法
System.out.println(s);//ObjectJDK.MyTime@776ec8df //1970年1月1日
}
2
}
class MyTime{
int year;
int month;
int day;
public MyTime() {
}
public MyTime(int year, int month, int day) {
this.year = year;
this.month = month;
this.day = day;
}
/*
要重写toString方法,越简洁越好,可读性越强越好
向简洁的、详实的、易读方法发展
*/
public String toString(){
return year + "年" + month + "月" + day + "日";
}
}
protected void finalize()
//垃圾回收器负责调用的方法
finalize方法
- 源码
protected void finalize() throws Throwable { } - finalize方法只有一个方法体,里面没有代码,而且这个方法是protected修饰的
- 这个方法不需要程序员手动调用。责JVM的垃圾回收器负调用这个方法(GC),equals toString方法是手动调用的
- finalize方法的转型时机:
当一个Java对象即将呗垃圾回收器回收的时候,垃圾回收器负责调用finalize()方法 - finalize方法实际上是SUN公司为Java程序员准备的一个时机,垃圾销毁时机,如果希望在对象销毁时机,执行一段代码的话,
这个代码需要写到finalize
6. 静态代码块的作用
static{
…
}
静态代码块在类加载时执行,并执行一次
这是SUN准备的类加载时机
finalize()方法也是SUN为程序员准备的一个时机,这个时机就是垃圾回收时机。
7. Java中的垃圾回收器不会轻易启动。
垃圾太少,或者时间没到,种种条件下,有可能启动有可能也不启动。
package ObjectJDK;
/*
finalize方法
1. 源码
protected void finalize() throws Throwable { }
2. finalize方法只有一个方法体,里面没有代码,而且这个方法是protected修饰的
3. 这个方法不需要程序员手动调用。责JVM的垃圾回收器负调用这个方法(GC),equals toString方法是手动调用的
4. finalize方法的转型时机:
当一个Java对象即将呗垃圾回收器回收的时候,垃圾回收器负责调用finalize()方法
5. finalize方法实际上是SUN公司为Java程序员准备的一个时机,垃圾销毁时机,如果希望在对象销毁时机,执行一段代码的话,
这个代码需要写到finalize中
6.静态代码块的作用
static{
....
}
静态代码块在类加载时执行,并执行一次
这是SUN准备的类加载时机
finalize()方法也是SUN为程序员准备的一个时机,这个时机就是垃圾回收时机。
7. Java中的垃圾回收器不会轻易启动。
垃圾太少,或者时间没到,种种条件下,有可能启动有可能也不启动。
*/
public class Test06 {
public static void main(String[] args){
Person p = new Person();
//变成垃圾
p = null;
//有一段代码可以建议垃圾回收器启动
System.gc();
}
}
//项目开发中有这样的业务需求:所有对象在JVM中被释放的时候,请记录一下释放时间
//记录对象被释放的时间点代码写到finalize方法中。
class Person{
protected void finalize() throws Throwable {
System.out.println("即将被销毁");
}
}
内部类
匿名内部类
1. 内部类
内部类:在类的内部又定义了一个新的类,被称为内部类
2. 内部类的分类:
静态内部类:类似于静态变量
实例内部类:类似于实例变量
局部内部类:类似于局部变量
3. 使用内部类编写的代码,可读性很差,能不用尽量不用
4. 匿名内部类属于局部内部类的一种,因为这个类没有名字,而叫匿名内部类
5. 学习匿名内部类的主要目的是让大家以后阅读代码时可以理解。
不建议使用,的两个缺点:
太复杂,可读性差
类没有名字,只能使用一次
package neibulei;
/*
匿名内部类:
1. 内部类
内部类:在类的内部又定义了一个新的类,被称为内部类
2. 内部类的分类:
静态内部类:类似于静态变量
实例内部类:类似于实例变量
局部内部类:类似于局部变量
3. 使用内部类编写的代码,可读性很差,能不用尽量不用
4. 匿名内部类属于局部内部类的一种,因为这个类没有名字,而叫匿名内部类
5. 学习匿名内部类的主要目的是让大家以后阅读代码时可以理解。
不建议使用,的两个缺点:
太复杂,可读性差
类没有名字,只能使用一次
*/
public class Test01 {
public static void main(String[] args){
//调用MyMath中的sum方法
MyMath mm = new MyMath();
// Compute c = new ComputeIm(); 向下转型
//mm.sum(new ComputeIm(),100,200);
mm.sum(new Compute(){
//匿名内部类 不建议使用,代码可读性太差,且只能使用一次。
public int sum(int a, int b) {
return a + b;
}//代表对接口的实现
},100,200);
}
static String country;
//该类在类的内部,所以称为内部类
//由于前面有static,所以称为静态内部类
static class Inner1{
}
//实例内部类
class Inner2{
}
public void doSome(){
//局部变量
int n = 100;
//局部内部类
class Inner3{
}
}
public void doOther(){
//dosome中的局部内部类在这里不能用 不在一个局部区域
}
}
//接口的实现类
//接口是完全抽象的,方法也是抽象方法,这里要重写方法
/*使用匿名内部类这个实现类可以不写
class ComputeIm implements Compute{
@Override
public int sum(int a, int b) {
return a + b;
}
}*/
//计算接口
interface Compute {
int sum(int a, int b);
}
class MyMath{
public void sum(Compute c,int x, int y){
int revalue = c.sum(x,y);
System.out.println(x + " + " + y + " = " + revalue);
}
}
数组
一维数组
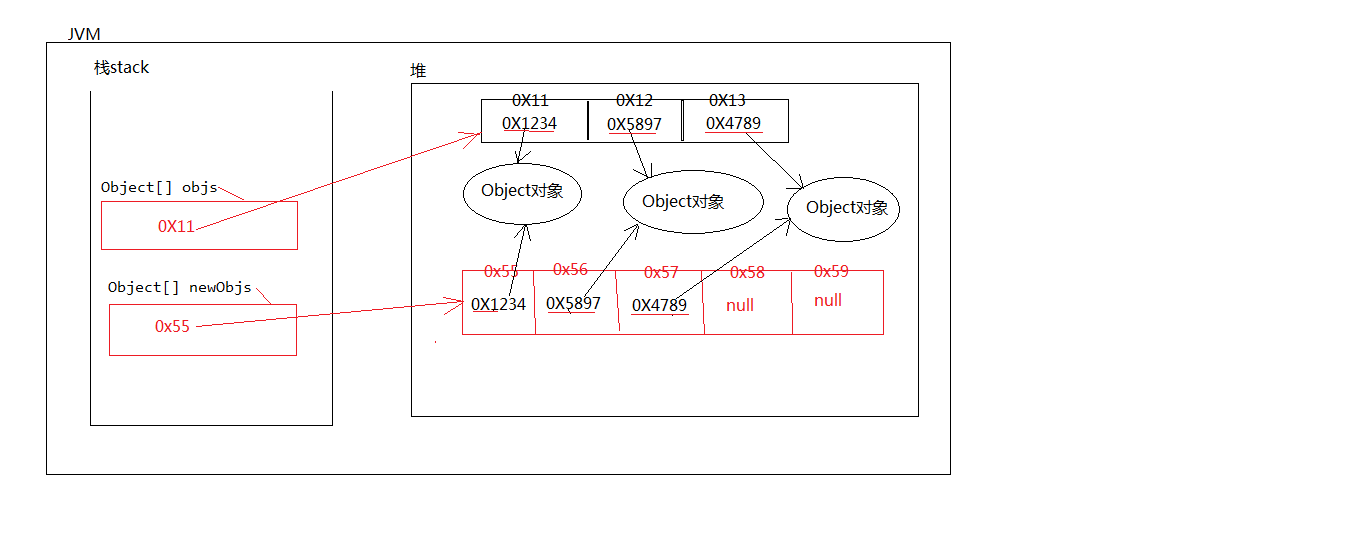
1.Java中的数组是一种引用数据类型,不属于基本数据类型,数组的父类时Object
2.数组实际上是一个容器,可以容纳多个元素。数组字面意思:一组数据
3.数组当中可以存储基本数据类型的数据,也可以存储引用数据类型的数据
4.数组因为是引用类型,所以数组对象是存储在堆内存中的
Person p1 = new Person();
Person p2 = new Person();
5.数组在内存方面:数组当中如果存储的是”java对象“的话,实际上存储的是对象的”引用(内存地址)“
6.数组一旦创建,在java中规定长度不可变
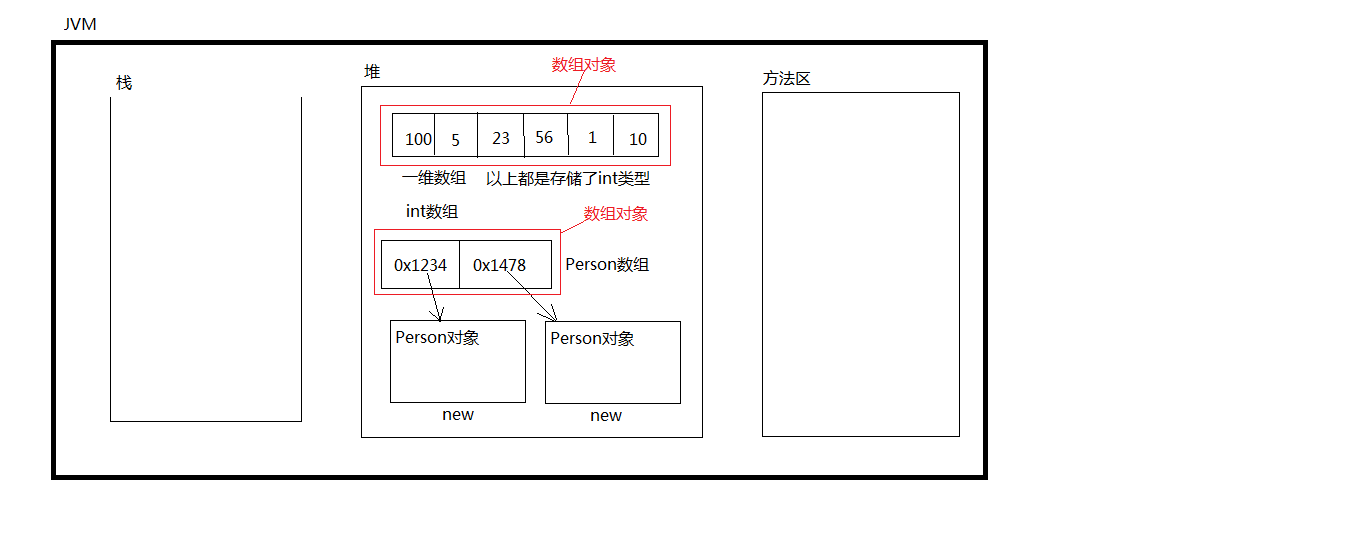
7.数组的分类:一维、二维、三维、多维…
8.所有的数组对象都有length属性,用来获取数组中元素的个数
9.java中的数组要求数组中的元素类型统一。比如:int类型数组只能存储int,person类型只能存储person
10.数组在内存方面存储的时候,数组中的元素内存地址是连续的(存储的每一个元素都是有规则的挨着排列的),内存地址连续
这是数组的存储特点,实际上数组是一种简单的数据结构
11.所有的数组都是拿”第一个小方块的内存地址“作为第一个内存地址(数组中的首元素内存地址,作为数组的内存地址)
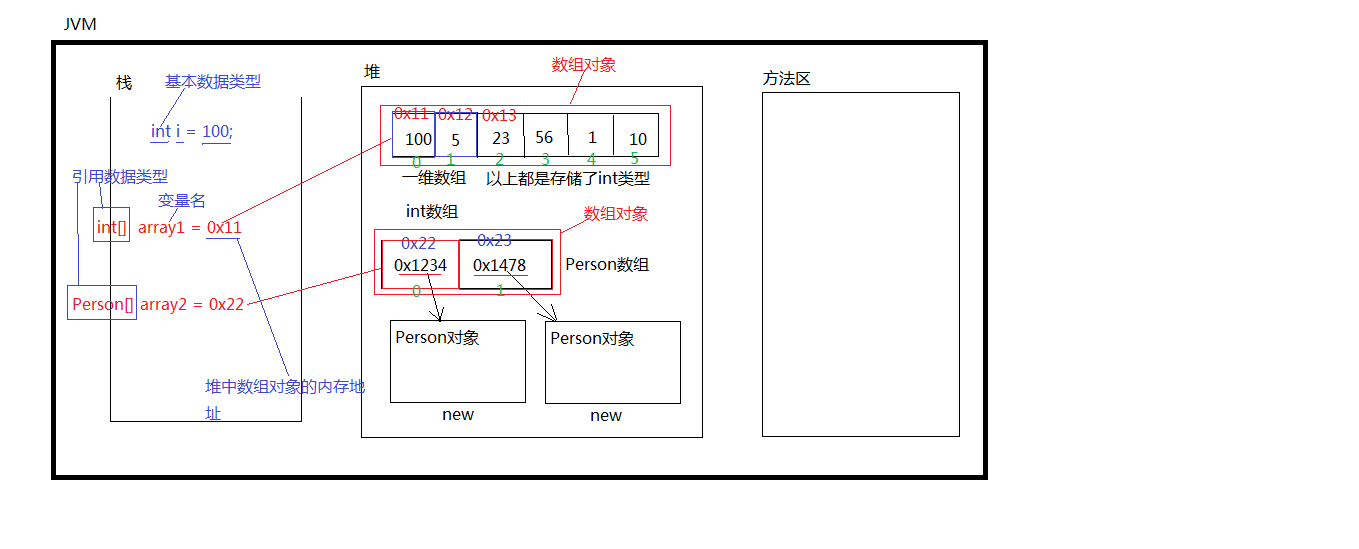
12.数组每一个元素都是有下标的从0开始,最后一个下标为:length-1
13.数组作为这种数据结构的优点缺点:
优点:查询/检索某个下标上的元素时效率极高。可以说是查询效率最高的一个数据结构
第一:每一个元素的内存地址在空间存储上是连续的
第二:每一个元素类型想同,所以占用空间大小一样
第三:知道第一个元素内存地址,知道每一个元素占用空间大小,又知道下标,所以通过一个数学表达式
就可以计算出某个下标上内存的地址,所以数组的检索效率是最高的
数组中存储100个元素,或者存储100w个元素,在元素查询时候,效率都是相同的,因为数组中元素查找的时候
不会一个一个找,是通过数学表达式计算出来的(直接定位的)
缺点:
第一:由于为了保证数组中的每个元素的内存地址连续,所以在数组上随机删除或者增加元素的时候效率较低,因为随机增删
元素会涉及到后面的元素统一向前或向后的位移操作。
第二:数组不能存储大数据量,因为很难在内存空间上找到一块特别大的连续的内存空间。
14.声明/定义一维数组
语法格式:
int[] array1;
double[] array2;
boolean[] array3;
15.初始化一维数组
包括两种方式:静态初始化一维数组,动态初始化一维数组。
静态初始化语法格式:
int[] array = {100,200,300};
动态初始化语法格式:
int[] array = new int[5];//这里的5代表数组的元素个数,每个元素的默认值为0
String[] names = new String[6];//初始化String类型的数组长度为6的数组,每个元素默认值null
package array;
/*
Array
1.Java中的数组是一种引用数据类型,不属于基本数据类型,数组的父类时Object
2.数组实际上是一个容器,可以容纳多个元素。数组字面意思:一组数据
3.数组当中可以存储基本数据类型的数据,也可以存储引用数据类型的数据
4.数组因为是引用类型,所以数组对象是存储在堆内存中的,数组存放放在堆当中
Person p1 = new Person();
Person p2 = new Person();
5.数组在内存方面:
数组当中如果存储的是”java对象“的话,实际上存储的是对象的”引用(内存地址)“,数组中不能直接存储java对象
6.数组一旦创建,在java中规定长度不可变
7.数组的分类:一维、二维、三维、多维...
8.所有的数组对象都有length属性,用来获取数组中元素的个数
9.java中的数组要求数组中的元素类型统一。比如:int类型数组只能存储int,person类型只能存储person
10.数组在内存方面存储的时候,数组中的元素内存地址是连续的(存储的每一个元素都是有规则的挨着排列的),内存地址连续
这是数组的存储特点,实际上数组是一种简单的数据结构
11.所有的数组都是拿”第一个小方块的内存地址“作为第一个内存地址(数组中的首元素内存地址,作为数组的内存地址)
12.数组每一个元素都是有下标的从0开始,最后一个下标为:length-1
13.数组作为这种数据结构的优点缺点:
优点:查询/检索某个下标上的元素时效率极高。可以说是查询效率最高的一个数据结构
第一:每一个元素的内存地址在空间存储上是连续的
第二:每一个元素类型想同,所以占用空间大小一样
第三:知道第一个元素内存地址,知道每一个元素占用空间大小,又知道下标,所以通过一个数学表达式
就可以计算出某个下标上内存的地址,所以数组的检索效率是最高的
数组中存储100个元素,或者存储100w个元素,在元素查询时候,效率都是相同的,因为数组中元素查找的时候
不会一个一个找,是通过数学表达式计算出来的(直接定位的)
缺点:
第一:由于为了保证数组中的每个元素的内存地址连续,所以在数组上随机删除或者增加元素的时候效率较低,因为随机增删
元素会涉及到后面的元素统一向前或向后的位移操作。
第二:数组不能存储大数据量,因为很难在内存空间上找到一块特别大的连续的内存空间。
14.声明/定义一维数组
语法格式:
int[] array1;
double[] array2;
boolean[] array3;
15.初始化一维数组
包括两种方式:静态初始化一维数组,动态初始化一维数组。
静态初始化语法格式:
int[] array = {100,200,300};
动态初始化语法格式:
int[] array = new int[5];//这里的5代表数组的元素个数,每个元素的默认值为0
String[] names = new String[6];//初始化String类型的数组长度为6的数组,每个元素默认值null
*/
public class Test01 {
public static void main(String[] agrs){
//使用静态初始化的方式,int类型
int[] a1 = {1,2,3,4};
//数组中元素的下标
//所有的数组对象都有length属性
System.out.println(a1.length);
System.out.println("第一个元素:" + a1[0]);
System.out.println("最后一个元素:" + a1[a1.length - 1]);
System.out.println("------------------------");
a1[0] = 11;
a1[a1.length - 1] = 0;
System.out.println("第一个元素:" + a1[0]);
System.out.println("最后一个元素:" + a1[a1.length - 1]);
System.out.println("------------------------");
for(int i = 0;i<a1.length;i++){
System.out.println(a1[i]);
}
System.out.println("------------------------");
//System.out.println(a1[5]);//ArrayIndexOutOfBoundsException异常
for(int i = a1.length - 1; i >= 0; i--){
System.out.println(a1[i]);
}
}
}
16.采用静态初始化方式和动态初始化方式时间
采用静态初始化方式:当你创建数组的时候,确定数组中存储哪些具体的元素时,可以采用静态初始化方式
采用动态初始化方式:当你创建数组的时候,不确定确定数组中存储哪些具体的元素时,可以采用动态初始化方式
package array;
/*
关于每个类型的默认值:
数据类型 默认值
----------------------------
byte 0
short 0
int 0
long 0l
double 0.0
float 0.0F
boolean false
char \u0000
引用数据类型 null
采用静态初始化方式:当你创建数组的时候,确定数组中存储哪些具体的元素时,可以采用静态初始化方式
采用动态初始化方式:当你创建数组的时候,不确定确定数组中存储哪些具体的元素时,可以采用动态初始化方式
*/
public class Test02 {
public static void main(String[] args){
int[] a = new int[4];//默认值都为0
for (int i = 0;i< a.length; i++){
System.out.println(a[i]);
}
a[0] = 1;
a[1] = 2;
a[2] = 3;
a[3] = 4;
//初始化一个Object类型的数组,采用动态初始化方法,默认值都为null
System.out.println("-------------");
Object[] objs = new Object[3];
for(int i = 0; i<objs.length; i++){
System.out.println(objs[i]);
}
System.out.println("-------------");
String[] strs = new String[3];
for(int i = 0; i< strs.length; i++){
System.out.println(strs[i]);
}
System.out.println("-------------");
String[] strs2 = {"abc","def","ghi"};
for (int i = 0; i< strs2.length; i++){
System.out.println(strs2[i]);
}
System.out.println("-------------");
//存储Object
Object o1 = new Object();
Object o2 = new Object();
Object o3 = new Object();
Object[] objects = {o1,o2,o3};
for (int i = 0; i< objects.length; i++){
System.out.println(objects[i]);
}
}
}
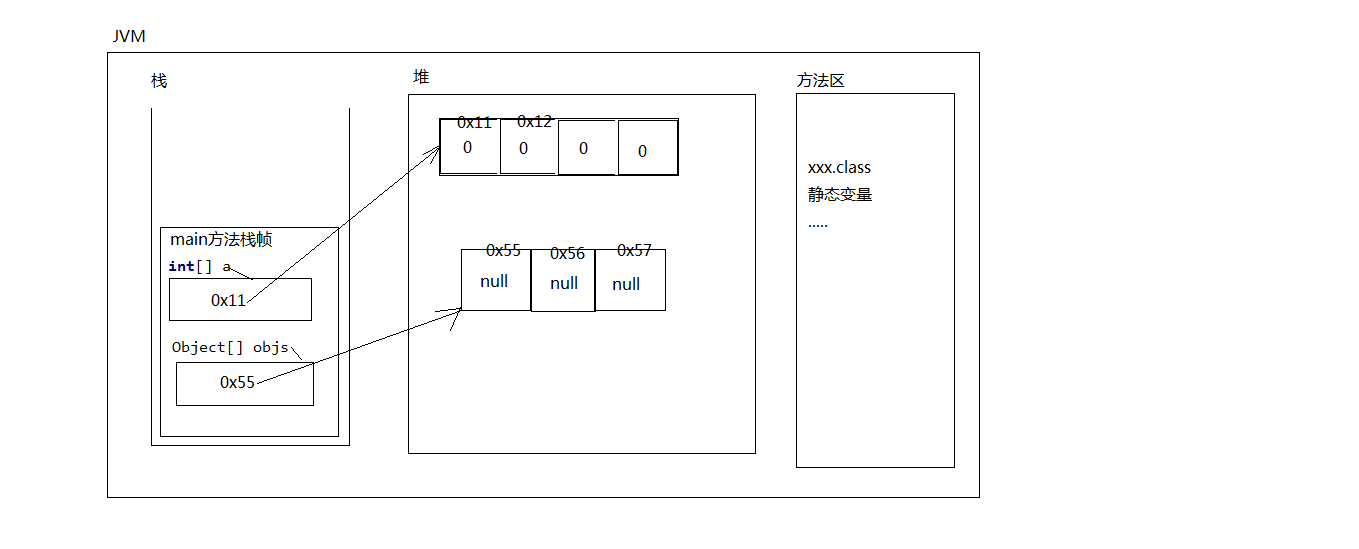
17.当一个方法上的参数类型是一个数组的时候,方法的传参方式
package array;
//当一个参数上,方法的类型是一个数组的时候。
public class Test03 {
public static void main(String[] args){
System.out.println("hello word");
//调用方法传数组
int[] x = {1,2,3,4};
printArray(x);
System.out.println("-----------------");
String[] strs = {"abc","def","ghi"};
printArray(strs);
System.out.println("-----------------");
String[] strs2 = new String[6];
printArray(strs2);
}
public static void printArray(int[] array){
for(int i = 0; i< array.length; i++){
System.out.println(array[i]);
}
}
public static void printArray(String[] args){
for(int i = 0; i< args.length; i++){
System.out.println(args[i]);
}
}
}
package array;
/*
当一个方法的参数是一个数组的时候,还可以采用
*/
public class Test04 {
public static void main(String[] args){
//静态初始化
int[] a = {1,2,3};
printArray(a);
System.out.println("------------------");
//如果直接传递一个静态数组,语法如下。
printArray(new int[]{1,2,3,});
//动态初始化一维数组\
System.out.println("------------------");
int[] a2 = new int[4];
printArray(a2);
System.out.println("------------------");
printArray(new int[3]);
}
public static void printArray(int[] array){
for(int i = 0; i< array.length; i++){
System.out.println(array[i]);
}
}
}
18.main方法中的“String[] args”有什么作用
JVM负责调用main方法的时候会自动传一个String数组过来。
package array;
/*
1.main方法中的“String[] args”有什么作用
JVM负责调用main方法的时候会自动传一个String数组过来。
*/
public class Test05 {
//JVM调用的时候一定会传递一个String数组
public static void main(String[] args){
//JVM默认传递过来的这个数组的长度为0
//通过测试得出args不为null。不是空引用
System.out.println("JVM给传递的String数组参数,这个数组的长度" + args.length);
//这个数组什么时候里面会有值呢,其实这个数组是留给用户的,用户可以在控制台上输入参数,这个参数会被
//自动转为String数组
//例如:java Test02 abc def xyz
//那么这个时候JVM会自动将abc def xyz通过空格的方式进行分离,分离完成之后,自动放到String[] args这个数组当中
//所以main方法上面的String数组,主要是用来接收用户输入参数的
//数组对象创建了,但是数组中没有任何东西
/*String[] strs = new String[0];
printArray(strs);*/
for(int i = 0;i < args.length;i++) {
System.out.println(args[i]);
}
}
public static void printArray(String[] args){
System.out.println(args.length);
}
}
19.模拟一个系统,假设这个系统要使用,必须输入用户名和密码
package array;
/*
模拟一个系统,假设这个系统要使用,必须输入用户名和密码
*/
public class Test06 {
/*
用户名密码输入args中
*/
public static void main(String[] args){
System.out.println("请输入用户名和密码");
//程序执行到此,用户确实提供了用户名和密码
//接下来判断是否正确
String username = args[0];
String password = args[1];
//判断字符串是否相等
if("admin".equals(username)&&"123".equals(password)){//这样编写可以预防空指针异常
//if(username.equals("admin")&&password.equals("123")){
System.out.println("登入成功");
}else {
System.out.println("登入成功");
}
}
}
20.一维数组的深入
一维数组的深入,数组中存储的类型为:引用数据类型
对于数组来说,实际上只能存储Java对象的内存地址,数组中存储的每个元素是“引用”
package array;
/*
一维数组的深入,数组中存储的类型为:引用数据类型
对于数组来说,实际上只能存储Java对象的内存地址,数组中存储的每个元素是“引用”
*/
public class Test07 {
public static void main(String[] args){
//创建一个Animal类型的数组
Animal a1 = new Animal();
Animal a2 = new Animal();
Animal[] animals = {a1,a2};
for(int i = 0; i<animals.length; i++){
animals[i].move();
}
System.out.println("---------------");
Animal[] ans = new Animal[2];
ans[0] = new Animal();//创建一个Animal对象,放入第一个位置
//Animal数组中只能存放Animal数组的类型,不能放其他的
//Animal可以存放Cat类型的数据,因为Cat时Animal的子类
ans[1] = new Cat();
Animal[] anis = {new Cat(),new Brid()};//该数组中存储了两个对象的内存地址
for(int i = 0; i< anis.length; i++){
//这个取出来有可能时Cat,也有可能是Brid,不管肯定是Animal
//如果调用的方法是父类型当中存在的方法,那么不需要向下转型,直接使用父类型调用即可。
anis[i].move();
//调用子对象特有的方法时,需要进行类型的判断
if (anis[i] instanceof Cat){
((Cat) anis[i]).catchMouse();//父类型需要转换为子类型
}
if(anis[i] instanceof Brid){
((Brid) anis[i]).Sing();
}
}
}
}
class Animal{
public void move(){
System.out.println("Animal move");
}
}
class product{
}
class Cat extends Animal{
public void move(){
System.out.println("Cat move");
}
public void catchMouse(){
System.out.println("catch mouse");
}
}
class Brid extends Animal{
public void move(){
System.out.println("Brid move");
}
public void Sing(){
System.out.println("sing");
}
}
21.关于一维数组的扩容
在Java中,数组长度一旦确定不可变,数组满了需要扩容。
Java中对数组的扩容是:
先新建一个大容量的数组,然后将小容量数组中的元素一个个拷贝到大数组当中
结论:数组扩容效率比较低,因为涉及到拷贝问题,所以在以后的开发中,尽可能少的进行数组的拷贝,
最好预估准确数组的长度,这样可以减少数组扩容的次数,提高效率
package array;
/*
关于一维数组的扩容
在Java中,数组长度一旦确定不可变,数组满了需要扩容。
Java中对数组的扩容是:
先新建一个大容量的数组,然后将小容量数组中的元素一个个拷贝到大数组当中
结论:数组扩容效率比较低,因为涉及到拷贝问题,所以在以后的开发中,尽可能少的进行数组的拷贝,
最好预估准确数组的长度,这样可以减少数组扩容的次数,提高效率
*/
public class Test08 {
public static void main(String[] args) {
//java中数组是怎么进行拷贝呢?
//System.arraycopy();5个参数
int[] src = {1, 11, 2, 3, 4};
int[] dest = new int[20];
//利用JDK System类中的arraycopy方法,来完成数组的拷贝
/*System.arraycopy(src,1,dest,3,2);
for(int i = 0; i< dest.length;i++){
System.out.println(dest[i]);
}*/
System.arraycopy(src, 0, dest, 0, src.length);
for (int i = 0; i < dest.length; i++) {
System.out.println(dest[i]);
}
System.out.println("------------");
String [] strs = new String[5];
String[] S = {"11","22","33"};
System.arraycopy(S,0,strs,0,S.length);
for (int i = 0; i< strs.length;i++){
System.out.println(strs[i]);
}
System.out.println("---------------");
Object[] objs = {new Object(),new Object(),new Object()};
Object[] Nobjs = new Object[5];
System.arraycopy(objs,0,Nobjs,0,objs.length);//拷贝的事内存地址
for (int i = 0; i< objs.length;i++){
System.out.println(Nobjs[i]);
}
}
}
1
11
2
3
4
0
0
0
0
0
0
0
0
0
0
0
0
0
0
0
------------
11
22
33
null
null
---------------
java.lang.Object@119d7047
java.lang.Object@776ec8df
java.lang.Object@4eec7777
Process finished with exit code 0
二维数组
1.二维数组其实是一个特殊的一维数组,特殊在这个一维数组当中的每一个元素是一个一维数组
2.三维数组是一个特殊的二维数组
实际的开发中,使用最多的是一维数组
3.二维数组静态初始化
int[][] a = {{},{}};
package array;
/*
关于Java中的二维数组,二维数组其实是一个特殊的一维数组
1.二维数组其实是一个特殊的一维数组,特殊在这个一维数组当中的每一个元素是一个一维数组
2.三维数组是一个特殊的二维数组
实际的开发中,使用最多的是一维数组
3.二维数组静态初始化
int[][] a = {{},{}};
*/
public class Test09 {
public static void main(String[] args){
//一维数组
int[] array = {100,200,300};
System.out.println(array.length);
//二维数组
int[][] a = {{2,3},
{4,5,6},
{7,8,9}};
System.out.println(a.length);
System.out.println(a[0].length);
}
}
4.关于二维数组中的读和改:
a[ 二维数组中一维数组的下标 ] [ 一维数组的下标 ]
a[0] [0]:表示第一个一维数组的第一个下标
package array;
/*
关于二维数组中的读和改:
a[二维数组中一维数组的下标][一维数组的下标]
a[0][0]:表示第一个一维数组的第一个下标
*/
public class Test10 {
public static void main(String[] args){
int[][] a={{1,2,3},
{4,5,6},
{7,8,9,10}};
//取出第一个一维数组
/*int[] aa1 = a[0];
int aaa1 = aa1[0];
System.out.println("我是第一个一维数组的第一个元素" + aaa1);*/
int aaa1 = a[0][0];
System.out.println("我是第一个一维数组的第一个元素" + aaa1);
a[1][1] = 11;
System.out.println(a[1][1]);
}
}
5.关于二维数组中的读和改:
a [二维数组中一维数组的下标] [一维数组的下标]
a[0] [0]:表示第一个一维数组的第一个下标
package array;
/*
关于二维数组中的读和改:
a[二维数组中一维数组的下标][一维数组的下标]
a[0][0]:表示第一个一维数组的第一个下标
*/
public class Test10 {
public static void main(String[] args){
int[][] a={{1,2,3},
{4,5,6},
{7,8,9,10}};
//取出第一个一维数组
/*int[] aa1 = a[0];
int aaa1 = aa1[0];
System.out.println("我是第一个一维数组的第一个元素" + aaa1);*/
int aaa1 = a[0][0];
System.out.println("我是第一个一维数组的第一个元素" + aaa1);
a[1][1] = 11;
System.out.println(a[1][1]);
}
}
6.二维数组的遍历
package array;
/*
二维数组的遍历
*/
public class Test11 {
public static void main(String[] args){
String[][] a = {
{"123","456"},
{"123","456","789"},
{"123","456","789","1111"}
};
for (int i = 0; i< a.length; i++){
System.out.println();
for (int j = 0; j< a[i].length; j++){
System.out.print(a[i][j] + " ");
}
}
}
}
7.动态初始化二维数组
package array;
/*
动态初始化二维数组
*/
public class Test12 {
public static void main(String[] args){
int[][] a = new int[3][4];
printArray(a);
printArray(new int[][]{{1,2,3},
{4,5,6},
{7,8,9,10}});
}
public static void printArray(int[][] a){
for (int i = 0; i< a.length; i++){
System.out.println();
for (int j = 0; j< a[i].length; j++){
System.out.print(a[i][j] + " ");
}
}
}
}
总结:
1.1、数组的优点和缺点,并且要理解为什么。
第一:空间存储上,内存地址是连续的。
第二:每个元素占用的空间大小相同。
第三:知道首元素的内存地址。
第四:通过下标可以计算出偏移量。
通过一个数学表达式,就可以快速计算出某个下标位置上元素的内存地址,
直接通过内存地址定位,效率非常高。
优点:检索效率高。
缺点:随机增删效率较低,数组无法存储大数据量。
注意:数组最后一个元素的增删效率不受影响。
1.2、一维数组的静态初始化和动态初始化
静态初始化:
int[] arr = {1,2,3,4};
Object[] objs = {new Object(), new Object(), new Object()};
动态初始化:
int[] arr = new int[4]; // 4个长度,每个元素默认值0
Object[] objs = new Object[4]; // 4个长度,每个元素默认值null
1.3、一维数组的遍历
for(int i = 0; i < arr.length; i++){
System.out.println(arr[i]);
}
1.4、二维数组的静态初始化和动态初始化
静态初始化:
int[][] arr = {
{1,2,34},
{54,4,34,3},
{2,34,4,5}
};
Object[][] arr = {
{new Object(),new Object()},
{new Object(),new Object()},
{new Object(),new Object(),new Object()}
};
动态初始化:
int[][] arr = new int[3] [4];
Object[][] arr = new Object[4] [4];
Animal[][] arr = new Animal[3] [4];
// Person类型数组,里面可以存储Person类型对象,以及Person类型的子类型都可以。
Person[][] arr = new Person[2] [2];
…
1.5、二维数组的遍历
for(int i = 0; i < arr.length; i++){ // 外层for循环负责遍历外面的一维数组。
// 里面这个for循环负责遍历二维数组里面的一维数组。
for(int j = 0; j < arr[i].length; j++){
System.out.print(arr[i][j]);
}
// 换行。
System.out.println();
}
1.6、main方法上“String[] args”参数的使用(非重点,了解一下,以后一般都是有界面的,用户可以在界面上输入用户名和密码等参数信息。)
1.7、数组的拷贝:System.arraycopy()方法的使用
数组有一个特点:长度一旦确定,不可变。
所以数组长度不够的时候,需要扩容,扩容的机制是:新建一个大数组,
将小数组中的数据拷贝到大数组,然后小数组对象被垃圾回收。
1.8、对数组中存储引用数据类型的情况,要会画它的内存结构图。
数组工具类
算法实际上在java中不需要精通,因为java中已经封装好了,要排序就调用方法就行。例如:java中提供了一个数组工具类:
java.util.Arrays
Arrays是一个工具类。
其中有一个sort()方法,可以排序。静态方法,直接使用类名调用就行。
数据常见算法
排序算法:
冒泡排序算法
选择排序算法
查找算法:
二分法查找
以上算法在以后的java实际开发中我们不需要使用的。
因为java已经封装好了,直接调用就行。
只不过以后面试的时候,可能会有机会碰上。
冒泡排序
参与比较的数据:9 8 10 7 6 0 11
第1次循环:
8 9 10 7 6 0 11 (第1次比较:交换)
8 9 10 7 6 0 11 (第2次比较:不交换)
8 9 7 10 6 0 11 (第3次比较:交换)
8 9 7 6 10 0 11 (第4次比较:交换)
8 9 7 6 0 10 11 (第5次比较:交换)
8 9 7 6 0 10 11 (第6次比较:不交换)
最终冒出的最大数据在右边:11
参与比较的数据:8 9 7 6 0 10
第2次循环:
8 9 7 6 0 10(第1次比较:不交换)
8 7 9 6 0 10(第2次比较:交换)
8 7 6 9 0 10(第3次比较:交换)
8 7 6 0 9 10(第4次比较:交换)
8 7 6 0 9 10(第5次比较:不交换)
参与比较的数据:8 7 6 0 9
第3次循环:
7 8 6 0 9(第1次比较:交换)
7 6 8 0 9(第2次比较:交换)
7 6 0 8 9(第3次比较:交换)
7 6 0 8 9(第4次比较:不交换)
参与比较的数据:7 6 0 8
第4次循环:
6 7 0 8(第1次比较:交换)
6 0 7 8(第2次比较:交换)
6 0 7 8(第3次比较:不交换)
参与比较的数据:6 0 7
第5次循环:
0 6 7(第1次比较:交换)
0 6 7(第2次比较:不交换)
参与比较的数据:0 6
第6次循环:
0 6 (第1次比较:不交换)
for (int i = 0;i<arr.length-1;i++){
for (int j = 0;j<arr.length-1-i;j++){
}
}
package array;
/*
冒泡算法
原始:3 2 7 6 8
拿着3和右边的2进行比较。如果左边>右边,交换位置
第一次:2 3 7 6 8
拿着上一次比较结果之后的右边较大的数据和后续的数据继续比较
第二次:2 3 7 6 8
第三次:2 3 6 7 8
第四次:2 3 6 7 8
*/
public class BubbleSort {
public static void main(String[] args){
int[] arr = {9,8,10,7,6,0,11};
int temp;
//经过冒泡排序算法,进行排序
for (int i = 0;i<arr.length-1;i++){
for (int j = 0;j<arr.length-1-i;j++){
if (arr[j]>arr[j+1]) {
temp = arr[j + 1];
arr[j + 1] = arr[j];
arr[j] = temp;
}
}
}
for (int i = 0;i<arr.length;i++){
System.out.print(arr[i]);
}
}
}
选择排序
选择排序比冒泡排序的效率高。
高在交换位置的次数上。
选择排序的交换位置是有意义的。
循环一次,然后找出参加比较的这堆数据中最小的,拿着这个最小的值和
最前面的数据“交换位置”。
参与比较的数据:3 1 6 2 5 (这一堆参加比较的数据中最左边的元素下标是0)
第1次循环之后的结果是:
1 3 6 2 5
参与比较的数据:3 6 2 5 (这一堆参加比较的数据中最左边的元素下标是1)
第2次循环之后的结果是:
2 6 3 5
参与比较的数据:6 3 5 (这一堆参加比较的数据中最左边的元素下标是2)
第3次循环之后的结果是:
3 6 5
参与比较的数据:6 5 (这一堆参加比较的数据中最左边的元素下标是3)
第4次循环之后的结果是:
5 6
注意:5条数据,循环4次。
二分法查找
第一:二分法查找建立在排序的基础之上。
第二:二分法查找效率要高于“一个挨着一个”的这种查找方式。
第三:二分法查找原理?
