







这篇论文同样是来自陆老师组的,发表在IEEE INTERNET OF THINGS JOURNAL上的一篇关于联邦学习、同态加密的文章。
目录
论文背景
在过去的几年里,移动通信和物联网的爆炸性发展带来了一种新的传感方法范式,称为 移动群智感知 (MCS)。从本质上讲,移动用户的人群,即工人,被MCS平台招募,将他们的传感数据外包给某些任务,如环境监测[、交通密度评估、城市规划、位置导航[和医疗保健供应。然而,工人在执行传感任务时,不可避免地要向平台分享他们的传感信息(如日常轨迹、实时位置和周围环境)。信息泄露可能导致严重的隐私问题。例如,攻击者可以通过分析工人的传感数据来推断其日常行为。因此,保护工人的敏感信息不被泄露是MCS应用的主要挑战之一。
在这里先介绍下群智感知(Crowd Sensing)
群智感知(Crowd Sensing)
群智感知(Crowd Sensing)一开始来源于众包的概念,科技公司将项目工作以自由意愿的形式分配给非特定的社会大众,一种分布式协作。而群智感知(Crowd Sensing) 指大规模的普通用户通过其自身携带的智能移动设备来采集感知数据并上传到服务器,服务提供商对感知数据进行记录处理,最终完成感知任务并利用收集的数据给用户提供日常所需服务的过程。近些年随着各种移动设备和可穿戴设备的普及利用这些传感设备收集的数据可以分析提取许多有用信息。移动的可穿戴的传感器可以有效的收集数据而没有维护成本高覆盖范围有限等问题。如今群智感知在环境污染监测、环境噪声地图、城市交通路况、社交网络与医疗保健等方面都已经得到了应用,在可预见的未来它将会应用到更多的业务场景中。
移动群智感知系统一般会由多个移动用户,任务发起者,云端感知平台组成,任务发起者向云端提交任务需求,感知平台向用户发布任务,移动用户携带智能设备执行任务并上传数据获得相应报酬,感知平台处理数据提供计算服务。整个过程主要设计如下几个研究方向:收集、用户招募、任务分配、隐私保护、数据质量和激励机制
F-MCS
到目前为止,已经有大量的、不断增长的文献被研究用来解决MCS中的隐私挑战。在所有的研究中,联合学习(FL)可以被认为是一个潜在的和实用的解决方案。在联合学习中,平台反复选择随机工人来下载一个可训练的模型。
FL的分布式性质使工作者能够优化共享模型,同时将所有训练数据保存在本地,从而确保他们的隐私。FL可以大致分为跨主机FL和跨设备FL。在跨主机FL中,工作者是具有丰富计算资源的职能机构(例如,金融机构)。
训练好的模型被专门发布给这些组织,但不包括FL聚合平台。相反,在跨设备FL中,工作者是计算能力有限的异质移动用户。FL平台最终将获得训练好的模型。
在这篇文章中,通过将跨设备FL引入MCS,我们提出了一个新的传感场景,称为联合MCS(F-MCS)。F-MCS允许工人建立一个强大而安全的机器学习模型,而不需要分享他们的感应数据。
因此,F-MCS可以解决传统MCS系统中工人信息泄露的关键问题,并有望成为移动传感服务的一个新热点。
尽管如此,如果我们简单地将FL技术与MCS服务相结合,仍然存在两个主要问题。
(1) 在F-MCS中选择稳定的工作者是一个挑战。这里的工作者拥有的搜集、上传数据的可携带式设备工作充满了不稳定性。这些设备硬件条件、网络连接(3G、4G、5G、Wi-Fi和信号强度),电源状态(续航时间),因为分布式训练在顺利进行下一轮训练之前就需要所有的workers的数据被正确上传,意思是受设备影响导致workers之间出现时间上的不协同,会影响后续的聚合步骤。
