







YOLOV2笔记
前言
YOLOv2针对YOLOv1的问题进行了改进,YOLOv2的改进点有新颖的,也有借鉴之前工作的。改进后的模型YOLOv2在PASCAL VOC和COCO等标准检测任务中是最先进的。
YOLOv2在保持处理速度的基础上,从预测准确(Better),速度更快(Faster),识别对象更多(Stronger)这三个方面进行了改进。
话不多说,看看都改进了哪些吧。
YOLOv2算法思想
YOLOv2的论文题目是:《YOLO9000:Better,Faster,Stronger》
9000是指可以识别9000种对象,后面就更通俗易懂了。更好,更快,更强(奥运会口号!)
YOLOv2的论文发表于2017年的CVPR会议,针对YOLOv1主要做了如下改进工作:

这里可以看出共有10点改进的策略。每个✔的地方代表加入这种策略,对应下方的MAP的变化,可以发现,每增加一个改进点,MAP基本上都是稳步增加的。最终从63.4增加至78.6。
YOLOV2的网络结构图是这样的,先放在这儿当总览了,以后再学习新的网络,先看网络结构图,就知道和其他网络的区别了。
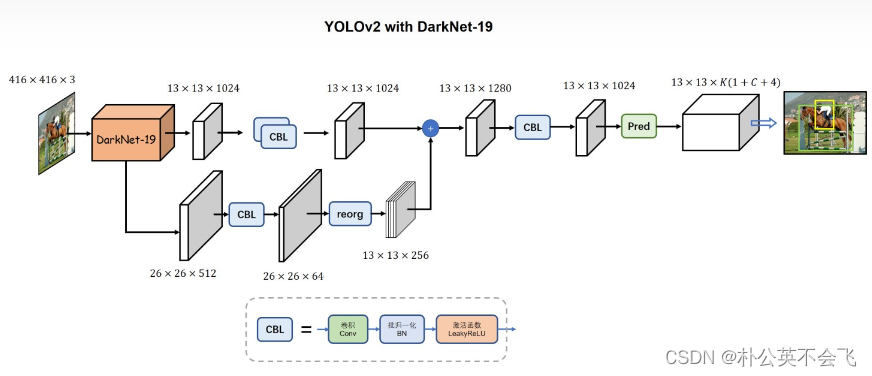
现在来一起看看这些策略吧。
1. Better
与最先进的探测系统相比,YOLO有许多缺点。与Fast R-CNN相比,YOLO存在大量的定位误差。YOLO具有较低的召回率。因此,我们主要关注提高召回率和定位,同时保持分类的准确性。
1.1 Batch Normalization(BN层)
根据原文叙述,BN层可以显著提高收敛性,同时消除其他形式的正则。通过在YOLO的所有卷积层上添加BN层,在mAP上得到了超过2%的改进。批处理归一化还有助于模型的正则化。通过BN层,我们可以在不过度拟合的情况下从模型中去除dropout。
翻译过来中国话,一句也没看懂,因此有必要深入理解一下BN,在后续的网络中,这成为了必不可少的东西。
BN是2015年提出的一种方法。
原文链接:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
