







# 关键词: DTW动态时间规整 、yolov5、tensorflow加载关键点-检测模型、pytorch加载人物-检测模型,tensorflow训练骨骼关键点检测模型、mediapipe关键点识别、多人2d检测:自上而下(top-down)
# 目标;
1、了解人体关键点,和动作、动态识别,
2、训练自己的关键点检测模型,
3、基于dtw算法的动作、动态识别!!!
关键点检测: 1、人脸关键点、 2、人体关键点、 3、特定物体、轮廓什么的!
人体骨骼关键点: Pose Estimation、最热门、最有难度、也是最广泛的!!
应用: 1、行为识别、2、人机交互、3、智能家居、4、虚拟现实、
细分: 1、单人、 2、多人、 3、2d、 4、3d
关键点,3类的检测模型:
1、基于坐标的 coordinate: 【回归模型!】
将关键点坐标(采集的训练样本),作为最后网络需要回归的目标(target),
网络直接得到,每个坐标直接的位置信息。(今天采用的!)
2、基于heatmap概率图, 【类似于图像分割】热力图,
将每一类坐标同一个概率图表示,
对图中的每一个像素位置,都给一个概率,表示该点属于某个类别---关键点的概率,
越接近关键点,越接近1; 距离关键点越远,越接近0;
3、基于heatmap + offset, heatmap + 偏移:
谷歌2017年在 cvpr 提出的!
更复杂的 heatmap概率图,并且加入了偏移offset..
单人2d检测: 14-20多篇文献
多人2d检测: 1、自上而下(top-down)
目标检测 + 单人人体骨骼关键点识别: 抠出车牌、检测识别!
2、自下而上(bottom-up)
关键点检测 + 关键点聚类: 所有人的点全检测出来,再聚类出来,看看是谁的!
优劣: 1、自上而下:精度高 2、自下而上:速度快!!!
OpenPose: 经典的《自下而上》!!!
一、训练自己的关键点,检测模型... tflite在windows上,可能只支持python 3.7
创建环境: conda create -n course_action_env python=3.7
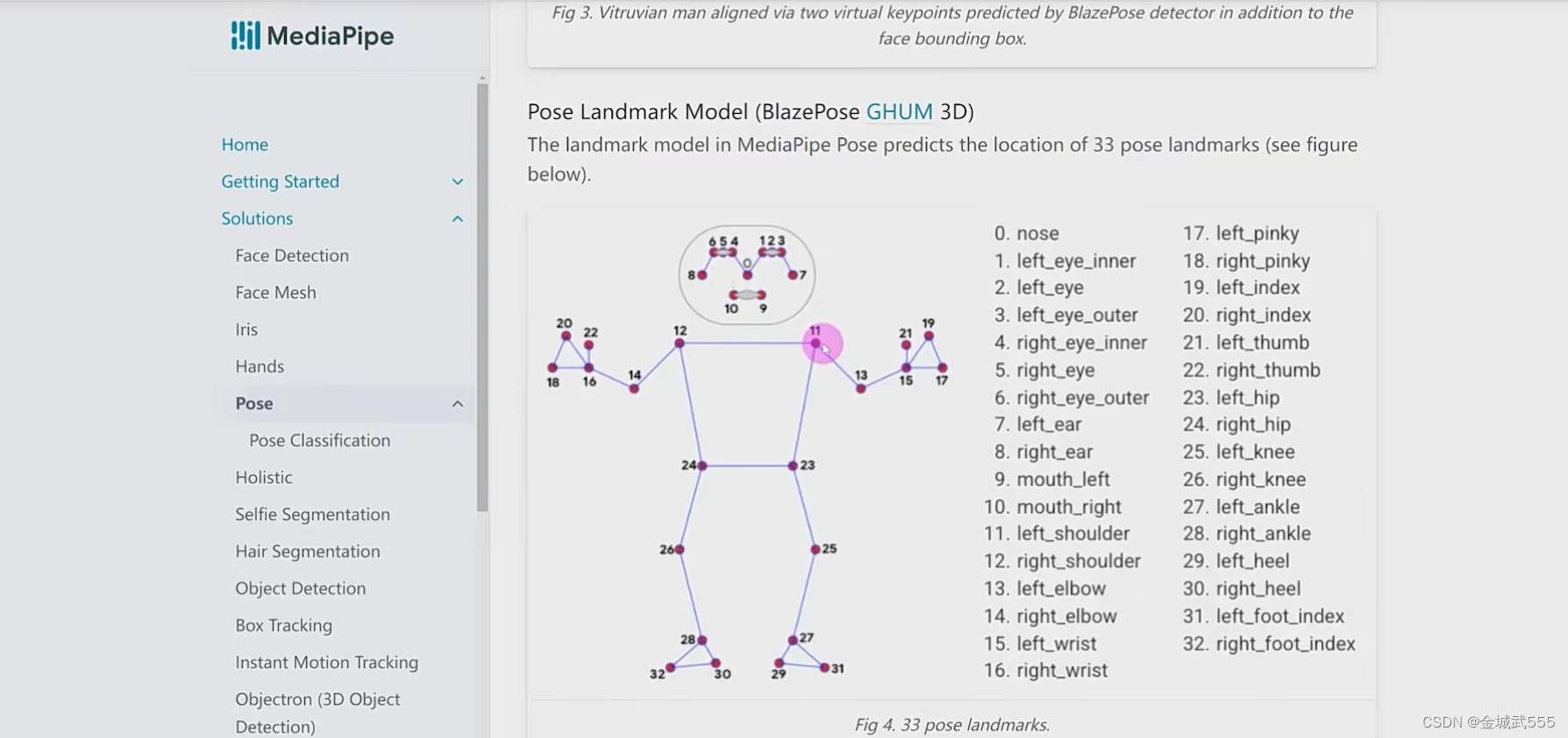
【11:17】 6个关键点,肩膀开始的,6个关节点!!!
【pytorch下载】
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
开启,采集脚本,采集自身关节点数据!!!
采集时、不要在人多的时候采集,以免影响,采集的质量,多人会导致窗口大小不稳定!!!
1、数据预处理、合成npz文件:
1、img数据-> resize压缩成128、灰质化、、/255 归一化0-1、reshape增加一个通道数c==1
2、lable标签-> 读取关节点坐标的数据、转为numpy数组、dtype==‘float’
2、搭建神经网络模型训练:
不需要onehot独热编码,分类才需要,我们是回归!!!