(2)跨设备的F-MCS平台缺乏实用的隐私保护解决方案。F-MCS是一个跨设备的FL系统,最终的模型将被发布到F-MCS平台,用于某些实时服务。因此,现有的方法不能应用于F-MCS。现在急需为F-MCS的应用设计实用的、保护隐私的解决方案
本文的主要贡献
在这篇文章中,为了解决上述挑战,我们提出了一种新型的、安全的F-MCS应用的数据聚合方案,称为FedSky。通过扩展经典的FedAvg算法,FedSky的特点是采用群体天际线(G-skyline)来选择合格的workers和同态加密来安全地聚合数据。具体来说,本文的主要贡献有以下三点:
(1)我们在FedSky中为F-MCS提出了一种新颖而有效的工人选择机制。具体来说,在每一轮通信中,我们不是随机选择一组工人,而是根据工人的本地数据大小和他们的移动设备的计算能力来选择一个工人的天际线组。这样一来,与传统的FedAvg算法相比,我们的方法可以大大减少工人的计算时间和平台的等待时间,因此,大大地提高了FL过程的效率。
(2)我们为F-MCS平台提出了一种基于HE(t同态加密)技术的新型隐私保护数据聚合方案。该方案是为跨设备的FL设置而设计的,这样,最终的全局模型可以被F-MCS平台访问。此外,整个训练过程不需要所选工人之间的互动。除了左邻的ID和右邻的ID,每个被选中的工人对其他工人的信息一无所知。
(3)我们建立了一个定制的模拟器来进行性能评估。
广泛的实验结果验证了所提方案的有效性和效率。特别是,通过引入一个新的工人选择机制和一个保护隐私的数据聚合协议,我们可以在不影响其准确性的情况下大大提高FL过程的效率。
模型与设计目标
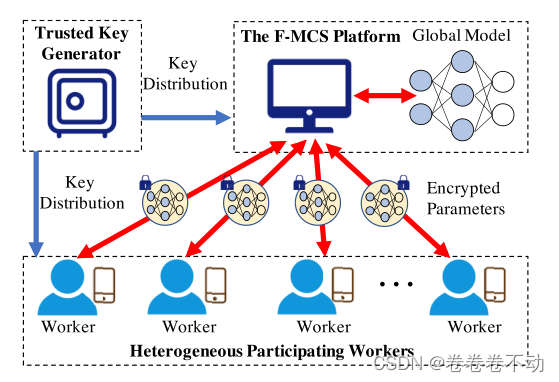
系统模型
场景考虑一个比较典型的F-MCS场景,包括三个实体:一个可信的密钥生成生成器
T
K
G
\mathcal{TKG}
TKG,一个
F
−
M
C
S
F-MCS
F−MCS平台和一组异质工人
W
=
{
w
1
,
w
2
,
w
3
.
.
.
.
}
\mathcal{W}=\{w_1,w_2,w_3....\}
W={w1,w2,w3....}.
(1)
T
K
G
\mathcal{TKG}
TKG:一个受信任的权威机构,它生成并向相应的实体分发适当的密钥,从而使某项F-MCS任务能够合作完成。
(2)
F
−
M
C
S
F-MCS
F−MCS平台
P
P
P:
P
P
P是提供F-MCS服务的可信平台,负责执行F-MCS任务,包括注册工人、初始化任务模型、选择工人和训练模型。更具体地说,在注册时,
P
P
P给每个注册的工人
W
i
W_i
Wi分配一个唯一的标识
I
D
w
i
ID_{wi}
IDwi。然后将工人的识别码广播给
T
K
G
\mathcal{TKG}
TKG。在训练的过程中,
P
P
P首先会初始化全局模型,然后从
W
=
{
w
1
,
w
2
,
w
3
.
.
.
.
}
\mathcal{W}=\{w_1,w_2,w_3....\}
W={w1,w2,w3....}选择一部分合格的员工(具体怎么选参考后文),
P
P
P将模型分发给选定的工人,并在每轮训练中通过汇总工人提供的模型参数来训练模型。为了实现最终的全局模型,需要P和选定的工人之间进行多轮互动。
(3) 参与的工作者:
W
=
{
w
1
,
w
2
,
w
3
.
.
.
.