从原文摘要中,是这样描述的。训练深度神经网络是复杂的,因为在训练过程中,每一层输入的分布都会随着前一层参数的变化而变化。这通过要求较低的学习率和谨慎的参数初始化来减慢训练速度,并使训练具有饱和非线性的模型变得非常困难。这种现象称为内部协变量移位,并通过BN层输入来解决问题。
论文作者是Google的研究人员,他们将这一现象总结为内部协变量移位 Internal Covariate Shift,简称 ICS。
通俗一点讲:网络深度越深,训练起来越困难,收敛越慢。
其实,深度学习的本质就是学习数据的分布规律,拟合出一个函数,可想训练数据和测试数据若分布相同,此时的泛化能力较强(对新鲜样本的适应能力强)。可随着网络的逐渐加深,就不再难么简单了。每一层输入的分布都会随着前一层参数的变化而变化*。这样一层又一层的变化,就会导致高层的数据变化剧烈,为了适应底层数据参数,就会对学习率等进行小心翼翼的设计,收敛速度将变慢。
这样就理解了,每一层网络参数的分布发生变化,网络每次迭代都会学习适应不同分布,收敛将变慢。
BN层是通过如下方式实现的:

1.输入数据集合B,两个可训练参数γ和β。
2.计算B的均值和方差
3.进行零均值归一化(归一化到0-1之间),这里的经过处理的数据符合标准正态分布,即均值为0,标准差为1。
4.乘以相应的系数进行调整
归一化的目的:将数据规整到统一区间,减少数据的发散程度,降低网络的学习难度。BN的精髓在于归一之后,使用作为还原参数,在一定程度上保留原数据的分布。
讲直白一点,就是为了让数据分布更均匀,好计算。
关于这部分详细的资料,大家可以在最后的参考学习链接中看一看,重点理解一下如何进行的计算。
1.2 High Resolution Classifier(高分辨率分类器)
YOLOV1中使用的是224×224的GooleNet进行的训练,而进行预测时是采用的448×448,这样分辨率会受到影响。在YOLOV2中,在采用224x224 图像进行分类模型预训练后,再采用448x448的高分辨率样本对分类模型进行微调10个epoch,使网络特征逐渐适应 448x448的分辨率。
这里是好理解的,训练用一个分辨率,推理再用另外一个不同的分辨率是行不通,微调解决了这一问题。
这样的高分辨率分类网络使其的mAP增加了近4%。
1.3 Convolutional With Anchor Boxes(锚框)
