







vue千位分隔符
MyBatis的xml写法
idea启动控制台tomcat中文乱码
常见的stream流方法
Collection集合、数组的遍历方式
vue页面浏览器缩放自适应
JVM的理解–理论篇
BigDecimal的常用运算
触发器的使用
存储过程的使用
el-input等显示框鼠标悬浮显示全部内容
el-table在JS中赋值内容后表格数据刷新
JS对象赋值,操作新对象影响原对象
java将数据处理成JSON树形结构
千位分隔符
场景:金额显示123,456 123456 =>123,456
方式1:js方法
numberExchange(value){
if (!value) return 0
// 获取整数部分
const intPart = Math.trunc(value)
// 整数部分处理,增加,
const intPartFormat = intPart.toString().replace(/(\d)(?=(?:\d{3})+$)/g, '$1,')
// 预定义小数部分
let floatPart = ''
// 将数值截取为小数部分和整数部分
const valueArray = value.toString().split('.')
if (valueArray.length === 2) {
// 有小数部分
floatPart = valueArray[1].toString() // 取得小数部分
return intPartFormat + '.' + floatPart
}
return intPartFormat + floatPart
}
}
方式2:el-table表格
加入 :formatter="numberFormat"
<el-table-column
prop="htsno"
label="合同序号"
width="100"
:formatter="numberFormat"
>
</el-table-column>
js部分:
numberFormat (row, column, cellValue) {
cellValue += ''
if (!cellValue.includes('.')) cellValue += '.'
return cellValue.replace(/(\d)(?=(\d{3})+\.)/g, function ($0, $1) {
return $1 + ','
}).replace(/\.$/, '')
},
MyBatis的xml写法
1.foreach
2.<、>、>=、<=
1.foreach
场景:编写sql语句:select name,sex from student where name in (’小谭‘,‘小花’);