}
\mathcal{W}=\{w_1,w_2,w_3....\}
W={w1,w2,w3....},
W
\mathcal{W}
W是希望进行某项F-MCS任务的参与工作者。如果
W
\mathcal{W}
W中的工人被P选中,首先,他/她需要用他/她的移动设备收集原始感应数据。在收到全局模型后,每个被选中的工人需要通过用他/她的本地数据训练模型来更新模型参数,加密模型参数,并与P交换密文。为了在每轮训练中被选中,工作者需要定期向P发送他们当前的训练能力和计算状态,例如,本地数据集的大小,他们的移动设备的当前CPU份额/电池/内存。
安全模型
首先,我们认为
P
\mathcal{P}
P和
T
K
G
\mathcal{TKG}
TKG是完全可信的。值得注意的是,一些恶意软件已经被对手
A
\mathcal{A}
A安装在
P
\mathcal{P}
P中而没有被发现。因此,
A
\mathcal{A}
A可以监视
P
\mathcal{P}
P的数据库,并窃听
P
\mathcal{P}
P和
W
\mathcal{W}
W之间的通信信息。基本上,
A
\mathcal{A}
A对每个工人上传至平台的模型更新感兴趣。通过这些更新,
A
\mathcal{A}
A可以推断出工人的实时空间-时间信息。
工人
W
\mathcal{W}
W是诚实而好奇的。
因此,所有工人都严格遵守设计的更新、加密和上传模型参数的协议,但可能对其他工人的数据资源感兴趣。此外,我们假设
W
\mathcal{W}
W的工人之间没有串通,工人也不能与
P
\mathcal{P}
P串通。外部攻击者可能利用F-MCS平台的其他漏洞。由于这项工作的重点是隐私保护,这些攻击超出了本文的范围,将在我们未来的工作中讨论。
设计目标
(1)效率:提出的FedSky方案在训练模型和在每轮通信中上传加密的模型参数方面应该是高效的。因此,与传统的FedAvg算法相比,在我们的方案中,P的等待时间应该缩短,整体的FL训练效率应该得到提高。
(2)隐私保护:我们计划设计一个保护隐私的F-MCS框架,它可以防止工人敏感信息的保密性被泄露。更具体地说,对于∀
w
i
w_i
wi,
D
i
\mathcal{D}_i
Di表示
w
i
w_i
wi的本地数据,
x
i
x_i
xi表示
w
i
w_i
wi在每轮训练后更新的模型参数,
D
i
\mathcal{D}_i
Di和xi都应该对其他工人保密。此外,即使
A
\mathcal{A}
A窃听了
P
\mathcal{P}
P的数据库并窃取了
w
\mathcal{w}
w和
P
\mathcal{P}
P之间的通信数据,它仍然无法识别每个工作者的上传模型参数
x
i
x_i
xi。
PRELIMINARIES
A. FedAvg Algorithm
联邦平均算法用于FL中深度学习和机器学习模型。在传统FL中有两种传统的实体:
1)数据聚合器
2)
K
K
K个参与的工作者
{
w
1
,
w
2
,
.
.
.
,
w
k
}
\{w_{1},w_{2},...,w_{k}\}
{w1,w2,...,wk}
令
N
i
N_{i}
Ni表示工作者
W
i
W_{i}
Wi拥有的数据集的数量,算法步骤如下:
1、FedAvg算法中每次在
t
t
t轮开始时都会从
K
K
K个工人中随机选择,
k
k
k个参与者,将在
t
t
t轮的的模型
x
t
x^{t}
xt广播给每个参与者。
2、在接受到当前模型时候,工作者
w
i
w_{i}
wi 都会在本地数据集上计算平均梯度。这个记为
g
i
g_{i}
gi
3、给定一个固定的学习率
η
\eta
η,
w
i
w_{i}
wi计算:
x
i
←
x
t
−
η
⋅
g
i
x_{i}\leftarrow x^{t}-\eta·g_{i}
xi←xt−η⋅gi
4、上传
x
i
x_{i}
xi到数据聚合器
5、最后数据聚合器根据下列算式更新全局模型:
x
t
+
1
←
∑
i
=
1
k
(
N
i
/
N
)
x
i
其
中
N
=
N
1
+
N
2
+
.
.
.
.
N
k
x^{t+1}\leftarrow\sum_{i= 1}^{k}(N_{i}/N)x_{i} 其中 N=N_{1}+N_{2}+....N_{k}
xt+1←∑i=1k(Ni/N)xi其中N=N1+N2+....Nk
具体算法细节如下图所示

B. Different Variants of Skyline Queries
不同的天际线查询 ,这使用MCS的工作者来举例说明几种不同的skyline:
skyline , G-skyline , and Constrained skyline
(C-skyline) (约束天际线) 然后提出一种新颖的skyline变体——CG-skyline :这个可以检索对数据具有特定尺寸限制的天际线组。
定义一:
(
s
k
y
l
i
n
e
)
(skyline)
(skyline) :
K
K
K 个参与的工作者:
W
=
{
w
1
,
w
2
,
.
