







 本文档记录了在Windows环境下,使用CUDA、Pybind11和Python进行混合编程的过程,包括环境配置、DLL与C++项目创建、Pybind11接口封装以及Python测试。通过实例展示了如何将CUDA的GPU计算功能与Python结合,实现数据处理的高效计算。
本文档记录了在Windows环境下,使用CUDA、Pybind11和Python进行混合编程的过程,包括环境配置、DLL与C++项目创建、Pybind11接口封装以及Python测试。通过实例展示了如何将CUDA的GPU计算功能与Python结合,实现数据处理的高效计算。
CUDA+ Pybin11+ Python和C++混合编程
小记
2022/5/12
毕设要求

环境:
window10
visual stdio2019
pybind11-2.9.0
Pycharm 2021.3.3
配置过程
1.在anaconda下创建一个新环境叫 envTest1
conda create -n 名字 python=3.9

后面会出现 Proceed ([y]/n)? ,就输入y就可。
我输入的是
conda env list #查看列表里的环境
conda create -n envTest1 python=3.8 #新建环境
2.在虚拟环境下 新建一个文件夹叫 CUDA+PYBIND11+C++
我在上面的步骤里新建了一个虚拟环境是envTest1, 就是在E:\software\Anaconda3\envs\envTest1这里,故而在此新建一个文件夹叫 CUDA+PYBIND11+C++,待会存放所有工程。
3.建立DLL项目 叫DLL_Project
(1)项目类型选 具有导出项的DLL动态链接库,注意观察图,如果找不到的话,可以看看那个项目类型是不是不是所有项目类型;
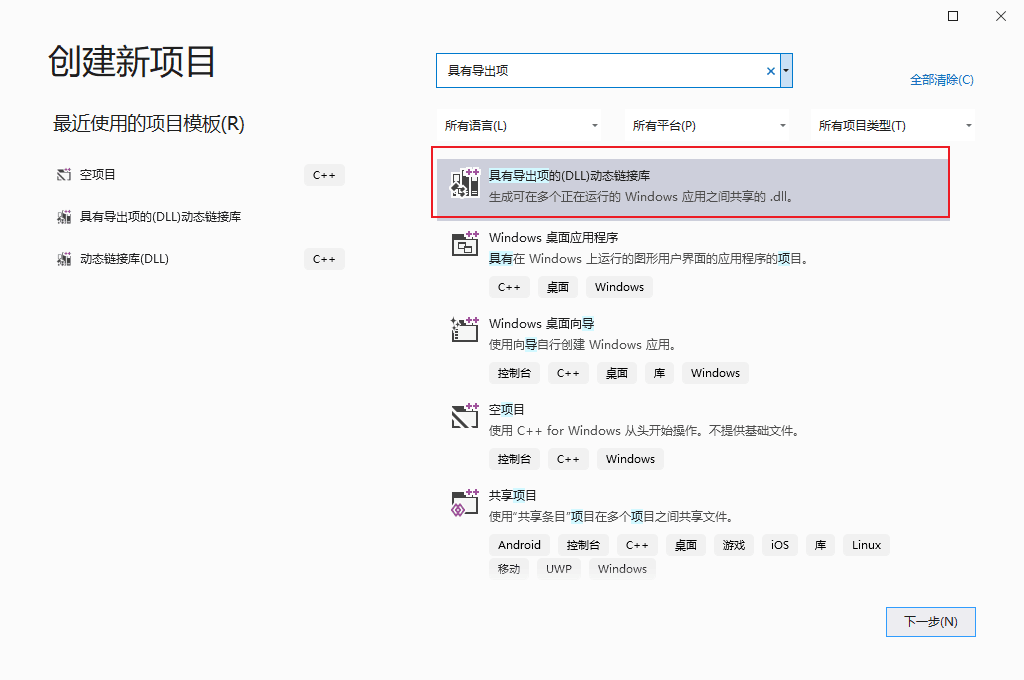
(2)项目名称叫DLL_Project
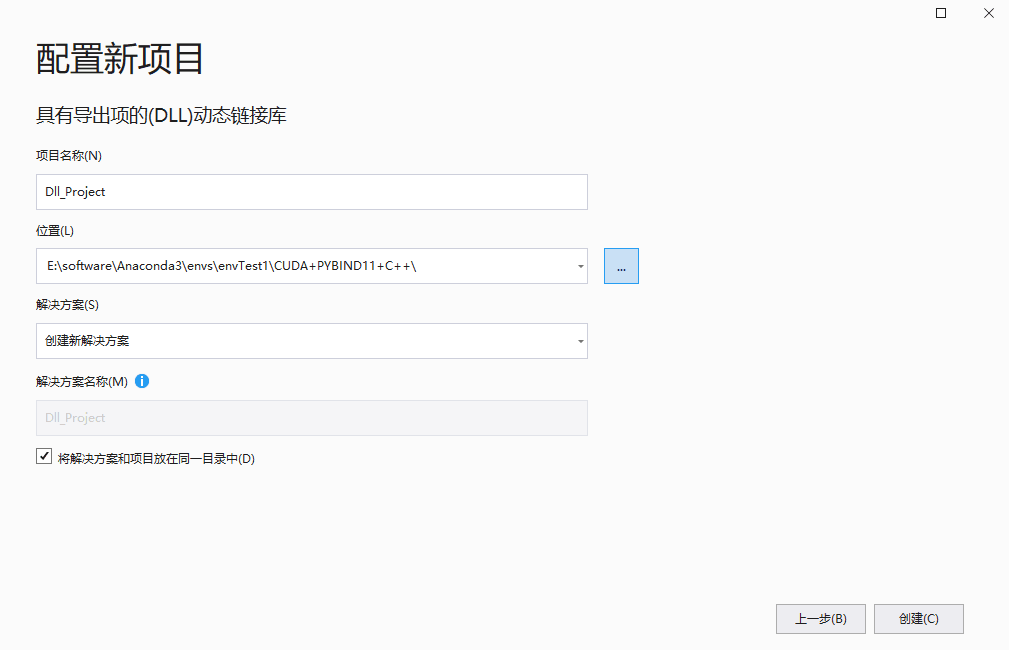
(3)把这个地方勾上