<select id="selectStudent" resultType="com.broad.emc.entity.Student" parameterType="java.util.List">
select name sex from student
where name in
<foreach item="name" collection="nameList" open="(" separator="," close=")">
#{name}
</foreach>
</select>
-- 参数是List集合nameList,元素是name
2.<、>、>=、<=
场景:sql语句 select name from student where age<=16,xml无法识别<=,需要转义
大于 > ==> >
大于等于 >= ==> >=
小于 < ==> <
小于等于 <= ==> <=
不等于 <> != ==> <>
select name from student where age <=16
idea启动控制台tomcat中文乱码
场景:在idea中启动项目,但是控制台中tomcat信息乱码了
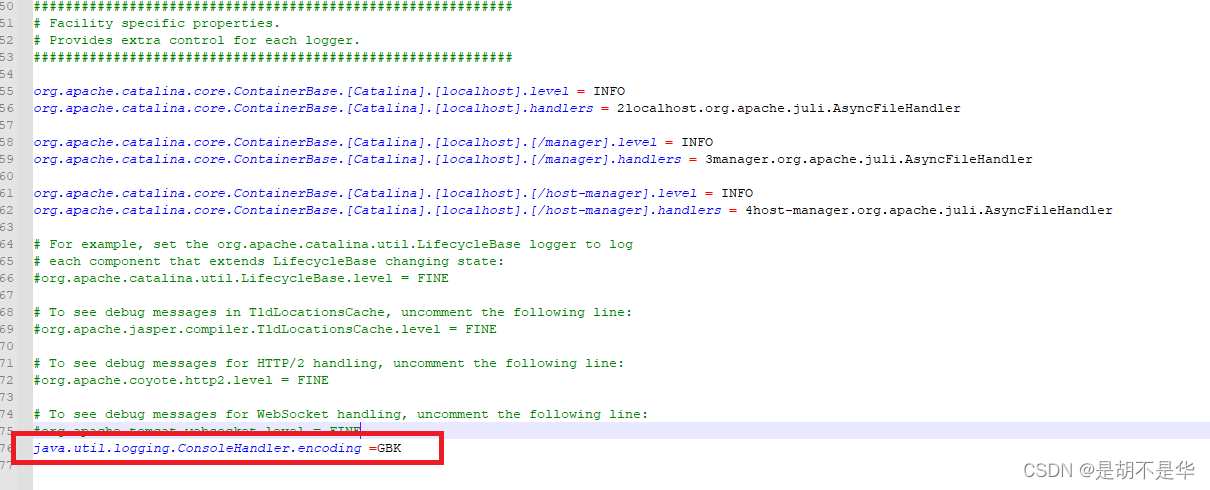
方法1:找到tomcat的文件夹的conf文件夹的配置文件logging.properties,新增java.util.logging.ConsoleHandler.encoding =GBK
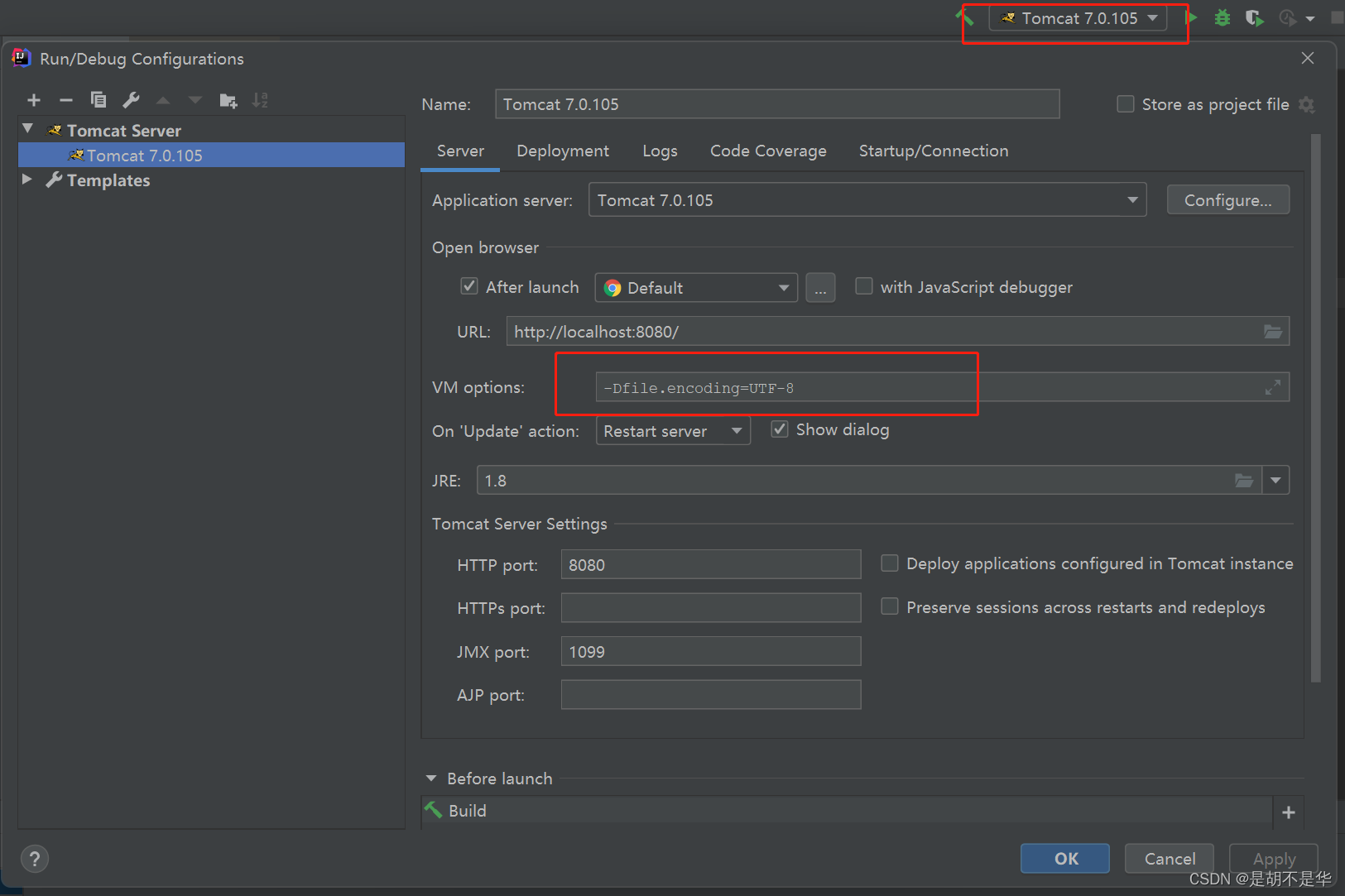
方法2:打开tomcat的配置页面,在VM options 新增 -Dfile.encoding=UTF-8
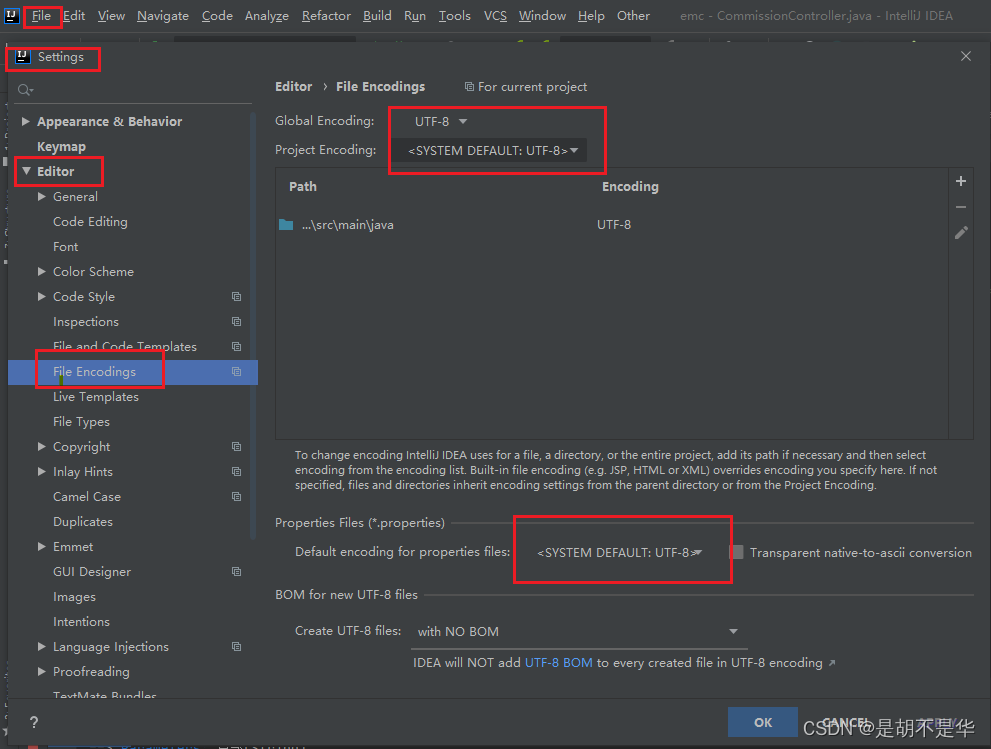
然后在idea中修改encoding,在File-setting-Editor-File Encodings修改对应的encoding为UTF-8
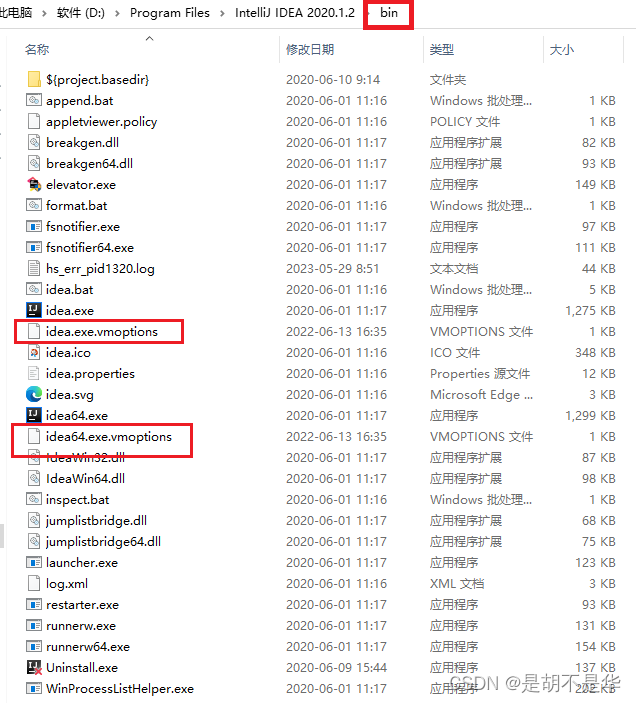
方法3: 打开idea本地安装目录的bin文件夹,打开idea.exe.vmoptions跟idea64.exe.vmoptions,在文件末尾添加 -Dfile.encoding=UTF-8
常见的stream流方法
stream流的创建:
//集合创建流对象 list/set
//1.1 创建Collection系列集合Stream流对象 list
List<String> list=new ArrayList<>();
Collections.addAll(list,"a","b","c");