.
.
,
w
k
}
\mathcal{W}=\{w_{1},w_{2},...,w_{k}\}
W={w1,w2,...,wk} 每个工作者都可以被表示为d维的数据点,
w
i
=
(
w
i
[
1
]
,
w
i
[
2
]
.
.
.
w
i
[
d
]
,
i
∈
[
1
,
K
]
)
wi=(w_{i}[1],w_{i}[2]...w_{i}[d] ,i ∈[1,K])
wi=(wi[1],wi[2]...wi[d],i∈[1,K]), 假设都是优先选择每个维度的最大值。 定义一种主导(dominated)关系(
w
a
≺
w
b
w_a \prec w_b
wa≺wb)如下: 对于
W
\mathcal{W}
W 中的俩个不同的工作者
w
a
w_a
wa,
w
b
w_b
wb(a≠b) 对于所有的维度
j
∈
[
1
,
d
]
j∈[1,d]
j∈[1,d] 都有
w
a
[
j
]
≥
w
b
[
j
]
w_{a[j]}≥w_{b[j]}
wa[j]≥wb[j] 且至少存在一个维度使得
w
a
[
j
]
>
w
b
[
j
]
w_{a[j]}>w_{b[j]}
wa[j]>wb[j],定义相等的关系,对于所有的维度都有,
w
a
[
j
]
=
w
b
[
j
]
w_{a[j]}=w_{b[j]}
wa[j]=wb[j]
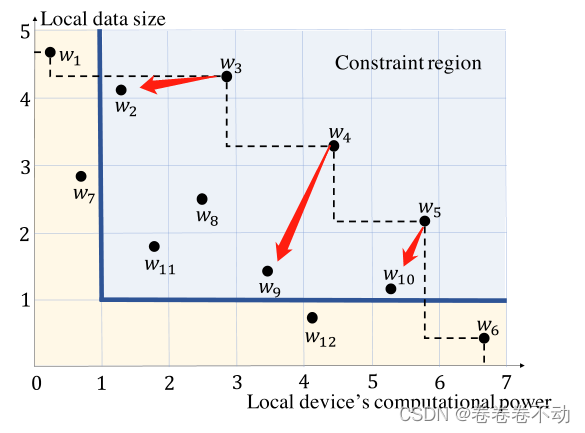
举例如下:

可以这样理解靠近坐标右上角的点是最好的点。
w
1
,
w
3
,
w
4
,
w
5
w_1,w_3,w_4,w_5
w1,w3,w4,w5和
w
6
w_6
w6是skyline的工作者。
定义二
k
−
P
o
i
n
t
G
−
S
k
y
l
i
n
e
k-Point\ G-Skyline
k−Point G−Skyline: 给定一系列工作者
W
\mathcal{W}
W
有两组数量为k的工人组
G
=
{
w
1
,
w
2
,
.
.
.
,
w
k
}
G=\{w_{1},w_{2},...,w_{k}\}
G={w1,w2,...,wk},然后
G
′
=
{
w
1
′
,
w
2
′
,
.
.
.
,
w
k
′
}
G'=\{w_{1}',w_{2}',...,w_{k}'\}
G′={w1′,w2′,...,wk′} ,k≤
K
K
K 且
G
和
G
‘
都
是
∈
W
G和G‘都是∈\mathcal{W}
G和G‘都是∈W
,定义一种 g-domaintes (
w
a
≺
g
w
b
w_{a} \prec_g w_{b}
wa≺gwb) : 在两个工人组中找到k个点的排列,
G
=
{
w
u
1
,
w
22
,
.
.
.
,
w
u
k
}
G=\{w_{u1},w_{22},...,w_{uk}\}
G={wu1,w22,...,wuk},
G
′
=
{
w
v
1
′
,
w
v
2
′
,
.
.
.
,
w
v
k
′
}
G'=\{w_{v1}',w_{v2}',...,w_{vk}'\}
G′={wv1′,wv2′,...,wvk′} 满足 所有的维度都有
w
u
i
⪯
w
v
i
′
w_{ui} \preceq w_{vi}'
wui⪯wvi′ 至少存在一个维度使得
w
u
i
≺
w
v
i
′
w_{ui} \prec w_{vi}'
wui≺wvi′ 这样就找出了k-point G-skyline 的组 这里的工作者不能由其他相同大小的组主导,举例如下;
注意:这里定义的符号
≺
\prec
≺ 是一种主导关系 ,具体到数值上其实是大于的关系,图像上显示实在右上角位置
定义三:(C-skyline): 给定一系列d-维度的工作者
W
\mathcal{W}
W
令
C
=
{
C
o
n
1
,
C
o
n
2
,
.
