






Hadoop集群的搭建
1、虚拟机网络模式为NAT
2、修改主机名(立即永久生效)
hostnamectl set-hostname master
**3、修改为静态ip:
**https://blog.csdn.net/qq_43243579/article/details/106928821
4、修改主机名和IP的映射关系
终端输入:vim /etc/hosts

在末行插入对应IP地址和主机名后保存关闭

5、关闭防火墙
查看防火状态:systemctl status firewalld
暂时关闭防火墙:systemctl stop firewalld(立即生效,但是重启后又会开启)
永久关闭防火墙:systemctl disable firewalld(直接输入此命令只有在重启机器后才会生效)
重启防火墙:systemctl enable firewalld
6、设置ntp时间同步
设置服务端master时间同步:
首先选择时区:
输入 tzselect 进入选择时区界面:

得到
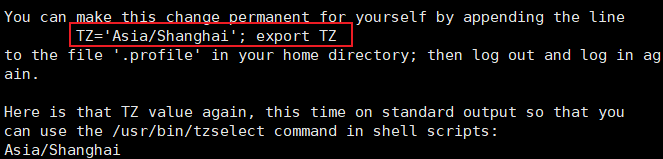
故在/etc/profile中设置TZ环境变量(保存退出后source生效)
TZ=‘Asia/Shanghai’;export TZ

安装ntp软件
语句为:yum install -y ntp (三台机器都需要)
master配置ntp文件
修改master配置文件
vi /etc/ntp.conf 文件末尾追加:
server 127.127.1.0(本地提供时间)
fudge 127.127.1.0 stratum 1 (设置层次)
注释掉server 0 ~ n (默认服务器注释掉)

master服务器重启服务:/bin/systemctl restart ntpd.service
master服务器设置ntp开机自启:/bin/systemctl enable ntpd.service
客户端与服务端同步
ntpdate master
设置定时任务(每十分钟同步一次):
crontab -e #写一个定时任务
键入i,进入编辑模式 输入内容:
查看定时任务列表:crontab -l
设置ntpd服务开机启动
systemctl enable ntpd.service
7、设置ssh免密
- 输入ssh-keygen -t rsa,一路默认回车,生成公钥

- 将该授权文件authorized_keys文件复制到slaves中的节点:
ssh-copy-id slave1
ssh-copy-id slave2

- 查看生成的公钥文件
cat .ssh/id_rsa.pub

- 查看授权列表
cat .ssh/authorized_keys
目的:将.ssh/id_rsa.pub(公钥)放到其他机器上的authorized_keys中注意:Master节点特殊,需要把自身的公钥拷贝到自身的authorized_keys中。
检查免密登录是否设置成功:ssh master/slave1看看能否进入目标服务器(第一次需要输入密码)
8、安装jdk
- 创建工作目录: mkdir -p /usr/java
- 下载软件: wget http://xxxx/jdk-8u171-linux-x64.tar.gz
- 解压: tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/java/
- 删除软件包: rm -rf /usr/java/jdk-8u171-linux-x64.tar.gz
- 环境变量: vim /etc/profile
在profile文件末尾加入
export JAVA_HOME=/usr/java/jdk1.8.0_65 #对应自己的jdk目录
export PATH=$PATH:$JAVA_HOME/bin
- 文件拷贝到其他节点
将master节点安装好jdk的文件通过scp远程拷贝到其他两台机器:
scp -r /usr/java slave1:/usr/
scp -r /usr/java slave2:/usr/
将master节点配置好的profile文件通过scp远程拷贝到其他两台机器(这步可以在hadoop环境变量添加完毕后再一并操作):
scp -r /etc/profile slave1:/etc/
scp -r /etc/profile slave2:/etc/
- 最后使用source对系统环境变量进行生效
source命令通常用于重新执行刚修改的初始化文件,使之立即生效,而不必注销并重新登录
source filename 或 .filename
- 查看jdk是否配置成功
java -version

