







python搭建 ADLINE 网络判断男女 (优化器)
小记
2022.4.18
参考张觉非的书的 ch03章,但是代码做了改动,把一些目前不需要的功能砍掉了。
训练目标
训练一个模型, 给出一个人的身高、体重和体脂率,判断男女。 使用梯度下降优化器和Adam优化器
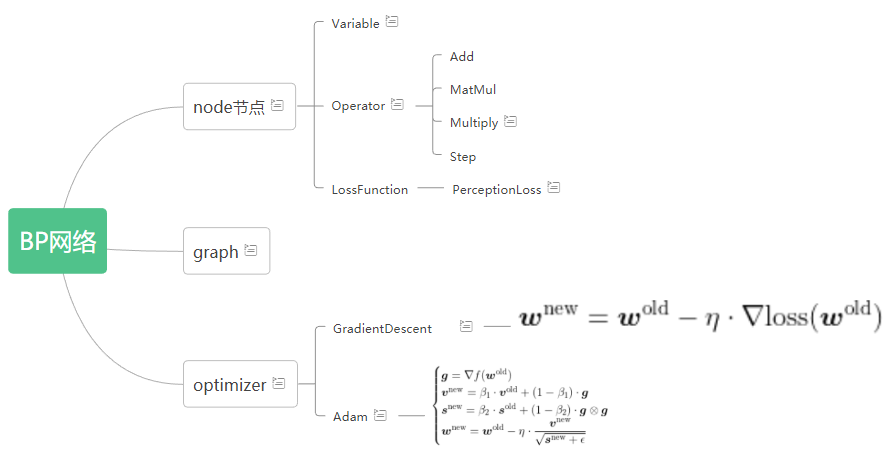
知识
把前向传播、反向传播、权值更新 封装在一起,就形成了一个优化器。
每个优化器的不同在于权值更新的方法不同,常见的优化器有梯度下降优化器,冲量优化器,AdaGrad优化器,RMSProp优化器,Adam优化器。
程序更新
- 是在 第一版代码SGD 上增改的。
- 由于使用优化器,故而对于Variable类的元素要增加可否训练属性。
- 新增optimizer.py
- 抽象优化器 Optimizer
- 传入图,目标结点(损失值loss)
- 功能:封装前向后向传播,达到batchsize的时候参数更新
- 属性
mp_gradient 一个字典,key值是结点,对应的是梯度
size_sample 计数器,当前包含的样本个数 - 通用函数:
forward_backward():
get_gradient(node):返回node结点的平均梯度 - 抽象函数:
_update() 更新每个结点的权值
-
引入优化器后,可从main函数看出区别,它只是包裹了几步
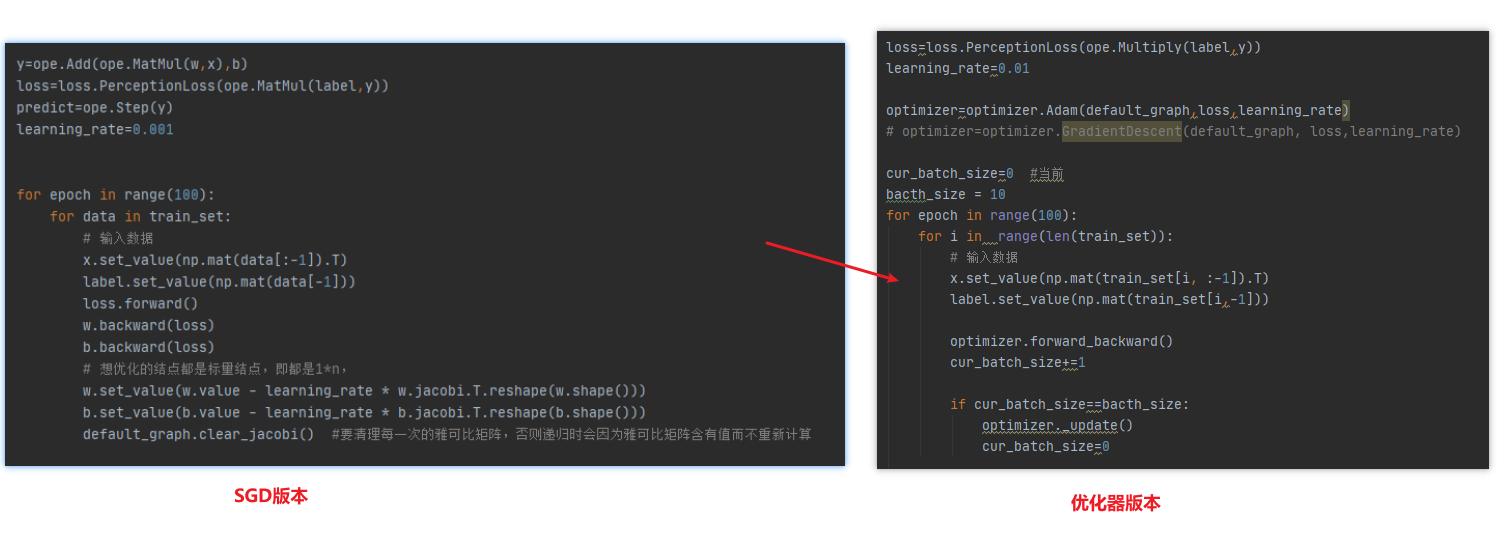
代码框架
代码
主要改在main
main.py
import numpy as np
from icecream import ic
import node,ope,loss,optimizer
from graph import default_graph
def make_test():
# 生产测试数据
m_h = np.random.normal(171, 6, 500)
f_h = np.random.normal(158, 5, 500)
m_w = np.random.normal(70, 10, 500)
f_w = np.random.normal(57, 8, 500)
m_bfrs = np.random.normal(16, 2, 500)
f_bfrs = np.random.normal(22, 2, 500)
m_labels = [1] * 500
f_labels = [-1] * 500
train_set = np.array([np.concatenate((m_h, f_h)),
np.concatenate((m_w, f_w)),
np.concatenate((m_bfrs, f_bfrs)),
np.concatenate((m_labels, f_labels))
]).T
np.random.shuffle(train_set)
return train_set
if __name__=='__main__':
train_set=make_test()
x=node.Variable(shape=(3,1))
w=node.Variable(shape=(1,3),trainable=True)
b=node.Variable(shape=(1,1),trainable=True)
label=node.Variable(shape=(1,1))
w.set_value(np.mat(np.random.normal(0,0.001,(1,3))))
b.set_value(np.mat(np.random.normal(0,0.001,(1,1))))
y=ope.Add(ope.MatMul(w,x),b)
predict=ope.Step(y)
loss=loss.PerceptionLoss(ope.Multiply(label,y))
learning_rate=0.01
optimizer=optimizer.GradientDescent(default_graph, loss,learning_rate)
cur_batch_size=0 #当前
bacth_size = 10
for epoch in range(100):
for i in range(len(train_set)):
# 输入数据
x.set_value(np.mat(train_set[i, :-1]).T)
label.set_value(np.mat(train_set[i,-1]))
optimizer.forward_backward()
cur_batch_size+=1
if cur_batch_size==bacth_size:
optimizer._update()
cur_batch_size=0
if epoch%10==0:
pred = []
for i in range(len(train_set)):
# 输入数据
x.set_value(np.mat(train_set[i, :-1]).T)
predict.forward()
pred.append(predict.value[0, 0]) # 模型的预测结果:1男,0女
pred = np.array(pred) * 2 - 1
accuracy = (train_set[:, -1] == pred).astype(np.int).sum() / len(train_set)
print("训练次数为:",epoch,"时,准确率为:",accuracy)
optimizer.py