在YOLOV1中,最终在图像中画出的框叫bounding box(BBOX),它是经过一系列卷积操作后,经过全连接层,提取了每个grid cell中的10维度的信息来完成的。这样想一下,每个grid cell中的两个BBOX,都是随机的,无序的,可能会出现在图像的任何地方。
如何事先先准备好一些框,完整包围起图像,是不是更好呢,YOLOV2就是这样做的。
在YOLOV2中,去除了全连接层,使用了锚框思想(Anchor)(这字念Mao!)。
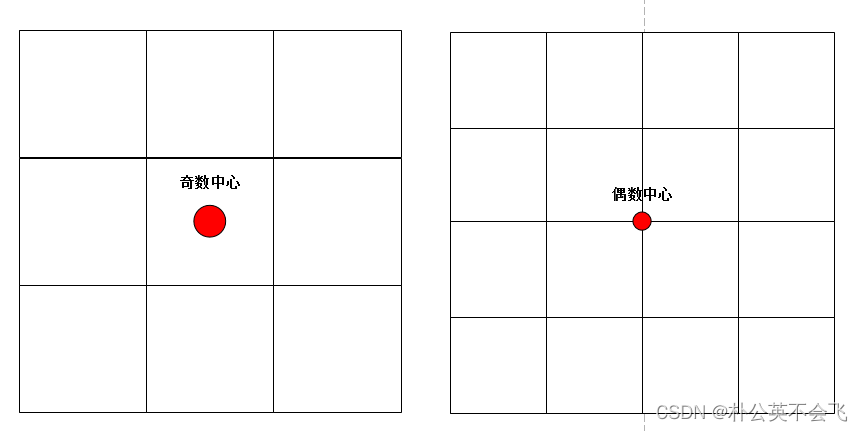
将网络输入缩小至操作416×416的图像,而不是原来448×448。这样做的目的是使得最后的特征图是个奇数。
在YOLOV2中最后的特征图可以看出,特征图是13×13的大小。这就意味着,最中间的grid cell会是一个单独的格子,他就会成为图的中心。如果一个大一点的物体占据整个图像,那么正好就可以用中心的grid cell预测,就像下面那样,作者是多少有点设计师在身上的。
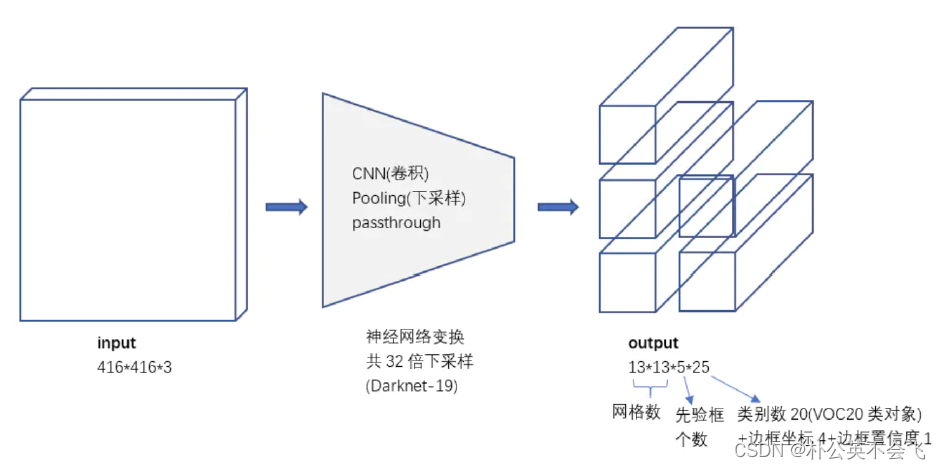
同时,由YOLOV1原来的一个grid cell产生两个BBOX变换成一个grid cell中包含5个BBOX,而且每个包含25个维度的信息,分别为中心点坐标x,y,宽w,高h,20个类别。不过现在不能再叫bounding box了,应该叫Anchor box。
13×13×5=845,这样就有了845个Anchor,这样可比YOLOV1(98个)能检测的对象多多了。
那么Anchor是如何设计的呢?这里作者在使用时,遇到了两个问题,并通过一些方法进行了解决。
第一个问题是:Anchor的尺寸问题。
网络是可以学习适当地调整框的大小和个数的,但如果为网络提前选好更好的框,可以使网络更容易学习预测,并完成检测。与人工选择Anchor不同,作者用的是K-means方法。
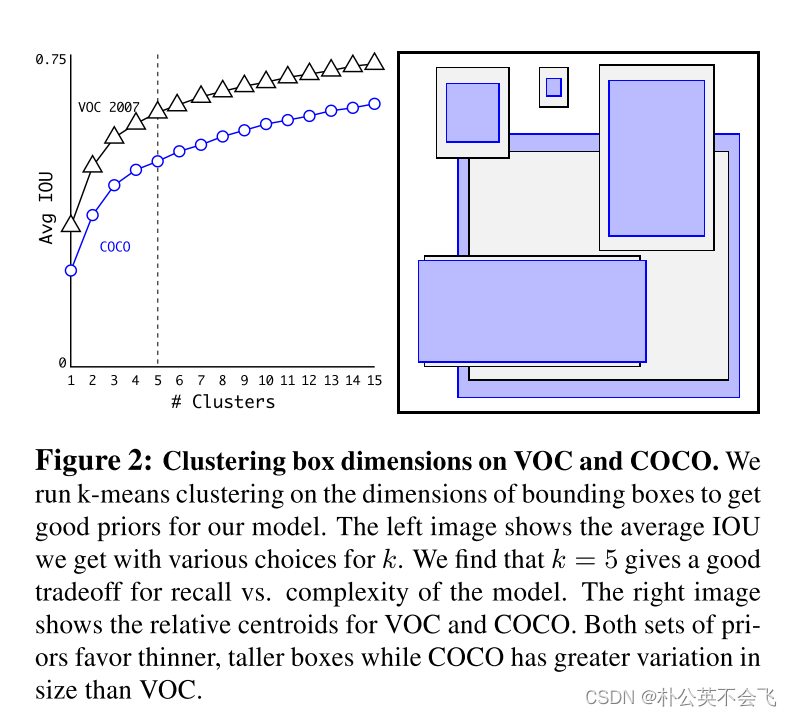
作者在 VOC和COCO数据集上通过Ground Truth进行聚类统计(采用K-means算法),实验发现当Anchor的尺寸数量k=5时,可以很好的平衡召回率和模型的复杂程度。而且从图中可以看出,瘦高的框比矮胖的框多一些,这可能跟数据集中的物体的形状有关系呢。