Stream<String> stream=list.stream();
//1.2 创建Collection系列集合Stream流对象 set
Set<String> set =new HashSet<>();
Collections.addAll(set,"a","b","c");
Stream<String> stream1=set.stream();
//2.创建Map系列集合Stream流对象
Map<String,Integer> map=new HashMap<>();
map.put("张三",19);
map.put("李四",20);
//方法1:把键值对 封装成一个整体
Set<Map.Entry<String, Integer>> entries=map.entrySet();
Stream<Map.Entry<String, Integer>> stream2=entries.stream();
//方法2: 分别把集合中的键和值取出单独放在集合中
Set<String> key=map.keySet();
Collection<Integer> value= map.values();
Stream<String> stream3=key.stream();
Stream<Integer> stream4=value.stream();
//3. 创建数组Stream流对象
String[] strings=new String[]{"a","b","c"};
//方法1:Arrays.stream()
Stream<String> stream5=Arrays.stream(strings);
//方法2:Stream.of() 对于集合也适用
Stream<String> stream6=Stream.of(strings);
//4. 补充: stream对象转list对象
List<String> newList=stream.collect(Collectors.toList());
常见的stream API:
场景:数组、集合根据需求快速过滤到需要的数据
Predicate 接口有一个抽象方法 test(T t),它接受一个类型为 T 的参数,返回一个布尔值。
List<String> lists=new ArrayList<>();
Collections.addAll(lists,"a","aaaaaaaaa","aaa","aaaaa");
Stream<String> stream=lists.stream();
Stream<String> result=stream.filter(res -> !res.equals("a"));
//result.forEach(System.out::println);
