







数据库基础篇
因为急于复试,跨考之前也没有学习过数据库,这两天匆匆过了一遍基础篇,但太多Sql语句没有记住,这里赶紧自己总结一下,可能会有错误和纰漏。
绪论
| 人工管理阶段 | 文件系统阶段 | 数据库阶段 |
|---|---|---|
| 程序员管理 | 文件系统管理 | 数据库系统管理 |
| 数据面向程序 | 数据面向应用 | 数据面向现实世界 |
| 无共享,冗余度大 | 共享性差,冗余度大 | 共享性高,冗余度小 |
| 数据不独立 | 独立性差 | 高度的物理独立性和一定的逻辑独立性 |
| 数据无结构 | 记录有结构,总体无结构 | 整体结构化 |

关系数据库
关系代数
笛卡尔积:所有域取值的任意组合
关系模式是型(type),关系是值(value);关系模式是对关系的描述。

- 常用连接运算分为两类:
- 等值连接:笛卡尔积中选出两个属性值相等的那些元组,即等值连接
- 自然连接:两个关系中比较的分量必须是相同的属性,在结果中把重复的属性列去掉
两个关系R和S在做自然连接时,关系R中的某些元组可能在S中不存在公共属性上的值相等的元组,从而造成R中的这些元组在操作时被舍弃,这些被舍弃的元组就叫悬浮元组。
如果把悬浮元组的结果也保存在结果的关系中,其属性设置为空值(null),就叫外连接(左右都保留)。
只保留左边的悬浮元组 --> 左外连接
只保留右边的悬浮元组 --> 右外连接
除运算

元组关系演算语言 ALPHA
语句的基本格式
操作语句 工作空间名 (表达式): 操作条件
ALPHA语言主要操作语句:GET、PUT、HOLD、UPDATE、DELETE、DROP
| ALPHA聚集函数名 | 功能 |
|---|---|
| COUNT | 对元组计数 |
| TOTAL | 求总和 |
| MAX | 最大值 |
| MIN | 最小值 |
| AVG | 求平均值 |
- 下面是一些例子 均来源中国人民大学PPT






域关系演算语言QBE
QBE(query by example)是基于屏幕表格的查询语言,以填写表格的方式构造查询条件,用示例元素构造查询结果的可能情况,查询结果用表格显示。

-
简单查询 以查询全体学生的姓名为例,步骤如下

-
示例元素:域变量,一定要加下划线
-
打印操作符P.:实际上是显示
-
查询条件:可用比较运算符>、≥、<、≤、=和≠,其中=可以省略
| QBE聚集函数 | 功能 |
|---|---|
| CNT | 对元组计数 |
| SUM | 求总和 |
| AVG | 求平均值 |
| MAX | 求最大值 |
| MIN | 求最小值 |
- 下面是一些例子 均来自中国人民大学PPT










关系数据库标准语言SQL(Structured Query Language)
| SQL功能 | SQL动词 |
|---|---|
| 数据查询 | SELECT |
| 数据定义 | CREATE,DROP,ALTER |
| 数据操纵 | INSERT,UPDATE,DELETE |
| 数据控制 | GRANT,REVOKE |