10(0下标) 23 56 89 100 111 222 235 500 600(下标9) arr数组
目标:找出600的下标
(0 + 9) / 2 --> 4(中间元素的下标)
arr[4]这个元素就是中间元素:arr[4]是 100
100 < 600
说明被查找的元素在100的右边。
那么此时开始下标变成:4 + 1
(5 + 9) / 2 --> 7(中间元素的下标)
arr[7] 对应的是:235
235 < 600
说明被查找的元素在235的右边。
开始下标又进行了转变:7 + 1
(8 + 9) / 2 --> 8
arr[8] --> 500
500 < 600
开始元素的下标又发生了变化:8 + 1
(9 + 9) / 2 --> 9
arr[9]是600,正好和600相等,此时找到了。
package array;
/*
二分法查找
10 11 12 13 14 15 16 17 18 19
通过二分法找出18这个元素的下标:
(0+10)/5------> 中间元素的下标
拿着中间这个元素和目标元素进行对比:
中间元素是:arr[5] ---> 15
15 < 18 被查找的元素在中间元素的右边
所以开始元素的小标从0变成5+1
在重新计算中间元素下标:
5+1+10 / 2 = 8
8下标对应的元素为18,找到了中间元素和被找的元素相等,下标为8
二分法查找元素算法是基于排序的基础之上,没有排序的数据是无法查找的
*/
public class TwoSaerch {
public static void main(String[] args){
int[] arr = {100,200,300,235,600,1000,2000,9999};
//二分法查找200
int index = binarySearch1(arr,2000);
System.out.println(index == -1? "该元素不存在":"该元素下表为:" + index);
}
private static int binarySearch1(int[] arr, int n) {
boolean flag = false;
int start = 0;
int end = arr.length - 1;
while(start <= end){
int mid = (start + end) / 2;
if(arr[mid] == n){
return mid;
}else if(arr[mid] < n){
start = mid +1;
}else if (arr[mid] > n){
end = mid -1;
}
}
return -1;
}
}
介绍一下java.util.Arrays工具类
所有方法都是静态的,直接用类名调用
主要使用的是两个方法:
二分法查找,排序
以后要看文档,不要死记硬背。
package array;
import java.lang.reflect.Array;
import java.util.Arrays;
/**
* SUN公司已经为我们写好了一个数组工具类
* java.util.Array
*
*/
public class ArrayTest02 {
public static void main(String[] args){
int arr[] = {1,5,7,4,3,4};
Arrays.sort(arr);
for (int i = 0; i< arr.length ; i++){
System.out.print(arr[i] + " ");
}
System.out.println("----------------");
//二分法查找
int index = Arrays.binarySearch(arr,4);
System.out.println(index == -1? "该元素不存在":"该元素下标为:" + index);
}
}
常用类
String类
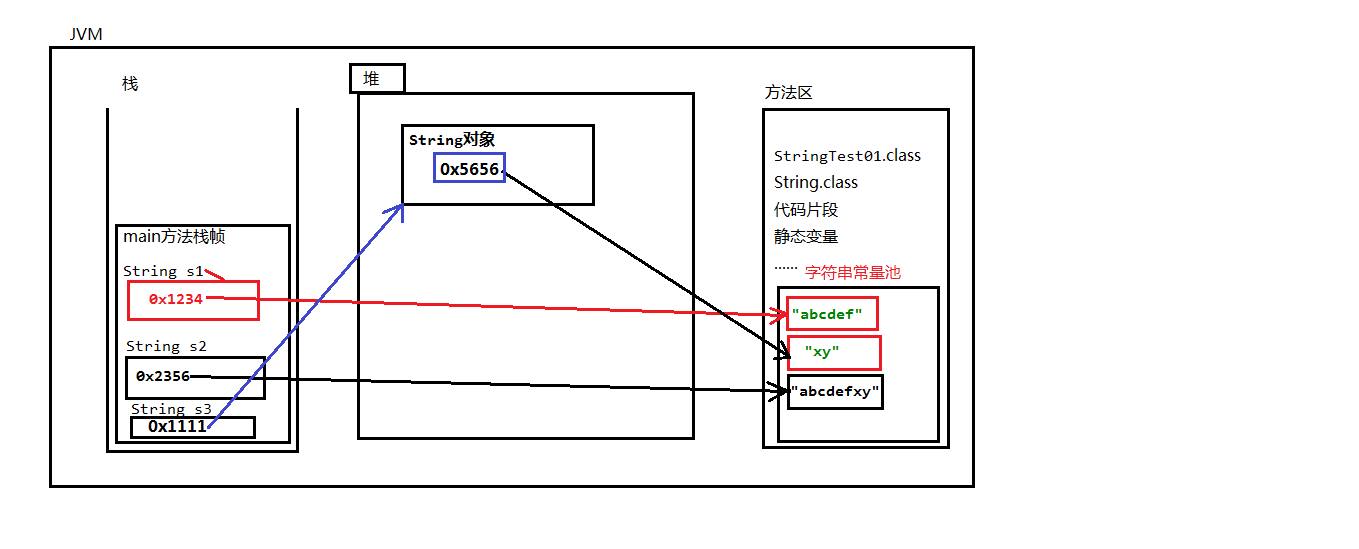
String为什么不可变?
String类中有一个byte[]数组,这个byte[]数组采用了final修饰,因为数组一旦创建长度不可变,并且被final修饰的引用指向某个对象之后,不可能再指向其他对象,所以String是不可变的!
String在内存方面的理解
1.String表示字符串类型,属于引用数据类型,不属于基本数据类
2.在Java随便使用双引号括起来的都是String对象。例如:”abc“,“def”,“hello world”,这三个String对象
3.Java中规定,双引号括起来的字符串是不可变的,也就是说”abc“从开始到最后,不能变成”abcd“
4.在JDK当中双引号括起来的字符串,都是直接存储在”方法区“的“字符串常量池“当中的
为什么sun公司把字符串存储在一个”字符串常量池“当中呢。因为字符串在实际开发中使用太频繁。为了执行效率,所以把字符串放到了
方法区的字符串常量池当中。
package javaseString;
/*
关于String
1.String表示字符串类型,属于引用数据类型,不属于基本数据类
2.在Java随便使用双引号括起来的都是String对象。例如:”abc“,"def","hello world",这三个String对象
3.Java中规定,双引号括起来的字符串是不可变的,也就是说”abc“从开始到最后,不能变成”abcd“
4.在JDK当中双引号括起来的字符串,都是直接存储在”方法区“的“字符串常量池“当中的
为什么sun公司把字符串存储在一个”字符串常量池“当中呢。因为字符串在实际开发中使用太频繁。为了执行效率,所以把字符串放到了
方法区的字符串常量池当中。
*/
public class Test01 {
public static void main(){
String s1 = "abcd";
String s2 = "abcd" +"xy";
//使用new方法来构建字符串对象
//凡是双引号括起来的都在字符串常量池中有一份,凡是new出来的对象都在堆内存中开辟空间
String s3 = new String("xy");
}
}
package javaseString;
public class UserTest {
public static void main(String[] args){
User user = new User(110,"x");
}
}
class User{
private int id;
private String name;
public User(){
}
public User(int id, String name) {
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public String getName() {
return name;
}
public void setId(int id) {
this.id = id;
}
public void setName(String name) {
this.name = name;
}
}
package javaseString;
public class Test02 {
public static void main(String[] args){
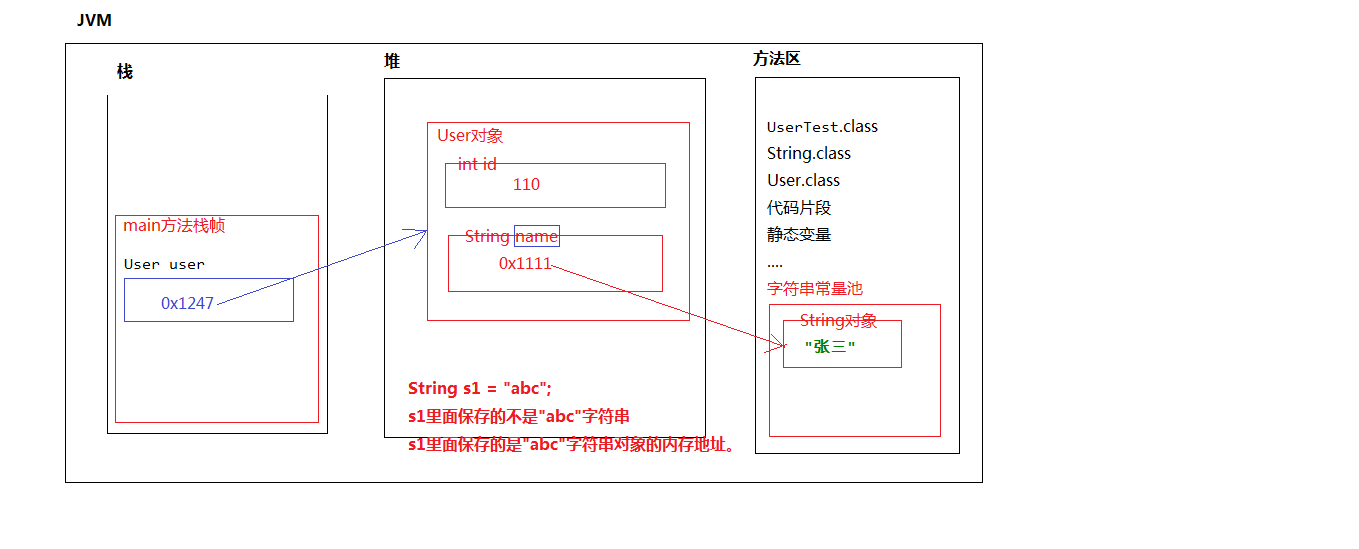
String s1 = "hello";
//"hello"是存储在方法区中的字符串常量池中
//所以这个”hello“不会重建
String s2 = "hello";
System.out.println(s1 == s2);//true
String x = new String("xy");
String y = new String("xy");
System.out.println(x==y);//false
//String类已经重写了equals方法
System.out.println(x.equals(y));//true
String k = new String("Test");
//"Test"是一个是String对象,只要是对象都可以调用方法
System.out.println("Test".equals(k));//建议使用这种方式,可以避免空指针异常
System.out.println(k.equals("Test"));
}
}
package javaseString;
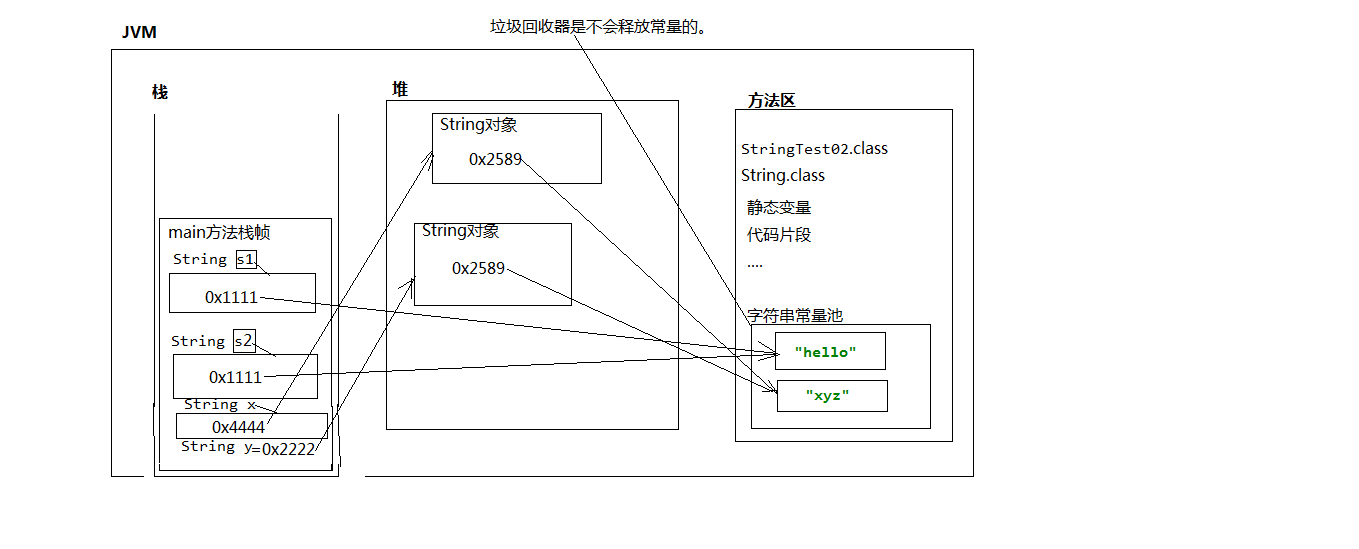
/*
分析一下程序创建了几个对象
*/
public class Test03 {
public static void main(String[] args){
/*
一共三个对象:
字符串常量池有一个对象
堆内存中有两个String对象
*/
String s1 = new String("hello");
String s2 = new String("hello");
}
}
关于String类中的构造方法
- String s = new String("");
- String s = “”; 最常用
- String s = new String(char数组);
- String s = new String(char数组,起始下标,长度)
- String s = new String(byte数组);
- String s = new String(byte数组,起始下标,长度)
package javaseString;
/**
* 关于String类中的构造方法
* String s = new String("");
* String s = ""; 最常用
* String s = new String(char数组);
* String s = new String(char数组,起始下标,长度)
* String s = new String(byte数组);
* String s = new String(byte数组,起始下标,长度)
*/
public class Test04 {
public static void main(String[] args){
//创建字符串最常用的方式
//这里只掌握常用的构造方法
String s1 = "hello world";
//String类已经重写了toString方法
System.out.println(s1);
byte[] bytes = {97,98,99};//97a 98b 99c
String s2 = new String(bytes);//支持传入byte数组
//输出一个引用的时候会自动toString方法,默认Object的话,会自动输出对象的内存地址
System.out.println(s2);//abc
//通过输出结果可以得到一个结论,String类已经重写了toString方法。
//输出字符串对象的话,输出的不是对象的内存地址,而是字符串本身。
//String(字节数组,起始位置,长度)
//将bytes数组中的一部分转换
String s3 = new String(bytes,1,2);//1为开始下标,2为长度
System.out.println(s3);
//将char数组全部转换为字符串
char[] chars = {'1','2','3','4'};
String s5 = new String(chars);
System.out.println(s5);
String s4 = new String(chars,1,2);
System.out.println(s4);
}
}
String类常用的21个方法
1.char charAt(int index)
2.compareT(String aontherString) 返回一个int
3.boolean contains(CharSequence s)
//判断前面的字符串是否包含后面的子字符串
4.boolean endsWith(String suffix)
//判断当前字符串是否以某个字符串结尾
5.boolean equals(String anotherString)
//equals方法是否调用compareTo JDK新版中没有调用compareTo()方法
6.boolean equalsIgnoreCase(String anotherString)
//判断两个字符串是否相等,忽略大小写
7.btye[] getBytes()
//将字符串对象转换为字节数组
8.int indexOf(String str)
//判断某个子字符串在当前字符串中第一次出现处的索引
9.boolean isEmpty()
//判断某个字符串是否为空
//底层源代码调用字符的length方法
10.int length()
//面试题:判断数组长度和判断字符串长度不一样
//判断数组长度是length属性,判断字符串长度是length方法
11.lastIndexOf(int ch)
//字符出现的最后一次索引位置
12.String replace(CharSequence traget,CharSequence replacement)
//替换指定的字符串
//String的父接口就是CharSequence
13.String[] split(String regex)
//拆分字符串
14.boolean startsWith(String perfix)
//判断某个字符串是否以某个子字符串开始的
15.String substring(int beginIndex)
//截取字符串
16.String substring(int beginIndex,int endIndex)//左闭右开
17.char[] toCharArray()
//将字符串转换为char数组
18.String toLowerCase()
转换为小写
19.String toUpperCase()
20.String trim()
去除字符串前后空白
21.String中只有一个方法是静态的不需要new对象
package javaseString;
import javax.crypto.spec.PSource;
import java.nio.charset.StandardCharsets;
import java.util.Locale;
public class Test05 {
public static void main(String[] args){
//String类当中的常用方法
//1.char charAt(int index)
char c= "中国人".charAt(1);
System.out.println(c);//输出国
//2.compareT(String aontherString) 返回一个int
System.out.println("abc".compareTo("abc"));//0 相等
System.out.println("abcd".compareTo("abce"));//-1 前小后大
System.out.println("abce".compareTo("abcd"));//1 前大后小
System.out.println("xyz".compareTo("yxz"));//-1
//3.boolean contains(CharSequence s)
//判断前面的字符串是否包含后面的子字符串
System.out.println("HelloWorld.java".contains(".java"));//true
System.out.println("1111111".contains("2"));//false
//4.boolean endsWith(String suffix)
//判断当前字符串是否以某个字符串结尾
System.out.println("test.txt".endsWith(".txt"));//true
System.out.println("test.txt".endsWith(".java"));//false
//5.boolean equals(String anotherString)
System.out.println("11".equals("11"));//true
//equals方法是否调用compareTo JDK新版中没有调用compareTo()方法
//6.boolean equalsIgnoreCase(String anotherString)
//判断两个字符串是否相等,忽略大小写
System.out.println("abc".equalsIgnoreCase("ABC"));//true
//7.btye[] getBytes()
//将字符串对象转换为字节数组
byte[] b = "abcdf".getBytes(StandardCharsets.UTF_8);
for (int i = 0;i<b.length;i++){
System.out.print(b[i] +" ");
}
System.out.println();
//8.int indexOf(String str)
//判断某个子字符串在当前字符串中第一次出现处的索引
System.out.println("abcd".indexOf("b"));
//9.boolean isEmpty()
//判断某个字符串是否为空
//底层源代码调用字符的length方法
System.out.println("11".isEmpty());//false
System.out.println("".isEmpty());//true
//10.int length()
//面试题:判断数组长度和判断字符串长度不一样
//判断数组长度是length属性,判断字符串长度是length方法
String s = "a";
System.out.println(s.length());//字符串.length()方法
//11.lastIndexOf(int ch)
//字符出现的最后一次索引位置
System.out.println("12345996789".lastIndexOf("9"));
//12.String replace(CharSequence traget,CharSequence replacement)
//替换指定的字符串
//String的父接口就是CharSequence
String newString = "11112222".replace("1111","2222");
System.out.println(newString);//22222222
//13.String[] split(String regex)
//拆分字符串
String[] s1 = "1998-1-0".split("-");//将1998-1-0以-进行拆分
for (int i =0;i<s1.length;i++){
System.out.print(s1[i] + " ");//1998 1 0
}
System.out.println();
//14.boolean startsWith(String perfix)
//判断某个字符串是否以某个子字符串开始的
System.out.println("111111223334456".startsWith("11"));//true
System.out.println("45678911".startsWith("11"));//flase
//15.String substring(int beginIndex)
//截取字符串
System.out.println("123456789987".substring(7));//参数是起始下标
//16.String substring(int beginIndex,int endIndex)
System.out.println("123456789987456".substring(7,10));//左闭右开 包含7 不包含10
//17.char[] toCharArray()
//将字符串转换为char数组
char[] chars = "我是中国人".toCharArray();
for (int i =0;i<chars.length;i++){
System.out.print(chars[i] + " ");//我 是 中 国 人
}
System.out.println();
//18.String toLowerCase()
//转换为小写
System.out.println("ABCDEF".toLowerCase(Locale.ROOT));//abcdef
//19.String toUpperCase()
System.out.println("abcdfe".toUpperCase(Locale.ROOT));//ABCDFE
//20.String trim()
//去除字符串前后空白
System.out.println(" 123 456 789 ".trim());//123 456 789
//21.String中只有一个方法是静态的不需要new对象
//valueOf
//将非字符串转换为字符串
String s2 = String.valueOf(true);//true 字符串
System.out.println(s2);
String s3 = String.valueOf(100);//100 字符串
System.out.println(s3);
String s4 = String.valueOf(new C());
System.out.println(s4);//obj.toString 没有重写toString方法之前是对象的内存地址
//println源代码
//底层调用了toString方法
Object obj = new Object();
System.out.println(obj);
/*
String s = String.valueOf(x);
public static String valueOf(Object obj) {
return (obj == null) ? "null" : obj.toString();
}
*/
//本质上System.out.println(),这个方法在输出任何数据的时候都是先转换成字符串,在进行输出
System.out.println();
}
}
class C{
//重写toString
public String toString(){
return "vip";
}
}
StringBuffer和StringBuilder
StringBuffer和StringBuilder为什么是可变的?
StringBuiler和StringBuffer内部实际上是一个byte[]数组,这个byte[]数组没有被final修饰,StringBuilder和StringBuffer的初始化容量为16,当存满之后会进行扩容,底层调用了数组拷贝的方法System.arrarycopy()。所以StringBuilder/StringBuffer适合于字符串频繁拼接操作。
在实际开发当中,频繁的拼接字符串会出现在什么问题?
* java的字符串是不可变的,每一次拼接都会产生一个新的字符串,这样会占用大量的方法去内存,造成内存空间的浪费
* String s = "abc";
* s += "hello"
* 以上两行代码,就导致在方法区字符串常量池中创建了3个字符串对象
1.StringBuffer/StringBuilder可以看做可变长度字符串。
2.StringBuffer/StringBuilder初始化容量16.
3.StringBuffer/StringBuilder是完成字符串拼接操作的,方法名:append
4.StringBuffer是线程安全的。StringBuilder是非线程安全的。
5.频繁进行字符串拼接不建议使用“+”
package StringBuffer;
/**
* 在实际开发当中,频繁的拼接字符串会出现在什么问题?
* java的字符串是不可变的,每一次拼接都会产生一个新的字符串,这样会占用大量的方法去内存,造成内存空间的浪费
* String s = "abc";
* s += "hello"
* 以上两行代码,就导致在方法区字符串常量池中创建了3个字符串对象
*/
/**
* 如果以后想要进行字符串的拼接,那么建议使用JDK中自带的:
* java.lang.StringBuffer/StringBuilder
* 优化StringBuffer性能
* 在创建StringBuffer的时候,尽量给定一个初始化容量
* 最好减少底层数组的扩容次数,预估计一下
* 关键点:给定一个合适的初始化容量,可以提高程序的效率
*
*/
public class Test01 {
public static void main(String[] args) {
//直接使用+=的方法会给方法区中的字符串常量池带来很大的压力
//创建一个初始化容量为16个byte[]数组
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("a");
stringBuffer.append("b");
stringBuffer.append("c");
System.out.println(stringBuffer);
//StringBuffer会自动扩容
//初始化指定容量的StringBuffer
StringBuffer stringBuffer1 = new StringBuffer(100);
stringBuffer1.append("1");
stringBuffer1.append("2");
stringBuffer1.append("3");
stringBuffer1.append("4");
System.out.println(stringBuffer1);
}
}
package StringBuffer;
/**
* StringBuilder
* StringBuffer和StringBuilder的区别
* StringBuffer中的方法,都有关键字synchronized修饰,表示StringBuffer在多线程环境下运行是安全的
* StringBuilder中的方法都没有关键字synchronized修饰,表示StringBuilder在多线程环境下运行是不安全的。
*
* StringBuffer是线程安全的
* StringBuilder是非线程安全的
*/
public class Test02 {
public static void main(String[] args) {
//扩容次数越少,效率越高
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("1");
stringBuilder.append("2");
stringBuilder.append("3");
stringBuilder.append("4");
System.out.println(stringBuilder);
}
}
八种基本数据类型对应的包装类
1.java中为8种基本数据类型有对应准备了8中包装类型。
8中包装类属于引用数据类型,父类是Object
2.为什么提供8中包装类?