# 科学计算包: pip install scikit-learn
# 作用:划分测试集、和训练集!!!
# tensorflow训练包: pip install tensorflow-gpu==2.6
# 报错: yolov5环境下,tensorflow绑定设备不显示,
# 解决: 用自己的 tf2.6的环境,作为替代,切换环境!! course_action__env [对应环境!!!]
1、今天使用的是 tensorflow keras Resnet50 # --可以百度搜索一下架构图、架构、相当复杂!!!
# 地址: https://tensorflow.google.cn/api_docs/python/tf/keras/applications/resnet50/ResNet50
# action报错!!!无法解读到 cuda设备!!!
# weights='imagenet', 可以基于weights='imagenet',预训练的!!!
2、可以直接使用,keras自带的 resnet50架构,调整:
1、定期存储:保留最好的 loss 2、提前终止: 设置大一点的epoch,loss30次不降自动终止
3、动态学习率: 之前都是固定学习率,更好地拟合, 刚开始学习率大,后面越来越小!!!让模型,更好地寻找一些参数!!
4、性能好; 增大 batch-size: 64-> 100....
3、测试训练模型:
1、加载模型 2、图片预处理、升维度(人数的参数) 3、模型预测: model.predict(img_input)
4、预测结果reshape:result[0].reshape((-1,2)) 5、坐标点还原:img_h,img_w = img_raw.shape[:2],乘上、画点!!
4、转化为 tf_lite,轻量级模型:
1、# 构造转换器
converter = tf.lite.TFLiteConverter.from_saved_model('./data/enpei_pose_resnet_128/')
2、# 转换
tflite_model = converter.convert()
3、# 保存lite
with open('./data/enpei_pose_resnet_128.tflite','wb') as f:
f.write (tflite_model)
# 小插曲: pandas 明明下载了,却引用不了:(解决方式如下 jupyterlab的!!!)
# 小插曲 : jupyter lab 罢工:
ImportError: cannot import name 'COMMON_SAFE_ASCII_CHARACTERS' from 'charset_normalizer.constant' (E:\mini\envs\course_action_env\lib\site-packages\charset_normalizer\constant.py)
# 解决方式: pip install chardet (修复 jupyter lab!!)
# 训练好的模型,放到3.project/weights/custom_resnet_128 下面
# code . 直接进入 VScode....
# 代码::: 【记得】 cd yolov5, pip install -r requirements.txt,下载 yolov5所需要的依赖!!!
cd..