9、安装zookeeper
-
安装准备
完成Zookeeper的解压后,在每个节点Zookeeper目录下创建数据目录Data。mkdir data
然后在Data目录下创建myid文件.(用于指定Server的编号)touch myid三台机器中myid分别指定为0,1,2(在搭建集群的时候,Zookeeper在启动的时候,会读取里面的数据与zoo.cfg中配置信息进行比较进而判断是哪个Server)
-
修改配置文件
将conf目录下的zoo_sample.cfg修改为zoo.cfg.(三个都修改)mv zoo_sample.cfg zoo.cfg
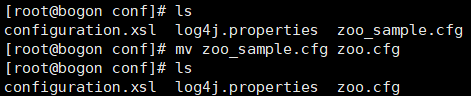
修改zoo.cfg文件
配置通式:serevr.A=B:C:D.解释如下:
A:表示这是第几号机器.
B:表示这台服务器的IP地址.
C:表示这台机器与集群Leader服务器交换信息的端口.常用2888端口.
D:如果集群中的Leader服务器挂了,选出一个新的Leader时,这个端口用来和其他服务器进行通信的端口.常用3888端口.因为是分布式集群搭建,所以可以配置一样的端口,如果是伪集群,在一台机器上搭建时,B就配置为127.0.0.1或localhost。C和D配置均为不同的端口.分布式集群中的每个节点都分布在不同的机器上,每个机器都有用的IP地址,端口也不会被其他节点所占用。vim zoo.cfg.(三个节点配置一样的).
修改文件中dataDir路径为上文创建data文件的路径
dataDir=/usr/local/zookeeper-3.4.12/data
在文件中追加
server.0=192.168.248.127:2888:3888
server.1=192.168.248.128:2888:3888
server.2=192.168.248.129:2888:3888

-
Zookeeper集群启动.
三台机器分别采用后台启动方式启动。在相应的bin目录下启动,在启动的过程中也完成了Leader的选举。
分别在bin目录下使用sh zkServer.sh start启动Zookeeper集群,
分别在启动目录下使用sh zkServer.sh status查看Zookeeper集群状态。

参考原文链接:
https://blog.csdn.net/HcJsJqJSSM/article/details/85337209
10、安装并配置Hadoop
- 创建工作目录: mkdir -p /usr/hadoop
- 下载软件: wget http://xxxx/hadoop
- 解压: tar -zxvf hadoop-2.7.1_64bit.tar.gz -C /usr/hadoop/
- 删除软件包: rm -rf /usr/hadoop/hadoop-2.7.1_64bit.tar.gz
- 配置相关文件信息
相关配置文件介绍:
hadoop-env.sh 用来定义Hadoop运行环境相关的配置信息;
core-site.xml 定义系统级别的参数,包括HDFS URL、Hadoop临时目录等;
hdfs-site.xml 定义名称节点、数据节点的存放位置、文本副本的个数、文件读取权限等;
mapred-site.xml MapReduce参数
yarn-site.xml集群资源管理系统参数配置
- hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_65 #找到JAVA_HOME导入自己的jdk目录
- core-site.xml(集群全局参数)
<property>
<name>fs.defaultFS</name> <!--配置NN节点地址与端口号-->
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name> <!--hadoop临时目录用来存放NN临时文件(tmp目录需要自己创建)-->
<value>/usr/hadoop/hadoop-2.7.3/data/tmp</value>
</property>
<property> <!--SNN检查NN日志时间间隔(单位为秒)-->
<name>fs.checkpoint.period</name> <!--设置两次相邻checkpoint之间的时间间隔,默认是1小时-->
<value>3600</value>
</property>
<property>
<name>fs.trash.interval</name> <!--以分钟为单位的垃圾回收时间,垃圾站中数据超过此时间,会被删除。如果是0,垃圾回收机制关闭。-->
<value>10080</value>
</property>
- hdfs-site.xml
<property>
<name>dfs.replication</name> <!--指定hdfs保存数据的副本数量-->
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name> <!--指定hdfs中NN的本地存储位置(name目录需要自己创建)-->
<value>/usr/hadoop/hadoop-2.7.3/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name> <!--指定hdfs中DN的本地存储位置(data目录需要自己创建)-->
<value>/usr/hadoop/hadoop-2.7.3/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name> <!--定义namenode的HTTP服务器地址和端口-->
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name> <!--定义HDFS对应的HTTP服务器地址和端口-->
<value>slave1:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name> <!--开启webhdfs,允许文件的访问修改等操作-->
<value>true</value>
</property>
- mapred-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_65 #找到JAVA_HOME导入自己的jdk目录
- mapred-site.xml
默认情况下只有mapred.xml.template文件,
复制并重命名cp mapred-site.xml.template mapred-site.xml
随后编辑mapred-site.xml文件
<property>
<name>mapreduce.framework.name</name> <!--取值为local、classic、yarn其中之一,选择yarn,使用yarn集群实现资源分配,默认是local-->
<value>yarn</value>
</property>
- yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_65 #找到JAVA_HOME导入自己的jdk目录
- yarn-site.xml
<property><!--设置运行yarn的机器-->
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property> <!--RM提供客户端访问的地址及端口-->
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property><!--RM提供给ApplicationMaster的访问地址,AM通过该地址向RM申请资源、释放资源等-->
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property><!--RM对web服务提供地址,用户通过该地址可以在浏览器上查看集群各类信息-->
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property><!--RM提供NodeManager地址,通过该地址向RM心跳、领取任务等-->
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property><!--RM提供的管理员访问地址,向RM发送管理命令等-->
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property><!--用户自定义服务,需配置成mapreduce_shuffle,才可运行MapReduce程序-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
- slaves
在slaves文件中将原有名称改成想要部署datanode的机子名称
vim slaves
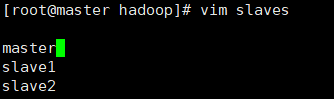
- 将hadoop添加到环境变量
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/sbin