.
.
C
o
n
d
,
}
\mathcal{C}=\{Con_1,Con_2,...Con_d,\}
C={Con1,Con2,...Cond,} 表示d维度的一些限制。
C
o
n
i
Con_i
Coni 表示的是一个属于一个维度的限制范围
[
m
i
n
i
,
m
a
x
i
]
[min_i,max_i]
[mini,maxi],或者是空集
∅
\emptyset
∅ ,这样所有的限制
C
\mathcal{C}
C会在d维度的空闲内形成一个约束空间 可以理解是普通的skyline上加上约束之后的点
定义四 (k-Point CG-Skyline,本文提出的新的skyline) 给定一系列d-维的工作者
W
\mathcal{W}
W,和一系列限制
C
\mathcal{C}
C , k-point CG-skyline 的点是由约束空间中的所有的拥有k个工作者且不会被别的组 g-dominated的所有组。
举个例子: 还是在上图中 令
C
=
{
C
o
n
1
,
C
o
n
2
}
\mathcal{C}=\{Con1,Con2\}
C={Con1,Con2} 其中
C
o
n
1
=
[
1
,
5
]
,
C
o
n
2
=
[
1
,
7
]
Con_1=[1,5],Con_2=[1,7]
Con1=[1,5],Con2=[1,7] 那么图上的蓝色区域就是约束空间,那么对于定义三种C-skyline就是
{
w
3
,
w
4
,
w
5
}
\{w_3,w_4,w_5\}
{w3,w4,w5} 其中组
G
=
{
w
1
,
w
4
,
w
5
}
G=\{w_1,w_4,w_5\}
G={w1,w4,w5} 是一个 3-point G-skyline 而不是一个 3-point CG-skyline 。
C.Bilinear Pairing
这部分内容就是双线性配对,就不展开讲述 可以参考 网络上的一些博文:
D.Paillier Cryptosystem
Paillier 同态加密也不做详述

要注意在Paillier密码系统中,两个密文的乘积可以解密为它们对应的明文之和,即:
D
(
s
k
,
E
(
p
k
,
m
1
)
⋅
E
(
p
k
,
m
2
)
m
o
d
n
2
)
=
m
1
+
m
2
m
o
d
n
D(sk,E(pk,m_1)·E(pk,m2) mod \ n^{2})=m_1+m_2 \ mod \ n
D(sk,E(pk,m1)⋅E(pk,m2)mod n2)=m1+m2 mod n
提出的方案
这一节会提出一个新颖的针对F-MCS -联合移动群智感知的数据聚合方案,称作FedSky 主要由三部分组成:
密钥分发(KeyDist)
工作者选择(WorkSel)
数据聚合(DataAgg)
A.KeyDist P h a s e Phase Phase
首先
T
K
G
\mathcal{TKG}
TKG运行
K
e
y
G
e
n
(
k
)
KeyGen(k)
KeyGen(k) 生成参数
(
p
,
q
,
n
,
λ
,
μ
)
(p,q,n,\lambda,\mu)
(p,q,n,λ,μ),生成公钥
p
k
p
=
(
n
,
g
)
pk_p=(n,g)
pkp=(n,g) 和私钥
s
k
p
=
(
λ
,
μ
)
sk_p=(\lambda,\mu)
skp=(λ,μ) 然后
T
K
G
\mathcal{TKG}
TKG 会选择统一的加密哈希函数
H
1
H_1
H1,
H
1
:
{
0
,
1