python ./2.pose_demo_resnet_yolov5.py
# 经验教训,总结:: 最好,寻求一个,tensorflow 和 pytorch 中和的版本,这个环境,需要用到!!!
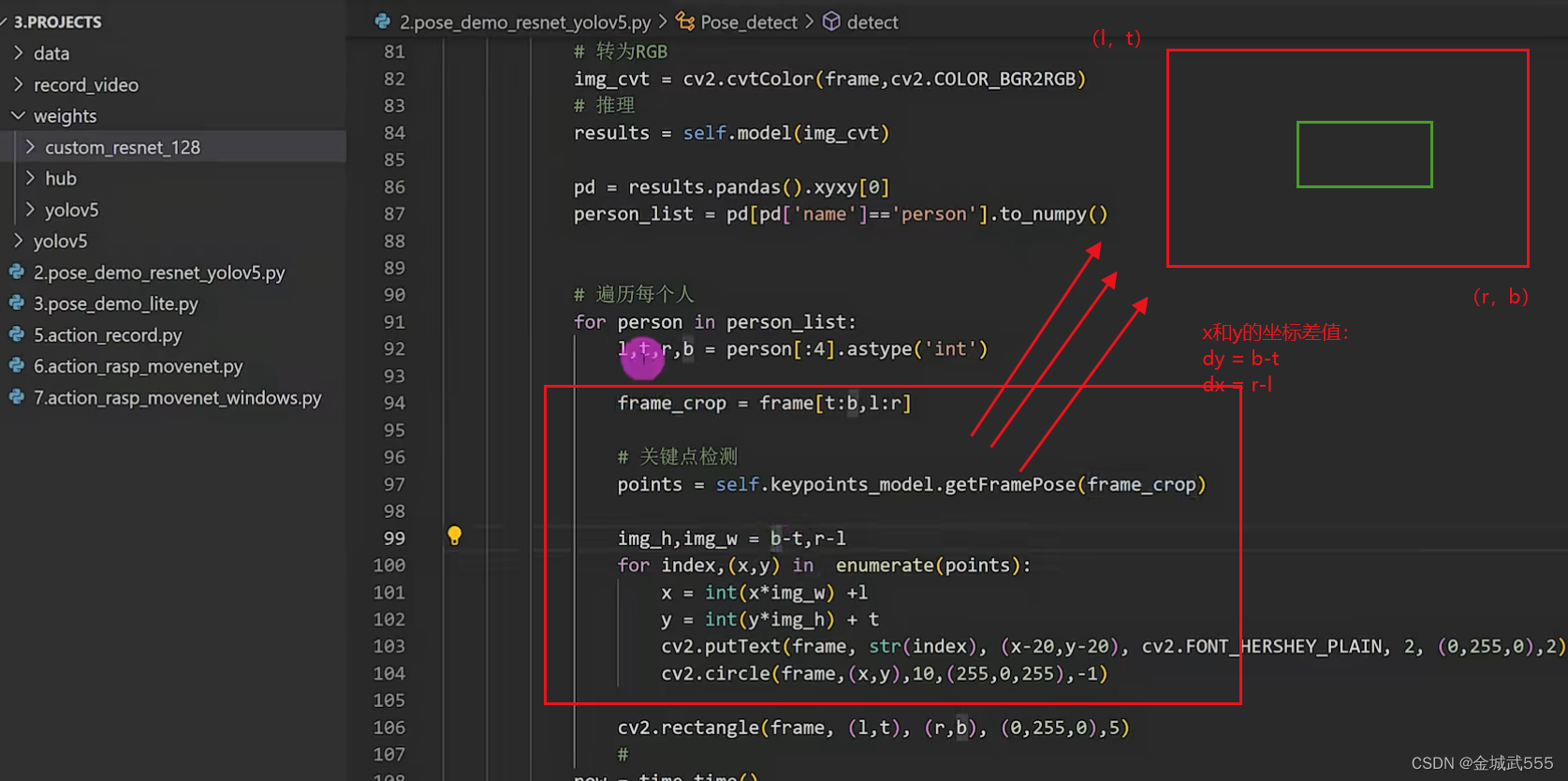
1、 # 加载、自定义关键点检测--模型
self.pose_model = tf.keras.models.load_model('./weights/custom_resnet_128/best_model_resnet_128.hdf5')
2、 # 加载、yolov人物检测--模型
self.model = torch.hub.load('./yolov5', 'custom', path='./weights/yolov5/yolov5m.pt',source='local') # local repo
# 速度较慢; 既要加载yolov5模型(pytorch),又要加载 关键点检测模型(tensorflow!)!!!!
5、若要再树莓派运行: yolov5运行不了(pytorch), 用tf_lite 的 ssd_mobilenet 运行,替代检测任务!!