7. 全部配置信息配置完毕后:
将master节点配置好的hadoop文件通过scp远程拷贝到其他两台机器:
scp -r /usr/hadoop slave1:/usr/
scp -r /usr/hadoop slave2:/usr/
将master节点配置好的profile文件通过scp远程拷贝到其他两台机器:
scp -r /etc/profile slave1:/etc/
scp -r /etc/profile slave2:/etc/
11、格式化并启动Hadoop
关于hdfs的格式化:
- 首次启动需要进行格式化,格式化之后,集群启动成功,后续再也不要进行格式化
- 格式化本质是进行文件系统的初始化操作,创建一些自己所需要的文件
- 格式化的操作要在hdfs集群的主角色(namenode)所在机器上操作
hadoop namenode -format //格式化
格式化成功:
cd到current目录下会看到相关文件信息: 在配置了etc/hadoop/slaves何免密登录的情况下可使用程序脚本启动所有Hadoop两个集群的相关进程。
在配置了etc/hadoop/slaves何免密登录的情况下可使用程序脚本启动所有Hadoop两个集群的相关进程。
cd到sbin目录下可查看到相关可执行文件:
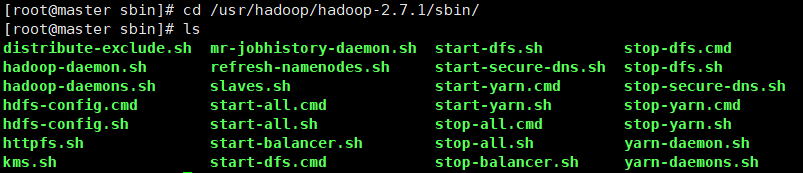
启动集群
在master的sbin目录上执行:
start-dfs.sh
结果如下
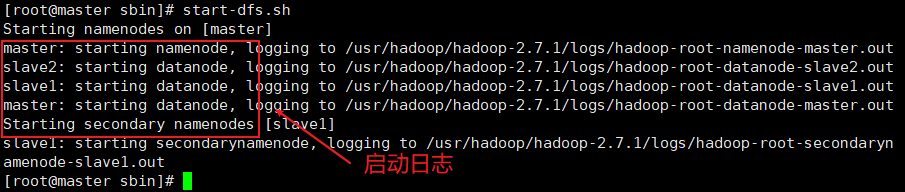
随后执行:
start-yarn.sh
结果如下:

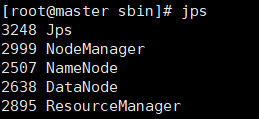
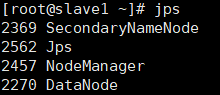
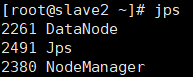
利用 jps 查看个节点的部署结果:
master
slave1
slave2
关闭集群
在master节点输入:
stop-dfs.sh
stop-yarn.sh
或
stop-all.sh
集群成功关闭

至此Hadoop集群搭建完毕!
















 3588
3588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