模式
- 为用户WANG定义一个学生-课程模式S-T
CREATE SCHEMA "S-T" AUTHORIZATION WANG;
/* 当没有指定模式名默认为用户名 */
CREATE SCHEMA AUTHORIZATION WANG;
定义模式实际上定义了一个命名空间,在这个空间中可以定义该模式包含的数据库对象,例如基本表,视图,索引等。
- 删除模式
/*
CASCADE(级联) 删除模式时把所有数据库对象全部删除
RESTRICT(限制) 仅当该模式没有下属对象才删除,有下属对象是拒绝执行
*/
DROP SCHEMA <模式名> <CASCADE|RESTRICT>;
基本表
- 定义基本表
CREATE TABLE <表名>
(<列名> <数据类型> [<列级完整性约束条件>]
[,<列名> <数据类型> [<列级完整性约束条件>]
...
[,<表级完整性约束条件>]);
/*
列级完整性约束条件:涉及属性列的完整性约束条件
表级完整性约束条件:涉及一个或多个属性列的完整性约束条件(涉及多个属性必须定义在表级上)
*/
- 以下通过三个表来举例说明
/* 建立Student表,学号主码,姓名唯一 */
CREATE TABLE Student
( Sno CHAR(9) PRIMARY KEY, /* PRIMARY KEY 代表主码 */
Sname CHAR(20) UNIQUE, /* UNIQUE 表示取值唯一 */
Ssex CHAR(2),
Sage SMALLINT,
Sdept CHAR(20)
);
/* 建立Course表 */
CREATE TABLE Course
( Cno CHAR(4) PRIMARY KEY,
Cname CHAR(40),
Cpno CHAR(4), /* 先修课 */
Ccredit SMALLINT,
FOREING KEY (Cpno) REFERENCES Course(Cno) /* 说明Cpno是外码,参照Course表中的Cno列 */
);
/* 建立学生选课表SC */
CREATE TABLE SC
( Sno CHAR(9),
Cno CHAR(4),
Grade SMALLINT,
PRIMARY KEY (Sno, Cno), /* 表级完整性约束条件 */
FOREINF KEY (Sno) REFERENCES Student(Sno),
FOREING KEY (Cno) REFERENCES Course(Cno)
);
- 定义基本表所属模式的方式:
- 表名中明显的给出模式:CREATE TABLE “S-T”.Student(…);
- 在创建模式的同时创建表
- 设置所属的模式
若没有指定搜索模式,系统根据搜索路径来确定,设置搜索路径:SET search_path TO “S-T”,PUBLIC;
- 修改基本表
ALTER TABLE <表名>
[ADD[COLUMN] <新列名> <数据类型> [完整性约束] ] /* 增加新列、列级完整性约束条件 */
[ADD <表级完整性约束> ] /* 增加表级完整性约束条件 */
[DROP [COLUMN] <列名> [CASCADE|RESTRICT] ] /* 删除列,是否级联或限制,第一个为默认 */
[DROP CONSTRAINT <完整性约束名> [RESTRICT|CASCADE] ] /* 删除指定的完整性约束条件 */
[ALTER COLUMN <列名><数据类型> ]; /* 修改列名或数据类型 */
- 一些例子如下
/* Student表增加入学时间列,数据类型为日期类型 */
ALTER TABLE Student ADD S_entrance DATE;
/* 将年龄有字符型该为数字型 */
ALTER TABLE Student ALTER COLUMN Sage INT;
/* 增加课程名必须唯一的约束条件 */
ALTER TABLE Course ADD UNIQUE(Cname);
- 删除基本表
DROP DELETE <> [ RESTRICT | CASCADE ];
/* 删除Student表 */
DROP DELETE Student CASCADE;
索引
CREATE [UNIQUE] [CLUSTER] INDEX <索引名>
ON <表名>(<列名>[<次序>][,<列名>[<次序>]]...);
/*
索引:可以建立在一列或多列上
次序:升序ASC 降序DESC 缺省值ASC
UNIQUE:每一索引只对应唯一数据记录
CLUSTER:建立的索引是聚簇索引
*/

/* 修改索引 */
ALTER INDEX <旧索引名> RENAME TO <新索引名>
/* 将表SC的SCno索引该为SCSno */
ALTER INDEX SCno RENAME TO SCSno;
/* 删除索引 */
DROP INDEX <索引名>;
/* 删除Student表Stusname索引 */
DROP INDEX Stusname;
数据查询
- 数据查询的语句格式

| 语句 | 作用 |
|---|---|
| SELECT | 指定显示的属性列 |
| FROM | 指定查询对象 |
| WHERE | 查询条件 |
| GROUP BY | 对查询结果按指定的值分组 |
| HAVING | 只有满足指定条件的组才能输出 |
| ORDER BY | 对查询结果表按指定列的值的升序或降序排序 |
| 常用查询条件 | 谓词 |
|---|---|
| 比较 | =,>,<,>=,<=,!=,<>,!>,!<,NOT |
| 确定范围 | BETWEEN AND,NOT BETWEEN AND |
| 确定集合 | IN,NOT IN |
| 字符匹配 | LIKE,NOT LIKE |
| 空值 | IS NULL,IS NOT NULL |
| 多重条件(逻辑运算) | AND,OR,NOT |
- 单表查询的例子









| SQL聚集函数 | 作用 |
|---|---|
| COUNT | 对元组计数 |
| SUM | 求总和 |
| MAX | 最大值 |
| MIN | 最小值 |
| AVG | 求平均值 |


- 等值连接和非等值连接


- 自身连接

- 外连接

- 多表连接

- 嵌套查询
子查询的查询条件不依赖于父查询,称为不相关子查询;依赖于父查询的为相关子查询



- 集合查询
| 集合操作 | 关键字 |
|---|---|
| 并 | UNION |
| 交 | INTERSECT |
| 差 | EXCEPT |

数据更新
- 插入元组


- 插入子查询


- 修改数据



- 删除数据



判断一个属性是否为空值,用IS NULL 或 IS NOT NULL 来表示。
空值与另一个值的算数运算结果是空值,与另一个值的比较运算结果为UNKNOWN,原来的真假逻辑扩张为三逻辑值。

视图
- 建立视图



- 删除视图


- 查询视图
用户看来视图和基本表是一样的,但关系数据库管理系统实现视图查询的方法为视图消解法。步骤:1. 进行有效性检查; 2. 转换成等价的对基本表的查询 3. 执行修正后的查询