完整tensorflow也比较卡,装推理引擎tf_lite,即可,传入压缩后的模型!!!按照步骤即可!!!
# 报错: ModuleNotFoundError: No module named 'tflite_runtime'
# 目录whl: 切入目录,pip install .whl ,即可!!!
# tflite_runtime 仓库地址:::
https://github.com/google-coral/pycoral/releases/download/v1.0.1/tflite_runtime-2.5.0-cp38-cp38-win_amd64.whl#sha256=efcd5605885811b5a967494fdc64bb18b5fde145db12ded3e886fcc42b3666fa
# 有点卡、3-5帧左右! 原因: 1、加了目标检测,任务多了 2、tflite在win上优化不太好!!!
# 没板子,烧录过程,直接跳过!!! 大致流程,是: 编译 opencv,安装 tflite的包,等等!!!
二、动作识别 action recognition;
3个小的细分,分类:
1、activity: 持续时间较长、长视频的单人或多人行为、 打电话、看书、吃饭、聊天、打球
2、action: 短时间的行为、短视频片段的单人行为、 鼓掌、接吻、拥抱、扔东西
3、hand gesture: 单人的手势! 今天类似于这个!!!
动作识别-领域,
非常大、海康的重点专注领域、因为,它会达到更多的信息抽取!!!
动作识别-算法分类:
1、基于骨架的识别,(today的)