因为8种基本数据类型不够用
3.基本数据类型和包装类的对应
基本数据类型:byte、short、int、long、floot、double、boolean、char
8种包装类型:Byte、Short、Integer、Long、Floot、Double(父类都是Number)、Boolean、Character(父类都是Object)
4.8中包装类种其中6个都是数字对应的包装类,他们的父类都是Number,可以先研究一下Number中公共方法:
Number是一个抽象类,无法实例化对象
Number类中有这样的方法:
byte byteValue()以 byte 形式返回指定的数值。
abstract double doubleValue() 以 double 形式返回指定的数值。
abstract float floatValue()以 float 形式返回指定的数值。
abstract int intValue()以 int 形式返回指定的数值。
abstract long longValue()以 long 形式返回指定的数值。
short shortValue() short 形式返回指定的数值。
这些方法是负责拆箱的[把引用数据类型都转换成基本数据类型]
5.装箱和拆箱
package Integer;
/*
关于Integer类的构造方法,有两个:
Integer(int)
Integer(String)
*/
public class Test02 {
public static void main(String[] args) {
//将数字100转换为Integer类型
Integer x = new Integer(100);
System.out.println(x);
//将字符串123转换为Integer类型
Integer y = new Integer("123");
System.out.println(y);
Double d = new Double(1.23);
System.out.println(d);
Double e = new Double(1);
System.out.println(e);
}
package Integer;
/*
在JDK1.5之后支持自动拆箱和自动装箱
*/
public class Test04 {
public static void main(String[] args) {
Integer x = 100;//自动装箱 int类型自动转换为Integer
int y = x;//自动拆箱 Integer自动转换为int
}
}
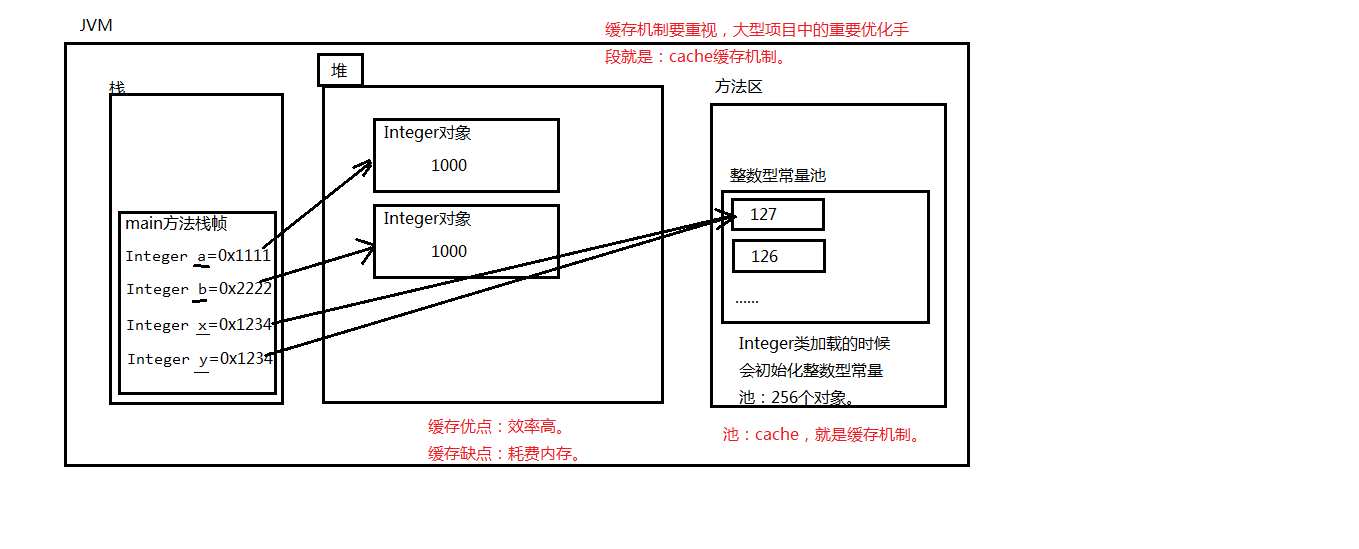
整数型常量池
java中为了提高程序执行效率,将-128-127之间的所有包装对象提前创建好
放到方法区整数型常量池当中,目的是只要用这个区间数据不需要在new,直接从整数型常量池中取出
所遇到异常的总结
空指针异常:NullPointerException
类型转换异常:ClassCastException
数组下标越界异常:ArraryIndexOutOfBoundsException
数组格式化异常:NumberFormatException
package Integer;
/*
总结所遇到的异常:
空指针异常:NullPointerException
类型转换异常:ClassCastException
数组下标越界异常:ArraryIndexOutOfBoundsException
数组格式化异常:NumberFormatException
*/
public class Test05 {
public static void main(String[] args) {
Integer x = 100;
int y = x;
System.out.println(y);
Integer z = new Integer("123");//字符串必须为一串数字,否则会出现数组格式化异常:NumberFormatException
System.out.println(z);
//重点方法
//static int parseInt(String s)
//静态方法,传参String 返回int
int retValue = Integer.parseInt("123");//String ---> int
System.out.println(retValue);
double retValue2 = Double.parseDouble("3.14");
System.out.println(retValue2);
float retValue3 = Float.parseFloat("1.0");
System.out.println(retValue3);
}
}
String int Integer类型转换
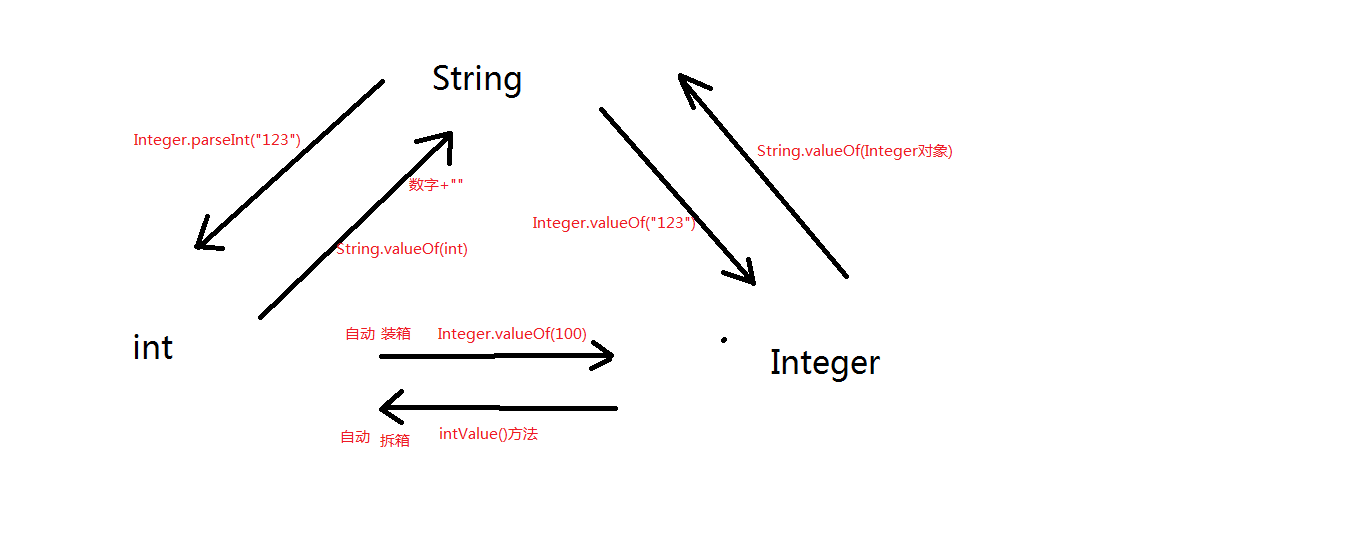
package Integer;
import java.io.StringWriter;
public class Test08 {
public static void main(String[] args) {
String s1 = "100";
int i1 = Integer.parseInt(s1);//String --> int
System.out.println(i1);
String s2 = i1 + ""; //int --> String
System.out.println(s2 +1);
Integer x = 1000;
int y = x; //自动装箱和自动拆箱
String s3 = "123";
Integer k = Integer.valueOf(s3); //Integer ---> String
Integer l = 123;
String s4 = String.valueOf(l);//String --> Integer
}
}
日期类
1.怎么获取当前系统时间
2.Date --> String
3.String --> Date
package Data;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
/*
java中对日期的处理
1.怎么获取当前系统时间
2.Date --> String
3.String --> Date
*/
public class Test01 {
public static void main(String[] args) throws ParseException {
//获取当前系统的时间
Date nowTime = new Date();
System.out.println(nowTime); //Mon Aug 09 09:44:49 CST 2021
//日期格式化,将日期按照指定的格式转换
//将日期按照指定格式进行转换:Date ---> String
//SimpleDateFormat专门负责日期格式化
/**
* yyyy 年
* MM 月
* dd 日
* HH 时
* mm 分
* ss 秒
* SSS 毫秒
* 注意:在日期格式中,除了y M d H m s S这些字符不能随便写之外,剩下的符号格式自己随意组织
*/
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH-mm-ss-SSS");
String nowTimeStr = sdf.format(nowTime);
System.out.println(nowTimeStr);
//日期字符串String,怎么转换成Date
String time = "2020-01-01 00:08:08:888";
//注意:字符串的日期格式和SimpleDateFormat对象指定的日期要相同,不然会出现异常PareException
SimpleDateFormat sdf2 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS");
Date dateTime = sdf2.parse(time);
System.out.println(dateTime);
}
}
统计方法的执行时长
package Data;
/*
自1970年1月1日 00:00:000到当前系统时间的总毫秒数
简单总结一下System类的相关属性和方法:
System.out out是System的静态变量
System.out.println() println()方法不是System类的,是PrintStream类的方法
System.gc() 建议启动垃圾回收器
System.currentTimeMillis() 自1970年1月1日 00:00:000到当前系统时间的总毫秒数
System.exit(0) 退出JVM
*/
public class Test02 {
public static void main(String[] args) {
long nowTimeMillis = System.currentTimeMillis();
System.out.println(nowTimeMillis);
//统计一个方法的耗时
//在调用目标方法之前记录一个毫秒数
long begin = System.currentTimeMillis();
System.out.println(begin);
print();
//执行完调用一个毫秒数
long end = System.currentTimeMillis();
System.out.println(end - begin);
}
//需求:统计一个方法执行所耗费的时长
public static void print(){
for (int i = 0; i < 1000; i++){
System.out.println("i = " + i);
}
}
}
package Data;
import java.text.SimpleDateFormat;
import java.util.Date;
/*
*/
public class Test04 {
public static void main(String[] args) {
//这个时间是:1970-01-01 00:00:00:001
Date time = new Date(1);//注意参数是1毫秒4
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");
String strTime = sdf.format(time);
System.out.println(strTime);
//获取昨天此时的时间
Date time1 = new Date(System.currentTimeMillis() - (1000 * 60 *60 *24));
String strTime2 = sdf.format(time1);
System.out.println(strTime2);
}
}
数字类
DecimalFormat 数字格式化
package Numbers;
import java.text.DecimalFormat;
public class DecimalFormatTest01 {
public static void main(String[] args) {
//专门负责数字格式化
//DecimalFormat df = new DecimalFormat("数字格式");
/**
* 数字格式有哪些
* #代表任意数字
* ,代表千分位
* .代表小数
*
* ###,###,##
* 表示:加入千分位,保留2个小数
*/
DecimalFormat df = new DecimalFormat("###,###.##");
String s = df.format(1234.56);
System.out.println(s);
DecimalFormat df2 = new DecimalFormat("###,###.0000");//保留4个小数,不够补0
String s2 =df2.format(1234.56);
System.out.println(s2);
}
}
BigDecimal 属于大数据,精度极高
财务软件的设计上使用精度高的BigDecimal
package Numbers;
import java.math.BigDecimal;
/*
1.BigDecimal 属于大数据,精度极高。不属于基本数据类型,属于java对象(引用数据)
这是SUN提供的一个类。专门用在财务软件中
2.注意:财务软件中Double是不够用的
财务数据是java.math.BigDecimal
*/
public class BigDecimalTest01 {
public static void main(String[] args) {
//这个100不是普通的100,是精度极高的100
BigDecimal v1 = new BigDecimal(100);
BigDecimal v2 = new BigDecimal(200);
//求和
//v1 + v2 都是引用数据类型不可以使用这个语法
//调用方法求和
BigDecimal v3 =v1.add(v2);
System.out.println(v3);
BigDecimal v4 = v2.divide(v1);
System.out.println(v4);
}
}
Random生成随机数
怎么产生int类型随机数。
Random r = new Random();
int i = r.nextInt();
怎么产生某个范围之内的int类型随机数。
Random r = new Random();
int i = r.nextInt(101); // 产生[0-100]的随机数。
package Numbers;
import java.util.Random;
import java.util.Arrays;
/*
编写程序,生成5个不重复的随机数。重复的话重新生成
最终生成的5个随机数,放入数组里面,要求这五个随机数不重复
*/
public class RandomTest02 {
public static void main(String[] args) {
//准备一个长度为5的一维数组
int[] arr = new int[5];
for (int i =0; i< 5 ; i++){
arr[i] = -1;
}
int index = 0;
//循环
Random random = new Random();
while(index < arr.length){
int res = random.nextInt(101);
boolean flag = flag(arr,res);
if (!flag){
arr[index++] = res;
}
}
for (int i =0;i<arr.length;i++){
System.out.println(arr[i]);
}
}
public static boolean flag(int[] arr,int res) {
/*
这个方法存在bug,有一半的数据不可以用
//排序
Arrays.sort(arr);
//二分法查找 元素所在的下标
int index = Arrays.binarySearch(arr, res);
return index >0 ;//证明存在
*/
for (int i = 0;i<arr.length;i++){
if (arr[i] ==res){
return true;
}
return false;
}
return false;
}
}
Enum枚举类型
枚举是一种引用数据类型。
枚举编译之后也是class文件。
枚举类型怎么定义?
enum 枚举类型名{
枚举值,枚举值2,枚举值3
}
枚举的使用情况
当一个方法执行结果超过两种情况,并且是一枚一枚可以列举出来的时候,建议返回值类型设计为枚举类型。
package enumlei;//关键字不可以做标识符
/*
分析以下程序的缺陷,没有使用枚举类型
以下程序可以编译运行,程序本身没有问题
设计缺陷:这个方法的返回值类型不恰当,这个方法只是返回成功和失败,那么最好返回布尔类型,返回值已经偏离了需求。
*/
public class Test01 {
public static void main(String[] args) {
boolean res = divide(10,2);
System.out.println(res);
boolean res2 = divide(10,0);
System.out.println(res2);
}
/**
* 以下程序计算两个int类型的商,计算成功返回1,计算失败返回0
* @param a
* @param b
* @return 返回1表示成功,0表示失败
*/
/*
public static int divide(int a,int b){
try{
int c= a/b;
return 1;//表示执行成功
}catch (Exception e){
return 0;//表示执行失败
}
}*/
public static boolean divide(int a,int b) {
try {
int c = a / b;
return true;//表示执行成功
} catch (Exception e) {
return false;//表示执行失败
}
}
/*
思考:以上的方法设计没毛病,但是在以后的开发过程中,有可能遇到一个方法的执行结果可能包括几种情况
这时布尔类型就无法满足需求,这是需要使用java中的枚举类型
*/
}
package enumlei;
/*
枚举:
1.枚举是一种引用数据类型
2.枚举怎么定义
enum 枚举类型名{
枚举值1,枚举值2
}
3.只有两种类型建议使用布尔类型,超过两种的建议使用枚举类型
*/
public class Test02 {
public static void main(String[] args) {
Result r = divide(10,2);
System.out.println(r == Result.SUCCESS? "Sucess":"Fail");
}
/**
*
* @param a
* @param b
* @return 返回枚举类型,SUCCESS表示成功,FAIL表示失败
*/
public static Result divide(int a,int b ){
try{
int c = a/b;
return Result.SUCCESS;
}catch(Exception e){
return Result.FAIL;
}
}
}
//枚举
enum Result{
//枚举编译成功之后也是生成class文件
//枚举也是一种引用数据类型
//枚举中的每一个值,可以看作是常量
//SUCCESS是枚举类中的一个值
//FAIL 也是枚举中的一个值
SUCCESS,FAIL
}
异常类
异常处理机制
0.1、java中异常的作用是:增强程序健壮性。
0.2、java中异常以类和对象的形式存在。
1.什么是异常,java提供异常处理机制有什么用?
以下程序执行过程中发生了不正常的情况,而这种不正常的情况叫做异常
java语言是十分完善的,提供了异常处理方式,以下程序出现了不正常的情况,java把该异常信息打印,
输出到控制台,供程序员参考。程序员看到异常信息之后,可以对程序进行修改,让程序更加健壮
2.以下程序执行控制台出现了:
Exception in thread “main” java.lang.ArithmeticException: / by zero
at exception.Test01.main(Test01.java:7)
这个信息我们称为:异常信息,这个信息是JVM打印的
package exception;
/*
1.什么是异常,java提供异常处理机制有什么用?
以下程序执行过程中发生了不正常的情况,而这种不正常的情况叫做异常
java语言是十分完善的,提供了异常处理方式,以下程序出现了不正常的情况,java把该异常信息打印,
输出到控制台,供程序员参考。程序员看到异常信息之后,可以对程序进行修改,让程序更加健壮
2.以下程序执行控制台出现了:
Exception in thread "main" java.lang.ArithmeticException: / by zero
at exception.Test01.main(Test01.java:7)
这个信息我们称为:异常信息,这个信息是JVM打印的
*/
public class Test01 {
public static void main(String[] args) {
/* int a =10;
int b =0;
int c= a/b; // 实际上JVM执行到此处时会new一个异常对象
System.out.println(c);*/
}
}
3.Java语言中异常是以什么形式存在的
异常在Java中以类的形式存在,每一个异常类都可以创建异常对象
package exception;
import lei.NullPointerTest;
/*
Java语言中异常是以什么形式存在的
异常在Java中以类的形式存在,每一个异常类都可以创建异常对象
*/
public class Test02 {
public static void main(String[] args) {
NumberFormatException nfe = new NumberFormatException("数字格式化异常");
//也会调用toString
System.out.println(nfe);
//通过异常类,创建异常对象
NullPointerException npe = new NullPointerException("空指针异常");
System.out.println(npe);
}
}
4.java的异常的继承结构
异常在java中以类和对象的形式存在。那么异常的继承结构是怎样的?
我们可以使用UML图来描述一下继承结构。
画UML图有很多工具,例如:Rational Rose(收费的)、starUML等…
Object
Object下有Throwable(可抛出的)
Throwable下有两个分支:Error(不可处理,直接退出JVM)和Exception(可处理的)
Exception下有两个分支:
Exception的直接子类:编译时异常(要求程序员在编写程序阶段必须预先对这些异常进行处理,如果不处理编译器报错,因此得名编译时异常。)。
RuntimeException:运行时异常。(在编写程序阶段程序员可以预先处理,也可以不管,都行。)
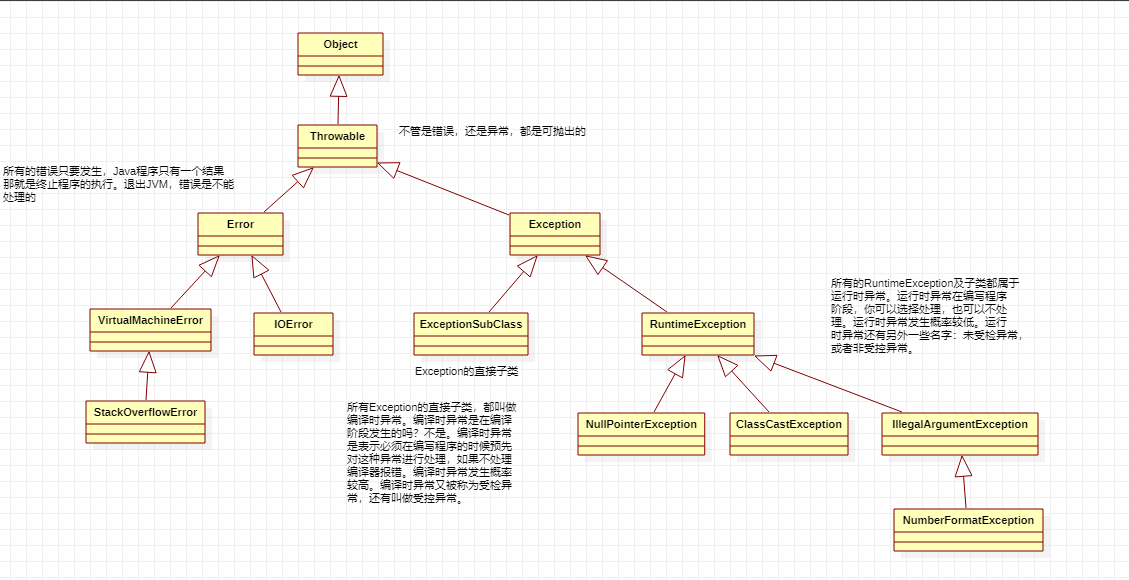
5.编译时异常和运行时异常
编译时异常和运行时异常,都是发生在运行阶段。编译阶段异常是不会发生的。
编译时异常因为什么而得名?
因为编译时异常必须在编译(编写)阶段预先处理,如果不处理编译器报错,因此得名。所有异常都是在运行阶段发生的。因为只有程序运行阶段才可以new对象。因为异常的发生就是new异常对象。
编译时异常和运行时异常的区别
编译时异常一般发生的概率比较高。对于一些发生概率较高的异常,需要在运行之前对其进行预处理。
运行时异常一般发生的概率比较低。
假设java中没有对异常进行划分,没有分为:编译时异常和运行时异常,所有的异常都需要在编写程序阶段对其进行预处理,将是怎样的效果呢?
首先,如果这样的话,程序肯定是绝对的安全的。但是程序员编写程序太累,代码到处都是处理异常的代码。
编译时异常还有其他名字:受检异常:CheckedException 受控异常
运行时异常还有其它名字:未受检异常:UnCheckedException 非受控异常
6.java对异常处理的两种方式
第一种方式:在方法声明的位置上,使用throws关键字抛给上一级。
谁调用我,我就抛给谁。抛给上一级。
第二种方式:使用try…catch语句进行异常的捕捉,这件事发生了,谁也不知道,因为我给抓住了。
举个例子:
我是某集团的一个销售员,因为我的失误,导致公司损失了1000元,
“损失1000元”这可以看做是一个异常发生了。我有两种处理方式,
第一种方式:我把这件事告诉我的领导【异常上抛】
第二种方式:我自己掏腰包把这个钱补上。【异常的捕捉】
思考:
异常发生之后,如果我选择了上抛,抛给了我的调用者,调用者需要对这个异常继续处理,那么调用者处理这个异常同样有这两种处理方式。
注意:Java中异常发生之后如果一直上抛,最终抛给了main方法,main方法继续向上抛,抛给了调用者JVM,JVM知道这个异常发生,只有一个结果。终止java程序的执行。
package exception;
public class Test03 {
public static void main(String[] args) {
System.out.println(100/0);
/*
程序执行到此处,发生了一个ArithmeticException异常,底层new了一个ArithmeticException异常对象,然后抛出了,由于是main方法调用了100/0,
所以这个异常ArithmeticException抛给了main方法,main方法没有处理,直接抛给了JVM,JVM最终终止了程序的执行。
ArithmeticException继承了RuntimeException,属于运行时异常,在编写阶段不需要进行异常的预先处理
*/
System.out.println("Hello Word");
}
}
编译时异常的报错
package exception;
/*
以下代码报错的原因是什么?
doSome方法声明位置上使用了:throws ClassNotFoundExcption,ClassNotFoundExcption是编译时异常,必须在编写代码时进行异常处理,否则报错。
*/
public class Test04 {
public static void main(String[] args) throws ClassNotFoundException {
//main方法中直接调用了doSome方法
//因为doSome方法声明位置上有:throws ClassNotFoundExcption
//我们调用doSome方法的时候必须对这种异常进行预先的处理,如果不处理,编译器报错
doSome();
}
/**
* doSome方法在方法声明的位置上使用了:throws ClassNotFoundExcption
* 这个代码表示doSome()方法执行过程中,有可能会出现ClassNotFoundExcption异常
* @throws ClassNotFoundException 类没有找到异常,父类为Exception,所以该异常属于编译时异常
*/
public static void doSome() throws ClassNotFoundException{
System.out.println("doSome");
}
}
两种处理方法
package exception;
public class Test05 {
//第一种处理方式:在方法声明的位置上继续使用:throws,来完成异常的上抛。抛给调用者
/*public static void main(String[] args) throws ClassNotFoundException {
doSome();
}*/
//第二种处理方式:try catch
//捕捉意味着把异常拦下了,把异常真正的解决了
public static void main(String[] args) {
try {
doSome();
}catch (ClassNotFoundException e){
e.printStackTrace();
}
}
public static void doSome() throws ClassNotFoundException{
System.out.println("doSome");
}
}
package exception;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/*
处理异常的第一种方式:在方法声明的位置上使用throws关键字抛出,谁调用这个方法,我就抛给谁
*/
public class Test06 {
/*
一般不建议在main方法上使用throws,因为这个异常如果真的发生了,一定会抛给JVM,那么JVM会终止程序的执行
异常处理机制的作用就是增强程序的健壮性,异常发生了也不会影响程序的执行,所以一般main方法中的异常建议使用try catch进行捕捉
main就不会继续上抛
*/
public static void main(String[] args) {
System.out.println("main begin");
try {
m1();
//出异常,这里不会执行
System.out.println("Hello Word");
} catch (FileNotFoundException e) {
System.out.println(e);
System.out.println("文件不存在");
}
System.out.println("main end");
}
public static void m1() throws FileNotFoundException{
System.out.println("m1 begin");
m2();
//出异常,这里不会执行
System.out.println("m2 end");
}
//抛FileNotFoundException的父类IOException,这样可以,因为IOException包括FileNotFoundException。
//throws可以抛出多个异常,可以使用逗号隔开
public static void m2() throws FileNotFoundException{
System.out.println("m2 begin");
m3();
//第二种方法进行捕捉
/*try {
m3();
} catch (FileNotFoundException e) {
System.out.println("该文件不存在");
}*/
//出异常,这里不会执行
System.out.println("m2 end");
}
//第一种方法继续上抛
public static void m3() throws FileNotFoundException {
System.out.println("m3 begin");
/*
编译报错的原因是什么?
第一:这里调用了一个构造方法:FileInputStream
第二:这个构造方法的声明位置上有:throws FileNotFoundException
第三:通过类的继承结构看到:FileNotFoundException 的父类为IOException,IOException的父类为Exception最终得知,
FileNotFoundException是编译时异常
编译时异常,要求程序员必须在编译过程中对他进行处理。
*/
//FileInputStream fileInputStream = new FileInputStream("C:\\Users\\77\\Downloads\\Documents\\07-JavaSE进阶每日复习与笔记\\11.txt");
FileInputStream fileInputStream = new FileInputStream("C:\\Users\\77\\Downloads\\Documents\\07-JavaSE进阶每日复习与笔记\\1.txt");
//出异常这里不会执行
System.out.println("m3 end");
}
}
try catch
1.catch语句块后面()可以写本身的类型,也可以写父类型
2.catch可以写多个,建议catch的时候一个一个精确的处理
3.catch写多个的时候,必须遵循从上到下,从小到大
4.catch (FileNotFoundException | ArithmeticException e) JDK8的新特性
package exception;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/*
try catch
1.catch语句块后面()可以写本身的类型,也可以写父类型
2.catch可以写多个,建议catch的时候一个一个精确的处理
3.catch写多个的时候,必须遵循从上到下,从小到大
4.catch (FileNotFoundException | ArithmeticException e) JDK8的新特性
*/
public class Test07 {
public static void main(String[] args) {
try {
FileInputStream fileInputStream = new FileInputStream("C:\\Users\\77\\Downloads\\Documents\\07-JavaSE进阶每日复习与笔记\\11.txt");
fileInputStream.read();//需要处理IO异常
System.out.println(100/0);//运行时异常,编译时可以处理可以不处理
} catch (FileNotFoundException | ArithmeticException e) {
e.printStackTrace();
System.out.println("文件不存在");
}catch (IOException e){
e.printStackTrace();
}
/*try {
FileInputStream fileInputStream = new FileInputStream("C:\\Users\\77\\Downloads\\Documents\\07-JavaSE进阶每日复习与笔记\\11.txt");
} catch (IOException e) {//多态
e.printStackTrace();
System.out.println("文件不存在");
}*/
System.out.println("后续代码可以执行");
}
}
异常的两个方法
package exception;
/*
异常对象有两个非常重要的方法:
获取异常简单的描述信息:
String msg = exception.getMessage();
打印异常追踪的堆栈信息:
exception.printStackTrace();
*/
public class Test08 {
public static void main(String[] args) {
//这里只是new了异常对象,没有将异常对象抛出,JVM认为这只是一个普通的Java对象
NullPointerException e = new NullPointerException("空指针异常");
//获取异常信息,这个信息实际上就是构造方法
System.out.println(e.getMessage());
//打印异常堆栈信息
//两个线程来分别进行下面两个指令
e.printStackTrace();
System.out.println("可以正常执行");
}
}
finally语句块
关于try catch中的finally子句:
1.在finally子句中的代码是最后执行的,是一定会执行的,即使try语句块中的代码出现了异常,finally语句必须和try一起出现,不能单独编写
2.finally语句通常使用在哪些情况下?
finally语句块中完成资源的释放/关闭
因为finally中的的代码比较有保障。
即使try语句块中的代码出现异常,finally中的代码块也会正常执行
package exception;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/*
关于try catch中的finally子句:
1.在finally子句中的代码是最后执行的,是一定会执行的,即使try语句块中的代码出现了异常
finally语句必须和try一起出现,不能单独编写
2.finally语句通常使用在哪些情况下?
finally语句块中完成资源的释放/关闭
因为finally中的的代码比较有保障。
即使try语句块中的代码出现异常,finally中的代码块也会正常执行
*/
public class Test10 {
public static void main(String[] args) throws IOException {
//设置为全局变量
FileInputStream fileInputStream = null;
try {
//创建输入流对象
//这里的fileInputStream是一个局部变量
fileInputStream = new FileInputStream("C:\\Users\\77\\Downloads\\Documents\\07-JavaSE进阶每日复习与笔记\\11.txt");
String s= null;
s.toString(); //会出现空指针异常
System.out.println("3");
//即使以上程序出现异常,流也必须关闭,放在当前位置有可能不会关闭
//fileInputStream.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
}catch (IOException e){
e.printStackTrace();
}catch (NullPointerException e){
e.printStackTrace();
}finally {
System.out.println("1");
//流的关闭放在这比较保险
if (fileInputStream != null){
//close方法有异常采用捕捉的方式
try {
fileInputStream.close();
}catch (IOException e){
e.printStackTrace();
}
System.out.println("2");
}
}
}
}
return,之后的finally也会执行
package exception;
public class Test11 {
public static void main(String[] args) {
/*
try和finally,没有catch
try不能单独使用
try finally可以联合使用
*/
try{
System.out.println("try");
return;
}finally {
//有return,finally也会执行
System.out.println("finally");
}
//如果有return
//这里不能写语句,这个代码是无法执行到的
//System.out.println("1");
}
}
退出exit后,finally不执行
package exception;
public class Test12 {
public static void main(String[] args) {
try{
System.out.println("try");
System.exit(0);
//退出JVM finally不执行
}finally{
System.out.println("finally");
}
}
}
面试题finally
package exception;
/*
finally面试题
*/
public class Test13 {
public static void main(String[] args) {
int res = m();
System.out.println(res);//100
}
/*
java语法规则(有一些规则是不能破坏的)
java中有一条这样的规则:
方法体中的代码必须遵循自上而下顺序依次逐行执行
*/
public static int m(){
int i = 100;
try{
//这行代码出现在int i = 100;的下面,所以最终结果必须是返回100
// return语句还必须保证是最后执行的,一旦执行,整个方法结束
return i;
}finally {
i++;
}
}
}
/*
反编译之后的效果
public static int m(){
int i = 100;
int j = i;
i ++;
return j;
Exceptrion exception;
exception;
i++;
throw exception;
}
*/
finally final finalize 的区别
final 关键字
final修饰的类无法继承
final修饰的变量无法修改
final修饰的方法无法覆盖
finally 关键字
finally和try连用
finally语句块中的代码必须执行
finalize 方法
是Object类中的一个方法名
这个方法是由垃圾回收器GC负责调用的
package exception;
/*
final 关键字
final修饰的类无法继承
final修饰的变量无法修改
final修饰的方法无法覆盖
finally 关键字
finally和try连用
finally语句块中的代码必须执行
finalize 方法
是Object类中的一个方法名
这个方法是由垃圾回收器GC负责调用的
*/
public class Test14 {
public static void main(String[] args) {
//final是一个关键字,表示最终的不变的
final int i =100;
//finally也是一个关键字,和try联合使用,使用在异常处理机制中
//finally语句块中的代码是一定会执行的
try{
}finally {
System.out.println("finally");
}
//finalize()是Object类中的一个方法。作为方法名出现
//所以finalize是标识符
}
}
自定义异常类
1.可以进行自定义异常
2.自定义异常的步骤:
第一步:编写一个类继承exception或者RuntimeException
第二步:提供两个构造方法,一个无参数的,一个带有String参数的
package exception;
/*
1.可以进行自定义异常
2.自定义异常的步骤:
第一步:编写一个类继承exception或者RuntimeException
第二步:提供两个构造方法,一个无参数的,一个带有String参数的
*/
public class Test15 {
public static void main(String[] args) {
//创建异常对象(没有手动抛出异常)
MyException myException = new MyException("no");
//打印异常信息
myException.printStackTrace();
String msg = myException.getMessage();
System.out.println(msg);
}
}
class MyException extends Exception{
public MyException() {
}
public MyException(String message) {
super(message);
}
}
异常在实际开发中的应用

package exception;
//测试改良之后的栈
public class Test16 {
public static void main(String[] args) {
Mystack mystack = new Mystack();
//压栈
try {
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
} catch (MyStackOperationException e) {
System.out.println(e.getMessage());
}
//弹栈
try {
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
} catch (MyStackOperationException e) {
e.printStackTrace();
}
}
}
package exception;
//测试改良之后的栈
public class Test16 {
public static void main(String[] args) {
Mystack mystack = new Mystack();
//压栈
try {
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
mystack.push(new Object());
} catch (MyStackOperationException e) {
System.out.println(e.getMessage());
}
//弹栈
try {
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
mystack.pop();
} catch (MyStackOperationException e) {
e.printStackTrace();
}
}
}
方法覆盖时的异常处理
package exception;
/*
之前在讲解方法覆盖的时候,遗留了一个问题
重写之后的方法不能比重写之前的方法抛出更多的异常,可以更少
*/
public class Test17 {
}
class A{
public void doSome(){}
public void doOtger() throws Exception{}
}
class B extends A{
/*public void doSome() throws Exception{ //父类没有抛出异常,子类不可以抛
}*/
/*编译正常
public void doOther(){ //不抛出异常不报错
}*/
/*编译正常
public void doOther() throws Exception{
}*/
/*编译正常
public void doOther() throws NullPointerException{
}
*/
}
总结异常关键字
总结异常的关键字:
异常捕捉:
try
catch
finally
throws 在方法声明位置上使用,表示上报异常信息给调用者
throw 手动抛出异常
集合
通过集合的构造方法可以完成类型的转换
集合的概述
1.什么是集合?有什么用?
数组起始就是一个集合,集合实际上就是一个容器,可以用来容纳其他类型的数据
集合为什么说在开发中使用较多?
集合是一个容器,是一个载体,可以一次容纳多个对象。在实际开发中,假设连接数据库,数据库当中有十条记录,那么假设把这10条记录查询出来,在java程序中会将10条数据封装成10个Java对象,然后将10个Java对象放到某一个 集合当中,将集合传到前端,然后遍历,将一个个数据展现出来
2.集合中存储的为引用数据类型
集合不能直接存储基本数据另类。另外集合也不能直接存储Java对象,集合当中存储的是Java对象的内存地址(或者说集合存储的是引用)
注意:集合在Java中本身是一个容器,引用对象
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1DyNs7od-1634041323688)(C:/Users/77/Downloads/Documents/09-JavaSE进阶每章课堂画图/05-集合/001-集合中存储的是对象的内存地址.png)]
3.不同的集合对饮不同的数据结构
在Java中每一个不同的集合,底层会对应不同的数据结构,往不同的集合中存储元素,等于将数据放到了不同的数据结构当中,什么是数据结构?数据存储的结构就是数据结构,不同的数据结构,数据存储方式不同。例如:数组,二叉树,链表,哈希表,以上都是常见的数据结构。
你往集合c1中放数据,可能是放到数组上了。
你往集合c2中放数据,可能是放到二叉树上了。
…
你使用不同的集合等同于使用了不同的数据结构
你在java集合这一章节,你需要掌握的不是精通数据结构。java中已经将数据结构实现了,已经写好了这些常用的集合类,你只需要掌握怎么用?在什么情况下选择哪一种合适的集合去使用即可。
new ArrayList(); 创建一个集合,底层是数组。
new LinkedList(); 创建一个集合对象,底层是链表。
new TreeSet(); 创建一个集合对象,底层是二叉树。
…
4.集合在java JDK中哪个包下?
java.util.*; 所有的集合类和集合接口都在java.util下
5.集合的继承结构图
一类是单个方式存储元素:
单个方式存储元素,这一类集合中超级父接口:java.util.Collection;
一类是以键值对儿的方式存储元素
以键值对的方式存储元素,这一类集合中超级父接口:java.util.Map;

Map接口
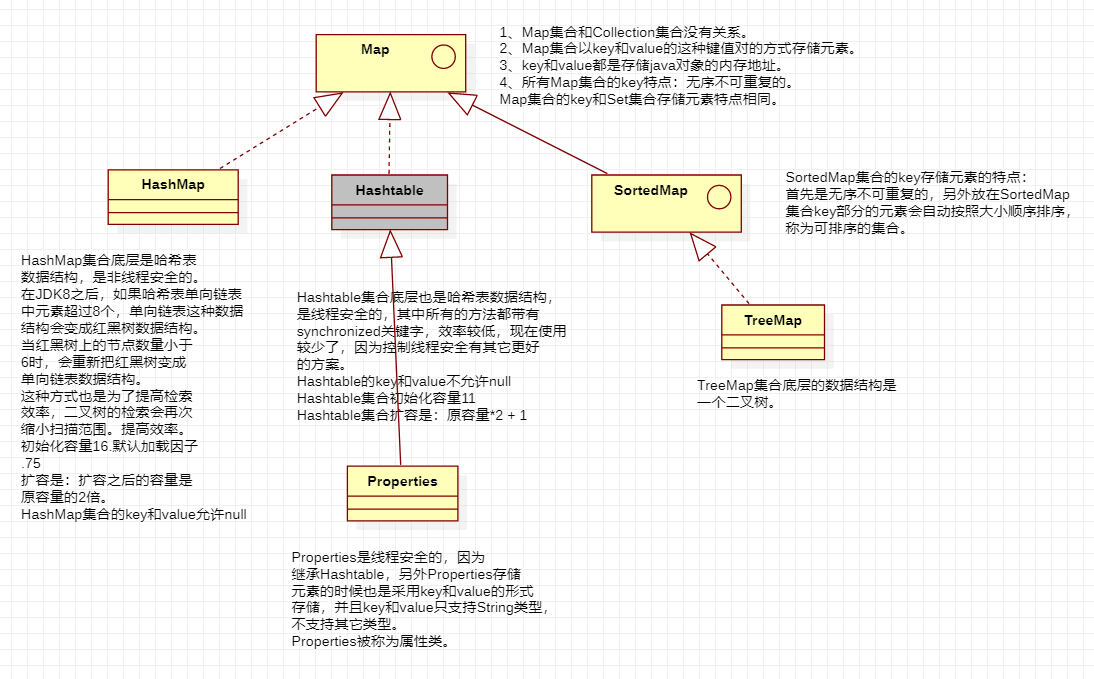
总结 :
ArrayList:底层是数组
LinkedList:底层是双向链表
Vector:底层是数组,线程安全的,效率较低,使用较少
HashSet:底层是HashMap,放到HashSet集合中的元素等同于放到HashMap集合Key部分了
TreeSet:底层是TreeMap,放到TreeMap结合中的元素等同于放到TreeMap集合key部分
HashMap:底层是哈希表数据结构
HashTable:底层也是哈希表,只不过效率较低,使用较少
Properties:是线程安全的,并且key和value只能存储字符串
TreeMap:底层是二叉树,TreeMap集合的key可以自动按照大小顺序排序
List集合存储元素的特点:有序可重复
有序:存进去的顺序和取出的顺序相同,每一个元素都有下标
可重复:存进去1,还可以存进去1
Set集合存储元素的特点:无序不可重复
无序:存进去的顺序和取出的顺序不一定相同,另外Set集合中元素没有下标
不可重复
SortedSet(SortedMap):无序不可重复,但是SortedSet中的元素是可排序的
Map集合中的key,就是一个Set集合
往Set集合中放数据,就是放到Map集合的key部分
Collection接口中的常用方法
1.Collection中能存放什么元素?