k-means方法一般使用的欧几里得距离两个点之间的坐标来进行确定质心,但这样会产生大一点的误差,其实更在意的是IOU。也就是真实框和标记框的交并比面积。因此采用了下方的定义方法来作为距离的度量。
想了解聚类的,可以看这个动画:https://www.zhihu.com/zvideo/1375592290656768001
聚类的目的是使Anchor和groud truth的有更大的IOU值,因此尺寸是不需要考虑的。
IOU越大,1-IOU就越小,这样就保证距离越小,IOU越大。
具体的操作可以参考这篇文章:https://blog.csdn.net/m0_50617544/article/details/120639193
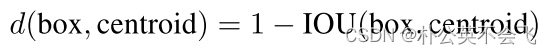
最终作者通过K-means和手动选择的方法进行了实验对比,发现聚类给出的结果完全胜出于自己选。
这样肯定就用聚类了。下图就可以发现,聚类k=5时的效果能达到Anchor=9时的效果。
YOLOV2最终选择了聚类的五种尺寸的anchor box。

作者在这时又遇到了第二个问题:在迭代的早期,模型不稳定。
这种不稳定性主要是因为预测Anchor的坐标。之前的算法(含YOLO)产生的Anchor(这里同一叫这个名字吧),都是随机的,意思是它可以出现在图像的任何一个位置,这样不由它“所在”的grid cell控制了,就会需要更长的时间来确定它的位置。
因此,首先需要约束Anchor的范围,不能让Anchor随意的大或者小,在YOLOV1中的BBOX是随意生成的。
YOLOV2中将边框的结果约束在特定的网格中,每个特征图中的grid cell生成5个Anchor box。
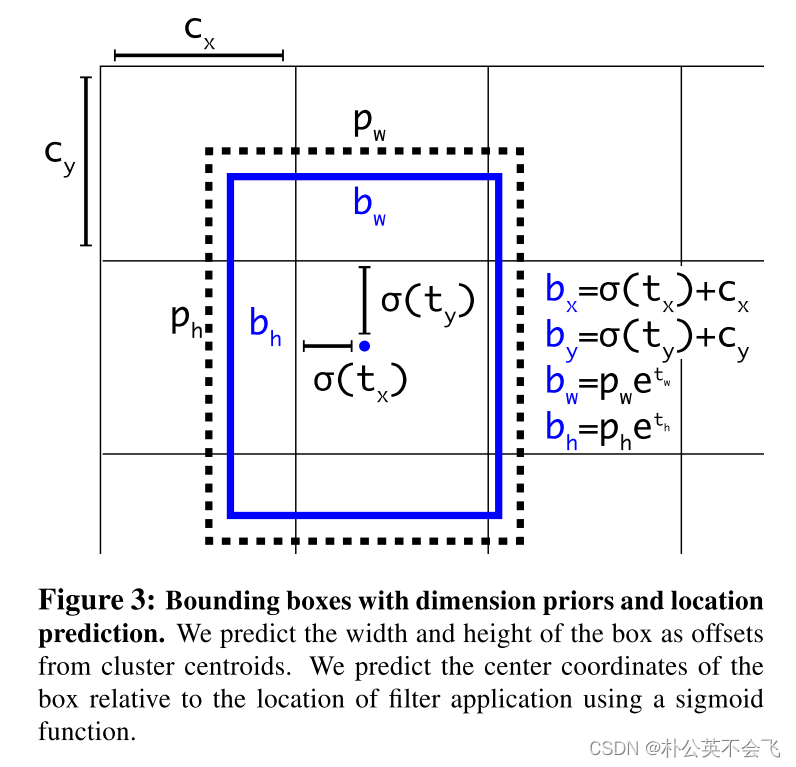
具体的图示如下:
bx, by, bw, bh 分别为预测框的中心点坐标,宽高
σ 是sigmoid函数(约束在了0-1之间)
cx,cy是当前网格左上角到图像左上角的距离。图中明显就是**(1,1)**
pw和ph是Anchor的宽和高
现在剩下了需要学习的参数tx,ty,tw, th, to 也就是需要通过这五个参数,来调整Anchor的位置。
举个栗子,看的更清楚些。