result.forEach(s -> System.out.println(s));
场景:判断数组中是否有小于3的数据,无需遍历对每个数进行判断
Integer[] nums=new Integer[]{1,2,3,4,5,6,7};
Stream<Integer> stream=Arrays.stream(nums);
//判断数组中是否有小于3的数据
Boolean flag=stream.anyMatch(res ->res<3);
System.out.println(flag); //true
场景:将集合list中的每个数乘2输出
Integer[] nums=new Integer[]{1,2,3,4,5,6,7};
Stream<Integer> stream=Arrays.stream(nums);
Stream<Integer> stream1=stream.map(s -> s*2);
stream1.forEach(s-> System.out.println(s));
场景:快速过滤掉一个集合/数组中重复元素
String[] strings=new String[]{"aaa","b","aaa","cc","张三","李四","张三","b"};
Stream<String> stream=Arrays.stream(strings);
Stream<String> stringStream=stream.distinct();
stringStream.forEach(s -> System.out.println(s));
场景:对一个数组/集合的数据进行排序,从大到小或从小到大排序;
班级学生按年龄进行排序;
Integer[] nums=new Integer[]{2,5,3,5,6,21,1};
Stream<Integer> stream=Arrays.stream(nums);
//自然排序
//Stream<Integer> stream1=stream.sorted();
//逆向排序
//Stream<Integer> stream2=stream.sorted(Comparator.reverseOrder());
//列表排序 Student实体类按学生年龄排序
//stream.sorted(Comparator.comparing(Student::getAge));
//stream.sorted(Comparator.comparing(Student::getAge).reversed());
Collection集合、数组的遍历方式
场景:面试官提问,Collection集合有哪些遍历方式?普通for循环可以吗?