(4)新建一个cu文件在源文件下,以及cuh文件在头文件下

(5)为了后续方便,我把生成的文件都放在了一个项目下面新创的文件夹out里了。

4.编写cuda代码
在cu文件里写如下代码,注意头文件包括
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "stdio.h"
#include "File.cuh" //注意包括这个头文件
//CUDA核函数
__global__ void addKernel(double* c, const double* a, const double* b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
// 向量相加
void vectorAdd(double c[], double a[], double b[],int size)
{
double* dev_a = 0;
double* dev_b = 0;
double* dev_c = 0;
// 在GPU中为变量dev_a、dev_b、dev_c分配内存空间.
cudaMalloc((void**)&dev_c, size * sizeof(double));
cudaMalloc((void**)&dev_a, size * sizeof(double));
cudaMalloc((void**)&dev_b, size * sizeof(double));
// 从主机内存复制数据到GPU内存中.
cudaMemcpy(dev_a, a, size * sizeof(double), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, size * sizeof(double), cudaMemcpyHostToDevice);
// 启动GPU内核函数
addKernel << <1, size >> > (dev_c, dev_a, dev_b);
// 采用cudaDeviceSynchronize等待GPU内核函数执行完成并且返回遇到的任何错误信息
cudaDeviceSynchronize();
// 从GPU内存中复制数据到主机内存中
cudaMemcpy(c, dev_c, size * sizeof(double), cudaMemcpyDeviceToHost);
//释放设备中变量所占内存
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return ;
}
void CUDA_Printf()
{
printf("This is CUDA Printf111\n");
}
头文件cuh里写这个,注意必须写上 __declspec(dllexport) ,不然生成的lib文件里没有该函数
#ifndef FILE_H
#define FILE_H
extern "C" __declspec(dllexport) void vectorAdd(double c[], double a[], double b[], int size);
extern "C" __declspec(dllexport) void CUDA_Printf();
#endif
注意把改成x64

然后就重新生成项目,就会看到生成了lib和dll文件。

5.新建C++项目,叫C++Test
因为如果直接建含Pybind11的项目,生成的东西是pyd,不能用窗口打印的功能来调试,看看cuda编写的dll好不好用。
(1)新建C++项目
(2)为了方便,把工作目录设置成DLL项目生成dll文件的位置(我刚刚设置了放在一个out文件夹里)的地方,这样使用Debug模式时,就可以直接找到dll文件了。