没有使用泛型之前,Collection中可以存储Object的所有子类型
使用“泛型”之后,Collection中只能存储某个具体类型
集合后期我们会学习“泛型”,Collection中什么都能存,只要Object子类型都行
(集合中不能直接存储基本数据类型,也不能存储Java对象,只存储Java对象的内存地址)
2.Collection中的常用方法
boolean add(Object e) add方法,向集合中添加元素
int size() 获取集合中元素的个数
void clear() 清空集合
boolean contains(Object o) 判断当前集合中是否包含元素o,包含返回true,不包含返回false
boolean remove(Object o) 删除集合中某个元素
boolean isEmpty() 判断集合中元素的个数是否为0
Object[] toArray() 调用这个方法可以把集合转换成数组
Iterator iterator() 返回在此 collection 的元素上进行迭代的迭代器。
package collection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/*
关于collection接口中的常用方法
1.Collection中能存放什么元素?
没有使用泛型之前,Collection中可以存储Object的所有子类型
使用“泛型”之后,Collection中只能存储某个具体类型
集合后期我们会学习“泛型”,Collection中什么都能存,只要Object子类型都行
(集合中不能直接存储基本数据类型,也不能存储Java对象,只存储Java对象的内存地址)
2.Collection中的常用方法
boolean add(Object e) add方法,向集合中添加元素
int size() 获取集合中元素的个数
void clear() 清空集合
boolean contains(Object o) 判断当前集合中是否包含元素o,包含返回true,不包含返回false
boolean remove(Object o) 删除集合中某个元素
boolean isEmpty() 判断集合中元素的个数是否为0
Object[] toArray() 调用这个方法可以把集合转换成数组
Iterator<E> iterator() 返回在此 collection 的元素上进行迭代的迭代器。
*/
public class Test01 {
public static void main(String[] args) {
//创建一个集合对象
//Collection c = new Collection(); 接口是抽象的,无法实例化
Collection c = new ArrayList();//多态
//add方法,向集合中添加元素
c.add(1200);//自动装箱,实际上是放进去了一个对象的内存地址。Integer x = new Integer(1200);
c.add(3.14);
c.add(new Object());
c.add(true);
System.out.println(c.size());
System.out.println("------------");
//清空集合
c.clear();
System.out.println(c.size());
c.add("hell0"); //hello对象的内存地址放入了集合当中
c.add("world");
c.add("h");
c.add("lv");
c.add(1);
//判断集合中是否包含
boolean flag = c.contains("h");
System.out.println(flag);
boolean flag2 = c.contains("1h");
System.out.println(flag);
System.out.println("------------");
System.out.println(c.size());
System.out.println("------------");
c.remove(1);
System.out.println(c.size());
System.out.println("------------");
//判断集合是否为空
System.out.println(c.isEmpty());
c.clear();
System.out.println(c.isEmpty());
System.out.println("------------");
c.add("abc");
c.add(1);
c.add(2);
c.add("world");
Object[] objs = c.toArray(); //把集合转换为数组
for (int i = 0; i<objs.length;i++){
System.out.println(objs[i]);
}
}
}
3.关于集合遍历/迭代器
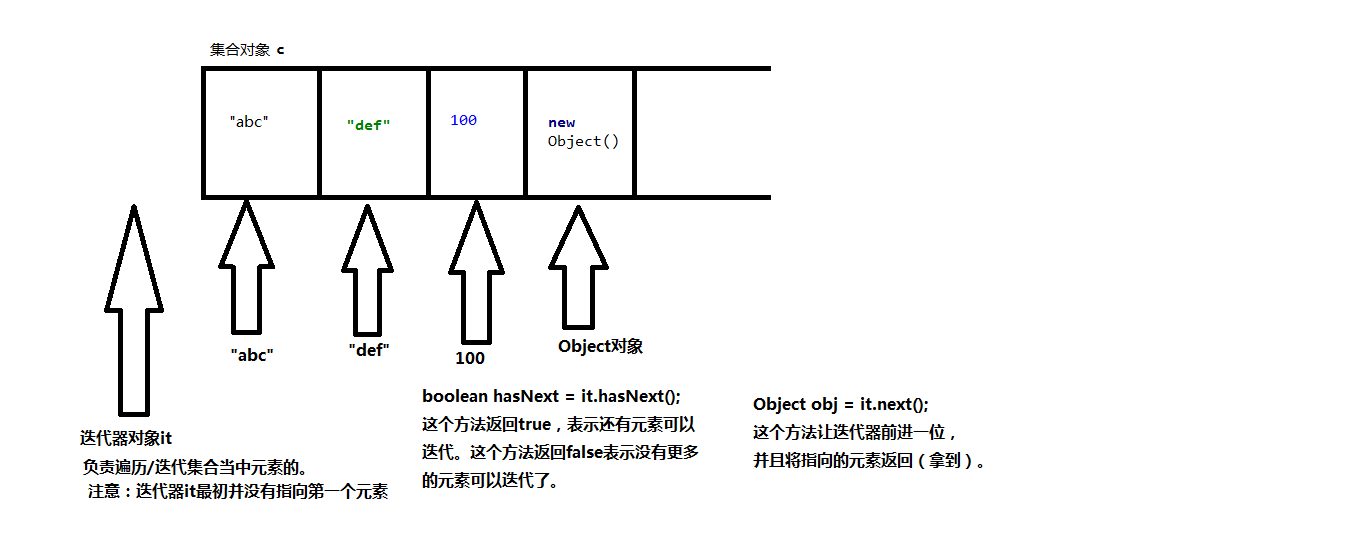
第一步:获取集合的迭代器对象Iterator
第二步:通过以上的迭代器对象开始迭代/遍历集合
package collection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
/**
* 关于集合遍历/迭代器
*
*/
public class Test02 {
public static void main(String[] args) {
//以下遍历方式/迭代方式,是所有的Collection通用的一种方式
//在Map集合中不能使用,在所有Collection以及子类中使用
//创建集合对象
Collection c = new ArrayList();
//添加元素
c.add("abc");
c.add(10);
c.add(2);
c.add("world");
//遍历/迭代
//第一步:获取集合的迭代器对象Iterator
Iterator iterator = c.iterator();
//第二步:通过以上的迭代器对象开始迭代/遍历集合
/*
以下方法是迭代器Iterator中的方法
boolean hasNext()
如果仍有元素可以迭代,则返回 true。
E next()
返回迭代的下一个元素。
*/
while(iterator.hasNext()){
Object obj = iterator.next();
System.out.println(obj);
}
}
}
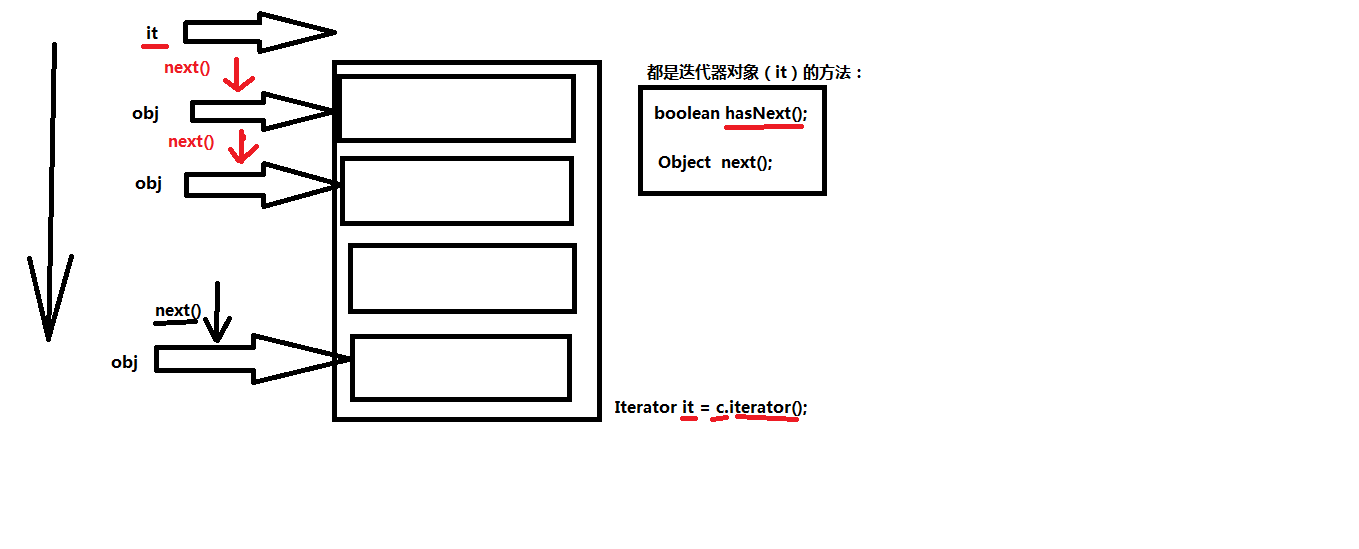
4.contains方法
boolean contains(Object o)
判断集合是否包含某个对象o
如果包含返回true,如果不包含返回flase
package collection;
import java.util.ArrayList;
import java.util.Collection;
/*
深入Collection集合的contains方法
boolean contains(Object o)
判断集合是否包含某个对象o
如果包含返回true,如果不包含返回flase
*/
public class Test04 {
public static void main(String[] args) {
//创建集合
Collection c = new ArrayList();
//向集合中存储元素
String s1 = new String("abc");
String s2 = new String("def");
c.add(s1);
c.add(s2);
System.out.println(c.size());
//String类已经重写了equals
String x= new String("abc");
System.out.println(c.contains(x));
//contains 底层调用了equals方法 ,String的equals方法已经重写了
}
}
4.放在集合里的类,需要重写equals方法
contains也重写equals方法
package collection;
import java.util.ArrayList;
import java.util.Collection;
/*
测试contains方法
*/
public class Test05 {
public static void main(String[] args) {
//创建集合对象
Collection c = new ArrayList();
User u1 = new User("j");
User u2 = new User("h");
c.add(u1);
c.add(u2);
//这里的class类没有重写equals方法
//所以contains方法为false
//重写了equals方法之后,返回true
User u3 = new User("j");
boolean flag = c.contains(u3);
System.out.println(flag);
}
}
class User{
private String name;
public User() {
}
public User(String name) {
this.name = name;
}
//重写equals方法
//这个equals的比较原理是,String name一样就可以
@Override
public boolean equals(Object o) {
if (o == null || ! (o instanceof User))return false;
if (o == this) return true;
User user = (User) o;
return user.name == this.name;
}
}
remove中也重写了equals方法
package collection;
import java.util.ArrayList;
import java.util.Collection;
/*
测试contains方法
测试remove方法
*/
public class Test05 {
public static void main(String[] args) {
//创建集合对象
Collection c = new ArrayList();
User u1 = new User("j");
User u2 = new User("h");
c.add(u1);
c.add(u2);
//这里的class类没有重写equals方法
//所以contains方法为false
//重写了equals方法之后,返回true
User u3 = new User("j");
boolean flag = c.contains(u3);
System.out.println(flag);
Collection collection = new ArrayList();
String s1 = new String("C");
String s2 = new String("C");
collection.add(s1);
//remove底层也调用了equals方法
//s1和s2是相同的
collection.remove(s2);
System.out.println(collection.size());
}
}
class User{
private String name;
public User() {
}
public User(String name) {
this.name = name;
}
//重写equals方法
//这个equals的比较原理是,String name一样就可以
@Override
public boolean equals(Object o) {
if (o == null || ! (o instanceof User))return false;
if (o == this) return true;
User user = (User) o;
return user.name == this.name;
}
}
5.remove方法中的迭代器
重点:当集合的结构发生改变时,迭代器必须重新获取,如果不重新获取迭代器那么就会出现异常ConcurrentModificationException。
Collection c = new ArrayList();
//此时获取的迭代器,指向的是那是集合中没有元素状态下的迭代器
//一定要注意:集合结构只要发生改变,迭代器就必须重新获取
//Iterator iterator = c.iterator();
c.add(1);
c.add(2);
c.add(3);
//迭代器没有重新获取那么会出现:ConcurrentModificationException异常
重点:在迭代集合元素过程中,不能调用集合对象的remove方法,删除元素;会出现ConcurrentModificationException。
Iterator iterator1 = c2.iterator();
while(iterator1.hasNext()){
Object o = iterator1.next();
//c2.remove(o); 直接通过集合去删除元素,没有通知迭代器(导致迭代器的快照和原集合状态不同)
//删除元素之后,集合的结构发生了变化,应该重新去获取迭代器,
//但是,循环下一次的时候并没有重新获取迭代器,所以会出现异常
//使用迭代器来删除,不会出现异常
//迭代器删除时,会自动更新迭代器并且更新集合(删除集合中的元素)
iterator1.remove();//删除的一定是迭代器当前指向的元素
System.out.println(o);
}
package collection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/*
关于集合的remove
重点:当集合的结构发生改变时,迭代器必须重新获取,如果不重新获取迭代器
那么就会出现异常ConcurrentModificationException。
重点:在迭代集合元素过程中,不能调用集合对象的remove方法,删除元素;
会出现ConcurrentModificationException。
*/
public class Test06 {
public static void main(String[] args) {
Collection c = new ArrayList();
//此时获取的迭代器,指向的是那是集合中没有元素状态下的迭代器
//一定要注意:集合结构只要发生改变,迭代器就必须重新获取
//Iterator iterator = c.iterator();
c.add(1);
c.add(2);
c.add(3);
//迭代器没有重新获取那么会出现:ConcurrentModificationException异常
Iterator iterator = c.iterator();
while(iterator.hasNext()){
//编写代码是next方法必须返回Object
Object i = iterator.next();
System.out.println(i);
}
System.out.println("-----");
Collection c2 = new ArrayList();
c2.add("a");
c2.add("b");
c2.add("c");
Iterator iterator1 = c2.iterator();
while(iterator1.hasNext()){
Object o = iterator1.next();
//c2.remove(o); 直接通过集合去删除元素,没有通知迭代器(导致迭代器的快照和原集合状态不同)
//删除元素之后,集合的结构发生了变化,应该重新去获取迭代器,
//但是,循环下一次的时候并没有重新获取迭代器,所以会出现异常
//使用迭代器来删除,不会出现异常
//迭代器删除时,会自动更新迭代器并且更新集合(删除集合中的元素)
iterator1.remove();//删除的一定是迭代器当前指向的元素
System.out.println(o);
}
System.out.println(c2.size());
}
}
重点:在迭代元素的过程中,一定要使用迭代器去删除元素, iterator1.remove();
List接口中常用方法
1.list集合存储元素特点:有序可重复
有序:有下表
2.list既然是Collection接口的子接口,那么一定有自己特有的方法:
以下只列出list接口特有的常用的方法:
void add(int index, E element)
在列表的指定位置插入指定元素(可选操作)。
E get(int index)
返回列表中指定位置的元素。
int indexOf(Object o)
返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1。
int lastIndexOf(Object o)
返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1。
E remove(int index)
移除列表中指定位置的元素(可选操作)。
E set(int index, E element)
用指定元素替换列表中指定位置的元素(可选操作)。
package collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/*
List接口中的常用方法
1.list集合存储元素特点:有序可重复
有序:有下表
2.list既然是Collection接口的子接口,那么一定有自己特有的方法:
以下只列出list接口特有的常用的方法:
void add(int index, E element)
在列表的指定位置插入指定元素(可选操作)。
E get(int index)
返回列表中指定位置的元素。
int indexOf(Object o)
返回此列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1。
int lastIndexOf(Object o)
返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1。
E remove(int index)
移除列表中指定位置的元素(可选操作)。
E set(int index, E element)
用指定元素替换列表中指定位置的元素(可选操作)。
*/
public class ListTest01 {
public static void main(String[] args) {
//创建list类型的集合
List l1 = new ArrayList<>();
l1.add("A");//默认都是向集合末尾添加元素
l1.add("b");
l1.add("c");
l1.add("d");
l1.add("A");
l1.add("A");
//这个方法使用不多,因为对于Arraylist集合来说效率比较低
l1.add(1,"king");//index 为下标,向指定位置添加元素
Iterator iterator = l1.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
//根据元素下标获取元素
System.out.println(l1.get(0));
System.out.println("-------list集合有自己特殊的遍历方式--------");
//list集合有自己特殊的遍历方式
for (int i =0;i<l1.size();i++){
System.out.println(l1.get(i));
}
System.out.println("-------获取指定对象,第一次出现处的索引--------");
//获取指定对象,第一次出现处的索引
System.out.println(l1.indexOf("king"));
System.out.println("-------获取指定对象,最后一次出现处的索引--------");
//获取指定对象,最后一次出现处的索引
System.out.println(l1.lastIndexOf("A"));
System.out.println("-------删除指定下标元素--------");
//删除指定下标元素
l1.remove(0);
System.out.println(l1.size());
System.out.println("-------修改指定位置的元素--------");
//修改指定位置的元素
l1.set(2,"s2");
for (int i =0;i<l1.size();i++){
System.out.println(l1.get(i));
}
}
}
ArrayList集合
常用的方法
1.默认初始化容量10,(底层先创建了一个长度为0的数组,当添加一个元素的时候,初始化容量为10)
2.集合底层是一个Object[]数组
3.构造方法:
new ArrayList();
new ArrayList(20);
4.ArrayList的集合扩容:
原容量的1.5倍
ArrayList集合底层是数组,尽可能减少扩容,因为数组扩容效率比较低,建议在使用ArrayList的时候预估计初始化容量。
5.数组的优点:检索效率比较高
6.数组的缺点:随机增删效率比较低,数组无法存储大数据量(很难找到一块非常巨大的连续空间)
7.数组末尾添加元素的效率很高,不受影响
8.这么多的集合中,用那个最多?
ArrayList,因为往末尾添加元素,效率不受影响。另外我们检索/查找某个元素的操作比较多、
9.Arraylist不是非线程安全的
package collection;
import java.util.ArrayList;
import java.util.List;
/*
ArrayList集合:
1.默认初始化容量10,(底层先创建了一个长度为0的数组,当添加一个元素的时候,初始化容量为10)
2.集合底层是一个Object[]数组
3.构造方法:
new ArrayList();
new ArrayList(20);
4.ArrayList的集合扩容:
原容量的1.5倍
ArrayList集合底层是数组,尽可能减少扩容,因为数组扩容效率比较低,建议在使用ArrayList的时候预估计初始化容量。
5.数组的优点:检索效率比较高
6.数组的缺点:随机增删效率比较低,数组无法存储大数据量(很难找到一块非常巨大的连续空间)
7.数组末尾添加元素的效率很高,不受影响
8.这么多的集合中,用那个最多?
ArrayList,因为往末尾添加元素,效率不受影响。另外我们检索/查找某个元素的操作比较多
*/
public class ArrayListTest01 {
public static void main(String[] args) {
//默认初始容量为10
List list1 = new ArrayList();
System.out.println(list1.size());
//指定初始容量为20
List list2 = new ArrayList(20);
System.out.println(list2.size());
//size方法是获取当前集合元素的个数,不是获取集合的容量
list1.add(1);
list1.add(2);
list1.add(3);
list1.add(4);
list1.add(5);
list1.add(6);
list1.add(7);
list1.add(8);
list1.add(9);
list1.add(10);
System.out.println(list1.size());
list1.add(11);
System.out.println();
}
}
构造方法
1.默认初始化
List mylist1 = new ArrayList();
2.给定初始化容量
List myList2 = new ArrayList(100);
3.初始化容量可以为其他的集合
Collection c = new HashSet();
List mylist3 = new ArrayList(c);
链表
Linkedlist创建的时候底层是双向的
单链表
单链表中的节点
节点是单链表中基本的单元。
每一个节点Node都有两个属性:
一个属性:是存储数据
一个属性:是下一个节点的内存地址
添加节点

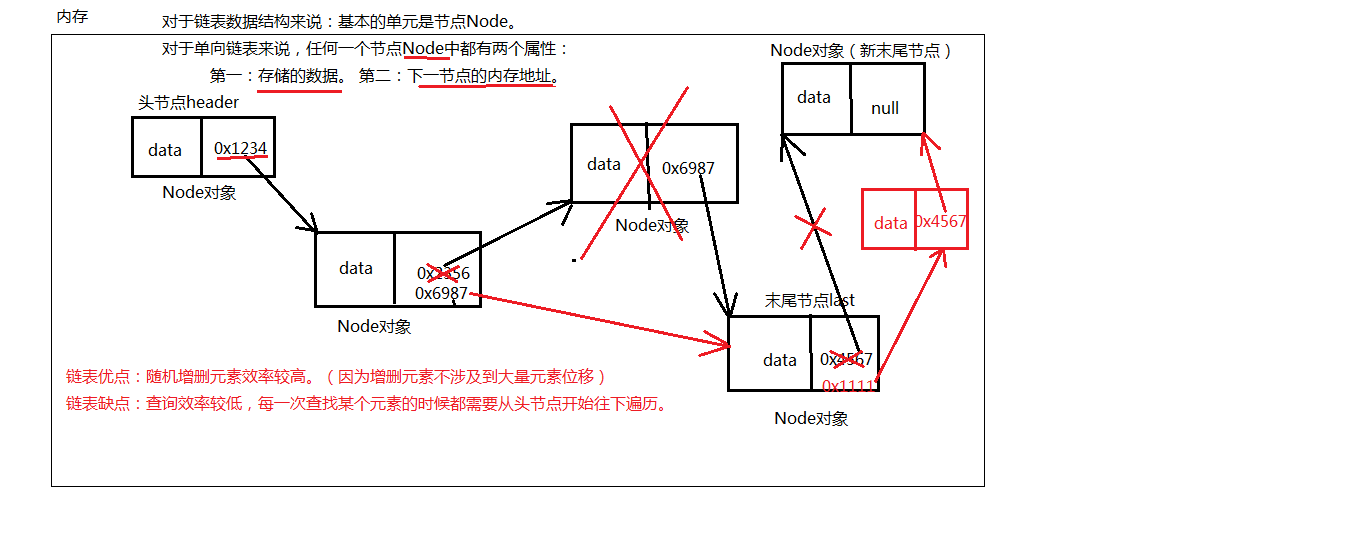
删除节点

链表的优点:
由于链表上的元素在空间存储上内存地址不连续,所以随机增删元素的时候不会有大量元素的位移,因此随即增删效率较高
在以后的开发中,如果遇到随即增删集合中元素的业务比较多时,建议使用linkedlist
链表的缺点:
不能通过数学表达式计算被查找元素的内存地址,每一次查找都是从头结点开始遍历,知道找到为止,所以linkedlist集合检索/查找的效率比较低
Arraylits:把检索发挥到极致
linkedlist:把随即增删发挥到极致
加元素往往从末尾开始添加,所以Arraylist末尾添加的效率还是比较高的
Linkedlist 集合底层也有下标
注意:Arraylist的检索效率比较高,不是单纯因为下标的原因,是因为底层数组发挥的作用
linkedlist集合照样有下标,但是检索/查找某个元素的时候效率比较低,因为只能从头节点开始一个一个遍历
双向链表
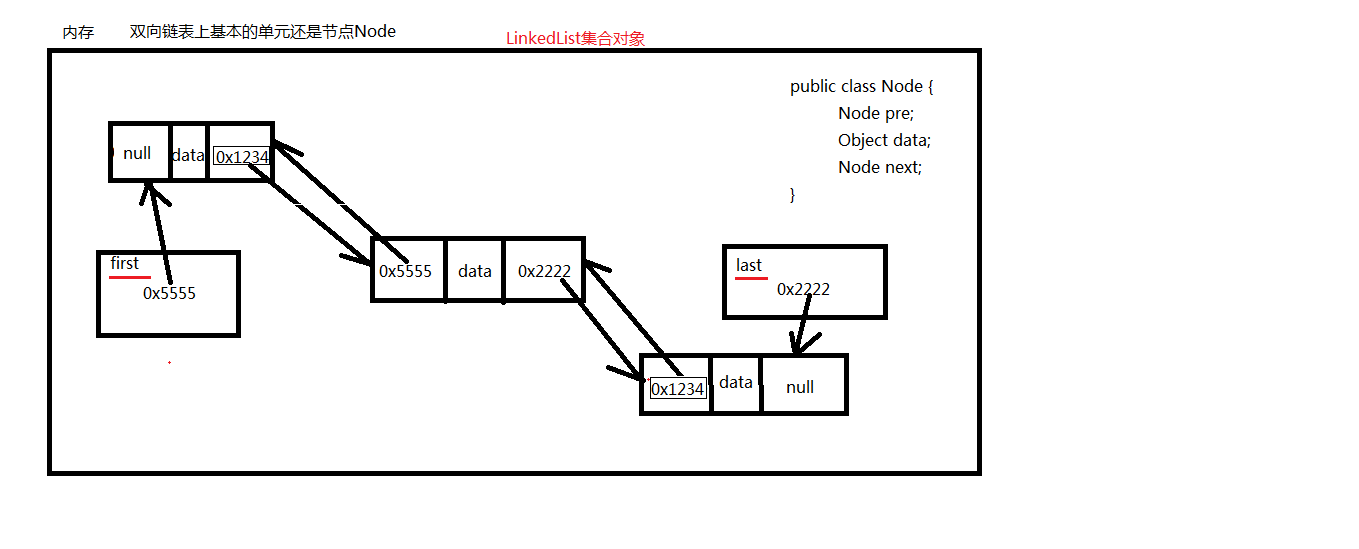
源码
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
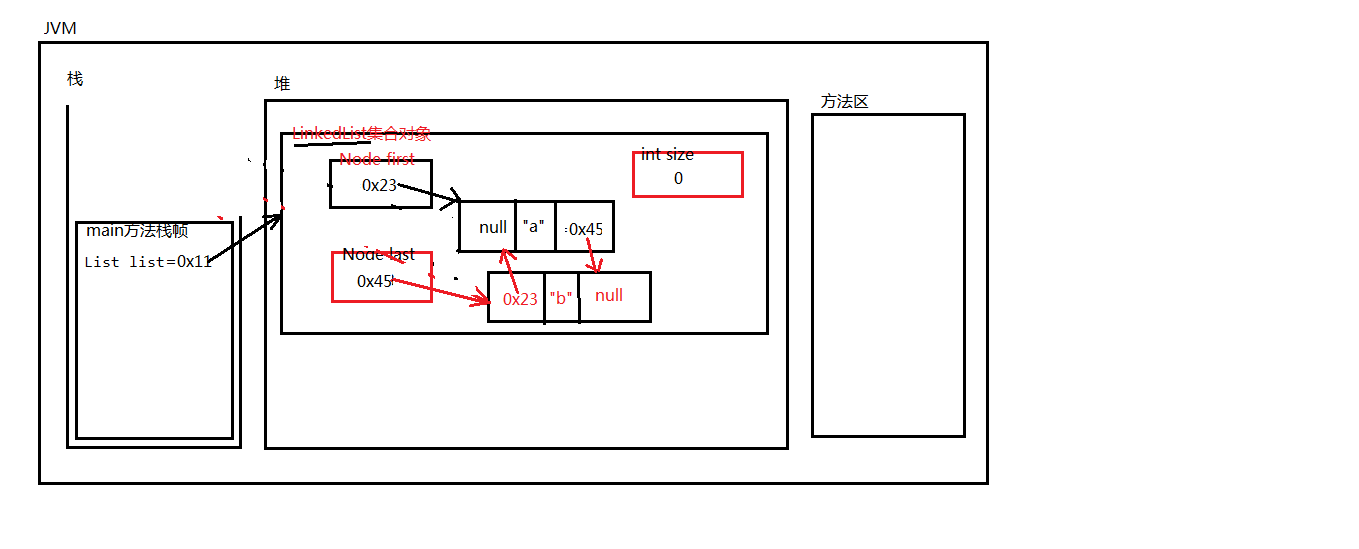
linkedlist集合没有初始化容量
最初这个链表中没有任何元素,first和last的引用都是null,不管是linkedlist还是Arraylist,以后写代码时不需要关心具体是哪一个集合,因为我们要面向接口编写,调用的方法都是接口中的方法
Vector
1.底层是一个数组
2.初始化容量为:10
3.扩容之后为原容量的二倍。10->20->40
4.ArrayList扩容是1.5倍 10->15->22.5
5.Vector中所有的方法都是线程同步的是线程安全的,效率比较低,使用较少
6.如何将Arraylist转换成线程安全的Vector
使用集合工具类:
java.util
Collections.synchronizedList 变成线程安全的
泛型机制
介绍
1.泛型这种语法机制,只在程序编译阶段起作用,只是给编译器擦参考的(运行阶段泛型没有用)
2.使用泛型的好处:
第一:集合中存储的元素类型统一了
第二:从集合中取出的元素是泛型指定的类型。不需要进行大量的”向下类型转换“
3.使用泛型的缺点:
导致结合中存储的元素缺乏多样性
大多数业务中,集合中元素的类型还是统一的,这种机制还是被认可的
使用泛型和不使用泛型
package collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/*
1.泛型这种语法机制,只在程序编译阶段起作用,只是给编译器擦参考的(运行阶段泛型没有用)
2.使用泛型的好处:
第一:集合中存储的元素类型统一了
第二:从集合中取出的元素是泛型指定的类型。不需要进行大量的”向下类型转换“
3.使用泛型的缺点:
导致结合中存储的元素缺乏多样性
大多数业务中,集合中元素的类型还是统一的,这种机制还是被认可的
*/
public class GenericTest01 {
public static void main(String[] args) {
//不适用泛型机制分析程序存在的缺点
/*List mylist= new ArrayList();
C c = new C();
B b = new B();
mylist.add(c);
mylist.add(b);*/
//遍历
//迭代器
/*Iterator iterator = mylist.iterator();
while(iterator.hasNext()){
A obj = (A) iterator.next();
if (obj instanceof C){
C x = (C) obj;
x.move();
x.catchM();
}else if (obj instanceof B){
B x = (B) obj;
x.move();
x.fiy();
}
}*/
//利用泛型
//使用泛型list<A>之后,表示list集合只允许存储Animal类型的数据
//用泛型来指定集合中的数据类型
//指定类为A,那么其他类型就会编译报错
//这样用了泛型之后,集合中元素的数据类型就更加统一的
List<A> mylist = new ArrayList<A>();
C c = new C();
B b = new B();
mylist.add(c);
mylist.add(b);
///表示迭代器迭代的是A类型
Iterator<A> iterator = mylist.iterator();
while(iterator.hasNext()){
//使用泛型迭代的数据,每一次返回的数据类型都是A
//这里不需要强制类型的转换
A a = iterator.next();
a.move();
//调用子类型特有的方法还是需要强制类型转换的
if (a instanceof C){
C C = (C)a;
C.catchM();
}else {
B B = (B)a;
B.fiy();
}
}
}
}
class A{
public void move(){
System.out.println("move");
}
}
class C extends A{
public void catchM(){
System.out.println("catch");
}
}
class B extends A{
public void fiy(){
System.out.println("fly");
}
}
自动类型推断机制
package collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/*
JDK8之后引入了:自动类型推断机制
*/
public class GenericTest02 {
public static void main(String[] args) {
//ArrayList<这里的类型会自动推断>()
//自动类型推断
List<A> mylist = new ArrayList<>();
mylist.add(new A());
mylist.add(new C());
mylist.add(new B());
//遍历
Iterator<A> iterator = mylist.iterator();
while(iterator.hasNext()){
iterator.next().move();
}
List<String> strlits = new ArrayList<>();
strlits.add("abc");
strlits.add("def");
Iterator<String> iterator1 = strlits.iterator();
while(iterator1.hasNext()){
System.out.println(iterator1.next());
}
}
}
自定义泛型
自定义泛型的时候,<>尖括号中的是一个标识符,随便写
java源代码中常出现的是< E >和< T >
E:是element首字母
T:是Type的首字母
package collection;
/*
自定义泛型:
自定义泛型的时候,<>尖括号中的是一个标识符,随便写
java源代码中常出现的是<E>和<T>
E:是element首字母
T:是Type的首字母
*/
public class GenericTest03<AA>/*只是一个标识符随便写*/ {
public void doSome(AA o){
System.out.println(o);
}
public static void main(String[] args) {
GenericTest03<String> gt = new GenericTest03<>();
gt.doSome("abc");
GenericTest03<Integer> gt2 = new GenericTest03<>();
gt2.doSome(1);
MyIterator<String> mi = new MyIterator<>();
String s = mi.get();//类型返回为String
MyIterator<A> mi2 = new MyIterator<>();
A a = mi2.get();
}
}
class MyIterator<T>{
public T get(){
return null;
}
}
增强for循环
package collection;
/*
增强for循环
*/
public class ForEachTest01 {
public static void main(String[] args) {
int[] arr = {1,55,4,7,3,14};
for (int i = 0; i< arr.length ; i++){
System.out.println(arr[i]);
}
System.out.println("-------------");
//增强for
//缺点:没有下标,在需要使用下标的循环中,建议不使用
for(int e: arr){
System.out.println(e);
}
}
}
package collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/*
集合使用增强foreach
*/
public class ForEachTest02 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("1");
list.add("2");
list.add("3");
//遍历 使用迭代器的方式
Iterator<String> it= list.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
System.out.println("----------");
//使用下标的方式,只针对于有下标的集合
for (int i = 0; i< list.size(); i++){
System.out.println(list.get(i));
}
System.out.println("----------------");
//使用foreach
for (String i :list){
System.out.println(i);
}
}
}
Set接口
HashSet
特点
1.存储顺序和取出顺序不同
2.不可重复
3.放到HashSet集合中的元素实际上是放到HashMap集合的key部分了
package collection;
import java.util.HashSet;
import java.util.Set;
/*
HashSet集合:
无序不可重复
*/
public class HashsetTest01 {
public static void main(String[] args) {
Set<String> str = new HashSet<>();
//添加元素
str.add("11");
str.add("55");
str.add("44");
str.add("22");
str.add("11");
str.add("33");
/*
11
33
44
22
55
1.存储顺序和取出顺序不同
2.不可重复
3.放到HashSet集合中的元素实际上是放到HashMap集合的key部分了。
*/
for (String i : str){
System.out.println(i);
}
}
}
TreeSet
特点
1.无序不可重复的,但是存储的元素可以自动按照大小顺序排序,称为:排序集合
2.无序,这里指的是存进去的顺序和取出来的顺序不同,并且没有下标
package collection;
import java.util.Set;
import java.util.TreeSet;
/*
TreeSet集合存储元素的特点:
1.无序不可重复的,但是存储的元素可以自动按照大小顺序排序,称为:排序集合
2.无序,这里指的是存进去的顺序和取出来的顺序不同,并且没有下标
*/
public class HashsetTest02 {
public static void main(String[] args) {
Set<String> strs = new TreeSet<>();
strs.add("11");
strs.add("23");
strs.add("45");
strs.add("22");
strs.add("45");
/*
11
22
23
45
从小到大自动排序
*/
for (String i : strs) {
System.out.println(i);
}
}
}
Map集合
常用的方法
1.Map和Collection没有继承关系
2.Map集合以key和value的方式存储数据:键值对
key和value都是引用数据类型
key和value都是存储对象的内存地址
key起主导作用,value是key的一个附属品
3.Map接口中常用的方法
V put(K key, V value) 向Map集合添加键值对
void clear() 清空Map
V get(Object key) 通过key获取value
boolean containsKey(Object key) 判断Map中是否包含某个key
boolean containsValue(Object value) 判断Map中是否包含某个value
boolean isEmpty() 判断Map集合中元素个数是否为0
Set < K > keySet() 获取Map集合中所有的key (所有的键是一个Set集合)
V remove(Object key) 通过key删除键值对
int size() 获取Map集合中所有的键值对
Collection values() 获取所有的value
Set<Map.Entry<K,V>> entrySet() 将Map集合转换成Set集合
map集合
key value
1 z
2 s
3 w
Set set = map.entrySet();
set集合
1=z 【注意:Map集合通过wntrySet()方法转换成的Set集合,Set集合中的元素类型是Map.Entry<K,V> ,Map.Entry<K,V>是Map中的静态内部类】
2=s
3=w
package collection;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
/*
java.util.Map的常用方法:
1.Map和Collection没有继承关系
2.Map集合以key和value的方式存储数据:键值对
key和value都是引用数据类型
key和value都是存储对象的内存地址
key起主导作用,value是key的一个附属品
3.Map接口中常用的方法
V put(K key, V value) 向Map集合添加键值对
void clear() 清空Map
V get(Object key) 通过key获取value
boolean containsKey(Object key) 判断Map中是否包含某个key
boolean containsValue(Object value) 判断Map中是否包含某个value
boolean isEmpty() 判断Map集合中元素个数是否为0
Set<K> keySet() 获取Map集合中所有的key (所有的键是一个Set集合)
V remove(Object key) 通过key删除键值对
int size() 获取Map集合中所有的键值对
Collection<V> values() 获取所有的value
Set<Map.Entry<K,V>> entrySet() 将Map集合转换成Set集合
map集合
key value
1 z
2 s
3 w
Set set = map.entrySet();
set集合
1=z 【注意:Map集合通过wntrySet()方法转换成的Set集合,Set集合中的元素类型是Map.Entry<K,V> ,Map.Entry<K,V>是Map中的静态内部类】
2=s
3=w
*/
public class MapTest01 {
public static void main(String[] args) {
//创建Map对象,向Maop集合中添加键值对
Map<Integer,String> map = new HashMap<>();
//添加键值对
map.put(1,"zz"); //1在这里进行了自动装箱
map.put(2,"ss");
map.put(3,"ww");
System.out.println("-----通过key来获取value-------");
//通过key来获取value
String s = map.get(2);
System.out.println(s);
System.out.println("-----获取键值对的数量-------");
//获取键值对的数量
System.out.println("键值对数量:"+map.size());
//通过key删除key-value
System.out.println("-----通过key删除key-value-------");
map.remove(1);
System.out.println("键值对数量:"+map.size());
//判断是否包含某个key
//contains方法底层调用的都是equals方法进行比对的,所以自定义的类型都需要重写equals方法
System.out.println("-----判断是否包含某个key-------");
System.out.println(map.containsKey(1));
//判断是否包含某个value
System.out.println("-----判断是否包含某个value-------");
System.out.println(map.containsValue("ww"));
//获取所有的value
System.out.println("-----获取所有的value-------");
Collection<String> c= map.values();
for (String e:c){
System.out.println(e);
}
//清空集合
System.out.println("-----清空集合-------");
map.clear();
System.out.println(map.size());
//判断是否为空
System.out.println("-----判断是否为空-------");
System.out.println(map.isEmpty());
}
}
关于内部类的用法
package collection;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
public class Myclass {
//声明一个静态内部类
private static class InnerClass{
public static void m1(){
System.out.println("静态方法执行");
}
public void m2(){
System.out.println("静态内部类实例方法执行");
}
}
public static void main(String[] args) {
Myclass.InnerClass.m1();//外部类 内部类.m1
Myclass.InnerClass mi = new Myclass.InnerClass();//创建静态内部类对象
mi.m2();
//给一个Set集合,存储这个静态内部类
Set<InnerClass> set = new HashSet<>();
Set<MyMap.Myentry> set1 = new HashSet<>();
}
}
class MyMap{
public static class Myentry<k,v>{
}
}
Map集合的遍历
第一种方式:获取所有的key,来遍历value
第二种方式:Set<Map.Entry<K,V>> entrySet() 将Map集合转换成Set集合
把Map集合全部转换成Set集合
Set集合中元素的类型是:Map.Entry<K,V>
package collection;
import java.util.*;
/*
Map集合的便利
第一种方式:获取所有的key,来遍历value
第二种方式:Set<Map.Entry<K,V>> entrySet() 将Map集合转换成Set集合
把Map集合全部转换成Set集合
Set集合中元素的类型是:Map.Entry<K,V>
*/
public class MapTest02 {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
map.put(1,"zz");
map.put(2,"ss");
map.put(3,"ww");
//第一种遍历
Set<Integer> keys = map.keySet();
//遍历key
//迭代器 foreach
Iterator<Integer> iterator = keys.iterator();
System.out.println("------迭代器---------");
while(iterator.hasNext()){
Integer key = iterator.next();
String value = map.get(key);
System.out.println(key + "=" + value);
}
System.out.println("------foreach---------");
//foreach
for (Integer key:keys){
System.out.println(key + "=" + map.get(key));
}
//第二种方式
System.out.println("-----Set<Map.Entry<K,V>>--------");
Set<Map.Entry<Integer,String>> set = map.entrySet();
//遍历set集合每一次取出node
Iterator<Map.Entry<Integer,String>> iterator1 = set.iterator();
while(iterator1.hasNext()){
Map.Entry<Integer,String> entry = iterator1.next();
Integer key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "=" +value);
}
System.out.println("-----Set<Map.Entry<K,V>> foreach-------");
for (Map.Entry<Integer,String> e:set){
System.out.println(e.getKey() + "=" + e.getValue());
}
}
}
哈希表的数据结构
HashMap集合:
1.HashMap集合底层是哈希表/散列表的数据结构
2.哈希表是一个数组和单向链表的结合体。
数组:在查询方面效率很高,随机增删效率很低
单向链表:随机增删效率很高,在查询方面效率很低
哈希表将两种数据结合在一起,充分发挥它们各自的优点
3.HashMap集合底层的源代码:
public class HashMap{
//HashMap底层实际上是一个一维数组
transient Node<K,V>[] table;
//静态内部类
static class Node<K,V> implements Map.Entry<K,V>{
final int hash; //哈希值,哈希值是key的hashCode()方法的执行结果,hash值通过哈希算法/函数,可以转换存储数组的下标
final K key; //存储到Map集合中的那个key
V value; //存储到Map集合中的那个value
Node<K,V> next; //下一节点的内存地址
}
}
哈希表/散列表:一维数组,这个数组中每一个元素都是一个单向链表(数组和链表的结合体)
4.最主要掌握的是:
map.put(k,v)
v = map.get(k)
以上这两个方法的实现原理,是必须掌握的

5.HashMap集合key部分特点:
无序不可重复
为什么无序?因为不一定挂到哪一个单向链表上
不可重复怎么保证?equals方法来保证HashMap集合的key不可重复
如果key重复,value会覆盖
放在HashMap集合key部分的元素其实就是放到HashMap集合中了
所以HashSet集合中的元素也需要同时重写hashCode()+equals()方法
6.HashMap使用不当时无法发挥性能
假设所有的hashCode()方法返回为某个固定的值,那么会导致底层哈希表变成纯单项链表。这种情况我们称为:散列分布不均匀
什么是散列分布均匀?