Q:一般情况下,普通for循环不能遍历集合,原因有二:其一是集合类的元素个数是动态变化的,普通for只能遍历固定长度元素,若集合类的元素个数发生变化,可能会出现索引越界异常;其二,对于有些集合如LinkedList,元素个数越多,循环次数越多,查询时间越慢
集合遍历方式:
增强型for循环,本质是迭代器
//增强型for循环
List<String> list=new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
list.add("老六");
for(String s : list){
System.out.println(s);
}```
迭代器
//迭代器遍历
List<String> list=new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
list.add("老六");
Iterator iterator= list.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
Java 8的 Stream API,源码是增强型for循环,本质是迭代器(增强for本质就是迭代器)
//stream forEach遍历
List<String> list=new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
list.add("老六");
//list.stream().forEach(s -> System.out.println(s));
list.forEach(s -> System.out.println(s));
数组的遍历方式:
- 普通for循环
- 增强型for循环
- Arrays工具类的toString静态方法(将一维数组转化为字符串形式)
vue页面浏览器缩放自适应
场景:vue项目页面在不同电脑上浏览器缩放比例不同,显示内容页面发生变化,需要自适应浏览器的缩放
在项目的 utils 下新建 devicePixelRatio.js 文件
class devicePixelRatio {
/* 获取系统类型 */
getSystem() {
const agent = navigator.userAgent.toLowerCase();
const isMac = /macintosh|mac os x/i.test(navigator.userAgent);
if (isMac) return false;
// 目前只针对 win 处理,其它系统暂无该情况,需要则继续在此添加即可
if (agent.indexOf("windows") >= 0) return true;
}
/* 监听方法兼容写法 */
addHandler(element, type, handler) {
if (element.addEventListener) {
element.addEventListener(type, handler, false);
} else if (element.attachEvent) {
element.attachEvent("on" + type, handler);
} else {
element["on" + type] = handler;
}
}
/* 校正浏览器缩放比例 */
correct() {
// 页面devicePixelRatio(设备像素比例)变化后,计算页面body标签zoom修改其大小,来抵消devicePixelRatio带来的变化
document.getElementsByTagName("body")[0].style.zoom =
1 / window.devicePixelRatio;
}
/* 监听页面缩放 */
watch() {
const that = this;
// 注意: 这个方法是解决全局有两个window.resize
that.addHandler(window, "resize", function () {
that.correct(); // 重新校正浏览器缩放比例
});
}
/* 初始化页面比例 */
init() {
const that = this;
// 判断设备,只在 win 系统下校正浏览器缩放比例
if (that.getSystem()) {
that.correct(); // 校正浏览器缩放比例
that.watch(); // 监听页面缩放
}
}
}
export default devicePixelRatio;
在App.vue 中引入并使用
<template>
<div id="app">
<router-view></router-view>
</div>
</template>
<script>
import devPixelRatio from "./utils/devicePixelRatio";
export default {
name: "App",
created() {
new devPixelRatio().init(); // 初始化页面比例
},
};
</script>
<style >
body {
margin: 0;
padding: 0;
}
</style>
BigDecimal的常用运算
场景: 项目在计算财务合同提成时表示金额,使用浮点型可能会丢失精度,使用BigDecimal类型表示金额,涉及到常用加减乘除,保留小数,两个BigDecimal数值比较
注意 :BigDecimal有多种构造函数,常用的有2种。建议使用String构造方式,不建议使用double构造方式,会丢失精度。
BigDecimal num=new BigDecimal(“12345.59”);
- 加法:add()函数
- 减法:subtract()函数
- 乘法:multiply()函数
- 除法:divide(除数,精确的小数位数,舍入模式) ROUND_HALF_UP 四舍五入
- 绝对值:abs()函数
- 保留小数:setScale(保留小数,舍入模式)
BigDecimal Lrl=( ( (sr.subtract(nhcb).subtract(sbft).subtract(fy)) .multiply ( new BigDecimal(“0.9892”) ) .multiply ( new BigDecimal(0.85) ) )