使用这种方法确定的Anchor的尺寸比起之前直接使用Anchor的版本提高了近5%的MAP。
这样看,使用Anchor思想,每个Grid cell产生的五个不同尺寸的Anchor仅仅都在自己所属的网格中进行中心坐标和尺寸的微调,而全部的Anchor能够覆盖整个图像,这样就更合理了。
1.4 Fine-Grained Features(细粒度特征融合)
图像中对象有大有小,输⼊图像经过多层网络提取特征,最后输出的特征图中,较小的对象可能特征已经不明显甚至被忽略掉了。
如何解决这一问题呢?那就是好好利用不同分辨率的信息。
就像拼积木一样,将某个过程的特征图进行拆分,拆分成四个小的和一个长的,
长的和小的再进行拼接,这样就包含了更多小目标的特征信息
YOLO2引入⼀种称为passthrough层的方法在特征图中保留⼀些细节信息。具体来说,就是在最后⼀个pooling之前,特征图的大小是26x26x512,将其1拆4,直接传递(passthrough)到pooling后(并且⼜经过⼀组卷积)的特征图,两者叠加到⼀起作为输出的特征图。
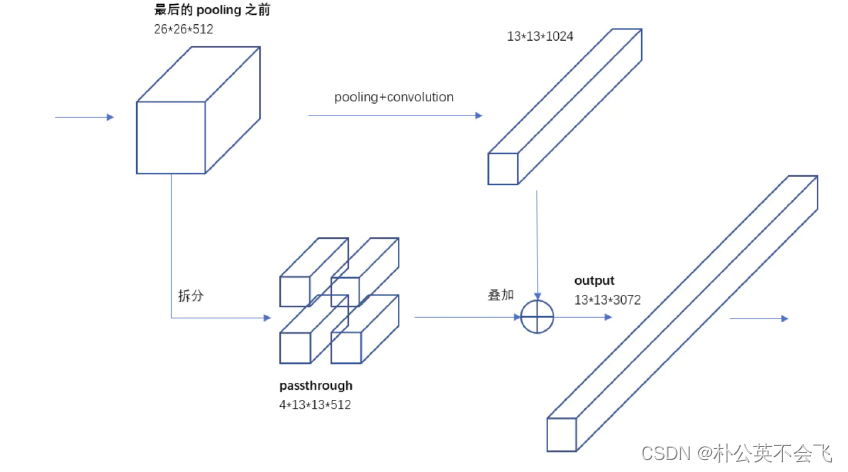
具体的拆分方法是这样的:
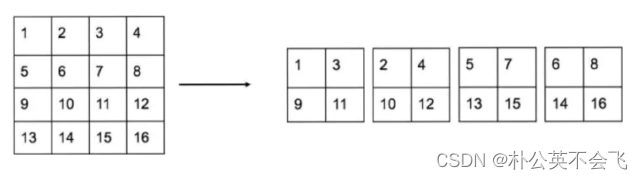
作者是多少有点积木在身上的。
1.5 Multi-Scale Training(多尺度训练)
本方法主要为了应对处理不同分辨率图像。
YOLOV1是使用448×448的图像进行输入的,YOLOV2由于使用了Anchor,分辨率使用了416×416。同时,由于没有了全连接层的限制,这个模型就可以使用不同分辨率了,这样来处理不同分辨率的输入更加灵活。
因为整个网络下采样倍数是32,采用了{320,352,…,608}等10种输⼊图像的尺寸,这些尺寸的输⼊图像对应输出的特征图宽和高是{10,11,…19}。训练时每10个batch就随机更换⼀种尺寸 ,使网络能够适应各种大小的对象检测。
因此,最小的选项是320 × 320,最大的选项是608 × 608。通过将网络调整到那个维度,然后继续训练。
至此,YOLOV2的Better部分也就结束了。
2. Faster