假设有100个元素,10个单向链表,那么每个单向列表上有10个节点,这是最好的,是散列均匀的
假设将所有的hashCode()返回值都设定为不一样的值,这样的话会导致底层哈希表就会成为一维数组,就没有链表的概念了,也是散列分布不均匀
散列分布均匀需要你重写hashCode方法时有一定的技巧。
7.重点:放在HashMap集合key部分的元素,以及放在HashSet集合中的元素,需要同时重写hashCode和equals方法。
8.HashMap集合默认初始化容量为16,默认加载因子为0.75
这个默认加载因子是当HashMap底层集合数组的容量达到75%的时候开始扩容
重点:HashMap集合初始化容量必须是2的倍数,这也是官方推荐的,这是因为可以提高存取效率,所以是必须的
equals和hashCode的重写
1.向Map集合中存,以及从Map集合中取,都是先调用key的hashCode方法,然后再调用equals方法
equals方法可能调用,也可能不调用
拿put(k,v)举例,
k.hashCode()方法返回哈希值,哈希值经过哈希算法转换为数组下标,数组下标位置上如果是null,equals不需要执行
拿get(k,v)举例
如果数组下标为null,不需要执行;如果数组单向链表上有元素时,就需要equals
2.注意:如果一个类的equals方法重写了,那么hashCode方法也需要重写,并且如果equals方法返回true,hashCode方法返回值必须一样
3.重写方法直接使用IDEA方法生成,这两个方法要同时生成
**4.结论:**放在HashMap集合key部分,以及放在HashSet集合中的元素,需要同时从写hashCode方法和equals方法
5.对于哈希表数据结构来说:
如果o1和o2的hash值相同,一定是放在一个单向链表上
当然如果o1和o2的hash值不同,但是由于哈希算法执行结束之后转换的数组下标可能相同,这时候会发生**“哈希碰撞”**
6.扩容:扩容容量是原容量的二倍
package collection;
import java.util.HashSet;
import java.util.Objects;
import java.util.Set;
/*
1.向Map集合中存,以及从Map集合中取,都是先调用key的hashCode方法,然后再调用equals方法
equals方法可能调用,也可能不调用
拿put(k,v)举例,
k.hashCode()方法返回哈希值,哈希值经过哈希算法转换为数组下标,数组下标位置上如果是null,equals不需要执行
拿get(k,v)举例
如果数组下标为null,不需要执行;如果数组单向链表上有元素时,就需要equals
2.注意:如果一个类的equals方法重写了,那么hashCode方法也需要重写,并且如果equals方法返回true,hashCode方法返回值必须一样
3.重写方法直接使用IDEA方法生成,这两个方法要同时生成
4.结论:放在HashMap集合key部分,以及放在HashSet集合中的元素,需要同时从写hashCode方法和equals方法
*/
public class HashMapTest02 {
public static void main(String[] args) {
Student student1 = new Student("zz");
Student student2 = new Student("zz");
System.out.println(student1.equals(student2)); //重写之后相等
System.out.println(student1.hashCode()); //2003749087
System.out.println(student2.hashCode()); //1324119927 重写之后都是3935
//student1.equals(student2)结果以及是true了,表示student1和student2是一样的,那么往HashSet集合中放的话,
//只能放进去一个
Set<Student> set = new HashSet<>();
set.add(student1);
set.add(student2);
System.out.println(set.size()); // 2
}
}
class Student{
private String name;
public Student() {
}
public Student(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
//hashCode
//equals
/*public boolean equals(Object obj){
if(obj == null || !(obj instanceof Student))return false;
if (obj == this) return true;
//类型转换
Student s = (Student) obj;
if (this.name == s.name)return true;
return false;
}*/
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name);
}
}
JDK8:如果哈希表单向链表中的元素超过8个,单向链表这种数据结构会变成红黑树数据结构,当红黑树上的节点雄安与6时,会重写把红黑树变成单向链表数据结构
HashTable
HashMap集合key和value部分允许为null
HashTable的key和value不允许为null
HashTable方法都带有synchronized:线程安全的,线程安全有其他方案,这个HashTable对线程的处理导致效率较低,使用较少了
HashTable和HashMap一样,底层都是哈希表数据结构,Hashtable的初始化容量是11,默认加载因子是0.75f,Hashtable的扩容是原容量 * 2+ 1
Properties
目前只需要掌握Properties属性类对象的相关方法即可.
Properties是一个Map集合,继承Hashtable,Properties的key和value都是String类型,Properties是属性类对象
package collection;
import java.util.Properties;
/*
目前只需要掌握Properties属性类对象的相关方法即可
Properties是一个Map集合,继承Hashtable,Properties的key和value都是String类型
Properties是属性类对象
*/
public class PropertiesTest01 {
public static void main(String[] args) {
//创建一个Properties对象
Properties properties = new Properties();
//需要掌握Properties的两个方法,一个存,一个取
properties.setProperty("url","http://");
properties.setProperty("driver","com.mysql.jac.Dirver");
properties.setProperty("uername","root");
properties.setProperty("password","123");
//通过key获取value
String s1 = properties.getProperty("url");
String s2 = properties.getProperty("driver");
String s3 = properties.getProperty("username");
String s4 = properties.getProperty("password");
System.out.println(s1);
System.out.println(s2);
System.out.println(s3);
System.out.println(s4);
}
}
TreeSet集合
1.TreeSet集合底层实际上是一个TreeMap
2.TreeMap集合底层是一个二叉树
3.放到TreeSet集合中的元素,等同于放到TreeMap集合key部分
4.Treeset集合中的元素,:无序不可重复,但是可以按照元素的大小顺序自动拍戏。称为可排序集合
第一种排序方式
package collection;
import java.util.TreeSet;
/*
1.TreeSet集合底层实际上是一个TreeMap
2.TreeMap集合底层是一个二叉树
3.放到TreeSet集合中的元素,等同于放到TreeMap集合key部分
4.Treeset集合中的元素,:无序不可重复,但是可以按照元素的大小顺序自动拍戏。称为可排序集合
*/
public class TreeSetTest01 {
public static void main(String[] args) {
//创建一个TreeSet集合
TreeSet<String> ts = new TreeSet<>();
ts.add("zz");
ts.add("za");
ts.add("aa");
ts.add("wa");
ts.add("sd");
for (String s:ts){
System.out.println(s);
}
TreeSet<Integer> ts1 = new TreeSet<>();
ts1.add(100);
ts1.add(200);
ts1.add(45);
ts1.add(78);
ts1.add(150);
for (int i : ts1){
System.out.println(i);
}
}
}
对自定义类型来说,TreeSet可以排序吗?
以下程序中对于Person类型来说,无法排序,因为没有指定排序规则
以下程序出现了这个异常:
java.lang.ClassCastException: class collection.
Person cannot be cast to class java.lang.Comparable
package collection;
import java.util.TreeSet;
/*
对自定义类型来说,TreeSet可以排序吗?
以下程序中对于Person类型来说,无法排序,因为没有指定排序规则
以下程序出现了这个异常:
java.lang.ClassCastException: class collection.
Person cannot be cast to class java.lang.Comparable
*/
public class TreeSetTest02 {
public static void main(String[] args) {
Person p1 = new Person(20);
Person p2 = new Person(20);
Person p3 = new Person(20);
Person p4 = new Person(20);
Person p5 = new Person(20);
TreeSet<Person> treeSet = new TreeSet<>();
treeSet.add(p1);
treeSet.add(p2);
treeSet.add(p3);
treeSet.add(p4);
treeSet.add(p5);
for (Person p : treeSet){
System.out.println(p);
}
}
}
class Person{
int age;
public Person(int age) {
this.age = age;
}
public String toString(String s){
return "Person[age:" + age+"]";
}
}
TreeSet的第二种排序方式
TreeSet集合元素可排序的第二种方式:使用比较器
结论:放在TreeMap或者TreeMap结合key部分的元素想要做到排序,包括两种方式:
第一种:放到集合java.lang.Comparable接口
第二种:再够在TreeMap或者TreeSet集合的时候给他传一个比较器对象
Comparator和Comparable怎么选择
当比较规则不会发生改变的时候,或者说当比较规则只有一个的时候,建议使用Comparable接口。
如果比较规则有多个,并且需要多个比较规则频繁切换,建议使用Comparator接口
Comparator接口符合OCP原则
package collection;
import java.util.Comparator;
import java.util.TreeSet;
/*
TreeSet集合元素可排序的第二种方式:使用比较器
结论:放在TreeMap或者TreeMap结合key部分的元素想要做到排序,包括两种方式:
第一种:放到集合java.lang.Comparable接口
第二种:再够在TreeMap或者TreeSet集合的时候给他传一个比较器对象
Comparator和Comparable怎么选择
当比较规则不会发生改变的时候,或者说当比较规则只有一个的时候,建议使用Comparable接口。
如果比较规则有多个,并且需要多个比较规则频繁切换,建议使用Comparator接口
Comparator接口符合OCP原则
*/
public class TreeSetTest06 {
public static void main(String[] args) {
//创建TreeSet的集合的时候,需要使用这个比较器
TreeSet<W> w = new TreeSet<>(new Wcomparator());
w.add(new W(100));
w.add(new W(101));
w.add(new W(10));
w.add(new W(800));
w.add(new W(2000));
w.add(new W(1000));
for (W s :w){
System.out.println(s);
}
//可以使用匿名内部类的方式(这个类没有名字直接new接口)
TreeSet<W> w1 = new TreeSet<>(new Comparator<W>(){
public int compare(W o1, W o2) {
//按照年龄排序
return o1.age - o2.age;
}
});
}
}
//单独编写一个比较器
//实现Comparator接口
class Wcomparator implements Comparator<W> {
@Override
public int compare(W o1, W o2) {
//按照年龄排序
return o1.age - o2.age;
}
}
class W {
int age;
public W(int age) {
this.age = age;
}
public String toString(){
return "W," + "age:" + age;
}
}
改变比较器可以修改比较规则
package collection;
import java.util.Collections;
import java.util.Comparator;
import java.util.TreeSet;
public class CollectionTest02 {
public static void main(String[] args) {
TreeSet<Integer> ts = new TreeSet<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
ts.add(1);
ts.add(100);
ts.add(150);
for (int i :ts){
System.out.println(i);
}
}
}
自平衡二叉树
自平衡二叉树遵循左小右大的原则存放
中序遍历:左根右
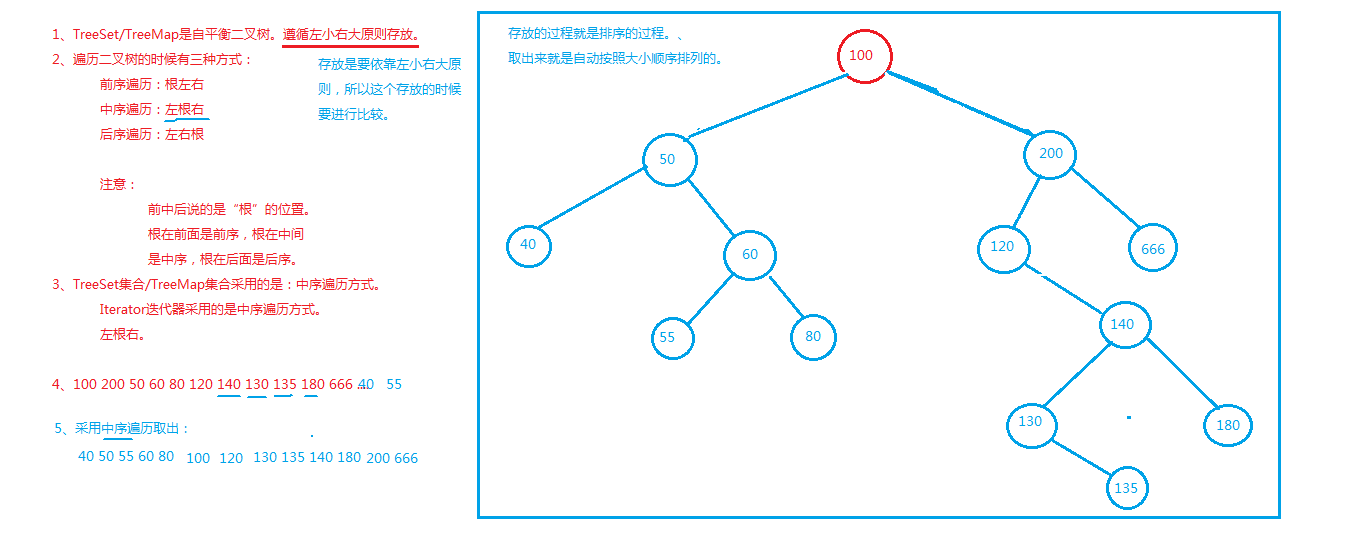
Collections工具类
java.util.Collection 集合接口
java.util.Collections 集合工具类
collections.sort如何进行排序
package collection;
import java.util.*;
/*
java.util.Collection 集合接口
java.util.Collections 集合工具类
*/
public class CollectionTest1 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
//变成线程安全的
Collections.synchronizedList(list);
//排序
list.add("avf");
list.add("abc");
list.add("qw");
list.add("wes");
System.out.println("------------------");
Collections.sort(list);
for (String s:list){
System.out.println(s);
}
List<W2> list1 = new ArrayList<>();
list1.add(new W2(200));
list1.add(new W2(250));
list1.add(new W2(400));
list1.add(new W2(500));
list1.add(new W2(700));
//对list集合元素排序,需要保证list结合中的元素实现:Comparable接口
Collections.sort(list1);
for (W2 w2 :list1){
System.out.println(w2.age);
}
System.out.println("------------------");
Set<String> set = new HashSet<>();
set.add("king");
set.add("king1");
set.add("king2");
set.add("king32");
set.add("king4");
//将Set集合转换为List
List<String> mylist = new ArrayList<>(set);
Collections.sort(mylist);
for (String s:mylist){
System.out.println(s);
}
//这种方式也可以排序
//Collections.sort(list,比较器)
}
}
class W2 implements Comparable<W2> {
int age;
public W2(int age) {
this.age = age;
}
public String toString(){
return "W," + "age:" + age;
}
@Override
public int compareTo(W2 o) {
return this.age - o.age;
}
}
总结
day30课堂笔记
1、掌握Map接口中常用方法。
2、遍历Map集合的两种方式都要精通。
第一种:获取所有key,遍历每个key,通过key获取value.
第二种:获取Set<Map.Entry>即可,遍历Set集合中的Entry
调用entry.getKey() entry.getValue()
3、了解哈希表数据结构。
4、存放在HashMap集合key部分和HashSet集合中的元素需要同时重写hashCode和equals。
5、HashMap和Hashtable的区别。
HashMap:
初始化容量16,扩容2倍。
非线程安全
key和value可以为null。
Hashtable
初始化容量11,扩容2倍+1
线程安全
key和value都不能是null。
6、Properties类的常用两个方法。
setProperty
getProperty
7、了解自平衡二叉树数据结构。
左小右大原则存储。
中序遍历方式。
8、TreeMap的key或者TreeSet集合中的元素要想排序,有两种实现方式:
第一种:实现java.lang.Comparable接口。
第二种:单独编写一个比较器Comparator接口。
9、集合工具类Collections:
synchronizedList方法
sort方法(要求集合中元素实现Comparable接口。)
集合这块最主要掌握什么内容?
1.1、每个集合对象的创建(new)
1.2、向集合中添加元素
1.3、从集合中取出某个元素
1.4、遍历集合
1.5、主要的集合类:
ArrayList
LinkedList
HashSet (HashMap的key,存储在HashMap集合key的元素需要同时重写hashCode + equals)
TreeSet
HashMap
Properties
TreeMap
I/O流
对I/O流的理解
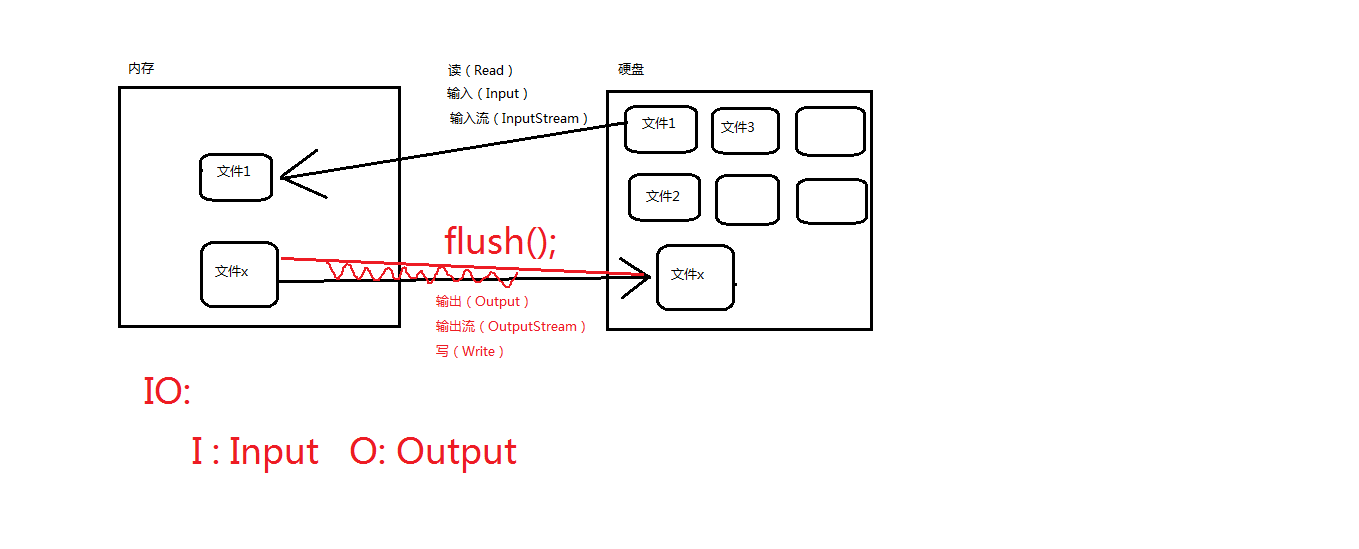
I:Input
O:Output
通过IO可以完成硬盘文件的读和写
IO流的分类?