}
∗
→
Z
n
2
H_1:\{0,1\}^{*}\rightarrow\mathbb{Z}_{n^2}
H1:{0,1}∗→Zn2 和一个双线性隐射
e
:
G
×
G
→
G
T
e:\mathbb{G} ×\mathbb{G}\rightarrow\mathbb{G}_{T}
e:G×G→GT。然后
T
K
G
\mathcal{TKG}
TKG 会将
(
p
k
p
,
H
1
,
e
:
G
×
G
)
(pk_p,H_1,e:\mathbb{G} ×\mathbb{G})
(pkp,H1,e:G×G) 广播给
P
P
P和系统中的所有工作者,然后安全的将
s
k
p
sk_p
skp 发送给
P
P
P(F-MCS 平台)
接下来
T
K
G
\mathcal{TKG}
TKG会选择另一个加密的哈希函数
H
2
H_2
H2,
H
2
:
{
0
,
1
}
∗
→
Z
n
H_2:\{0,1\}^{*}\rightarrow\mathbb{Z}_{n}
H2:{0,1}∗→Zn
T
K
G
\mathcal{TKG}
TKG选择一个随机数
S
∈
Z
n
∗
S∈\mathbb{Z}^{*}_n
S∈Zn∗,作为一个钥匙,同时对
W
W
W中的每一个工作者
w
i
w_i
wi都给予一个标识
I
D
w
i
ID_{w_i}
IDwi 其中
I
D
w
i
=
H
0
(
w
i
)
H
0
:
{
0
,
1
}
∗
→
G
ID_{w_i}=H_0(w_i) \ H_0:\{0,1\}^{*}\rightarrow\mathbb{G}
IDwi=H0(wi) H0:{0,1}∗→G ,
T
K
G
\mathcal{TKG}
TKG 会计算
I
D
w
i
S
ID_{w_i}^S
IDwiS 并将这个安全的发送给
w
i
w_i
wi ,将哈希函数
H
2
H_2
H2发送给所有工作者
B. WorkSel P h a s e Phase Phase
在本文的模型中。所有的工作者
w
i
wi
wi都具备两种属性
(1)本地的数据集大小
N
i
N_i
Ni
(2)移动设备的计算能力大小
P
i
P_i
Pi ,
P
i
P_i
Pi表示在F-MCS任务中每分钟可以处理多少任务,
w
i
wi
wi需要定期的将
N
i
N_i
Ni和
P
i
P_i
Pi 发送给平台
P
P
P 在选择工作者之前,平台
P
P
P 会根据F-MCS 任务的要求定义一些二维的限制
C
=
{
C
o
n
1
,
C
o
n
2
}
\mathcal{C}=\{Con_1,Con_2\}
C={Con1,Con2} 对于更高的要求 限制应该也是更加严格一点。
C
o
n
1
=
[
m
i
n
1
,
m
a
x
1
]
Con_1=[min_1,max_1]
Con1=[min1,max1],
C
o
n
2
=
[
m
i
n
2
,
m
a
x
2
]
Con_2=[min_2,max_2]
Con2=[min2,max2], 我们认为如果
m
i
n
1
>
m
i
n
2
min_1>min_2
min1>min2且
m
a
x
1
>
m
a
x
2
max_1>max_2
max1>max2那么
C
o
n
1
Con_1
Con1 是比
C
o
n
2
Con_2
Con2更加严格的。 接着平台
P
P
P 会选择一系列符合这些限制的工作者
W
′
\mathcal{W}'
W′ ,在每轮训练前
P
P
P都会从
W
′
\mathcal{W}'
W′种 由