作为目标检测算法,准确是很关键的,但同时也希望它是快速的。现实中的大多数检测应用,如机器人或自动驾驶汽车,都依赖于低延迟预测。工业中的应用也肯定是如此,机器的效率肯定要比人的效率高才有价值。
因此YOLOV2的设计也着重考虑了这个问题。
2.1 Darknet-19
YOLOV2提出了Darknet-19(有19个卷积层和5个MaxPooling层)网络结构作为特征提取网络。DarkNet-19比VGG-16小⼀些,精度不弱于VGG-16,但浮点运算量减少到约1/5,以保证更快的运算速度。下图是Darknet-19的网络结构图。
Darknet-19的19是,有19个卷积层和5个maxpooling层。
这部分工作的预备知识肯定是分类网络了。VGG等,这个还得以后补上呀-。-。
总之,这部分理解的重点就是提出了一个新的网络结构,使得运算速度更快。
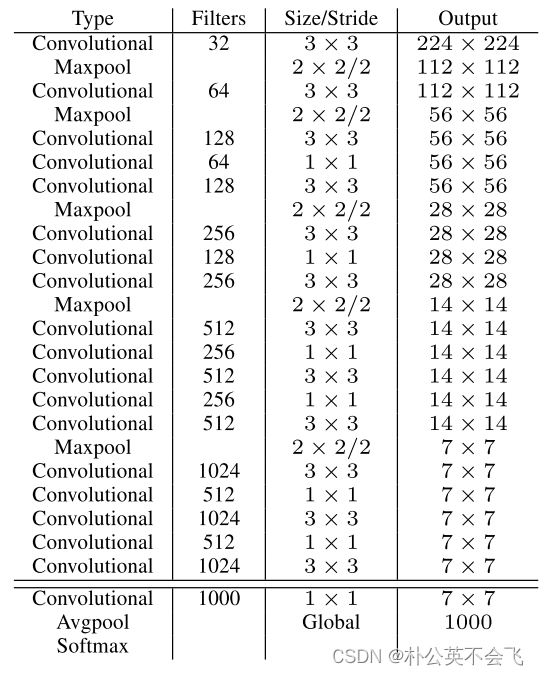
可以往上看看结构总图,就会更清楚,这个只是分类网络。
2.2 Training for classification(训练分类网络)
作者在标准ImageNet1000类分类数据集上训练网络160个epoch,使用随机梯度下降,起始学习率为0.1,多项式速率衰减为4,权重衰减为0.0005,动量为0.9,使用Darknet神经网络框架。
同时使用了标准的数据增强技巧,包括随机裁剪、旋转、色调、饱和度和曝光移位,这个技巧,在以后肯定用得着,先标记一下。
在对224 × 224图像进行初始训练后,将网络调整为更大的尺寸448。对于这种微调,使用上述参数进行训练,但只训练10个epoch,并以10-3的学习率开始。在这个更高的分辨率下,网络达到了76.5%的top-1精度和93.3%的top-5精度。
2.3 Training for detection(为推理所作工作)
这里放这张图就很清楚了。为推理所做的工作整体流程就是这样的。到最后的K=5,C=20,也就是每个grid cell拥有5个Anchor,每个Anchor具有25的维度的信息,包含了坐标值、宽、高、置信度。
为了清楚再放一下这张图吧。
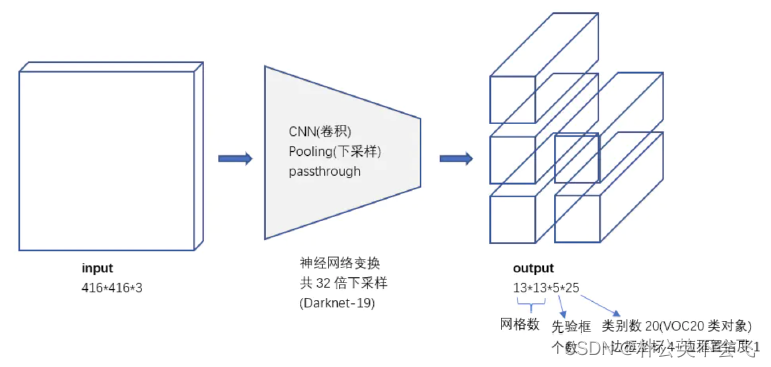
同样的,训练网络160个epoch,起始学习率为10−3,在60和90个epoch时除以10。我们使用的权重衰减为0.0005,动量为0.9。