from node import Node,Variable
from graph import Graph
from abc import ABC, abstractmethod
import graph,node
from icecream import ic
import numpy as np
class Optimizer(object):
def __init__(self,graph,target):
assert isinstance(target,Node)
assert isinstance(graph,Graph)
self.graph=graph
self.target=target
# 用于累加一个批大小的全部样本的梯度
self.mp_gradient={}
self.size_sample=0
def get_gradient(self,node):
#返回样本的平均梯度
assert node in self.mp_gradient
return self.mp_gradient[node]/self.size_sample
@abstractmethod
def _update(self):
pass
def forward_backward(self):
self.graph.clear_jacobi()
self.target.forward()
for node in self.graph.nodes:
if isinstance(node,Variable) and node.trainable:
node.backward(self.target)
# # 最终结果(标量)对节点值的雅可比是一个行向量,其转置是梯度(列向量)
# # 这里将梯度reshape成与节点值相同的形状,好对节点值进行更新。
# gradient = node.jacobi.T.reshape(node.shape())
gradient=node.jacobi
if node not in self.mp_gradient:
self.mp_gradient[node]=gradient
else :
self.mp_gradient[node]+=gradient
self.size_sample+=1
class GradientDescent(Optimizer):
def __init__(self,graph,target,learning_rate):
Optimizer.__init__(self,graph, target)
self.learning_rate=learning_rate
def _update(self):
"""
朴素梯度下降法
"""
for node in self.graph.nodes:
if isinstance(node, Variable) and node.trainable:
# 取得该节点在当前批的平均梯度
gradient = self.get_gradient(node)
# 用朴素梯度下降法更新变量节点的值
node.set_value(node.value - self.learning_rate * gradient)
self.mp_gradient.clear()
self.size_sample=0
class Adam(Optimizer):
"""
Adam优化器
"""
def __init__(self, graph, target, learning_rate=0.01, beta_1=0.9, beta_2=0.99):
Optimizer.__init__(self, graph, target)
self.learning_rate = learning_rate
# 历史梯度衰减系数
assert 0.0 < beta_1 < 1.0
self.beta_1 = beta_1
# 历史梯度各分量平方衰减系数
assert 0.0 < beta_2 < 1.0
self.beta_2 = beta_2
# 历史梯度累积
self.v = dict()
# 历史梯度各分量平方累积
self.s = dict()
def _update(self):
for node in self.graph.nodes:
if isinstance(node, Variable) and node.trainable:
# 取得该节点在当前批的平均梯度
gradient = self.get_gradient(node)
if node not in self.s:
self.v[node] = gradient
self.s[node] = np.power(gradient, 2)
else:
# 梯度累积
self.v[node] = self.beta_1 * self.v[node] + \
(1 - self.beta_1) * gradient
# 各分量平方累积
self.s[node] = self.beta_2 * self.s[node] + \
(1 - self.beta_2) * np.power(gradient, 2)
# 更新变量节点的值
node.set_value(node.value - self.learning_rate *
self.v[node] / np.sqrt(self.s[node] + 1e-10))
















 1609
1609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