2、基于视觉的:
2.1 two-stream: 特征提取,有两个分支: 1、基于rgb分支的提取的空间特征,2、基于光流分支的提取时间上的光流特征,
最后,结合两种特征,进行动作识别
2.2 c3d: 3d conv 加入了时间特征,直接将2d conv拓展到了3d,直接提取 时间+空间,两方面特征!!
2.3 LSTM 使用CNN提取特征,使用RNN提取时间特征(如变种:LSTM),进行行为识别。。
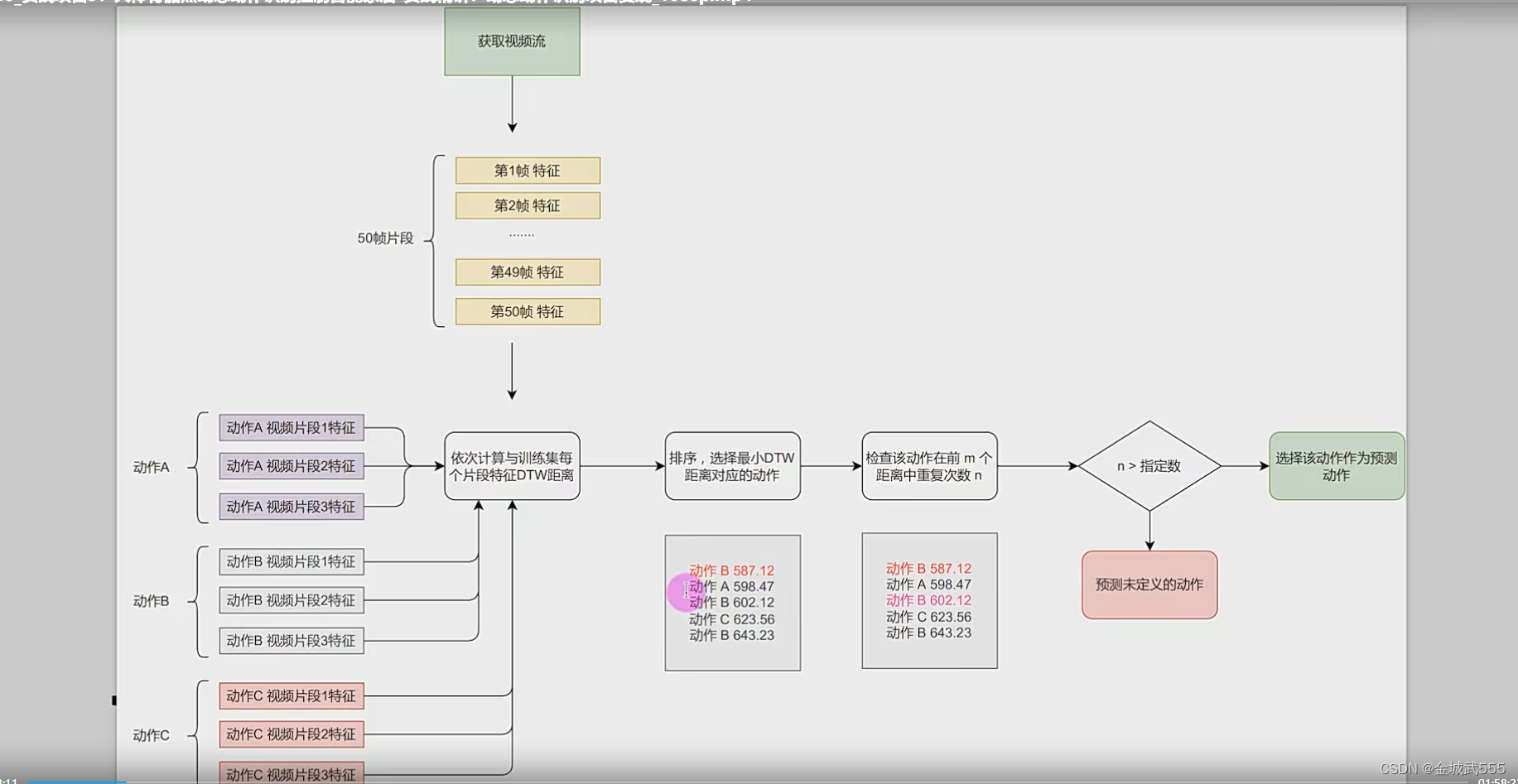
dtw算法,大致流程:
1、多动作,分别录制,多个片段视频,提取动作特征,小的特征,
2、多帧画面,视频流提取,如定期挑选,50帧画面特征,大的特征,
3、依次计算、计算大的特征,与小的特征的 DTW 距离!
4、距离排序,最小的最接近,检查该动作,在m帧画面中,是否满足重复n次,(权重)
5、满足 >n 条件,预测应该是,某动作!!
大致: 1、各动作片段视频,提取特征 -> 2、大视频、视频流、提取特征 -> 3、计算视频流中,各动作的 dtw距离 -> 4、由小到大排序 -> 5、最满足筛选条件的,认定为《某动作》!!
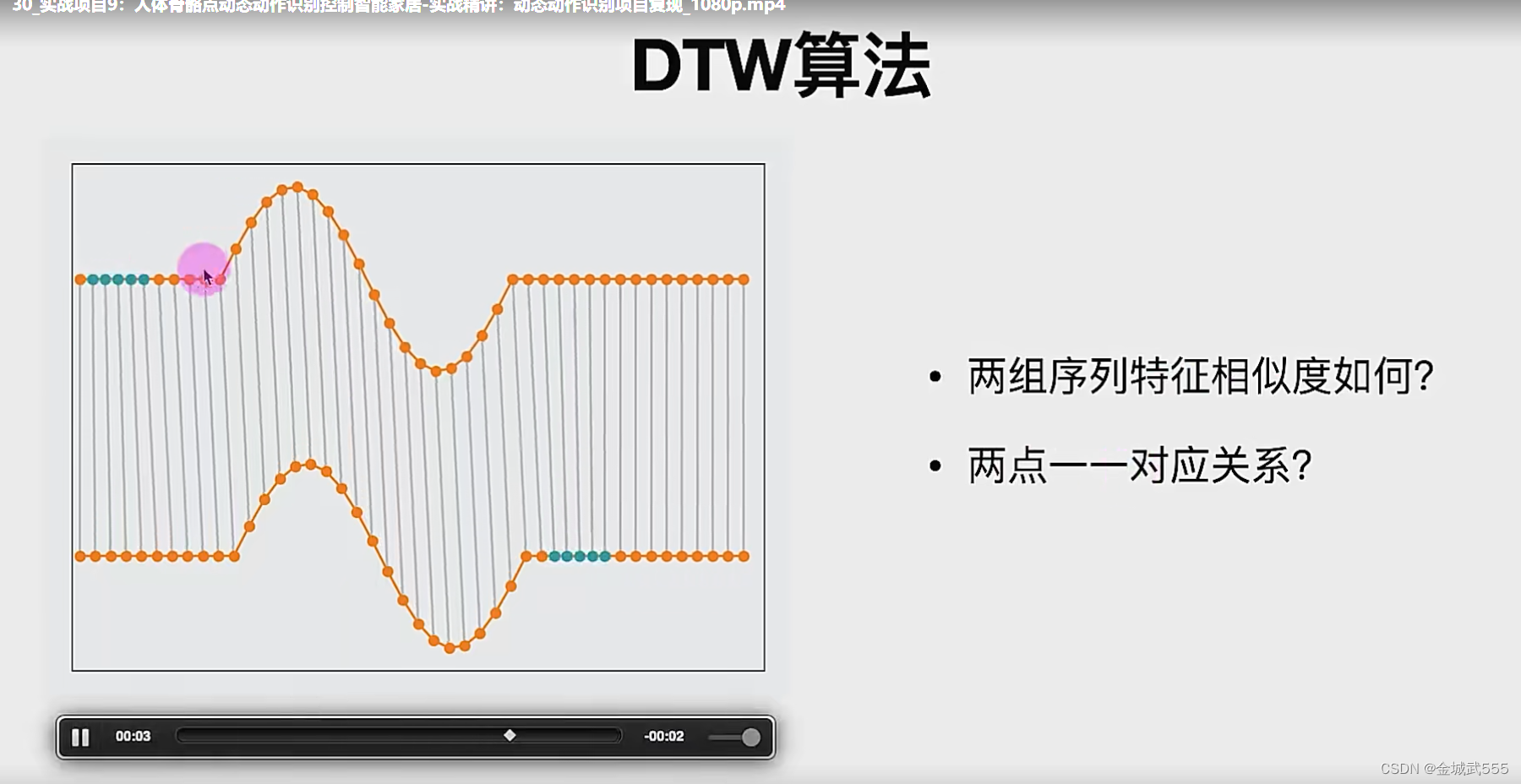
DTW 算法: Dynamic Time Warping ,《动态时间规整 》算法!!!!
很老的算法,最早用在于语音识别,
最大作用: 可以计算、两个时间序列的相似度,
尤其是,两个时间速度不同的情况,节奏快慢不等的情况下,不同人读一个音频词,不同人走路速度,