有多种分类方式:
一种方式按照流的方向进行分类:
以内存作为参照物,往内存中去,叫做输入。或者叫做读;从内存中出来,叫做输出,或者叫做写
一种方式是按照读取数据方式不同进行分类:
**有的流是按照字节的方式读取数据,叫做字节流,一次读取一个字节byte,**等同于一次读取8个二进制位,这种流是万能的,什么类型的文件都可以读取,包括:文本文件,图片,声音文件,视频文件等…
假设文件file1.txt,采用字节流的话是这样读的:
a中国bc张三fe
第一次读:一个字节,正好读到’a’
第二次读:一个字节,正好读到’中’字符的一半。
第三次读:一个字节,正好读到’中’字符的另外一半。
**有的按照字符的方式读取数据,一次读取一个字符,**叫做字符流,这种流是为了方便读取普通文本文件而存在的,这种流不能读取:图片、声音、视频等文件,只能读取存文本文件,连word文件都无法读取。
假设文件file1.txt,采用字符流的话是这样读的:
a中国bc张三fe
第一次读:'a’字符('a’字符在windows系统中占用1个字节。)
第二次读:'中’字符('中’字符在windows系统中占用2个字节。)
综上所述:流的分类
输入流、输出流、字节流、字符流
java中的I/O
Java中的I/O流都是写好的,程序员不需要关心,我们主要还是掌握在java中以及提供了哪些流,每个流的特点是什么,每个流对象上的常用方法有哪些
Java中所有的流都在:java.io.*; 下
java中主要还是研究:
怎么new流对象。
调用流对象的哪个方法是读,哪个方法是写。
java IO流四大家族
四大家族的首领:
java.io.InputStream 字节输入流
java.io.OutputStream 字节输出流
java.io.Reader 字符输入流
java.io.Writer 字符输出流
四大家族的首领都是抽象类。(abstract class)
注意:在java中只要“类名”以Stream结尾的都是字节流。以**“Reader/Writer”结尾的都是字符流**。
close()和flush()方法
所有的流都实现了:
java.io.Closeable接口,都是可关闭的,都有close()方法。
流毕竟是一个管道,这个是内存和硬盘之间的通道,用完之后一定要关闭,不然会耗费(占用)很多资源。养成好习惯,用完流一定要关闭。
所有的输出流都实现了:
java.io.Flushable接口,都是可刷新的,都有flush()方法。
养成一个好习惯,输出流在最终输出之后,一定要记得flush()刷新一下。这个刷新表示将通道/管道当中剩余未输出的数据,强行输出完(清空管道!)刷新的作用就是清空管道。
注意:如果没有flush()可能会导致丢失数据。
java.io包下需要掌握的流有16个:
文件专属:
java.io.FileInputStream(掌握)
java.io.FileOutputStream(掌握)
java.io.FileReader
java.io.FileWriter
转换流:(将字节流转换成字符流)
java.io.InputStreamReader
java.io.OutputStreamWriter
缓冲流专属:
java.io.BufferedReader
java.io.BufferedWriter
java.io.BufferedInputStream
java.io.BufferedOutputStream
数据流专属:
java.io.DataInputStream
java.io.DataOutputStream
标准输出流:
java.io.PrintWriter
java.io.PrintStream(掌握)
对象专属流:
java.io.ObjectInputStream(掌握)
java.io.ObjectOutputStream(掌握)
java.io.FileInputStream
1.文件字节输入流,万能的,任何类型的文件都可以采用这个流来读
2.字节的方式,完成输入操作,完成读的操作(硬盘---->内存)
创建文件字节流文件
//以下都是采用了绝对路径的方式
//文件路径:C:\Users\77\Downloads\Documents\07-JavaSE进阶每日复习与笔记 会制动把\编程\\,因为java中的\代表转义
//也可以写成C:/Users/77/Downloads/Documents/07-JavaSE进阶每日复习与笔记
package streamsIO;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/*
java.io.FileInputStream
1.文件字节输入流,万能的,任何类型的文件都可以采用这个流来读
2.字节的方式,完成输入操作,完成读的操作(硬盘---->内存)
*/
public class FileInputTest01 {
public static void main(String[] args) {
FileInputStream fis = null;
//创建文件字节流文件
//以下都是采用了绝对路径的方式
//文件路径:C:\Users\77\Downloads\Documents\07-JavaSE进阶每日复习与笔记 会制动把\编程\\,因为java中的\代表转义
//也可以写成C:/Users/77/Downloads/Documents/07-JavaSE进阶每日复习与笔记
try {
fis = new FileInputStream("C:\\Users\\77\\Downloads\\Documents\\07-JavaSE进阶每日复习与笔记\\11.txt");
int readData = fis.read();
System.out.println(readData);//这个方法的返回值是:读取到的字节本身
readData = fis.read();
System.out.println(readData);
readData = fis.read();
System.out.println(readData);
readData = fis.read();
System.out.println(readData);
readData = fis.read();
System.out.println(readData);//读取到末尾了,返回值为-1
//文件中为:abcd
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//finally语句块中确保流一定关闭。流是null的时候没必要关闭,避免空指针异常
if (fis!=null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
对程序进行改造,while循环
package streamsIO;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/*
对第一个程序进行改进,循环方式
一次读取一个字节,这样内存和硬盘交互太频繁了,基本上时间、资源都耗费了
*/
public class FileInputTest02 {
public static void main(String[] args) {
FileInputStream fis = null;
try {
fis = new FileInputStream("C:\\Users\\77\\Downloads\\Documents\\07-JavaSE进阶每日复习与笔记\\11.txt");
/*while(true){
int readDate = fis.read();
if (readDate == -1){
break;
}
System.out.println(readDate);
}*/
//改进while
int readDate = 0;
while((readDate = fis.read())!=-1){
System.out.println(readDate);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if (fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
继续改造,一次读取多个字节
package streamsIO;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/*
int read(byte[] b)
一次最多读取b.length个字节
减少硬盘和内存的交互,提高程序的执行效率
往byte[]数组当中读
*/
public class FileInputTest03 {
public static void main(String[] args) {
FileInputStream fis = null;
try {
//使用相对路径
//IDEA当前的默认路径为,工程Project的根就是IDEA的默认当前路径
fis = new FileInputStream("myfile.txt");
//开始读,采用byte数组,一次读取多个字节,最多读取“数组.length”个字节
byte[] bytes = new byte[4];//一次最多读取四个字节
//xiaoqi
int readCount = fis.read(bytes);//4
System.out.println(readCount);
//以下方法是把byte数组全部转换成了字符串
//System.out.println(new String(bytes));
//不应该全部都转,应该是读取了多少个字节,转换多少个
System.out.println(new String(bytes,0,readCount));
//第二次只能读到两个字节
readCount = fis.read(bytes);//2
System.out.println(readCount);
//System.out.println(new String(bytes));
System.out.println(new String(bytes,0,readCount));
//最后读不到数据返回-1
readCount = fis.read(bytes);//-1
System.out.println(readCount);
} catch (IOException e) {
e.printStackTrace();
}finally {
if (fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
最后的改进
package streamsIO;
import java.io.FileInputStream;
import java.io.IOException;
/*
最后的版本
*/
public class FileInputTest04 {
public static void main(String[] args) {
FileInputStream fis = null;
try {
fis = new FileInputStream("myfile.txt");
//准备一个数组
byte[] bytes = new byte[4];
/*while(true){
int readCount = fis.read(bytes);
if (readCount==-1){
break;
}
System.out.println(new String(bytes,0,readCount));
}*/
int readCount = 0;
while((readCount = fis.read(bytes))!= -1){
System.out.println(new String(bytes,0,readCount));
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if (fis!=null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
其他常用的两个方法
int available() 返回流当中剩余的没有读到的字节数量
long skip(long n) 跳过几个字节不读
package streamsIO;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
/*
其他常用的两个方法:
int available() 返回流当中剩余的没有读到的字节数量
long skip(long n) 跳过几个字节不读
*/
public class FileInputeTest05 {
public static void main(String[] args) {
FileInputStream fis = null;
try {
fis = new FileInputStream("myfile.txt");
//读一个字节
//int readByte = fis.read();//还剩下五个字节
//这个方法有什么用
//不需要循环了,直接读一次就可以
/*System.out.println("字节数量:" + fis.available());
byte[] bytes = new byte[fis.available()];//这种方式不太适合太大的文件,因为bytes[]数组不能太大
int readCount = fis.read(bytes);
System.out.println(new String(bytes));*/
//跳过几个字节不读取,这个方法以后可能也会用到
fis.skip(3);
System.out.println(fis.read());
} catch (IOException e) {
e.printStackTrace();
}finally {
if (fis!=null)
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
java.io.FileOutput
文件字节输出流,负责写(从内存到硬盘)
写入方式
package streamsIO;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
/*
文件字节输出流,负责写
从内存到硬盘
*/
public class FileOutputTest01 {
public static void main(String[] args) {
FileOutputStream fos = null;
try {
//文件不存在时会自动创建新的文件
//这种方式需要谨慎使用,因为他会把源文件清空
//以追加的方式在文件末尾写入。不会清空源文件内容
fos = new FileOutputStream("myfile.txt",true);
//开始往文件中写
byte[] bytes = {97,98,99,100};
//将byte数组全部写出
fos.write(bytes);//abcd
//将bytes数组的一部分写出
fos.write(bytes,0,2);//写出ab
String s= "china";
byte[] ss = s.getBytes();//将字符串转换为byte数组
fos.write(ss);
//写完之后一定要刷新
fos.flush();
} catch (IOException e) {
e.printStackTrace();
}finally {
if (fos != null)
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
文件的拷贝
使用Fileinput和FileOutput完成文件的拷贝
拷贝的过程应该是一边读一边写,
使用以上的字节流拷贝文件的时候,文件类型随意,万能的,什么样的文件都能拷贝
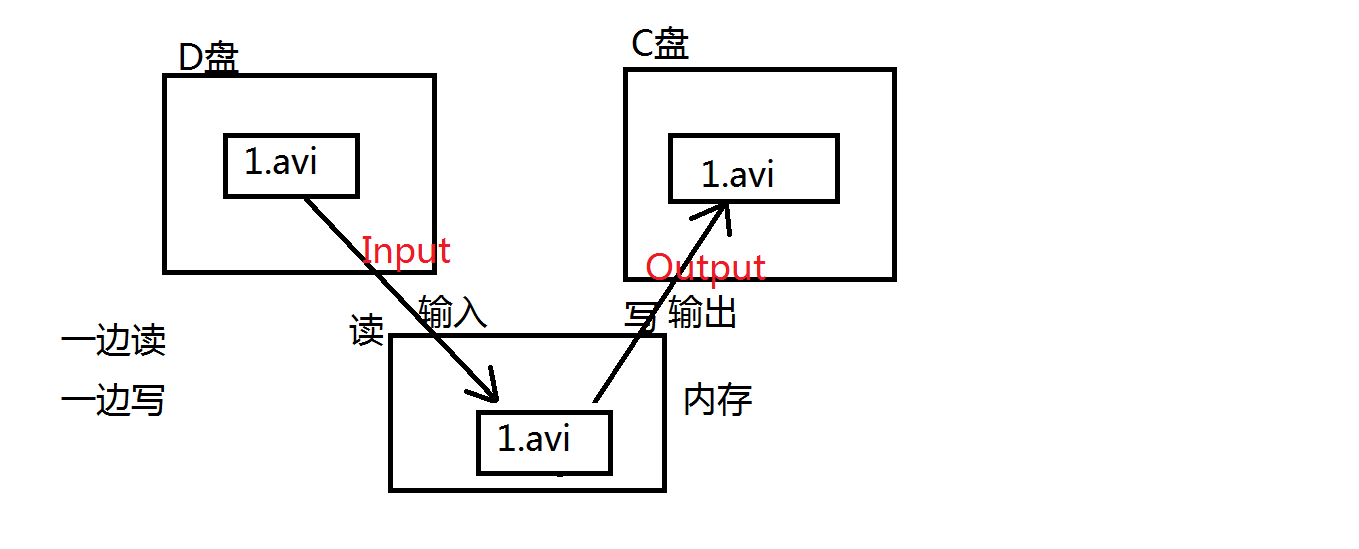
package streamsIO;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
/*
使用Fileinput和FileOutput完成文件的拷贝
拷贝的过程应该是一边读一边写,
使用以上的字节流拷贝文件的时候,文件类型随意,万能的,什么样的文件都能拷贝
*/
public class Copy1 {
public static void main(String[] args) {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream("C:\\Users\\77\\Downloads\\Documents\\07-JavaSE进阶每日复习与笔记\\day34课堂笔记.txt");
fos = new FileOutputStream("D:\\学习\\day34课堂笔记.txt");
//最核心的一边读一边写
byte[] bytes = new byte[1024*1024];
int readCount = 0;
while((readCount = fis.read(bytes)) != -1){
fos.write(bytes,0,readCount);
}
//输出流最后要刷新
fos.flush();
} catch (Exception e) {
e.printStackTrace();
}finally {
if (fos != null)
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
if(fis != null)
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
FileReader
文件字符输入流,只能读取普通文本。读取文本内容时,比较方便,快捷
package streamsIO;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
/*
FileReader:
文件字符输入流,只能读取普通文本。
读取文本内容时,比较方便,快捷
*/
public class FileReaderTest01 {
public static void main(String[] args) {
FileReader reader = null;
try {
reader = new FileReader("myfile.txt");
char[] chars = new char[4];//一次读取四个字符
reader.read(chars);
for (char c : chars){ //按照字符的方式读取,第一次a 第二次b 第三次 小
System.out.println(c);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if (reader!=null)
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
FileWriter
文件字符输出流—写,只能输出普通文本
package streamsIO;
import java.io.FileWriter;
import java.io.IOException;
/*
FileWriter:
文件字符输出流,写
只能输出普通文本
*/
public class FileWriterTest01 {
public static void main(String[] args) {
FileWriter out = null;
try {
//创建文件字符输出流对象
out = new FileWriter("file",true);
//开始写
char[] chars = {'1','x','3','小','七'};
out.write(chars);
out.write(chars,3,2);
out.write("\n");//换行
out.write("廿七小七");
//需要刷新
out.flush();
} catch (IOException e) {
e.printStackTrace();
}finally {
if (out != null)
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
拷贝普通文本文件
使用FileReader和FileWriter进拷贝的话,只能拷贝普通文本文件
package streamsIO;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
/*
使用FileReader和FileWriter进拷贝的话,只能拷贝普通文本文件
*/
public class Copy02 {
public static void main(String[] args) {
FileReader in = null;
FileWriter out = null;
try {
in = new FileReader("file");
out = new FileWriter("file1");
char[] chars = new char[1024 * 512];//1M
int readCount = 0;
while((readCount = in.read(chars))!= -1){
out.write(chars,0,readCount);
}
out.flush();
} catch (IOException e) {
e.printStackTrace();
}finally {
if(in!=null)
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
if(out!=null)
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
BufferedReader
带有缓冲区的字符输入流,使用这个流的时候不需要自定义char数组,或者说不需要自定义byte数组,自带缓冲
package streamsIO;
import lei.T;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
/*
BufferReader:
带有缓冲区的字符输入流
使用这个流的时候不需要自定义char数组,或者说不需要自定义byte数组,自带缓冲
*/
public class BuggeredReaderTest01 {
public static void main(String[] args) {
FileReader reader = null;
BufferedReader buf = null;
try {
reader = new FileReader("myfile.txt");
//当一个流的构造方法中需要一个流的时候,这个被传进来的流叫做:节点流
//外部负责包装的流,叫做包装流,还有一个名字叫做:处理流
//像当前这个程序来说,FileReader就是一个节点流,BufferReader就是处理流
buf = new BufferedReader(reader);
/*//读一行
String firstLine = buf.readLine();
System.out.println(firstLine);
//在读一行
String SecondLIne = buf.readLine();
System.out.println(SecondLIne);//读到最后一行的时候返回null*/
String s = null;
//readline方法读取文本的一行,但是不带换行符
while((s = buf.readLine())!=null){ // 没有读出来换行
System.out.println(s);
}
//关闭流
//对于包装流来说,只需要关闭包装流,里面的流会自动关闭
} catch (IOException e) {
e.printStackTrace();
}finally {
if (buf!=null)
try {
buf.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
字符流转换为字符
package streamsIO;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
public class BufferReadTest02 {
public static void main(String[] args) throws Exception {
FileInputStream fileInputStream = new FileInputStream("file");
//FileInputStream是一个字节流,不是一个字符流,BufferedReader里面需要传一个字符流
//BufferedReader buf = new BufferedReader(fileInputStream);
//fileInputStream是节点流,inputStreamReader是包装流
/*InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream);//将节点流转换为字符流
//inputStreamReader是节点流,bufferedReader是包装流
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);*/
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(fileInputStream));
//合并
String line = null;
while((line = bufferedReader.readLine())!=null){
System.out.println(line);
}
//关闭,关闭最外层
bufferedReader.close();
}
}
BufferedWriter
带有缓存的字符输出流
package streamsIO;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
/*
BufferWriter:带有缓存的字符输出流
*/
public class BufferWriterTest01 {
public static void main(String[] args) throws IOException {
BufferedWriter out = new BufferedWriter(new FileWriter("file2"));
out.write("xiaoqi");
out.write("\n");
out.write("1111");
out.flush();
out.close();
}
}
PrintStream
标准的字节输出流。默认输出到控制台
改变流的方向setOut
package streamsIO;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
/*
标准的字节输出流。默认输出到控制台
*/
public class PrintStreamTest {
public static void main(String[] args) throws FileNotFoundException {
//联合起写
System.out.println("hello word");
//分开写
PrintStream ps = System.out;
ps.println("hello l");
ps.println("hello l");
ps.println("hello a");
//标准输出流不需要手动关闭
//改变便准输出流的输出方向
/*
这些是之前System类的使用过的方法和属性
System.gc();
System.currentTimeMillis();
PrintStream ps1 = System.out;
System.exit();
*/
//标准输出流不再指向控制台,指向myfile文件
PrintStream printStream= new PrintStream(new FileOutputStream("myfile"));
System.setOut(printStream);
System.out.println("11");
System.out.println("222");
System.out.println("3333");
}
}
日志工具类的使用
package streamsIO;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.PrintStream;
import java.text.SimpleDateFormat;
import java.util.Date;
/*
日志工具
*/
public class LogUtil {
public static void log(String msg){
PrintStream out = null;
/*
记录日志的方法
*/
try {
out = new PrintStream(new FileOutputStream("log.txt",true));
//改变输出方向
System.setOut(out);
//日期当前时间
Date date = new Date();
//格式化
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");
String strtime= sdf.format(date);
System.out.println(strtime + ":" + msg);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
package streamsIO;
public class LogTest {
public static void main(String[] args) {
//测试工具类是否好用
LogUtil.log("调用了System类的gc方法,建议启动垃圾回收器");
LogUtil.log("调用了UserService的doSome()方法");
LogUtil.log("用户尝试进行登录,验证失败");
}
}
ObjectOutputStream
序列化和反序列化
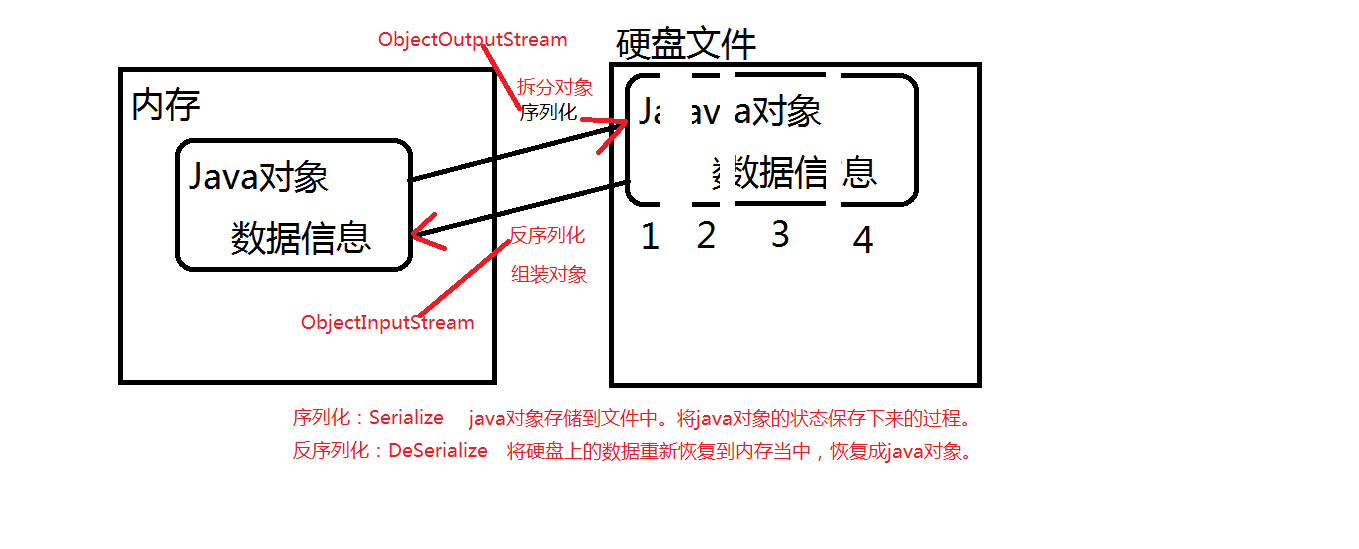
序列化
1.NotSerializableException: streamsIO.S: S类不支持序列化
2.参与序列化和反序列化的对象,必须实现Serializable这个接口
3.注意:通过源代码发现,Serializable接口只是一个标志接口
public interface Serializable{
}
这个接口当中什么代码也没有
他起到一个标志的作用,Java虚拟机,看到这个类实现了这个接口,可能会对这个类进行特殊待遇
java虚拟机看到了这个接口之后,会为该类自动生成一个序列化版本号。
序列化版本号:
如果更改了源代,在进行反序列会报错
java.io.InvalidClassException: streamsIO.S; local class incompatible:
stream classdesc serialVersionUID = 1419743757676022108,(之前的序列号)
local class serialVersionUID = -7501560671412578309(之后的序列号)
Java语言中是采用什么机制来区分类的?
第一:首先通过类名进行对比,如果类名不一样肯定不是同一个类
第二:如果类名一样,靠序列化号版本进行区分
序列化版本号是用来区分类的
不同的人编写了同一个类,但是这两个类不是同一个人编写的,这时候序列化就起作用了
对于Java虚拟机来说,Java虚拟机是可以区分开这两个类的,因为这两个类都实现了Serialaizeble接口
都有默认的序列化版本号,他们的序列化版本号不一样,所以区分开了(这是自动生成序列化版本号的好处)
自动生成的序列化版本号的缺陷:这种自动生成的序列化版本号缺点是:一旦代码确定之后,不能进行后续的修改,因为只要修改,必然要重新编译,
此时会生成全新的序列化版本号,这时候Java虚拟机会认为这是一个全新的类,这样是不好的
**结论:**凡是一个类实现了Serializable接口,建议给该类提供一个固定的序列化版本号,这样即使这个类的代码被修改了,但是版本号不变,java虚拟机会认为是同一个类
建议将序列化版本号手动的写出来,不建议自动生成
package streamsIO;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.Serializable;
/*
1.NotSerializableException: streamsIO.S: S类不支持序列化
2.参与学序列化和反序列化的对象,必须实现Serializable这个接口
3.注意:通过源代码发现,Serializable接口只是一个标志接口
public interface Serializable{
}
这个接口当中什么代码也没有
他起到一个标志的作用,Java虚拟机,看到这个类实现了这个接口,可能会对这个类进行特殊待遇
java虚拟机看到了这个接口之后,会为该类自动生成一个序列化版本号。
4.序列化版本号:
*/
public class ObjectOutputStreamTest01 {
public static void main(String[] args) {
S s = new S(111,"zz");
ObjectOutputStream objectOutputStream = null;
//序列化
try {
objectOutputStream = new ObjectOutputStream(new FileOutputStream("data"));
objectOutputStream.writeObject(s);
objectOutputStream.flush();
} catch (IOException e) {
e.printStackTrace();
}finally {
if (objectOutputStream!=null){
try {
objectOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
//继承一个可序列化接口
class S implements Serializable {
private int no;
private String name;
public S() {
}
public S(int no, String name) {
this.no = no;
this.name = name;
}
public int getNo() {
return no;
}
public String getName() {
return name;
}
public void setNo(int no) {
this.no = no;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "S{" +
"no=" + no +
", name=" + name +
'}';
}
}
序列化多个集合——list集合
package streamsIO;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
/*
一次序列化多个对象,可以把对象放到序列化集合当中
*/
public class ObjectOutputStreamTest02 {
public static void main(String[] args) throws Exception {
List<U> list = new ArrayList<>();
list.add(new U(1,"z"));
list.add(new U(2,"x"));
list.add(new U(3,"P"));
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("users"));
//序列化一个集合,一个集合有多个对象
oos.writeObject(list);
oos.flush();
oos.close();
}
}
class U implements Serializable {
private int number;
private String name;
public U() {
}
public U(int number, String name) {
this.number = number;
this.name = name;
}
public int getNumber() {
return number;
}
public String getName() {
return name;
}
public void setNumber(int number) {
this.number = number;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "U{" +
"number=" + number +
", name='" + name + '\'' +
'}';
}
}
反序列化
package streamsIO;
import java.io.*;
public class ObjectInputeStreamTest01 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("data"));
//反序列化
Object obj = objectInputStream.readObject();
//反序列化回来是一个学生对象的toString方法
System.out.println(obj);
objectInputStream.close();
}
}
反序列化多个集合——list集合
package streamsIO;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.util.ArrayList;
import java.util.List;
public class ObjectInputStreamTest02 {
public static void main(String[] args) throws Exception{
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("users"));
/*Object obj = ois.readObject();
System.out.println(obj instanceof List);*/
List<U> list = (List<U>) ois.readObject();//向下类型转换
for (U u:list){
System.out.println(u);
}
ois.close();
}
}
transient关键字
transient定义的变量,不参与序列化
File类
1.File类和四大家族没有关系,所有File类不能完成文件的读写
2.File对象代表,文件和路径名的抽象表示形式
C:\Users\77\Downloads\Documents\07-JavaSE进阶每日复习与笔记 是File对象、
一个File对象可能是目录也可能是文件
File只是一个路径名的抽象表示形式
3.掌握File类的常用方法
常用方法
boolean exists(); 测试此抽象路径名表示的文件或目录是否存在。
boolean createNewFile(); //以文件形式创建
boolean mkdir(); 创建此抽象路径名指定的目录。
boolean mkdirs(); 创建此抽象路径名指定的目录,包括所有必需但不存在的父目录。
String getAbsolutePath(); 返回此抽象路径名的绝对路径名字符串。
String getParent(); 返回此抽象路径名父目录的路径名字符串;如果此路径名没有指定父目录,则返回 null。
String getName() 返回由此抽象路径名表示的文件或目录的名称。
boolean isDirectory(); 测试此抽象路径名表示的文件是否是一个目录。
boolean isFile(); 测试此抽象路径名表示的文件是否是一个标准文件
long length(); 返回由此抽象路径名表示的文件的长度。
long lastModified(); 返回此抽象路径名表示的文件最后一次被修改的时间。
package streamsIO;
import java.io.File;
import java.io.IOException;
/*
File
1.File类和四大家族没有关系,所有File类不能完成文件的读写
2.File对象代表,文件和路径名的抽象表示形式
C:\Users\77\Downloads\Documents\07-JavaSE进阶每日复习与笔记 是File对象、
一个File对象可能是目录也可能是文件
File只是一个路径名的抽象表示形式
3.掌握File类的常用方法
*/
public class FileTest01 {
public static void main(String[] args) throws IOException {
File f1 = new File("D:\\file");
System.out.println(f1.exists());//判断是否存在的
//可以创建多重目录
File f2 = new File("D:\\file\\11");
//如果D盘先的file不存在 ,则以文件的形式创建出来
if(!f1.exists()){
//以文件形式创建
//f1.createNewFile();
f1.mkdir();//以目录的形式创建
}
if (!f2.exists()){
f2.mkdirs();
}
File f3 = new File("D:\\java\\javaSE\\log.txt");
String parentPath = f3.getParent();
System.out.println(parentPath);//D:\java\javaSE
File parentFile = f3.getParentFile();
System.out.println("获取绝对路径" + parentFile.getAbsolutePath());//获取绝对路径D:\java\javaSE
File f4 = new File("myfile");
System.out.println("绝对路径"+ f4.getAbsolutePath());//绝对路径D:\java\javaSE\myfile
}
}
package streamsIO;
import java.io.File;
import java.text.SimpleDateFormat;
import java.util.Date;
/*
File类的常用方法
*/
public class FileTest02 {
public static void main(String[] args) {
File f1 = new File("myfile");
//或取名文件
System.out.println(f1.getName());
//判断是否是一个目录
System.out.println(f1.isDirectory());
//判断是否是一个文件
System.out.println(f1.isFile());
//获取文件最后一次的修改时间
System.out.println(f1.lastModified());//返回的long是一个毫秒
//将毫秒转换为日期
Date time = new Date(f1.lastModified());
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss SSS");
String strtime = sdf.format(time);
System.out.println(strtime);
//获取文件大小的
System.out.println(f1.length());
}
}
File[] listFiles(); 返回一个抽象路径名数组,这些路径名表示此抽象路径名表示的目录中的文件。
package streamsIO;
import java.io.File;
/*
File中的listFiles方法
File[] listFiles()
返回一个抽象路径名数组,这些路径名表示此抽象路径名表示的目录中的文件。
*/
public class FileTest03 {
public static void main(String[] args) {
//File[] listFile()
//获取当前目录下的所有子文件
File f = new File("D:\\");
File[] files = f.listFiles();
for (File file:files){
System.out.println(file.getAbsoluteFile());//所有子文件
}
}
}
拷贝整个目录下的文件
package streamsIO;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class Copy03 {
public static void main(String[] args) {
//拷贝源和拷贝目标
//调用方法拷贝
File f1 = null;
File f2 = null;
f1 = new File("D:\\java\\javaSE");
f2 = new File("c:\\java");
CopyDir(f1,f2);
}
/**
* 拷贝目录
* @param src
* @param dest
*/
private static void CopyDir(File src, File dest) {
if (src.isFile()){
//src是一个文件的话,递归结束
//是文件的时候需要拷贝
FileInputStream fileInputStream = null;
FileOutputStream fileOutputStream = null;
try {
fileInputStream = new FileInputStream(src);
byte[] bytes = new byte[1024*1024];
String path = dest.getAbsolutePath().endsWith("\\")?dest.getAbsolutePath(): dest.getAbsolutePath() + "\\" + src.getAbsolutePath().substring(3);
fileOutputStream = new FileOutputStream(path);
int readCount = 0;
while((readCount = fileInputStream.read(bytes))!= -1){
fileOutputStream.write(bytes,0,readCount);
}
fileOutputStream.flush();
} catch (Exception e) {
e.printStackTrace();
}finally {
if (fileInputStream != null){
try {
fileInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fileOutputStream != null){
try {
fileOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return;
}
//获取源下面的子目录
File[] files = src.listFiles();
for (File file: files){
//System.out.println(file.getAbsolutePath());//获取所有文件的绝对路径
//可能是文件、可能是目录
if (file.isDirectory()){
String srcDir = file.getAbsolutePath();//获取源目录的绝对路径
//System.out.println(srcDir);
String destDir = dest.getAbsolutePath().endsWith("\\")?dest.getAbsolutePath(): dest.getAbsolutePath() + "\\" + srcDir.substring(3);
//System.out.println(destDir);
File newFile = new File(destDir);
if (!newFile.exists()){
newFile.mkdirs();
}
}
CopyDir(file,dest);
}
}
}
IO和Properties联合使用
IO流:文件的读和写。
Properties:是一个Map集合,key和value都是String类型。
非常好的设计理念:以后经常改变的数据,可以单独写到一个文件中,使用程序动态的读取,将来只需要修改这个文件的内容,Java代码不需要改动,不需要重新编译,服务器也不需要重新重启,就可以拿到动态的信息。类似于以上机制的这种文件被称为配置文件
并且当配置文件中的内容格式是:
key = value
的时候,我们把这种配置文件叫做属性配置文件
java规范中要求,属性配置文件建议以properties结尾,但是不是必须的
这种以properties对象是专门存放属性配置文件内容的一个类
package streamsIO;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.util.Properties;
/*
IO和Properties联合使用
非常好的设计理念:以后经常改变的数据,可以单独写到一个文件中,使用程序动态的读取
将来只需要修改这个文件的内容,Java代码不需要改动,不需要重新编译,服务器也不需要重新重启,就可以拿到动态的信息
类似于以上机制的这种文件被称为配置文件
并且当配置文件中的内容格式是:
key = value
的时候,我们把这种配置文件叫做属性配置文件
java规范中要求,属性配置文件建议以properties结尾,但是不是必须的
这种以properties对象是专门存放属性配置文件内容的一个类
*/
public class IOPropertiesTest01 {
public static void main(String[] args) throws Exception {
/*
Properties是一个Map集合,key和value都是String类型。
想将userinfo文件中的数据加载到Properties对象当中。
*/
//新建一个输入流对象
FileReader fileReader = new FileReader("demo\\src\\streamsIO\\userinfo.properties");
//新建一个Map集合
Properties properties = new Properties();
//调用Properties对象的load方法将文件中的数据加载到Map集合当中
properties.load(fileReader);//文件中的数据顺着管道,加载到Map集合中,其中=左边作为key,右边作为value username = admin
//通过key来获取value
System.out.println(properties.getProperty("username"));
System.out.println(properties.getProperty("password"));
}
}
属性配置文件
username=admin
password=123
##########在属性配置文件中#是注释#############
#属性配置文件的key重复的话,value会覆盖
#属性配置文件中可以有空格,但是最好不要有空格
#不建议中间使用:
#建议中间使用=的格式
多线程
线程和进程
进程是一个应用程序(1个进程是一个软件)。线程是一个进程中的执行场景/执行单元。
一个进程可以启动多个线程。
对于java程序来说,当在DOS命令窗口中输入:
java HelloWorld 回车之后。会先启动JVM,而JVM就是一个进程。
JVM再启动一个主线程调用main方法。同时再启动一个垃圾回收线程负责看护,回收垃圾。
最起码,现在的java程序中至少有两个线程并发,
一个是垃圾回收线程,一个是执行main方法的主线程。
进程和线程的关系
进程可以看做是现实生活当中的公司,线程可以看做是公司当中的某个员工。
注意:
进程A和进程B的内存独立不共享。(阿里巴巴和京东资源不会共享的!)
魔兽游戏是一个进程
酷狗音乐是一个进程
这两个进程是独立的,不共享资源
线程A和线程B呢?
在java语言中:
线程A和线程B,堆内存和方法区内存共享。
但是栈内存独立,一个线程一个栈。
假设启动10个线程,会有10个栈空间,每个栈和每个栈之间,互不干扰,各自执行各自的,这就是多线程并发。多线程并发可以提高效率,java中之所以有多线程机制,目的就是为了提高程序的处理效率。
使用了多线程机制之后,main方法结束,是不是有可能程序也不会结束。main方法结束只是主线程结束了,主栈空了,其它的栈(线程)可能还在压栈弹栈。
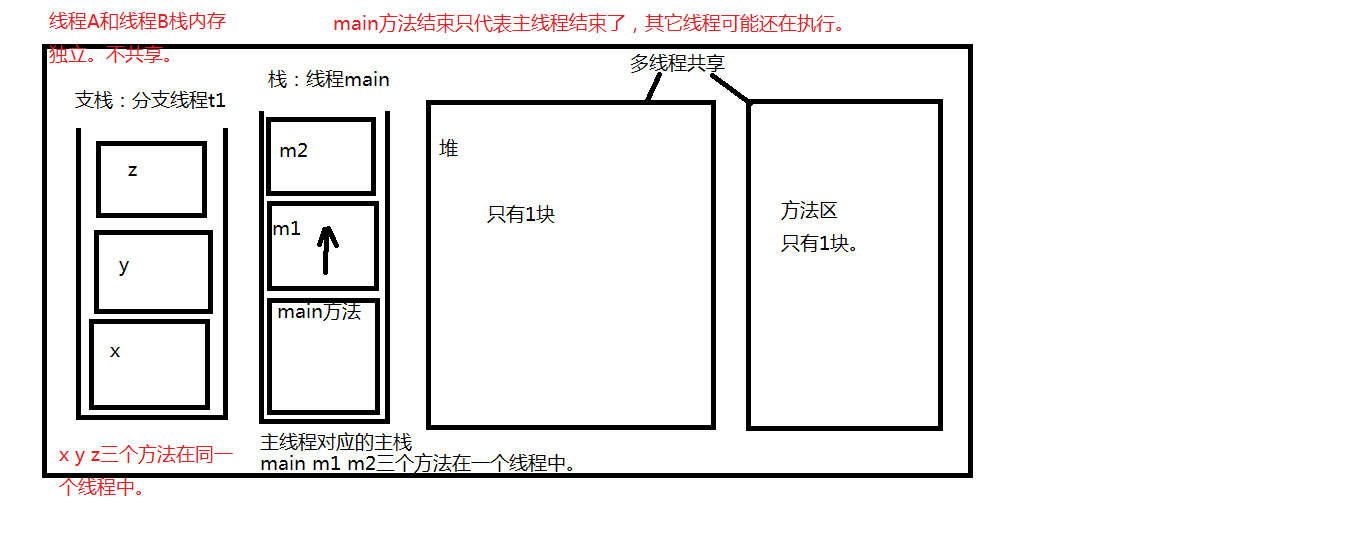
单核CPU和多核CPU
对于单核的CPU来说,真的可以做到真正的多线程并发吗?
对于多核的CPU电脑来说,真正的多线程并发是没问题的。4核CPU表示同一个时间点上,可以真正的有4个进程并发执。
什么是真正的多线程并发?
t1线程执行t1的。
t2线程执行t2的。
t1不会影响t2,t2也不会影响t1。这叫做真正的多线程并发。
单核的CPU表示只有一个大脑:
不能够做到真正的多线程并发,但是可以做到给人一种“多线程并发”的感觉。
对于单核的CPU来说,在某一个时间点上实际上只能处理一件事情,但是由于CPU的处理速度极快,**多个线程之间频繁切换执行,**跟人来的感觉是:多个事情同时在做!!!!!