(3)
#include<cstdio>
#include <random>
#include "../Dll_Project/File.cuh" //注意这里添加头文件,用的相对路径
#pragma comment (lib, "E:/software/Anaconda3/envs/envTest1/CUDA+PYBIND11+C++/Dll_Project/out/DllProject.lib")
//添加lib库,绝对地址
using namespace std;
int main()
{
printf("test");
CUDA_Printf();
double a[] = {1, 2, 3, 4};
double b[] = { 2, 3, 4, 5 };
double c[4];
int size = 4;
vectorAdd(c, a, b, size);
for (int i = 0; i < size; ++i)
printf("%d: %lf+ %lf= %lf\n",i,a[i],b[i],c[i]);
return 0;
}
(4)运行结果如下,说明cuda代码没问题,好使!那就下一步,用pybind11把它包起来

6.创立含pybind11的项目,叫pybind11_Project
(1)新建文件夹 Pybind11_Project,与刚刚项目的文件夹并行

(2)把刚刚从官网下载的 pybind11-2.9.0 放到Pybind11_Project里,并解压,里面会是这样的pybind11-2.9.0\pybind11-2.9.0 ,把第2个pybind11-2.9.0 文件夹直接提到E:\software\Anaconda3\envs\envTest1\CUDA+PYBIND11+C++\Pybind11_Project里,并且改名为pybind11。
使得pybind打开就如下图

(3)在Pybind11_Project目录下,用记事本新建main.cpp和 CMakeLists.txt ,CMakeLists.txt里写如下内容。
cmake_minimum_required(VERSION 2.8.12) #这个是cmake编译后的工程名,可以自己定义
project(pybind11_Project)
add_subdirectory(pybind11)
pybind11_add_module(pybind11_Project main.cpp) #括号内第一个为工程名,和上面一样,后面包含我们需要的所有文件
(4)然后就使用cmake gui界面来编译CMakeLists 会生成新的项目pybind11_Project , 如果没用过,可见 win10下配置和使用pybind10, visual stdio2019+pycharm_是Mally呀!的博客-CSDN博客 里的第5步。
7.编写含pybind11_Project里的代码
在main.cpp里注意头文件和lib文件, 不用管dll文件,因为这个项目直接生成pyd文件,不能调试
#include <pybind11/pybind11.h>
#include<pybind11/numpy.h>
#include<stdio.h>
#include<cstring>
#include "../Dll_Project/File.cuh" //头文件路径
#pragma comment (lib, "E:/software/Anaconda3/envs/envTest1/CUDA+PYBIND11+C++/Dll_Project/out/DllProject.lib") //Lib文件路径
namespace py = pybind11;
int add(int i, int j) {
return i + j;
}
py::array_t<double> vectorAdd1(py::array_t<double>& arr_a, py::array_t<double>& arr_b) {
py::buffer_info bufA = arr_a.request(), bufB = arr_b.request();
//request方法活得对py::array_t<T>的绑定,包括维度、数据指针、size、shape等参数
const int w = bufA.shape[1];
py::print("result_shape w=", w);
auto result = py::array_t<double>(w);
py::buffer_info bufResult = result.request();
double* ptrA = (double*)bufA.ptr,
* ptrB = (double*)bufB.ptr,
* ptrResult = (double*)bufResult.ptr; //获得数据指针
vectorAdd(ptrResult, ptrA, ptrB, w);
for (int i = 0; i < w; ++i)
py::print("he:", i, " ", ptrA, ptrB, ptrResult[i]);
return result;
}
PYBIND11_MODULE(pybind11_Project, m) {
m.doc() = "pybind11 example plugin"; // optional module docstring
m.def("add", &add, "A function that adds two numbers");
m.def("vectorAdd1", &vectorAdd1, "A function that adds two ");
}
8.在python里测试
(1) 用pycharm新建一个python项目,把它的编译环境最好换成刚刚那个虚拟环境下的python.exe, 并且把 DLL_Project生成dll的文件位置(那个out文件夹)和pybind11_Project生成pyd的文件位置加入Interpreter Paths的分支里面(如图所示)

(2)把DLL_Project生成的dll放到当前python项目的目录下
(3)测试代码
import numpy as np
import pybind11_Project
print('hello')
a=pybind11_Project.add(3,4)
print(a)
a=np.mat([2,3,4])
b=np.mat([2,3,4])
c=pybind11_Project.vectorAdd1(a,b)
print(c)
'''
测试结果
hello
7
[4. 6. 8.]
'''
















 7684
7684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