- 更新视图




- 视图作用:
- 简化用户操作
- 使用户多一种角度看待同一数据
- 对重构数据库提供了一定程度的逻辑独立性
- 对机密文件数据提供安全保护
- 更清晰的表达查询
数据库安全性
用户身份鉴别
像静态口令、动态口令、生物特征识别、智能卡识别等。
存取控制
存取控制机制分两部分组成:定义用户权限,合法权限检查
自主存取控制(DAC):通过SQL的GRANT和REVOKE语句实现。自主存取控制仅仅通过数据的存取权限来进行安全控制,可能存在“无意泄漏”的风险,如高权限的人将隐私数据保存本地后被泄漏。
- 权限授予
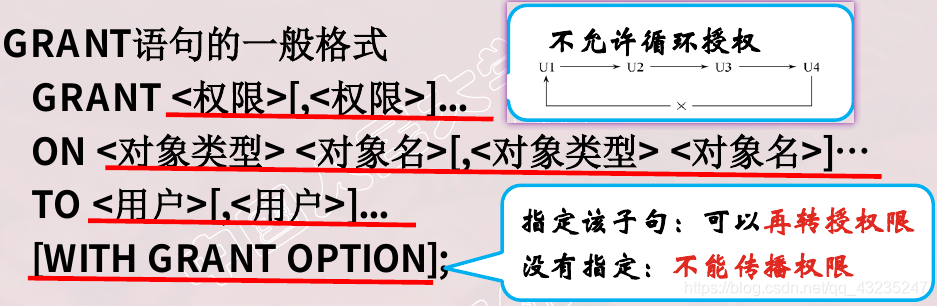


- 权限回收


创建数据库模式的权限:
CREATE USER <username> [WITH] [DBA | RESOURCE | CONNECT];
CREATE USER语句不是SQL标准,这里只是说明对于数据库模式这一类数据对象也有安全控制的需要,也需要授权
- 数据库角色:被命名的一组与数据库操作相关的权限


- 强制存取控制(MAC):使用敏感度标记(Label):TS(绝密)>=S(机密)>=C(可信)>=P(公开)
- 仅当主体许可证级别大于客体密级,主体才能读客体
- 仅当主体许可证级别小于客体密级,主体才能写客体
视图
视图机制:通过视图把要保密的数据对无权存取的用户隐藏起来,对数据起一定程度的安全保护。
审计
审计日志(Audit Log):将用户对数据库的所有操作记录在上面。
审计功能是一个可选项,因为很耗费时间和空间。
/*
审计功能设置:
AUDIT语句:设置审计功能
NOAUDIT语句:取消审计功能
*/
/* 对修改SC表的结构和表数据进行审计操作 */
AUDIT ALTER,UPDATE
ON SC;
/* 取消对SC表的一切审计 */
NOAUDIT ALTER,UPDATE
ON SC;
数据加密
| 存储加密 | 说明 |
|---|---|
| 透明存储加密 | 内核级加密保护方式,对用户完全透明 |
| 非透明存储加密 | 通过多个加密函数实现 |
| 传输加密 | 说明 |
|---|---|
| 链路加密 | 报头报文均加密 |
| 端到端加密 | 只加密报文,不加密报头 |
数据库完整性
数据库的完整性是指数据的正确性和相容性。
实体完整性
如定义的列级约束条件和表级约束条件
违约处理时,如定义了主码,会检查主码是否唯一和主码各个属性是否为空…
参照完整性
- 参照完整性的定义
- CREATE TABLE时用FOREING KEY定义的那些列为外码
- 用REFERENCES短语指明这些外码参照那些表的主码

| 参照完整性违约处理 | 说明 |
|---|---|
| 拒绝(NO ACTION) | 不允许执行该操作,一般为默认选择 |
| 级联(CASCADE) | 对所有造成不一致的元组进行处理 |
| 设置为空值(SET-NULL) | 将参照表中所有造成不一致元组的对应属性设置为NULL |
用户定义的完整性
- 用户CREATE TABLE时定义的完整性条件分类
- 列值非空(NOT NULL)
- 列值唯一(UNIQUE)
- 检查是否满足一个条件表达式(CHECK)


三大完整性的总结

完整性约束命名子句
- 命名形式
CONSTRAINT <完整性约束条件名> <完整性约束条件>
/* 约束条件包括:NOT NULL,UNIQUE,PRIMARY KEY,FOREING KEY,CHECK等 */
- 具体操作的例子


断言


触发器
- 定义触发器/删除触发器
/* 定义 */
CREATE TRIGGER <触发器名> /* 每当触发事件发生时,该触发器被激活 */
{BEFORE | AFTER } <触发事件> ON <表名> /* 指明触发器激活时间是在执行触发事件的前或后 */
REFERENCING NEW|OLD ROW AS<变量> /* REFERENCING指出引用变量 */
FOR EACH {ROW | STATEMENT} /* 定义触发类型,指明动作执行的频率 */
[WHEN <触发条件>] <触发动作体> /* 仅当触发条件为真时才执行触发动作体 */
/* 删除 */
DROP TRIGGER <触发器名> ON <表名>;
- 一些例子如下



完
大致我自己就记录了这些内容,接着网后面看吧,复试越来越近,没时间了















 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