.divide(sr,4,BigDecimal.ROUND_HALF_UP) ) .doubleValue();
Lrl=Lrl.setScale(6, BigDecimal.ROUND_HALF_UP);
两个BigDecimal大小比较 compareTo
BigDecimal num1=new BigDecimal("123");
BigDecimal num2=new BigDecimal("456");
int flag = num1.compareTo(num2);
flag = -1,表示num1小于num2;
flag =0,表示num1等于num2;
flag =1,表示num1大于num2;
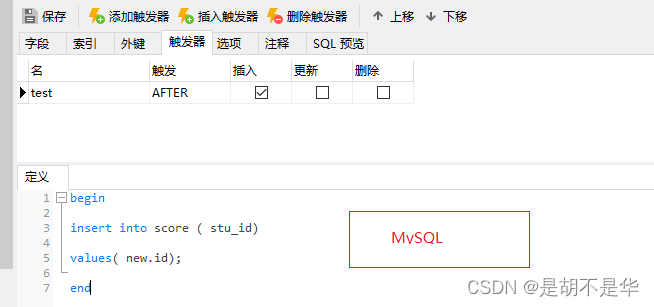
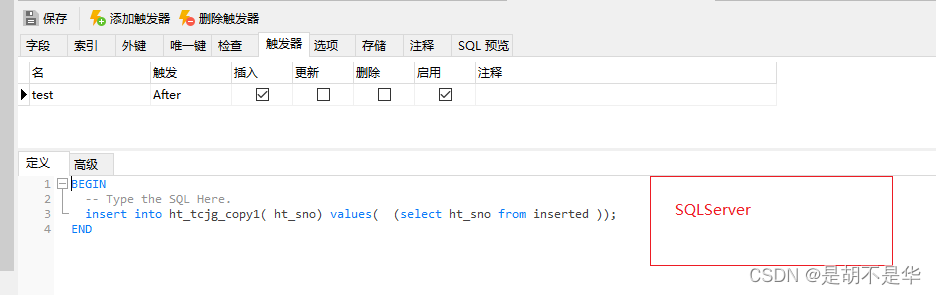
触发器的使用
场景:监视某种情况,并触发某种操作。当对主表进行操作( insert,delete, update)时,就会激活它执行对从表进行操作。
- MySQL中对主表student(id,name)进行新增,从表成绩表socre(stu_id,score)添加学生id
- SQLServer中对主表ht_tcjg进行新增时,从表复制表ht_tcjg_copy进行备份操作
MySQL触发器语法:
triggerName :触发器名称,不能同名
after/before ::触发时间,可以为before(在检查约束前触发)或after(在检查约束后触发)
insert/update/delete :触发事件
new :引用触发器中发生变化的记录内容
old :引用触发器中发生变化的记录内容
create trigger triggerName
after/before
insert/update/delete on 表名
for each row
begin
-- 触发器的逻辑代码;
end;
SQLServer触发器语法:
deleted: 更新前的数据
inserted: 更新后的数据
CREATE TRIGGER trigger_name
ON table_name
AFTER INSERT, UPDATE, DELETE
AS
BEGIN
-- 触发器的逻辑代码;
END
存储过程的使用
介绍:SQL语句需要先编译然后执行,而存储过程是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,用户通过指定存储过程的名字并给定参数(如果该存储过程带有参数)来调用执行它,个人将它理解为可调用的函数方法。
存储过程的创建
1. MySQL存储过程创建
2.SQLServer存储过程创建
MySQL存储过程创建
delimiter //
Create producedure 过程名([[in|out|inout]参数名 参数类型,[in|out|inout]参数名 数据类型...]])
begin
-- 逻辑代码
end
//
delimiter ;
-- delimiter (可省略):Mysql默认以“;”为分隔符,如果没有什么分隔符,则编译器会把存储过程当成SQL语句进行处理,因此编译过程会报错,所以要事先用“DELIMITER //声明当前段分隔符,让编译器把两个“//”之间的内容当做存储过程的代码,不会执行这些代码;"DELIMITER;"的意为把分隔符还原。
-- 参数:输入in、输出out、输入输出inout
-- In:参数的值必须在调用存储过程时指定,在存储过程中修改该参数的值不能被返回,为默认值(参数值不受过程体影响,参数参与过程体逻辑,仅当作参数输入 )
-- OUT:该值可在存储过程内部被改变,并可返回(参数值受过程体影响,参数不参与过程体逻辑 ,仅输出参数)
-- InOUT:调用时指定,并且可被改变和返回(既当作参数输入,又输出参数)
-- 过程体:过程体的开始与结束使用begin和end进行标识
ex:in参数
delimiter //
create PROCEDURE in_example (in param int )
begin
select param;
set param=2;
select param;
end
//
delimiter ;
set @param=1; -- 设置in参数
call in_example(@param); -- 调用存储过程 1 2
select @param -- 查询参数 1
ex:out参数
delimiter //
create procedure out_example (out param int)
begin
select param;
set param=4;
select param;
end
//
delimiter;
set @param=1;
call out_example(@param); -- null 4
select @param; -- 4
ex:inout参数
delimiter //
create procedure inout_example(inout param int)
begin
select param;
set param=2;
select param;
end;
//
delimiter;
set @param=1;
call inout_example(@param); -- 1 2
select @param; -- 2
SQLServer存储过程创建
create proc proc_ht
@htsno varchar,
@swsid varchar
as
select * from ht_ht where ht_sno=@htsno and sws_id=@swsid
#调用
exec proc_ht @htsno=11663,@swsid=17;
el-input等显示框鼠标悬浮显示全部内容
场景:在使用element组件如el-input时,由于显示框长度受限,内容文本超出显示框长度,导致显示不全,解决办法:当鼠标在显示框停留时悬浮显示文本内容,鼠标移开不显示文本内容
使用elementUI的el-tooltip组件
<!--light为背景白色 dark为背景黑色-->
<el-tooltip
class="item"
effect="light"