最厉害的是:他会扭曲不同的时间长度,局部缩放较长的时间长度,使得动作时长,尽量相等!!!
如: 同一个动作,有时摆的时间长、有时摆的时间短!!!
1、动作录制:
脚本录制: 注意、动作要干净、不要夹带无用的动作....
利用: 各个关节点、构建的其夹角、形成特征 。
两点相减 == 向量:【后 -前 】 0-2,2-4
夹角 = =两向量的差值,再 arc cos求出来!!!
相互之间的夹角:::构成了特征!!!
不用坐标做特征、选夹角的原因: 坐标会移动、夹角即使目标移动、也可方便稳定计算!
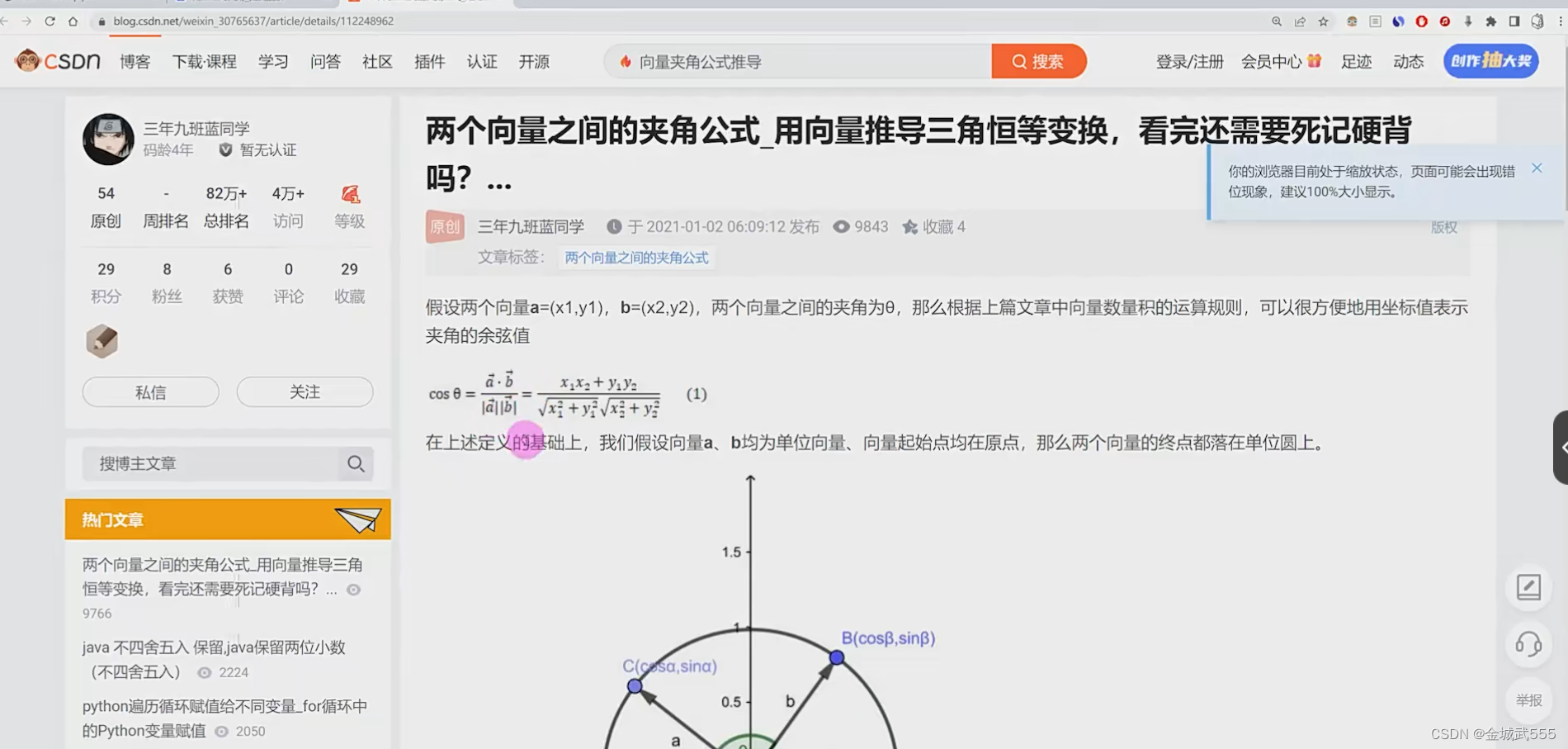
向量的夹角 cos∠ = (a->*b->) / |a|*|b|
夹角的cos = 向量的点*积 / 向量的模*积, 在 arc cos,求出夹角!!!
点积: dot = np.dot(v1,v2)
模积: norm = np.linalg.norm(v1) * np.linalg.norm(v1) # 有点像,欧氏距离公式啊!!!
return np.acrcos(dot/norm)
前提: 两向量,方向不一致,既是 ∠ !=0,
判断方式: if np.array_equal(v1,v2):
return 0 # 直接返回 夹角 ==0 !!!
2、代码部分:: 难度不大,但是难写,很复杂,时间上也特别耗时,意义不大!
仅仅作为dtw算法的了解,供后续使用,本次就不再复现了!!大体上陈述几个核心的主要点!
pip install fastdtw
from fastdtw import fastdtw
dis_list = []
# 遍历动作名称、视频特征
distance,path = fastdtw(seq_feat,video_feat) # 传入序列特征、视频特征
dis_list.append([action_name,distance])
# 转为numpy
dis_list = np.asarray(dis_list,dytype=object) # 两个点: 转为numpy,方便排序;既有str,又有float,用object类型,防止报错!!
# 排序(距离:由低到高)
dis_list = dis_list[ dis_list[:,1].argsort() ][:self.batch_size] # 每行的第二列,排序,筛选32帧的前4个(batch_size个)!!m!!!
# 排名第一的动作
first_key = dis_list[0][0]
# 前m次重复次数
max_num = np.count_nonzero(dis_list[:,0]==first_key) # 每行第二列中,排名第一动作的重复次数, m中找n...
# 是否满足> 阈值n ==2,
if max_num / batch_size >=0.5: # 用比例 0.5 表示!!!
return first_key # 返还,动作名字!!!
else:
return 'unknow!' # 不满足条件,无法判断!!!


















 6
6

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