3. Stronger
这部分工作旨在能够分辨更多类别的物体,因为VOC数据集中只有20个类别,现实中肯定也不只有这20个类别。那么怎么样去让网络升级,识别更多类别的物体呢,肯定是要训练有更多类别的数据集才行。
于是作者使用了ImageNet数据集开展此工作,但是开展工作时候面临了新的问题,类别需要互斥。
正如作者举例,狗是一个类别,狗下面还有不同品种的狗,京巴啊,泰迪啊,腊肠啊,金毛啊等等。
之前做的分类研究时,都是狗、猫、车等这种互斥的对象,要想再往下分一层,就不容易喽。
于是想出了如下办法:
3.1 Hierarchical classification(层次分类)
既然要分类,那就多分一次呗,作者使用WordTree的概念组合ImageNet和COCO的标签。
先分大类,再分小类。
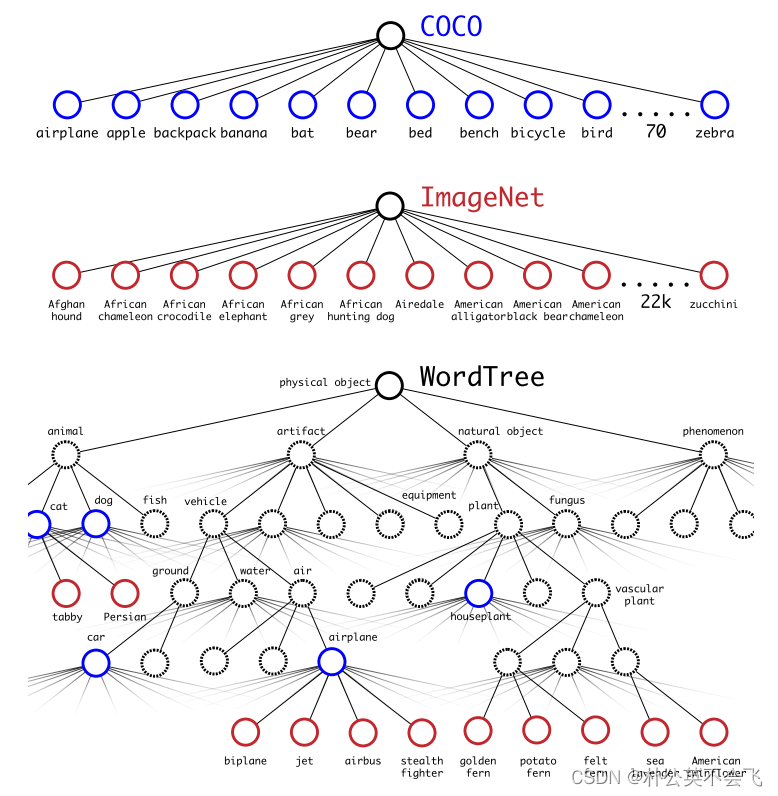
3.2 Joint classification and detection(联合分类预测)
作者想训练一个超大规模的检测器,所以使用COCO检测数据集和完整ImageNet发布的前9000个类创建了组合数据集。
这也就是为啥YOLOV2叫YOLO9000了。
当网络看到检测图像时,正常地反向传播损失。对于分类损失,只反向传播标签对应级别或以上的损失。
这也好理解,有标记框的就可以记录下位置的损失信息,没有标记框的就记录类别损失。
通过这种联合训练,YOLO9000学习使用COCO中的检测数据在图像中查找对象,并学习使用ImageNet中的数据对各种对象进行分类。
这部分实验最终的结果并不是对所有类别都准确,毕竟9000多种,但是打开了一个新的思路。
4.1 损失函数
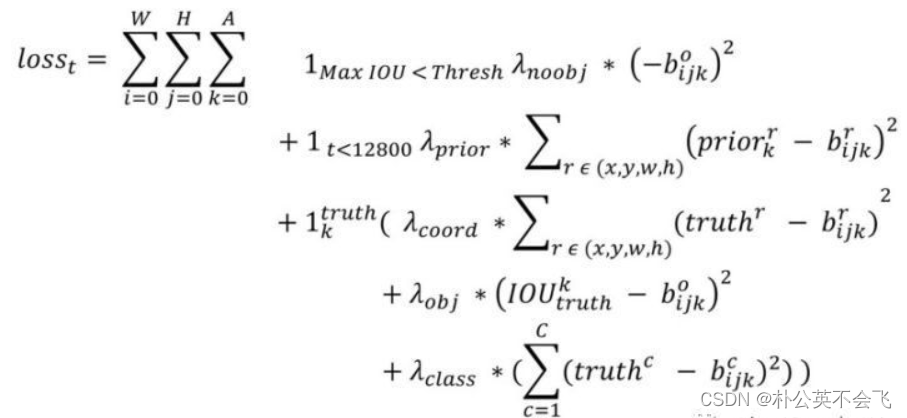
W=13,H=13,A=5,这好理解,13×13×5嘛。
第一部分:用来预测背景;这里计算所有Anchors与Ground Truth(简称GT吧)之间的IOU值,取最大的记作MaxIOU(非0即1),如果小于阈值(Thresh)(原文0.6),那么就把这个框作为预测背景的Anchor。我这里理解的是最小于并接近0.6的第一个框。