线程A:播放音乐
线程B:运行魔兽游戏
线程A和线程B频繁切换执行,人类会感觉音乐一直在播放,游戏一直在运行,
给我们的感觉是同时并发的。
package thread;
/*
分析程序有几个线程,除垃圾回收之外,有几个线程
一个线程(因为程序只有一个栈)
一个main方法中调用m1,m1调用m2,m2调用m3 都在一个栈中
*/
public class ThereadTest01 {
public static void main(String[] args) {
System.out.println("main begin");
m1();
System.out.println("main over");
}
private static void m1() {
System.out.println("m1 begin");
m2();
System.out.println("m1 over");
}
private static void m2() {
System.out.println("m2 begin");
m3();
System.out.println("m3 over");
}
private static void m3() {
System.out.println("m3 exceute");
}
}
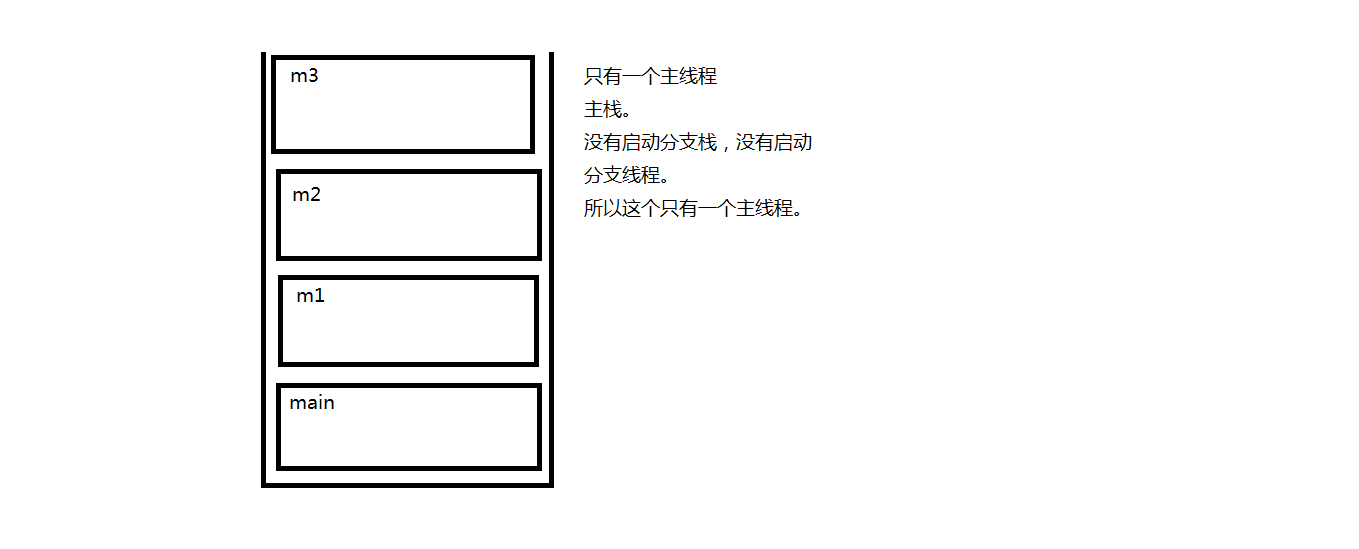
实现线程的两种方式
第一种方式
第一种方式:编写一个类,直接继承java.lang.Thread,重写run方法。
// 定义线程类
public class MyThread extends Thread{
public void run(){
}
}
// 创建线程对象
MyThread t = new MyThread();
// 启动线程。
t.start();
package thread;
/*
实现线程的第一种方式:
编写一个类,直接继承java.lang。Thread,重写run方法
void run()
如果该线程是使用独立的 Runnable 运行对象构造的,则调用该 Runnable 对象的 run 方法;否则,该方法不执行任何操作并返回。
如何创建线程? new就可以了
怎么启动线程? 调用线程对象的short()方法
*/
public class ThreadTest02 {
public static void main(String[] args) {
//这里是main方法。这里的代码属于主线程,在主栈中运行
//新建一个分支线程对象
MyThread myThread = new MyThread();
//启动线程
myThread.start();
//这里的代码还是运行在主线程中
}
class MyThread extends Thread{
public void run(){
//编写程序,这段程序运行在分支线程中
}
}
直接调用run方法的时候栈
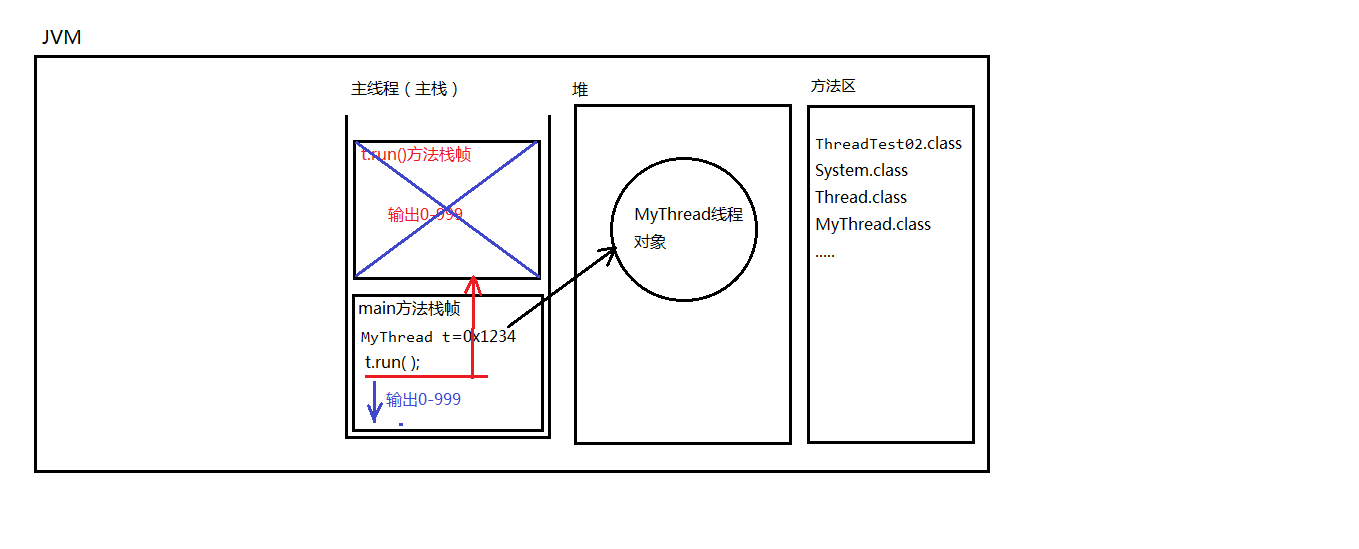
调用start方法的时候栈
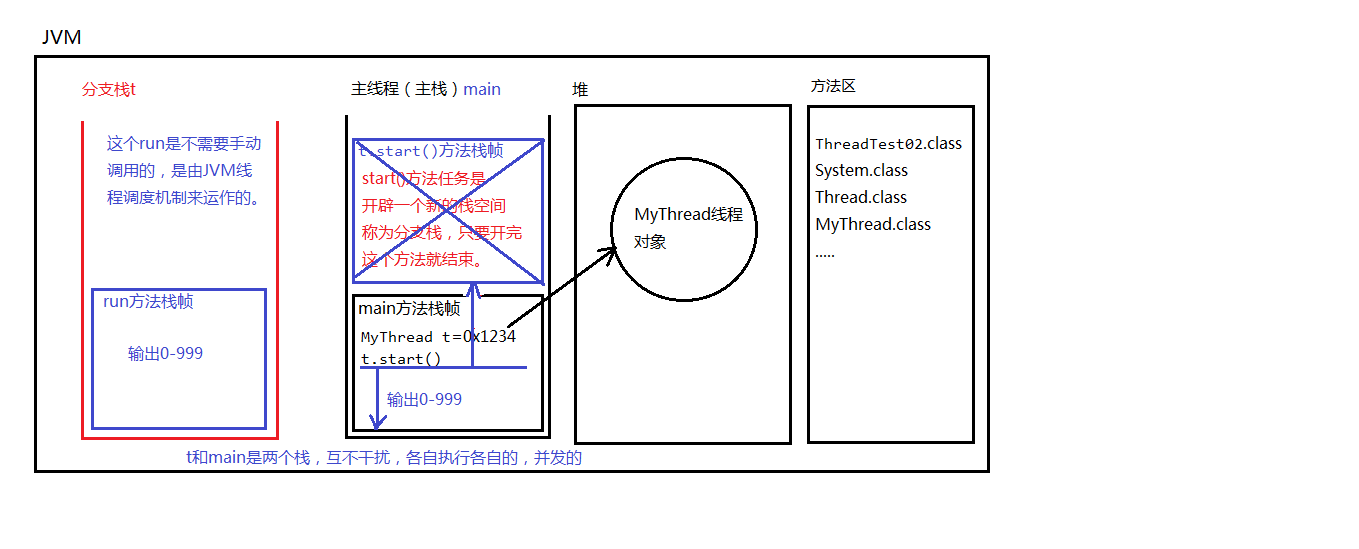
package thread;
/*
实现线程的第一种方式:
编写一个类,直接继承java.lang。Thread,重写run方法
void run()
如果该线程是使用独立的 Runnable 运行对象构造的,则调用该 Runnable 对象的 run 方法;否则,该方法不执行任何操作并返回。
如何创建线程? new就可以了
怎么启动线程? 调用线程对象的short()方法
注意:
方法体当中的代码永远都是自上而下的顺序依次逐行执行的
以下程序的输出结果有这样的特点:
有先有后,有多有少
*/
public class ThreadTest02 {
public static void main(String[] args) {
//这里是main方法。这里的代码属于主线程,在主栈中运行
//新建一个分支线程对象
MyThread myThread = new MyThread();
//启动线程
//myThread.run(); //如果只调用run方法不会启动线程,不会分配新的分支栈(这种方式就是单线程)
//start()方法的作用是:启动一个分支线程,在JVM中开辟一个新的栈空间,这段代码瞬间就结束
//这段代码的任务只是为了开启新的栈空间,只要新的栈空间开出来了,start()方法就结束了,线程就启动成功了。
//启动成功的线程就自动调用run方法,并且run方法在分支栈的底部(压栈)
//run方法在分支栈的栈底部,main方法在主栈的栈底部,run和main是平级的
myThread.start();
//这里的代码还是运行在主线程中
for (int i = 0; i<1000;i++){
System.out.println("主线程 --->" + i);
}
}
}
class MyThread extends Thread{
public void run(){
//编写程序,这段程序运行在分支线程中
for (int i = 0; i<1000;i++){
System.out.println("分支线程 --->" + i);
}
}
}
第二种方式(建议使用)
第二种方式:实现java.lang.Runnable接口,实现run方法
package thread;
/*
实现线程的第二种方式,编写一个类实现java.lang.Runnable接口
*/
public class ThreadTest03 {
public static void main(String[] args) {
//创建一个可运行的对象
//MyRunnable myRunnable = new MyRunnable();
//将可运行的对象封装成一个线程对象
Thread thread = new Thread(new MyRunnable());//合并之后的代码
//启动线程
thread.start();
for (int i = 0; i<1000;i++){
System.out.println("主线程 --->" + i);
}
}
}
//这并不是一个线程类,是一个可运行的类,他还不是一个线程
class MyRunnable implements Runnable{
@Override
public void run() {
for (int i = 0; i<1000;i++){
System.out.println("分支线程 --->" + i);
}
}
}
这种方式比较常用,一个类实现了接口,他还可以去继承其他的类,更加的灵活
使用匿名内部类来创建线程
package thread;
import lei.T;
/*
采用匿名内部类
*/
public class ThreadTese04 {
public static void main(String[] args) {
//创建线程对象,采用匿名内部类的方式
Thread thered = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i<1000;i++){
System.out.println("分支线程 --->" + i);
}
}
});
//启动线程
thered.start();
for (int i = 0; i<1000;i++){
System.out.println("主线程 --->" + i);
}
}
}
线程生命周期
新建状态,就绪状态,运行状态,死亡状态

1.怎么获取当前线程对象
Thiead t = Thread.currentThread();
返回值t就是当前线程
2.获取线程对象的名字
线程对象。getName()
3.修改线程对象的名字
线程对象。setName(“线程名字”)
4.线程的默认名字
当没有设置线程名称的时候,线程的默认名字为:
Thread-0
Thread-1
package thread;
/*
1.怎么获取当前线程对象
Thiead t = Thread.currentThread();
返回值t就是当前线程
2.获取线程对象的名字
线程对象。getName()
3.修改线程对象的名字
线程对象。setName("线程名字")
4.当没有设置线程名称的时候,线程的默认名字为
Thread-0
Thread-1
*/
public class ThreadTest05 {
public static void main(String[] args) {
//current就是当前线程
//这个方法出现在主线程中,这就是主线程
Thread current = Thread.currentThread();
System.out.println(current.getName());//main 主方法名字
//创建线程对象
M m = new M();
M m2 = new M();
//设置线程的名字
m.setName("m1");
m2.setName("m2");
//获取线程的名字
System.out.println(m.getName());//默认名字Thread-0
System.out.println(m2.getName());
//启动线程
m.start();
m2.start();
}
}
class M extends Thread{
@Override
public void run() {
for (int i = 0; i<10;i++){
//current就是当前线程
//当m线程执行run方法,当前线程就是m
//当m2线程执行,当前线程就是m2
Thread current = Thread.currentThread();
//System.out.println(current.getName() + " "+ i);
//System.out.println(super.getName() + " "+ i);
System.out.println(this.getName() + " "+ i);
}
}
}
5.sleep方法
关于线程的sleep方法:
static void slep(long millis)
1.静态方法 Thread.sleep(1000);
2.参数是毫秒
3.作用:让当前线程进入休眠状态,进入休眠状态,放弃占有cpu时间片,让给其他线程使用出现在那个线程中,就让那个线程休眠
4.Thread.sleep() 可以达到这种效果: 间隔一定的时间,去执行一段特定的代码。
package thread;
import lei.T;
/*
关于线程的sleep方法:
static void slep(long millis)
1.静态方法 Thread.sleep(1000);
2.参数是毫秒
3.作用:让当前线程进入休眠状态,进入休眠状态,放弃占有cpu时间片,让给其他线程使用
出现在那个线程中,就让那个线程休眠
4.Thread.sleep() 可以达到这种效果: 间隔一定的时间,去执行一段特定的代码。
*/
public class ThreadTest06 {
public static void main(String[] args) {
/*try {
//让当前线程进入休眠
Thread.sleep(1000*5);
} catch (InterruptedException e) {
e.printStackTrace();
}
//5秒后执行
System.out.println("hello word");*/
for (int i =0;i<10;i++){
System.out.println(Thread.currentThread().getName() + " --- >" + i);
//睡眠一秒,执行一次
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
package thread;
/*
关于sleep方法
*/
public class ThreadTest07 {
public static void main(String[] args) {
M1 m = new M1();
m.setName("m");
m.start();
//调用sleep方法
try {
m.sleep(1000);//在执行的时候还是会转换成 Thread.sleep() 这行代码的作用是当前线程进入休眠,main方法进入休眠
//这行代码出现在main方法中,main线程休眠
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("hello world");
}
}
class M1 extends Thread{
@Override
public void run() {
for (int i =0;i<10;i++){
System.out.println(Thread.currentThread().getName() + " --> " + i);
}
}
}
唤醒正在睡眠的线程
t.interrupt();
package thread;
/*
唤醒一个正在睡眠的线程,这个不是中断线程的执行,是终止线程的睡眠
*/
public class ThreadTest08 {
public static void main(String[] args) {
Thread t = new Thread(new MyRunnable2());
t.setName("t");
t.start();
//希望5秒之后t线程醒来
try {
Thread.sleep(1000*5);
} catch (InterruptedException e) {
e.printStackTrace();
}
//中断t线程的睡眠(这种中断睡眠方式,依靠了java异常的处理机制)
t.interrupt();//干扰
}
}
class MyRunnable2 implements Runnable{
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "--> begin");
//这块只能try catch 子类不能比父类抛出更多的异常
try {
Thread.sleep(1000*60*60);
} catch (InterruptedException e) {
//打印异常信息
//e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "---> end");
//调用doOther
try {
doOther();
} catch (Exception e) {
e.printStackTrace();
}
}
//其他的方法可以throws
public void doOther() throws Exception{
}
}
6.终止线程
stop方法不建议使用
package thread;
/*
在java中强行终止一个线程
这种方式有很大的缺点:容易丢失数据,,因为这种方式是直接将线程杀死
线程没有保存的数据会丢失,不建议使用
*/
public class ThreadTest09 {
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable3());
thread.setName("t");
thread.start();
//模拟5秒睡眠
try {
Thread.sleep(1000*5);
} catch (InterruptedException e) {
e.printStackTrace();
}
//5秒之后强行终止t线程
thread.stop();//已过时
}
}
class MyRunnable3 implements Runnable{
@Override
public void run() {
for (int i =0;i<10;i++){
System.out.println(Thread.currentThread().getName() + "-->" + i);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
布尔方法建议使用
package thread;
/*
合理终止线程
*/
public class ThreadTest10 {
public static void main(String[] args) {
MyRunnable4 myRunnable4 = new MyRunnable4();
Thread thread = new Thread(myRunnable4);
thread.setName("t");
thread.start();
//模拟五秒
try {
Thread.sleep(1000*5);
} catch (InterruptedException e) {
e.printStackTrace();
}
//终止线程
//想要什么时候终止t的执行,修改run为false
myRunnable4.run = false;
}
}
class MyRunnable4 implements Runnable{
boolean run = true;//设置一个布尔标记
@Override
public void run() {
for (int i =0; i<10;i++) {
if (run) {
System.out.println(Thread.currentThread().getName() + "--->" + i);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
else{
//return就结束了,在结束之前还有什么没有保存的,在这里就可以保存
//save
return;
}
}
}
}
关于线程的调度
常见的调度模式
抢占式调度模型:
那个线程的优先级比较高,抢到的CPU时间片的概率就高一些/多一些。
java采用的就是抢占式调度模型。
均分式调度模型:
平均分配CPU时间片。每个线程占有的CPU时间片时间长度一样。
平均分配,一切平等。
有一些编程语言,线程调度模型采用的是这种方式
关于线程调度的方法
实例方法:
void setPriority(int newPriority) 设置线程的优先级
int getPriority() 获取线程优先级
最低优先级1
默认优先级是5
最高优先级10
优先级比较高的获取CPU时间片可能会多一些。(但也不完全是,大概率是多的。)
静态方法:
static void yield() 让位方法
暂停当前正在执行的线程对象,并执行其他线程
yield()方法不是阻塞方法。让当前线程让位,让给其它线程使用。
yield()方法的执行会让当前线程从“运行状态”回到“就绪状态”。
注意:在回到就绪之后,有可能还会再次抢到。
实例方法:
void join() ,合并线程
class MyThread1 extends Thread {
public void doSome(){
MyThread2 t = new MyThread2();
t.join(); // 当前线程进入阻塞,t线程执行,直到t线程结束。当前线程才可以继续。
}
}
class MyThread2 extends Thread{
}
线程安全(重点)
在以后的开发中,我们的项目都是运行在服务器当中,二服务器已经将线程的定义,线程对象的创建,线程的启动等,都已经实现完了。这些代码我们都不需要编写。最重要的是,编写的代码需要放到一个多线程的环境下运行,更需要关注的是这些数据在多线程并发的环境下是否是安全的。
多线程并发的问题
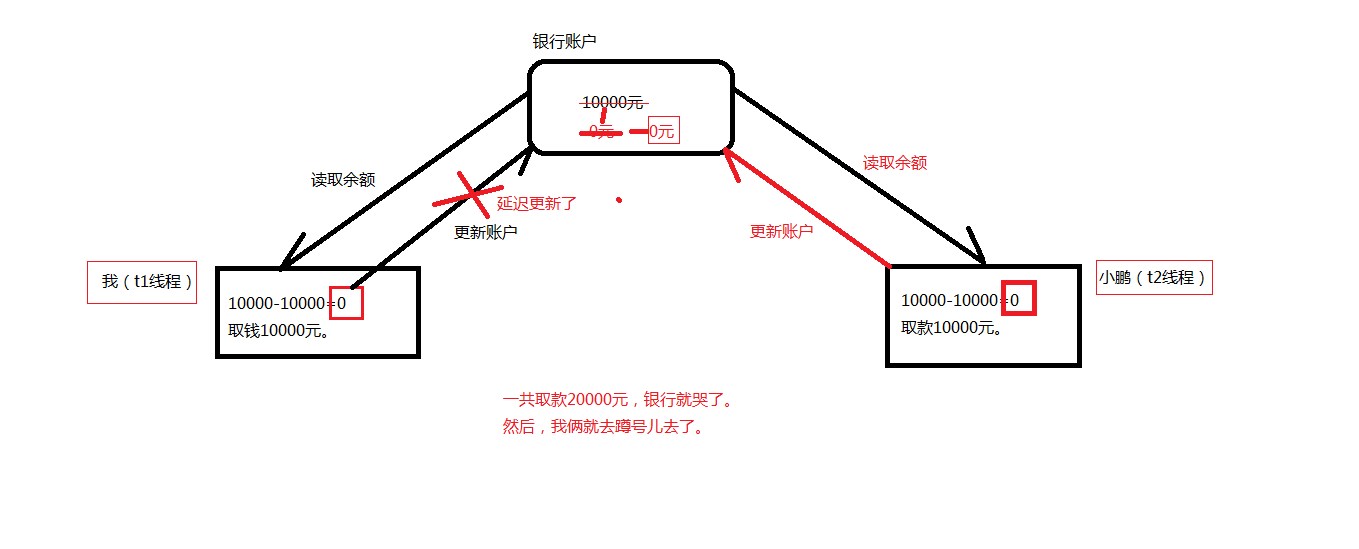
什么时候出现线程安全问题
三个条件:
条件1:多线程并发。
条件2:有共享数据。
条件3:共享数据有修改的行为。
满足以上3个条件之后,就会存在线程安全问题。
解决线程安全问题
在多线程并发的环境下,有共享数据,并且这个数据还会被修改,此时就存在线程安全的问题,解决线程的安全问题:
线程排队执行(不能并发)
这种排队执行解决线程安全问题
这种机制被称为:线程同步机制
解决线程安全问题:使用线程同步机制
线程同步就是线程排队了,线程排队就会牺牲一部分效率,数据安全第一位,只有数据安全了,才可以提高效率
涉及到的专业术语
异步编程模型:
线程t1和线程t2,各自执行各自的,t1不管t2,t2不管t1,谁也不需要等谁,这种编程模型叫做:异步编程模型
其实就是:多线程并发,效率高
异步就是并发
同步编程模型:
线程t1和线程t2,在线程t1执行的时候,必须等待t2线程执行结束,或者说在t2执行的时候必须等待t1线程执行结束,两个线程之间发生了等待关系,这就是同步编程模型,效率低,线程排队执行
同步就是排队
线程安全的例子
线程不安全
package TgreadSAFE;
/*
不使用线程同步机制,多线程对同一个账户进行取款,出现了线程安全问题
*/
public class Account {
private String acton;//账户
private double balance;//余额
public Account() {
}
public Account(String acton, double balance) {
this.acton = acton;
this.balance = balance;
}
public String getActon() {
return acton;
}
public double getBalance() {
return balance;
}
public void setActon(String acton) {
this.acton = acton;
}
public void setBalance(double balance) {
this.balance = balance;
}
//取款方法
public void withdraw(double money){
//取款之前的余额
double before = this.balance;
//取款之后的余额
double after = before - money;
//模拟一下网络延迟,100%初出问题
try {
Thread.sleep(1000*5);
} catch (InterruptedException e) {
e.printStackTrace();
}
//更新余额
this.setBalance(after);
}
}
package TgreadSAFE;
public class AccountThread extends Thread {
//两个线程必须共享一个账户对象
private Account account;
//通过构造方法来传递账户对象
public AccountThread(Account account){
this.account = account;
}
@Override
public void run() {
//run方法的执行表示取款
double money = 5000;
//多线程并发执行这个方法(t1和t2两个栈)
account.withdraw(money);
System.out.println(Thread.currentThread().getName() + "余额:" + account.getBalance());
}
}
package TgreadSAFE;
public class Test01 {
public static void main(String[] args) {
//创建账户对象(只有一个)
Account account = new Account("001",10000);
//创建了两个线程,共享一个账户
AccountThread accountThread1 = new AccountThread(account);
AccountThread accountThread2 = new AccountThread(account);
//设置name
accountThread1.setName("t1");
accountThread2.setName("t2");
//启动取款
accountThread1.start();
accountThread2.start();
}
}
解决线程安全的方法
线程同步机制的语法:
synchronized (){
//线程同步机制代码块
}
() 传的数据必须是多线程共享的数据,才能达到多线程排队
() 中写什么?
那要看你想要哪些线程同步
假设有t1,t2,t3,t4,t5,有5个线程
你只希望t1 t2 t3排队,t4 t5不需要排队,怎么办?
你一定要在()中传入t1 t2 t3共享的对象,这个对象对于t4 t5不是共享的
package ThreadSafe2;
/*
使用线程同步机制,多线程对同一个账户进行取款,解决线程安全问题
*/
public class Account {
private String acton;//账户
private double balance;//余额
public Account() {
}
public Account(String acton, double balance) {
this.acton = acton;
this.balance = balance;
}
public String getActon() {
return acton;
}
public double getBalance() {
return balance;
}
public void setActon(String acton) {
this.acton = acton;
}
public void setBalance(double balance) {
this.balance = balance;
}
//取款方法
public void withdraw(double money){
//以下这几行代码必须是线程排队的不能并发
//一个线程把这里的代码全部执行结束之后,另一个线程才能进来
/*
线程同步机制的语法:
synchronized (){
//线程同步机制代码块
}
传的数据必须是多线程共享的数据,才能达到多线程排队
()中写什么?
那要看你想要哪些线程同步
假设有t1,t2,t3,t4,t5,有5个线程
你只希望t1 t2 t3排队,t4 t5不需要排队,怎么办?
你一定要在()中传入t1 t2 t3共享的对象,这个对象对于t4 t5不是共享的
*/
//账户对象是共享的,this就是账户对象
synchronized (this){
//取款之前的余额
double before = this.balance;
//取款之后的余额
double after = before - money;
//模拟一下网络延迟,100%初出问题
try {
Thread.sleep(1000*5);
} catch (InterruptedException e) {
e.printStackTrace();
}
//更新余额
this.setBalance(after);
}
}
}
在java语言中,任何一个对象都有一把“锁”,其实这把锁就是标记(只是把它叫做锁)
100个对象100把锁
以下代码的执行原理:
1.假设t1和t2线程并发,开始执行以下代码的时候,肯定有一个先有一个后
2.假设t1先执行了,遇到 synchronized,这时候自动找后面共享对象的对象锁
找到之后,并占有这把锁,然后执行同步代码块中的程序,在执行过程中一直都是占有这把锁的,直到同步代码块代码结束,
这把锁才会释放
3.假设t1已经占有这把锁,此时t2也遇到了 synchronized关键字,也会去占有后面共享对象的这把锁,结果这把锁被t1占有,
t2只能在同步代码块外面等待t1的结束,直到t1把同步代码块执行结束,t1会归还这把锁,此时t2等到这把锁,t2占有这把锁之后,
进入同步代码块执行程序
这样就达到了线程排队执行
这里需要注意的是:共享的对象一定是要选好了。这个共享的对象一定是你需要排队执行的这些线程对象共享的。
synchronized (this){
//取款之前的余额
double before = this.balance;
//取款之后的余额
double after = before - money;
//模拟一下网络延迟,100%初出问题
try {
Thread.sleep(1000*5);
} catch (InterruptedException e) {
e.printStackTrace();
}
//更新余额
this.setBalance(after);
}
java中的三大变量的安全问题
实例变量:堆
局部变量:栈
静态变量:方法区
以上三大变量中,局部变量永远都不存在安全问题,因为局部变量不共享。常量也不会有线程安全问题
实例变量在堆中,静态变量在方法区中,堆和方法区只有一个,
堆和方法区都是多线程共享的,所以可能存在线程安全问题
扩大安全同步的范围
在run中把withdraw方法进行同步,扩大了同步范围,效率更低
package ThreadSafe2;
public class AccountThread extends Thread {
//两个线程必须共享一个账户对象
private Account account;
//通过构造方法来传递账户对象
public AccountThread(Account account){
this.account = account;
}
@Override
public void run() {
//run方法的执行表示取款
double money = 5000;
//多线程并发执行这个方法(t1和t2两个栈)
//扩大线程同步范围
synchronized (account){
account.withdraw(money);
}
System.out.println(Thread.currentThread().getName() + "余额:" + account.getBalance());
}
}
在实例方法上使用synchronized
在实例方法中加入synchronized
synchronized 出现在实例方法上。一定锁的是this,所以这种方式不灵活;
还有一个缺点:synchronized出现在实例方法上,表示整个方法都需要同步,可能会无故扩大同步的范围,可能会导致程序的效率降低,所以这种方式不常用
synchronized 出现在实例方法中的好处: 代码写的比较少,节俭了。
如果共享的对象就是this,并且需要同步的代码块是整个方法体,建议使用这种方式
package ThreadSafe3;
public class Account {
private String acton;//账户
private double balance;//余额
Object object = new Object();//实例变量(Account是多线程共享的,Account中的实例变量object也是共享的)
public Account() {
}
public Account(String acton, double balance) {
this.acton = acton;
this.balance = balance;
}
public String getActon() {
return acton;
}
public double getBalance() {
return balance;
}
public void setActon(String acton) {
this.acton = acton;
}
public void setBalance(double balance) {
this.balance = balance;
}
//取款方法
//在实例方法中加入synchronized
//synchronized 出现在实例方法上。一定锁的是this,所以这种方式不灵活,
//还有一个缺点:synchronized出现在实例方法上,表示整个方法都需要同步,可能会无故扩大同步的范围,可能会导致程序的效率降低,所以这种方式不常用
//synchronized 出现在实例方法中的好处: 代码写的比较少,节俭了
//如果共享的对象就是this,并且需要同步的代码块是整个方法体,建议使用这种方式
public synchronized void withdraw(double money){
double before = this.balance;
double after = before - money;
try {
Thread.sleep(1000*5);
} catch (InterruptedException e) {
e.printStackTrace();
}
this.setBalance(after);
}
}
如果使用局部变量的话,建议使用StringBuilder,因为局部变量不存在线程安全问题,选择StringBuffer效率便较低。
ArrayList是非线程安全的,Vector是线程安全的
HshMap、HashSet是非线程安全的 ,HashTable是线程安全的。
总结
synchronized有三种写法:
第一种:同步代码块,灵活
synchronized(线程共享对象){
同步代码块;
}
第二种:在实例方法上使用synchronized
表示共享对象一定是this
并且同步代码块是整个方法体。
第三种:在静态方法上使用synchronized
表示找类锁。
类锁永远只有1把。
就算创建了100个对象,那类锁也只有一把。
对象锁:1个对象1把锁,100个对象100把锁。
类锁:100个对象,也可能只是1把类锁。
面试题
package ThreadExam1;
/*
t2不需要等到t1执行,只有doSome有锁
*/
public class Test01 {
public static void main(String[] args) {
M m = new M();
Thread t1 = new MyThread(m);
Thread t2 = new MyThread(m);
t1.setName("t1");
t2.setName("t2");
t1.start();
try {
Thread.sleep(1000);//保证t1线程先执行
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.start();
}
}
class MyThread extends Thread{
private M m;
public MyThread(M m){
this.m = m;
}
public void run(){
if(Thread.currentThread().getName() == "t1"){
m.doSome();
}
if(Thread.currentThread().getName() == "t2"){
m.doOther();
}
}
}
class M {
public synchronized void doSome(){//线程安全的方法
System.out.println("doSome begin");
try {
Thread.sleep(1000*10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("doSome over");
}
public void doOther(){//非线程安全的方法
System.out.println("doOther begin");
System.out.println("doOther over");
}
}
package ThreadExam2;
/*
t2需要等t1执行结束,doSome和doOther都是this这把锁
*/
public class Test01 {
public static void main(String[] args) {
M m = new M();
Thread t1 = new MyThread(m);
Thread t2 = new MyThread(m);
t1.setName("t1");
t2.setName("t2");
t1.start();
try {
Thread.sleep(1000);//保证t1线程先执行
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.start();
}
}
class MyThread extends Thread{
private M m;
public MyThread(M m){
this.m = m;
}
public void run(){
if(Thread.currentThread().getName() == "t1"){
m.doSome();
}
if(Thread.currentThread().getName() == "t2"){
m.doOther();
}
}
}
class M {
public synchronized void doSome(){//锁 是 this
System.out.println("doSome begin");
try {
Thread.sleep(1000*10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("doSome over");
}
public synchronized void doOther(){//锁 是 this
System.out.println("doOther begin");
System.out.println("doOther over");
}
}
package ThreadExam3;
/*
两个线程对象,所以t2不需要等t1执行
*/
public class Test01 {
public static void main(String[] args) {
M m = new M();
M m1 = new M();
Thread t1 = new MyThread(m);
Thread t2 = new MyThread(m1);
t1.setName("t1");
t2.setName("t2");
t1.start();
try {
Thread.sleep(1000);//保证t1线程先执行
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.start();
}
}
class MyThread extends Thread{
private M m;
public MyThread(M m){
this.m = m;
}
public void run(){
if(Thread.currentThread().getName() == "t1"){
m.doSome();
}
if(Thread.currentThread().getName() == "t2"){
m.doOther();
}
}
}
class M {
public synchronized void doSome(){//锁 是 this
System.out.println("doSome begin");
try {
Thread.sleep(1000*10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("doSome over");
}
public synchronized void doOther(){//锁 是 this
System.out.println("doOther begin");
System.out.println("doOther over");
}
}
package ThreadExam4;
/*
静态方法是类锁,所以t2需要等t1执行
*/
public class Test01 {
public static void main(String[] args) {
M m = new M();
M m1 = new M();
Thread t1 = new MyThread(m);
Thread t2 = new MyThread(m1);
t1.setName("t1");
t2.setName("t2");
t1.start();
try {
Thread.sleep(1000);//保证t1线程先执行
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.start();
}
}
class MyThread extends Thread{
private M m;
public MyThread(M m){
this.m = m;
}
public void run(){
if(Thread.currentThread().getName() == "t1"){
m.doSome();
}
if(Thread.currentThread().getName() == "t2"){
m.doOther();
}
}
}
class M {
public synchronized static void doSome(){//锁 是 this
System.out.println("doSome begin");
try {
Thread.sleep(1000*10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("doSome over");
}
public synchronized static void doOther(){//锁 是 this
System.out.println("doOther begin");
System.out.println("doOther over");
}
}
死锁现象
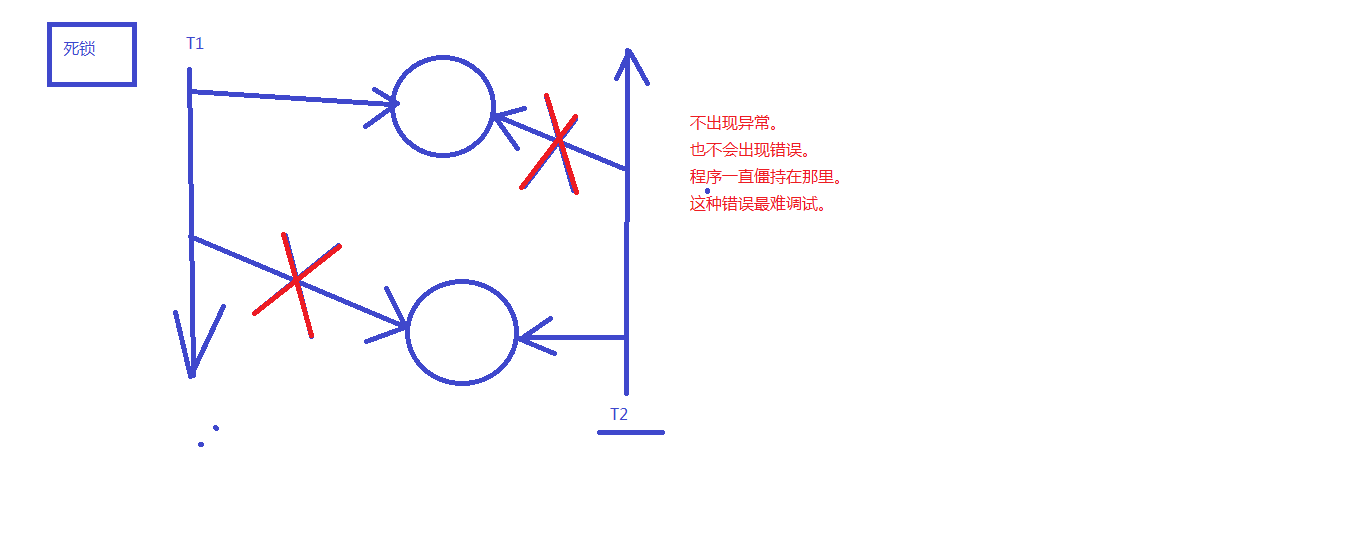
package DeadLock;
import lei.T;
/*
死锁代码要会写
只有会写的,才会在以后的开发中注意这个事情
因为死锁很难调试
*/
public class DeadLock {
public static void main(String[] args) {
Object o1 = new Object();
Object o2 = new Object();
//t1和t2共享o1 和 o2
Thread t1 = new Mythread(o1,o2);
Thread t2 = new Mythread2(o1,o2);
t1.start();
t2.start();
}
}
class Mythread extends Thread{
Object o1;
Object o2;
public Mythread(Object o1,Object o2){
this.o1 = o1;
this.o2 = o2;
}
public void run(){
synchronized (o1){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (o2){
}
}
}
}
class Mythread2 extends Thread{
Object o1;
Object o2;
public Mythread2(Object o1,Object o2){
this.o1 = o1;
this.o2 = o2;
}
public void run(){
synchronized (o2){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (o1){
}
}
}
}
开发中如何解决线程安全问题
是一上来就选择线程同步吗?synchronized
不是,synchronized会让程序的执行效率降低,用户体验不好。
系统的用户吞吐量降低。用户体验差。在不得已的情况下再选择
线程同步机制。
第一种方案:尽量使用局部变量代替“实例变量和静态变量”。
第二种方案:如果必须是实例变量,那么可以考虑创建多个对象,这样实例变量的内存就不共享了。(一个线程对应1个对象,100个线程对应100个对象,对象不共享,就没有数据安全问题了。)
第三种方案:如果不能使用局部变量,对象也不能创建多个,这个时候就只能选择synchronized了。线程同步机制。
线程其他的内容
1.守护线程
java语言中线程分为两大类:
一类是:用户线程
一类是:守护线程(后台线程)
其中具有代表性的就是:垃圾回收线程(守护线程)。
守护线程的特点:
一般守护线程是一个死循环,所有的用户线程只要结束,守护线程自动结束。
注意:主线程main方法是一个用户线程。
守护线程用在什么地方呢?