:content="value"
placement="top-start"
:disabled="isShowTooltip"
>
<el-input v-model="value" style="width:55%;"></el-input>
</el-tooltip>
// js代码
data(){
return {
value:"",
isShowTooltip:false
}
},
methods:{
inputOnMouseOver(e){
const target = event.target;
// 判断是否开启tooltip功能
if (target.offsetWidth < target.scrollWidth) {
this.isShowTooltip = false;
} else {
this.isShowTooltip = true;
}
}
}
效果图

JS对象赋值,操作新对象影响原对象
场景:在写js代码时,原对象a,将a赋值b,操作b对象,结果a对象也跟着变化,影响其他地方调用a对象的结果。
//a.id=‘1’;
var b=a;
b.id=‘2’;
console.log(a.id); //2
console.log(b.id); //2
原因:JavaScript 中对象的赋值是默认引用赋值的(两个对象指向相同的内存地址)
法1:使用Object.assign() 深拷贝
Object.assign(obj) --浅拷贝
Object.assign({},obj) --深拷贝(只有第一层深拷贝)
// 使用 Object.assign() 方法复制对象
let obj1 = { a: 0 , b: { c: 0}};
let obj2 = Object.assign({}, obj1);
console.log(JSON.stringify(obj2)); // { a: 0, b: { c: 0}}
obj2.a = 1;
console.log(JSON.stringify(obj1)); // { a: 0, b: { c: 0}}
console.log(JSON.stringify(obj2)); // { a: 1, b: { c: 0}}
obj2.b.c = 3;
console.log(JSON.stringify(obj1)); // { a: 0, b: { c: 3}} //只有第一层深拷贝
console.log(JSON.stringify(obj2)); // { a: 1, b: { c: 3}}
法2:使用 JSON.parse(JSON.stringify(obj))
//JSON.stringfy(); 把对象转换成JSON字符串
//JSON.parse(); 把JSON字符串转换成对象
let obj1 = { a: 0 , b: { c: 0}};
let obj2=JSON.parse( JSON.stringify(obj1) );
obj2.a=1;
console.log(JSON.stringify(obj1)); // { a: 0, b: { c: 0}}
console.log(JSON.stringify(obj2)); // { a: 1, b: { c: 0}}
# el-table在JS中赋值内容后表格数据刷新
场景:el-table的表格内容在js代码中赋值,但是表格内容无变化,需要增加刷新table的操作
无效情况:push()、pop(),实际效果不理想
this.fkgdTableData=res.data; //table内容赋值
//刷新table数据
this.fkgdTableData.push({});
this.fkgdTableData.pop();
解决方法:在el-table增加 :key,在赋值处随机设置key的值,使得el-table强制刷新
<el-table
:data="fkgdTableData"
:key="itemKey"
height="400px"
>
</el-table>
//JS代码
//在赋值的方法中设置key的值 实现表格内容刷新
this.itemKey=Math.random();
java将数据处理成JSON树形结构
场景:数据库表有公司的部门关系表,需要根据部门关联关系在前端显示一个树形结构图;
思路:前端可使用tree相关组件,在后端查询部门数据并使用树形结构封装成JSON对象,传递给前端直接调用。
效果:

实现过程:
1. 定义TreeNode实体类(定义树结构属性)
package com.broad.emc.entity;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.List;
import java.util.Objects;
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class TreeNode {
private Integer id;
private String bmmc;
private Integer pid;
// children属性用于保存当前记录的子节点信息
// 注意:数据中对应的实体没有该字段,我们可以从数据库中查询所有记录后,再使用BeanUtils或MapStruct相关工具进行转换
private List<TreeNode> children;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
TreeNode treeNode = (TreeNode) o;
return Objects.equals(id, treeNode.id) && Objects.equals(bmmc, treeNode.bmmc) && Objects.equals(pid, treeNode.pid) && Objects.equals(children, treeNode.children);
}
@Override
public int hashCode() {
return Objects.hash(id, bmmc, pid, children);
}
}
2. 数据处理和封装(树节点关系:上下级关系为下级的pid=上级的id)
@RestController
@RequestMapping("/treeNode")