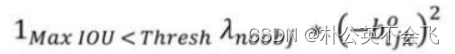
第二部分:计算前12800次迭代的位置误差。让模型更快学会Anchor的位置和形状。
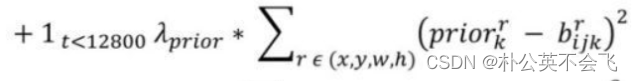
第三部分:这一部分计算的是和GT匹配的预测框Anchor各部分的损失总和。
坐标损失:确定GT中心点落在哪个grid cell上,计算cell的5个Anchor与GT的IOU,不考虑坐标,只考虑形状,将Anchor和GT的中心重合,然后计算出对应的IOU值,IOU值最大的Anchor与ground truth匹配,对应的预测框来预测。
置信度损失:在计算obj置信度时, 增加了一项权重系数。当其为1时,损失是预测框和GT的真实IOU值(darknet中采用了这种实现方式)。而对于没有和ground truth匹配的先验框,除去那些Max_IOU低于阈值的,其它就全部忽略。
分类损失: 同YOLOV1。
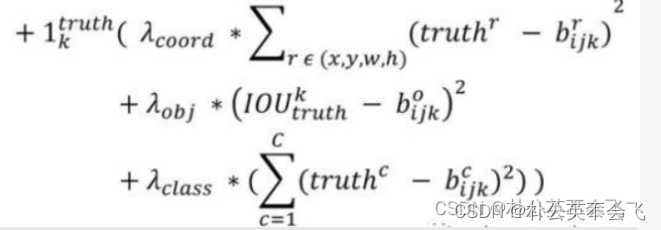
YOLOV2的笔记记到这里告一段落,这里只介绍了思想,没有放代码。
YOLOV3应该会对代码详细解读一下,毕竟看懂代码才是王道!复现,创新才能指日可待!
自己不是计算机专业的,看这论文才9页,但是蕴含的信息非常多,不亏是顶刊论文。很多东西作者并没有放具体那内容,都需要查阅很多资料理解。
深度学习,,,真深啊。
参考:
- http://t.csdn.cn/FoDiB
- https://zhuanlan.zhihu.com/p/93643523
- https://zhuanlan.zhihu.com/p/34879333
- https://blog.csdn.net/qq_38375203/article/details/125502438
- https://blog.csdn.net/linolzhang/article/details/59728206
- https://cloud.tencent.com/developer/article/1547377















 1156
1156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