每天00:00的时候系统数据自动备份。
这个需要使用到定时器,并且我们可以将定时器设置为守护线程。
一直在那里看着,每到00:00的时候就备份一次,所有的用户线程
如果结束了,守护线程自动退出,没有必要进行数据备份了。
package thread;
/*
守护线程
*/
public class Test14 {
public static void main(String[] args) {
Thread t= new BakDtaThread();
t.setName("beifeng");
//启动线程之前,将线程设置为守护线程
t.setDaemon(true);
t.start();
//主线程
for (int i =0;i<10;i++){
System.out.println(Thread.currentThread().getName() + "-->" + i);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class BakDtaThread extends Thread{
public void run(){
int i = 0;
while(true){
System.out.println(Thread.currentThread().getName() + " --- >" + (++i));
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
2.定时器
定时器的作用:
间隔特定的时间,执行特定的程序。
每周要进行银行账户的总账操作。
每天要进行数据的备份操作。
在实际的开发中,每隔多久执行一段特定的程序,这种需求是很常见的,那么在java中其实可以采用多种方式实现:
可以使用sleep方法,睡眠,设置睡眠时间,没到这个时间点醒来,执行任务。这种方式是最原始的定时器。(比较low)
在java的类库中已经写好了一个定时器:java.util.Timer,可以直接拿来用。不过,这种方式在目前的开发中也很少用,因为现在有很多高级框架都是支持 定时任务的。
在实际的开发中,目前使用较多的是Spring框架中提供的SpringTask框架,这个框架只要进行简单的配置,就可以完成定时器的任务。
3.实现线程的第三种方式:FutureTask方式,实现Callable接口
这种方式实现的线程可以获取线程的返回值。
之前讲解的那两种方式是无法获取线程返回值的,因为run方法返回void。
思考:
系统委派一个线程去执行一个任务,该线程执行完任务之后,可能会有一个执行结果,我们怎么能拿到这个执行结果呢?
使用第三种方式:实现Callable接口方式。
4.关于Object类中的wait和notify方法。(生产者和消费者模式)
第一:wait和notify方法不是线程对象的方法,是java中任何一个java对象都有的方法,因为这两个方式是Object类中自带的。
wait方法和notify方法不是通过线程对象调用,不是这样的:t.wait(),也不是这样的:t.notify()…不对。
第二:wait()方法作用?
Object o = new Object();
o.wait();
表示:
让正在o对象上活动的线程进入等待状态,无期限等待,直到被唤醒为止。
o.wait();方法的调用,会让“当前线程(正在o对象上活动的线程)”进入等待状态。
第三:notify()方法作用?
Object o = new Object();
o.notify();
表示:
唤醒正在o对象上等待的线程。
还有一个notifyAll()方法:
这个方法是唤醒o对象上处于等待的所有线程。

生产者和消费者模式
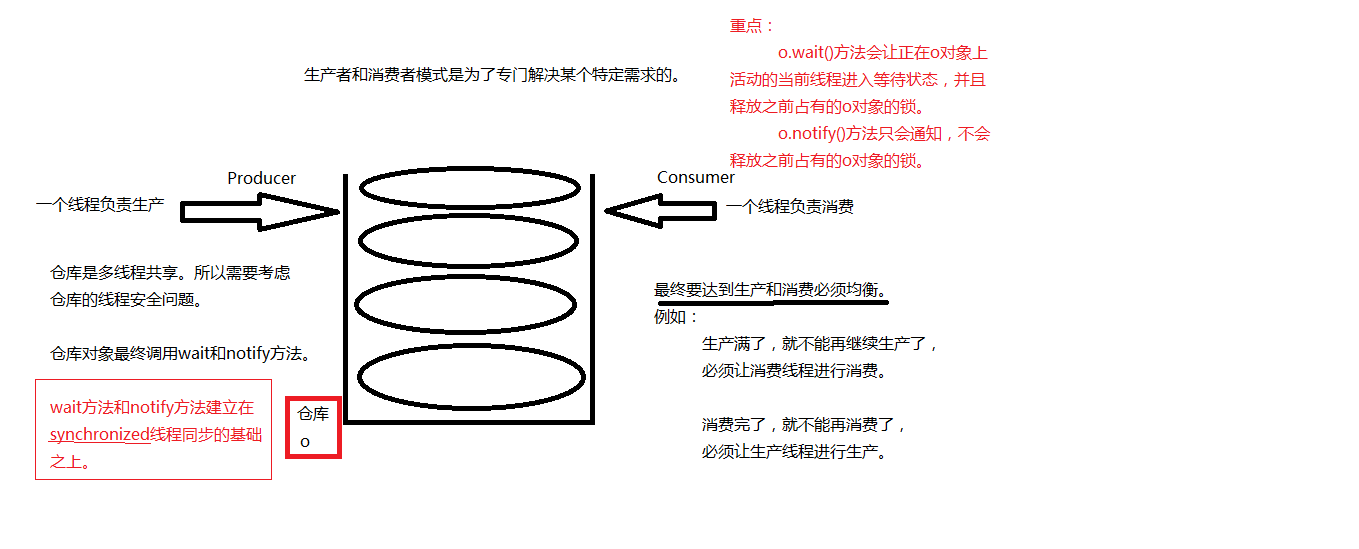
生产一个消费一个
package thread;
import lei.T;
import java.util.ArrayList;
import java.util.List;
/*
1.使用wait方法和notify方法实现生产者和消费者模式
2.什么是“生产者和消费者模式”?
生产线程负责生产,消费线程负责消费
生产线程和消费线程要达到均衡
这是一种特殊的业务需求,在这种特殊的情况下需要使用wait和notify方法
3.wait和notify方法不是线程对象的方法,是普通java对象的方法
4.wait方法和notify方法建立在线程同步的基础之上。因为多线程要同时操作一个仓库,有现成安全的问题
5.wait方法的作用,o.wait()让正在o对象上活动的线程t进入等待状态,并且释放掉t线程之前占有的o对象的锁
6.notify方法的作用:o.notify()让正在o对象上等待的线程唤醒,只是通知,不会释放o对象上之前占有的锁
7.模拟需求
仓库采用list集合
list集合中假设只能存储一个元素
1个元素就代表仓库满了
如果list集合中的元素为0,就表示仓库空了
保证list集合永远都是最多存储一个元素
必须做到这种效果:生成一个消费一个
*/
public class ThreadTest16 {
public static void main(String[] args) {
//创建仓库对象
List list = new ArrayList();
//创建两个线程对象
//一个是生产者线程
Thread thread1 = new Thread(new Procuder(list));
//一个是消费者线程
Thread thread2 = new Thread(new Consumer(list));
thread1.setName("t1");
thread2.setName("t2");
thread1.start();
thread2.start();
}
}
//生产线程
class Procuder implements Runnable{
//共享的仓库
private List list;
public Procuder() {
}
public Procuder(List list) {
this.list = list;
}
@Override
public void run() {
//一直生产
while(true){
synchronized (list){
if(list.size() > 0){
//当前线程进入等待状态
try {
list.wait();//当前线程进入等待状态,并且释放procuder之前占有list集合的锁
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//程序执行到这里说明,仓库是空的可以生产
Object obj = new Object();
list.add(obj);
System.out.println(Thread.currentThread().getName() + "--->" + obj);
//唤醒消费者进行消费
list.notify();
}
}
}
}
//消费线程
class Consumer implements Runnable{
private List list;
public Consumer() {
}
public Consumer(List list) {
this.list = list;
}
@Override
public void run() {
//一直消费
while(true){
synchronized (list){
if(list.size() == 0){
try {
list.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//程序执行到这里说明仓库中有数据,进行消费
Object obj = list.remove(0);
System.out.println(Thread.currentThread().getName() + "---->" + obj);
//唤醒生产者生产
list.notify();
}
}
}
}
反射机制
反射机制有什么用?
通过java语言中的反射机制可以操作字节码文件。
优点类似于黑客。(可以读和修改字节码文件。)
通过反射机制可以操作代码片段。(class文件。)
反射机制的相关类在哪个包下?
java.lang.reflect.*;
反射机制相关的重要的类有哪些?
java.lang.Class:代表整个字节码,代表一个类型,代表整个类。
java.lang.reflect.Method:代表字节码中的方法字节码。代表类中的方法。
java.lang.reflect.Constructor:代表字节码中的构造方法字节码。代表类中的构造方法
java.lang.reflect.Field:代表字节码中的属性字节码。代表类中的成员变量(静态变量+实例变量)。
java.lang.Class:
public class User{
// Field
int no;
// Constructor
public User(){
}
public User(int no){
this.no = no;
}
// Method
public void setNo(int no){
this.no = no;
}
public int getNo(){
return no;
}
}
获取字节码的三种方式
第一种:
Class c = Class.forName(“完整类名”);
第二种:
Class c = 对象.getClass();
第三种:
Class c = int.class;
Class c = String.class;
package reflect;
import java.awt.dnd.DropTarget;
import java.util.Date;
/*
要操作一个类的字节码,需要首先获取到这个类的字节码,怎么获取java.lang.Class实例
三种方式
1.第一种方式:Class.foename
2.第二种方式:Class c = 引用.getClass();
3.第三种方式:Class c = 任何类型.class;
*/
public class Test01 {
public static void main(String[] args) {
/*
Class.forname()
1.静态方法
2.方法的参数是一个字符串
3.字符串需要的是一个完整的类型
4.完整类名必须带有包名。java.lang也不能省略
*/
Class c1 = null;
Class c2 = null;
try {
c1 = Class.forName("java.lang.String");//c1代表String.class文件,或者说c1代表String类型
c2 = Class.forName("java.util.Date");//c2代表Date类型
Class c3 = Class.forName("java.lang.Integer");
Class c4 = Class.forName("java.lang.System");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
//java中任何一个对象都有一个方法:getClass()
String s = "abc";
Class x = s.getClass();//x代表String.class字节码文件,s代表String类型
Date time = new Date();
Class y = time.getClass();
System.out.println(c2 == y); //true c2和y两个变量中保存的内存地址都是一样的
//第三种方式,java语言中任何一种类型,包括基本数据类型,他都有class属性
Class z = String.class;//z代表String类型
Class k = Date.class;//k代表Date类型
Class f = int.class;//f代表int类型
Class e= double.class;//e代表double类型
System.out.println(x == z);
}
}
通过class的newInstance方法来实例化对象
一定要注意:
newInstance()底层调用的是该类型的无参数构造方法。
如果没有这个无参数构造方法会出现"实例化"异常。
package reflect;
import bean.User;
/*
获取class,能干什么
通过class的newInstance方法来实例化对象
注意:newInstance()方法内部实际上调用了无参数构造方法,必须保证无参数构造存在才可以
*/
public class Test02 {
public static void main(String[] args) {
//不使用反射机制创建对象
User user = new User();
System.out.println(user);
//通过反射机制获取class,通过class实例化对象
try {
Class c = Class.forName("bean.User");
//重点:newInstance调用的是无参数的构造,必须保证无参数的构造存在
Object object = c.newInstance();//newInstance会调用user的无参数构造方法,完成对象的创建
System.out.println(object);//bean.User@776ec8df
} catch (Exception e) {
e.printStackTrace();
}
}
}
验证反射机制的灵活性
package reflect;
import java.io.FileReader;
import java.util.Properties;
/*
验证反射机制的灵活性
java代码写一遍,在不改变java代码的基础上,可以做到不同对象的实例化,非常灵活,(符合OCP原则,对扩展开放,对修改关闭)
后期要学习高级框架,而工作中也都是学习高级框架
包括:ssh ssm..
*/
public class Test03 {
public static void main(String[] args) {
//通过IO流读取classinfo.properties文件
try {
FileReader reader = new FileReader("D:\\java\\javaSE\\demo\\src\\reflect\\classinfo.properties");
//创建属性类对象pr
Properties properties = new Properties();
//加载
properties.load(reader);
//关闭
reader.close();
//获得类名
String classname = properties.getProperty("className");
System.out.println(classname);
//通过反射机制实例化对象
Class c = Class.forName(classname);
c.newInstance();//创建实例化对象
System.out.println(c);
} catch (Exception e) {
e.printStackTrace();
}
}
}
研究一下classforname
如果你只想让一个类的“静态代码块”执行的话,你可以怎么做?
Class.forName(“该类的类名”);
这样类就加载,类加载的时候,静态代码块执行!!!!
在这里,对该方法的返回值不感兴趣,主要是为了使用“类加载”这个动作。
package reflect;
/*
研究一下Class.forname发生了什么
记住:重点
如果你只是希望一个类的静态代码块执行,其他代码一律不执行
你可以使用:
Class.forname("完整类名")
这个方法会导致类加载,类加载时,静态代码块执行
*/
public class Test04 {
public static void main(String[] args) {
try {
//这个方法会导致:类加载
Class c = Class.forName("reflect.MYcalss");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
class MYcalss{
//静态代码块在类加载时执行,并且只执行一次
static{
System.out.println("myclass类的静态代码块执行");
}
}
关于路径的问题
怎么获取文件的绝对路径,以下的讲解方式是通用的,但是前提是:文件需要在类路径下才能用这种方式
String path = Thread.currentThread().getContextClassLoader()
.getResource("写相对路径,但是这个相对路径从src出发开始找").getPath();
String path = Thread.currentThread().getContextClassLoader()
.getResource("abc").getPath(); //必须保证src下有abc文件。
String path = Thread.currentThread().getContextClassLoader()
.getResource("a/db").getPath(); //必须保证src下有a目录,a目录下有db文件。
String path = Thread.currentThread().getContextClassLoader()
.getResource("com/bjpowernode/test.properties").getPath();
//必须保证src下有com目录,com目录下有bjpowernode目录。
//bjpowernode目录下有test.properties文件。
这种方式是为了获取一个文件的绝对路径。(通用方式,不会受到环境移植的影响。)
但是该文件要求放在类路径下,换句话说:也就是放到src下面。src下是类的根路径。
直接以流的形式返回:
InputStream in = Thread.currentThread().getContextClassLoader()
.getResourceAsStream("com/bjpowernode/test.properties");
package reflect;
/*
关于路径的问题
怎么获取文件的绝对路径,以下的讲解方式是通用的,但是前提是:文件需要在类路径下才能用这种方式
*/
public class Test05 {
public static void main(String[] args) {
// try {
//这种的方式的缺点是:移植性差,在idea中默认是当前路径project的根
//这个代码假设离开了IDEA,换到了其他位置,可能当前路径就不是project的根了
//FileReader reader = new FileReader("demo/src/reflect/classinfo.properties");
//接下来说一种比较通用的路径,即使代码换位置了,这样编写也是通用的
//注意:使用以下通用方式的前提是:这个文件必须在类路径下
//什么是类路径下?
//凡是在src下的,都是类路径下
//src是类的根路径
/*
Thread.current() 当前线程对象
getContextClassLoader() 是线程对象的方式,可以获取到当前线程的类加载器对象
getResource() 【获取资源】这是类加载器对象的方法,默认当前线程的类加载器从根路径下获取资源
*/
String path =Thread.currentThread().getContextClassLoader().getResource("classinfo.properties").getPath();
System.out.println(path);
// /D:/java/javaSE/out/production/demo/classinfo.properties
//采用以上的方法可以拿到一个文件的绝对路径
//} catch (FileNotFoundException e) {
// e.printStackTrace();
//}
//获取db.properties的绝对路径
String path2 = Thread.currentThread().getContextClassLoader().getResource("src/bean/db.properties").getPath();
// /D:/java/javaSE/out/production/demo/src/bean/db.properties
System.out.println(path2);
}
}
以路径的形式返回
package reflect;
import java.io.FileReader;
import java.io.IOException;
import java.util.Properties;
public class IOPropertiseTest {
public static void main(String[] args) throws IOException {
//可以获取一个文件的绝对路径
String path = Thread.currentThread().getContextClassLoader().getResource("classinfo.properties").getPath();
FileReader fileReader =new FileReader(path);
Properties properties = new Properties();
properties.load(fileReader);
fileReader.close();
//通过key来获取value
String className = properties.getProperty("className");
System.out.println(className);
//java.util.Date
}
}
直接以流的形式返回
package reflect;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
public class IOPropertiseTest {
public static void main(String[] args) throws IOException {
//可以获取一个文件的绝对路径
/*
String path = Thread.currentThread().getContextClassLoader().getResource("classinfo.properties").getPath();
FileReader fileReader =new FileReader(path);
*/
//以流的形式返回
InputStream in = Thread.currentThread().getContextClassLoader().getResourceAsStream("classinfo.properties");
Properties properties = new Properties();
properties.load(in);
in.close();
//通过key来获取value
String className = properties.getProperty("className");
System.out.println(className);
//java.util.Date
}
}
资源绑定器
java.util包下提供了一个资源绑定器,便于获取属性配置文件中的内容;使用以下这种方式的时候,属性配置文件xxx.properties必须放到类路径下
**要求:**第一这个文件必须在类路径下
第二这个文件必须是以.properties结尾。
ResourceBundle bundle = ResourceBundle.getBundle("com/bjpowernode/test");
String value = bundle.getString(key);
最简单的方式
package reflect;
import java.util.ResourceBundle;
/*
java.util包下提供了一个资源绑定器,便于获取属性配置文件中的内容
使用以下这种方式的时候,属性配置文件xxx.properties必须放到类路径下
*/
public class ResourceBunleTest {
public static void main(String[] args) {
//资源绑定器,只能绑定xxx.properties文件。并且这个文件必须在类路径下。文件扩展名也必须是properties
//并且在写路径的时候,路径后面的扩展名不能写
ResourceBundle resourceBundle = ResourceBundle.getBundle("classinfo");
ResourceBundle resourceBundle1 = ResourceBundle.getBundle("src/bean/db");
String className = resourceBundle.getString("className");
String className1 = resourceBundle1.getString("className");
System.out.println(className);
System.out.println(className1);
}
}
类加载器
什么是类加载器?
专门负责加载类的命令/工具。
ClassLoader
JDK中自带了3个类加载器
启动类加载器:rt.jar
扩展类加载器:ext/*.jar
应用类加载器:classpath
假设有这样一段代码:String s = “abc”;
代码在开始执行之前,会将所需要类全部加载到JVM当中。通过类加载器加载,看到以上代码类加载器会找String.class文件,找到就加载,那么是怎么进行加载的呢?
首先通过“启动类加载器”加载。
注意:启动类加载器专门加载:C:\Program Files\Java\jdk1.8.0_101\jre\lib\rt.jar
rt.jar中都是JDK最核心的类库。
如果通过“启动类加载器”加载不到的时候,
会通过"扩展类加载器"加载。
注意:扩展类加载器专门加载:C:\Program Files\Java\jdk1.8.0_101\jre\lib\ext*.jar
如果“扩展类加载器”没有加载到,那么
会通过“应用类加载器”加载。
注意:应用类加载器专门加载:classpath中的类。
java中为了保证类加载的安全,使用了双亲委派机制。
优先从启动类加载器中加载,这个称为“父”
“父”无法加载到,再从扩展类加载器中加载,这个称为“母”。双亲委派。如果都加载不到,才会考虑从应用类加载器中加载。直到加载到为止。
通过反射机制访问一个类属性的修饰符列表/属性/属性名字
package reflect;
import java.io.File;
import java.io.FileReader;
import java.lang.reflect.Field;
import java.lang.reflect.Modifier;
public class reflectTest06 {
//反射所有student类当中的属性
public static void main(String[] args) throws ClassNotFoundException {
//获取整个类
Class studentclass = Class.forName("reflect.Student");
//获取类中所有的field
//可以获取类中所有公开的属性
Field[] fields = studentclass.getFields();
//Class也可以getName
String className = studentclass.getName();
System.out.println(className);
System.out.println(studentclass.getSimpleName());
System.out.println("------------------------");
System.out.println(fields.length);//1
Field f = fields[0];
String fieldName = f.getName();
System.out.println(fieldName);//no
System.out.println("--------------------------");
//获取所有的Field
Field[] fds = studentclass.getDeclaredFields();
System.out.println(fds.length);
for (Field field:fds){
//获取属性的修饰符列表
int modifier = field.getModifiers();//返回的修饰符是一个数字,每一个数字是一个修饰符的代号
//可以将代号数字转换成字符串
String modifierString = Modifier.toString(modifier);
//获取属性的类型
String fieldTyepe = field.getType().getSimpleName();
//获取到每个属性的名字
System.out.println(modifierString + " + " + fieldTyepe + " + " + field.getName());
}
}
}
通过反射机制反编译一个类的属性
package reflect;
//通过反射机制反编译一个类的属性
import java.lang.reflect.Field;
import java.lang.reflect.Modifier;
public class reflextTest07 {
public static void main(String[] args) throws ClassNotFoundException {
StringBuilder stringBuilder = new StringBuilder();//为了拼接字符串
Class studentClass = Class.forName("reflect.Student");
Field[] fields = studentClass.getDeclaredFields();
stringBuilder.append(Modifier.toString(studentClass.getModifiers()) + " class " + studentClass.getSimpleName() + "{" + "\n");
for(Field field:fields){
stringBuilder.append("\t");
stringBuilder.append(Modifier.toString(field.getModifiers()) + " ");
stringBuilder.append(field.getType() + " ");
stringBuilder.append(field.getName());
stringBuilder.append(";" + "\n");
}
stringBuilder.append("}");
System.out.println(stringBuilder);
}
}
通过反射机制访问对象的某个类
package reflect;
import java.lang.reflect.Field;
/*
怎么通过反射机制访问一个对象的属性?
给属性赋值
获取属性的值
*/
public class reflectTest08 {
public static void main(String[] args) throws Exception {
Class studentclass = Class.forName("reflect.Student");
Object object = studentclass.newInstance();//Obj就是student的对象(底层调用无参数构造方法)
//获取属性(根据属性的名称获取field)
Field noField = studentclass.getDeclaredField("no");
//给no属性赋值
/*
虽然使用了反射机制,但是三要素还是缺1不可
要素1:obj对象
要素2:no属性
要素3:2的值
注意:反射机制让代码负载量,但是为了一个”灵活“还是值得的
*/
noField.set(object,2);//给Object对象的no属性赋值2
//读取属性的值
System.out.println(noField.get(object));//获取object对象的no属性的值
//可以访问私有的属性
//打破封装进行访问,这样设置完之后,在外部也可以访问private属性
Field namefield = studentclass.getDeclaredField("name");
namefield.setAccessible(true);
namefield.set(object,"w");
System.out.println(namefield.get(object));
}
}
}
}
}
class MYcalss{
//静态代码块在类加载时执行,并且只执行一次
static{
System.out.println(“myclass类的静态代码块执行”);
}
}
### 关于路径的问题
怎么获取文件的绝对路径,**以下的讲解方式是通用的,但是前提是:文件需要在类路径下才能用这种方式**
String path = Thread.currentThread().getContextClassLoader()
.getResource(“写相对路径,但是这个相对路径从src出发开始找”).getPath();
String path = Thread.currentThread().getContextClassLoader()
.getResource(“abc”).getPath(); //必须保证src下有abc文件。
String path = Thread.currentThread().getContextClassLoader()
.getResource(“a/db”).getPath(); //必须保证src下有a目录,a目录下有db文件。
String path = Thread.currentThread().getContextClassLoader()
.getResource(“com/bjpowernode/test.properties”).getPath();
//必须保证src下有com目录,com目录下有bjpowernode目录。
//bjpowernode目录下有test.properties文件。
**这种方式是为了获取一个文件的绝对路径**。(通用方式,不会受到环境移植的影响。)
但是该文件要求放在类路径下,换句话说:也就是放到src下面。src下是类的根路径。
直接以流的形式返回:
InputStream in = Thread.currentThread().getContextClassLoader()
.getResourceAsStream(“com/bjpowernode/test.properties”);
```java
package reflect;
/*
关于路径的问题
怎么获取文件的绝对路径,以下的讲解方式是通用的,但是前提是:文件需要在类路径下才能用这种方式
*/
public class Test05 {
public static void main(String[] args) {
// try {
//这种的方式的缺点是:移植性差,在idea中默认是当前路径project的根
//这个代码假设离开了IDEA,换到了其他位置,可能当前路径就不是project的根了
//FileReader reader = new FileReader("demo/src/reflect/classinfo.properties");
//接下来说一种比较通用的路径,即使代码换位置了,这样编写也是通用的
//注意:使用以下通用方式的前提是:这个文件必须在类路径下
//什么是类路径下?
//凡是在src下的,都是类路径下
//src是类的根路径
/*
Thread.current() 当前线程对象
getContextClassLoader() 是线程对象的方式,可以获取到当前线程的类加载器对象
getResource() 【获取资源】这是类加载器对象的方法,默认当前线程的类加载器从根路径下获取资源
*/
String path =Thread.currentThread().getContextClassLoader().getResource("classinfo.properties").getPath();
System.out.println(path);
// /D:/java/javaSE/out/production/demo/classinfo.properties
//采用以上的方法可以拿到一个文件的绝对路径
//} catch (FileNotFoundException e) {
// e.printStackTrace();
//}
//获取db.properties的绝对路径
String path2 = Thread.currentThread().getContextClassLoader().getResource("src/bean/db.properties").getPath();
// /D:/java/javaSE/out/production/demo/src/bean/db.properties
System.out.println(path2);
}
}
以路径的形式返回
package reflect;
import java.io.FileReader;
import java.io.IOException;
import java.util.Properties;
public class IOPropertiseTest {
public static void main(String[] args) throws IOException {
//可以获取一个文件的绝对路径
String path = Thread.currentThread().getContextClassLoader().getResource("classinfo.properties").getPath();
FileReader fileReader =new FileReader(path);
Properties properties = new Properties();
properties.load(fileReader);
fileReader.close();
//通过key来获取value
String className = properties.getProperty("className");
System.out.println(className);
//java.util.Date
}
}
直接以流的形式返回
package reflect;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
public class IOPropertiseTest {
public static void main(String[] args) throws IOException {
//可以获取一个文件的绝对路径
/*
String path = Thread.currentThread().getContextClassLoader().getResource("classinfo.properties").getPath();
FileReader fileReader =new FileReader(path);
*/
//以流的形式返回
InputStream in = Thread.currentThread().getContextClassLoader().getResourceAsStream("classinfo.properties");
Properties properties = new Properties();
properties.load(in);
in.close();
//通过key来获取value
String className = properties.getProperty("className");
System.out.println(className);
//java.util.Date
}
}
资源绑定器
java.util包下提供了一个资源绑定器,便于获取属性配置文件中的内容;使用以下这种方式的时候,属性配置文件xxx.properties必须放到类路径下
**要求:**第一这个文件必须在类路径下
第二这个文件必须是以.properties结尾。
ResourceBundle bundle = ResourceBundle.getBundle("com/bjpowernode/test");
String value = bundle.getString(key);
最简单的方式
package reflect;
import java.util.ResourceBundle;
/*
java.util包下提供了一个资源绑定器,便于获取属性配置文件中的内容
使用以下这种方式的时候,属性配置文件xxx.properties必须放到类路径下
*/
public class ResourceBunleTest {
public static void main(String[] args) {
//资源绑定器,只能绑定xxx.properties文件。并且这个文件必须在类路径下。文件扩展名也必须是properties
//并且在写路径的时候,路径后面的扩展名不能写
ResourceBundle resourceBundle = ResourceBundle.getBundle("classinfo");
ResourceBundle resourceBundle1 = ResourceBundle.getBundle("src/bean/db");
String className = resourceBundle.getString("className");
String className1 = resourceBundle1.getString("className");
System.out.println(className);
System.out.println(className1);
}
}
类加载器
什么是类加载器?
专门负责加载类的命令/工具。
ClassLoader
JDK中自带了3个类加载器
启动类加载器:rt.jar
扩展类加载器:ext/*.jar
应用类加载器:classpath
假设有这样一段代码:String s = “abc”;
代码在开始执行之前,会将所需要类全部加载到JVM当中。通过类加载器加载,看到以上代码类加载器会找String.class文件,找到就加载,那么是怎么进行加载的呢?
首先通过“启动类加载器”加载。
注意:启动类加载器专门加载:C:\Program Files\Java\jdk1.8.0_101\jre\lib\rt.jar
rt.jar中都是JDK最核心的类库。
如果通过“启动类加载器”加载不到的时候,
会通过"扩展类加载器"加载。
注意:扩展类加载器专门加载:C:\Program Files\Java\jdk1.8.0_101\jre\lib\ext*.jar
如果“扩展类加载器”没有加载到,那么
会通过“应用类加载器”加载。
注意:应用类加载器专门加载:classpath中的类。
java中为了保证类加载的安全,使用了双亲委派机制。
优先从启动类加载器中加载,这个称为“父”
“父”无法加载到,再从扩展类加载器中加载,这个称为“母”。双亲委派。如果都加载不到,才会考虑从应用类加载器中加载。直到加载到为止。
通过反射机制访问一个类属性的修饰符列表/属性/属性名字
package reflect;
import java.io.File;
import java.io.FileReader;
import java.lang.reflect.Field;
import java.lang.reflect.Modifier;
public class reflectTest06 {
//反射所有student类当中的属性
public static void main(String[] args) throws ClassNotFoundException {
//获取整个类
Class studentclass = Class.forName("reflect.Student");
//获取类中所有的field
//可以获取类中所有公开的属性
Field[] fields = studentclass.getFields();
//Class也可以getName
String className = studentclass.getName();
System.out.println(className);
System.out.println(studentclass.getSimpleName());
System.out.println("------------------------");
System.out.println(fields.length);//1
Field f = fields[0];
String fieldName = f.getName();
System.out.println(fieldName);//no
System.out.println("--------------------------");
//获取所有的Field
Field[] fds = studentclass.getDeclaredFields();
System.out.println(fds.length);
for (Field field:fds){
//获取属性的修饰符列表
int modifier = field.getModifiers();//返回的修饰符是一个数字,每一个数字是一个修饰符的代号
//可以将代号数字转换成字符串
String modifierString = Modifier.toString(modifier);
//获取属性的类型
String fieldTyepe = field.getType().getSimpleName();
//获取到每个属性的名字
System.out.println(modifierString + " + " + fieldTyepe + " + " + field.getName());
}
}
}
通过反射机制反编译一个类的属性
package reflect;
//通过反射机制反编译一个类的属性
import java.lang.reflect.Field;
import java.lang.reflect.Modifier;
public class reflextTest07 {
public static void main(String[] args) throws ClassNotFoundException {
StringBuilder stringBuilder = new StringBuilder();//为了拼接字符串
Class studentClass = Class.forName("reflect.Student");
Field[] fields = studentClass.getDeclaredFields();
stringBuilder.append(Modifier.toString(studentClass.getModifiers()) + " class " + studentClass.getSimpleName() + "{" + "\n");
for(Field field:fields){
stringBuilder.append("\t");
stringBuilder.append(Modifier.toString(field.getModifiers()) + " ");
stringBuilder.append(field.getType() + " ");
stringBuilder.append(field.getName());
stringBuilder.append(";" + "\n");
}
stringBuilder.append("}");
System.out.println(stringBuilder);
}
}
通过反射机制访问对象的某个类
package reflect;
import java.lang.reflect.Field;
/*
怎么通过反射机制访问一个对象的属性?
给属性赋值
获取属性的值
*/
public class reflectTest08 {
public static void main(String[] args) throws Exception {
Class studentclass = Class.forName("reflect.Student");
Object object = studentclass.newInstance();//Obj就是student的对象(底层调用无参数构造方法)
//获取属性(根据属性的名称获取field)
Field noField = studentclass.getDeclaredField("no");
//给no属性赋值
/*
虽然使用了反射机制,但是三要素还是缺1不可
要素1:obj对象
要素2:no属性
要素3:2的值
注意:反射机制让代码负载量,但是为了一个”灵活“还是值得的
*/
noField.set(object,2);//给Object对象的no属性赋值2
//读取属性的值
System.out.println(noField.get(object));//获取object对象的no属性的值
//可以访问私有的属性
//打破封装进行访问,这样设置完之后,在外部也可以访问private属性
Field namefield = studentclass.getDeclaredField("name");
namefield.setAccessible(true);
namefield.set(object,"w");
System.out.println(namefield.get(object));
}
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