@Slf4j
public class infoController {
/**
* 单个父节点模式
*
* @return
*/
@GetMapping("/oneFather")
public TreeNode listOne() {
List<TreeNode> nodes = new ArrayList<>();
// 封装数据:模拟数据数据
// 注意:从数据库中查询到的数据没有childrenNode属性,那我们可以使用BeanUtils和mapstruct进行对象转换
// id可自定义 为避免重复可从10000开始自增
Collections.addAll(nodes,
//根节点
TreeNode.builder().id(1).pid(0).bmmc("xxxx公司").build(),
//子节点1
TreeNode.builder().id(2).pid(1).bmmc("总裁办").build(),
//1.1
TreeNode.builder().id(3).pid(2).bmmc("美术组").build(),
//1.2
TreeNode.builder().id(4).pid(2).bmmc("信息化部").build(),
//1.2.1
TreeNode.builder().id(5).pid(4).bmmc("软件开发课").build(),
//子节点2
TreeNode.builder().id(6).pid(1).bmmc("人力部").build(),
//子节点3
TreeNode.builder().id(7).pid(1).bmmc("财经部").build()
);
// 获取树节点
TreeNode root = nodes.stream().filter(node -> Objects.equals(node.getPid(), 0)).findFirst().orElse(null);
if (root == null) {
return null;
}
root.setChildren(getChildren(root, nodes));
return root;
}
/**
* 多个父节点模式
*
* @return
*/
@GetMapping("/manyFather")
public Set<TreeNode> listMany() {
List<TreeNode> nodes = new ArrayList<>();
// 封装数据
Collections.addAll(nodes,
TreeNode.builder().id(1).pid(0).name("江西省").build(),
TreeNode.builder().id(2).pid(1).name("吉安市").build(),
TreeNode.builder().id(3).pid(2).name("遂川县").build(),
TreeNode.builder().id(5).pid(1).name("赣州市").build(),
TreeNode.builder().id(6).pid(5).name("章贡").build(),
TreeNode.builder().id(7).pid(0).name("浙江省").build(),
TreeNode.builder().id(8).pid(7).name("杭州").build()
);
// 封装树节点
Set<TreeNode> root = nodes.stream().filter(node -> Objects.equals(node.getPid(), 0)).collect(Collectors.toSet());
if (CollectionUtils.isEmpty(root)) {
return null;
}
// 遍历树节点
root.stream().forEach(rootNode -> {
rootNode.setChildrenNode(getChildren(rootNode, nodes));
});
return root;
}
/**
* 递归获取根节点的子节点信息
*
* @param root 根节点
* @param nodes 要遍历的节点
* @return
*/
private List<TreeNode> getChildren(TreeNode root, List<TreeNode> nodes) {
List<TreeNode> childrenNodes = nodes.stream()
// 使用stream流过滤出数据的父级id信息等于根节点的id信息的数据
.filter(node -> Objects.equals(node.getPid(), root.getId()))
.map(childNode -> {
// 同时使用map方法对每个过滤后的数据进行处理,递归找到其对应的子数据
childNode.setChildrenNode(getChildren(childNode, nodes));
return childNode;
})
.collect(Collectors.toList());
return childrenNodes;
}
}
调用单个父节点方法返回结果
{
"id": 1,
"bmmc": "xxxx公司",
"pid": 0,
"children": [
{
"id": 2,
"bmmc": "总裁办",
"pid": 1,
"children": [
{
"id": 3,
"bmmc": "美术组",
"pid": 2,
"children": []
},
{
"id": 4,
"bmmc": "信息化部",
"pid": 2,
"children": [
{
"id": 5,
"bmmc": "软件开发课",
"pid": 4,
"children": []
}
]
}
]
},
{
"id": 6,
"bmmc": "人力部",
"pid": 1,
"children": []
},
{
"id": 7,
"bmmc": "财经部",
"pid": 1,
"children": []
}
]
}















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