N
i
N_i
Ni和
P
i
P_i
Pi 两个属性的CG-skyline 选择最佳的k个工作者,具体的方法如下:
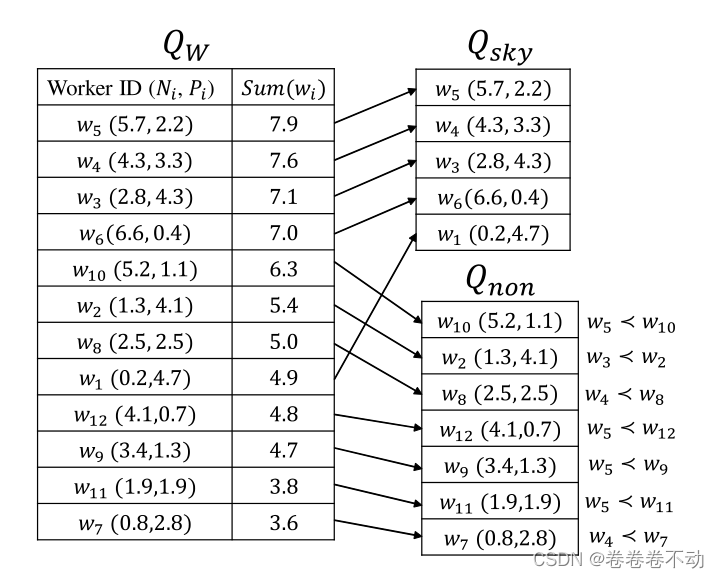
首先对于每个工作者
w
i
wi
wi,
P
P
P 会计算
S
u
m
(
w
i
)
=
N
i
+
P
i
Sum(w_i)=N_i+P_i
Sum(wi)=Ni+Pi,根据这个
S
u
m
(
i
)
Sum(i)
Sum(i) 所有的工作者都会被添加进一个最大值优先队列
Q
W
Q_W
QW ,即降序排列,值越大的越先从队列种删去。这里注意
P
i
P_i
Pi和
N
i
N_i
Ni 应该在同一水平(即数值上是在相近的范围内,不会出现某个属性主导的情况) ,由上述章节的描述有以下两个定理:
Theorem 1: 如果
w
i
w_i
wi是第一个被
Q
W
Q_W
QW移除的工作者那么
w
i
w_i
wi就是一个符合skyline 的工作者
Theorem 2: 对于所有的
w
j
∈
W
′
w_j ∈\mathcal{W}'
wj∈W′ 能主导
w
j
w_j
wj的一定是比
w
j
w_j
wj先移出
Q
W
Q_W
QW的
算法执行如下:
首先
P
P
P 会初始化另一个空的最大优先队列
Q
n
o
n
Q_{non}
Qnon,和一个空的列表
Q
s
k
y
Q_{sky}
Qsky
P
P
P 会遍历
Q
W
Q_W
QW队列,根据上述的定理,第一个工作者
w
i
w_i
wi 会被直接加入
Q
s
k
y
Q_{sky}
Qsky,然后接下来的
Q
W
Q_W
QW中的第一个工作者,去跟
Q
s
k
y
Q_{sky}
Qsky中的所有工作者比较,如果都没被
Q
s
k
y
Q_{sky}
Qsky中的工作者所主导那么就加入到
Q
s
k
y
Q_{sky}
Qsky中,否则就添加入
Q
n
o
n
Q_{non}
Qnon。
P
P
P重复执行上述步骤直到
Q
s
k
y
Q_{sky}
Qsky中的数量为k或者
Q
W
Q_W
QW队列为空。最后还会进行一个判断,如果最终
Q
s
k
y
Q_{sky}
Qsky中的数量少于k个,那么会从
Q
n
o
n
Q_{non}
Qnon选出少的个数的工作者加入到
Q
s
k
y
Q_{sky}
Qsky,这一部分的理解是即使是某些工作者的计算能力或者数据集不够,还是需要保证有k个参与者。
举例如下
值得注意的是,所提出的CG-skyline技术只能选择一组G-skyline工人。
在选择工人后,MCS平台
P
P
P将全局模型的超参数(如学习速率)广播给所有被选择的工人,工人可以使用这些超参数进行下一步的模型训练和优化.
C.DataAgg P h a s e Phase Phase
W s \mathcal{W}_s Ws 是一个组中k个被挑选的工作者,例如 W s = { w 1 , w 2 , . . . , w k } \mathcal{W}_s=\{w_1,w_2,...,w_k\} Ws={w1,w2,...,wk} 在每一轮开始前 P P P 都会计算 y i = N i / ( N 1 + N 2 + … N k ) y_i=Ni/(N_1+N_2+…N_k) yi=Ni/(N1+N2+…Nk) 作为 w i w_i wi的模型参数 , y i y_i yi会保留三位小数, P P P会对 y i y_i yi 进行放大1000倍的操作,具体的DataAgg 操作如下:
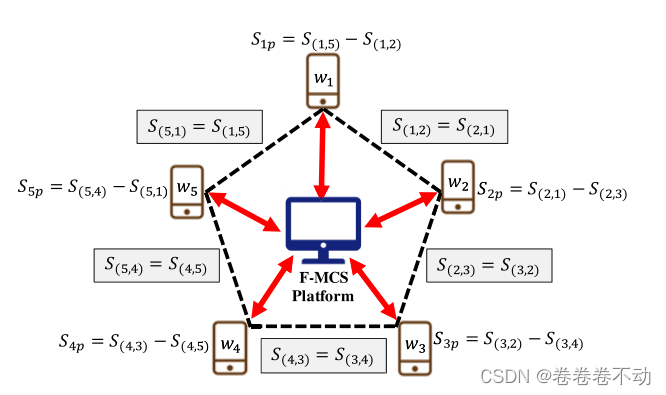
-
P
P
P 将来自
W
s
\mathcal{W}_s
Ws 中的k个工人放入一个循环中,排列如下图,注意
w
i
w_i
wi 的邻居下标,以及
w
1
w_1
w1的左边是
w
k
w_k
wk:
-
P
P
P 产生一个随机数
α
i
∈
Z
n
∗
\alpha_i ∈\mathbb{Z}^{*}_n
αi∈Zn∗
P
P
P将如下信息发送给每个工作者
w
i
w_i
wi:

这里的 i → l i\rightarrow l i→l 和 i → r i\rightarrow r i→r 表示 w i w_i wi的左邻居和右邻居, t t t当前训练的轮次,因此值都会随着每轮的变化而变化. - 接收到信息之后
w
i
w_i
wi 会根据本地数据集计算本地梯度
g
i
g_i
gi
根据固定的学习率,会计算本地的模型参数 x i ← x t − η ⋅ g i x_{i}\leftarrow x^{t}-\eta·g_{i} xi←xt−η⋅gi ,为了尽可能的保持原始信息,将 x i xi xi 保留 到小数点后八位,在每轮训练完之后 w i w_i wi都会计算 x i ˉ = 1 0 8 ⋅ x i \bar{x_i}=10^{8}·x_i xiˉ=108⋅xi - 接下来
w
i
w_i
wi会计算
C
ˉ
i
\bar{C}_i
Cˉi和三个
k
e
y
key
key , 左会话密钥
S
(
i
,
i
→
l
)
S_{(i,i\rightarrow l)}
S(i,i→l),右会话密钥
S
(
i
,
i
→
r
)
S_{(i,i\rightarrow r)}
S(i,i→r), 处理密钥
S
i
p
S_ip
Sip:
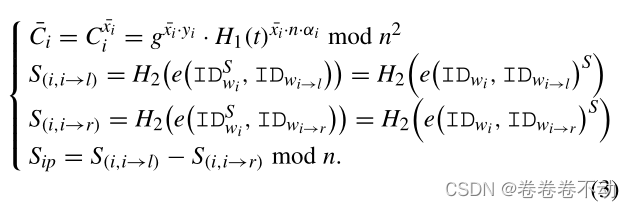
接着 w i w_i wi会计算一个 π i \pi_i πi 发送给 P P P:
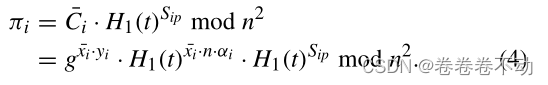
-
P
P
P首先会检查是否存在
w
i
w_i
wi 没有提交
π
i
\pi_i
πi 如果有那么
P
P
P会终止协议然后开始新的训练回合。如果所有的
w
i
w_i
wi 都提交了他们的
π
i
,
P
\pi_i,P
πi,P会计算:
θ
=
∏
i
=
1
k
π
i
\theta=\prod_{i = 1}^{k}{\pi_i}
θ=∏i=1kπi mod n²
计算如下:
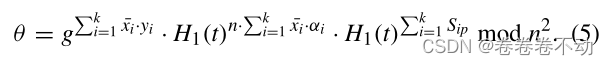
令 m ˉ = ∑ i = 1 k x ˉ i ⋅ y i \bar{m}=\sum_{i = 1}^{k}{\bar{x}_{i}·y_i} mˉ=∑i=1kxˉi⋅yi P P P 可以通过 D ( s k , c ) D(sk,c) D(sk,c) 进行过解密获得 m ˉ \bar{m} mˉ:
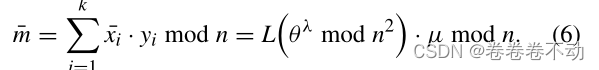
正确性验证:
考虑给定的 W i W_i Wi 对于所有 k k k个工作者,处理密钥的求和形式为 ∏ i = 1 k S i p = S 1 p + S 2 p + S 3 p + . . . S k p = S ( 1 , k ) − S ( 2 , 1 ) − S ( 2 , 3 ) + . . . + S ( k , k − 1 ) − S ( k , 1 ) \prod_{i = 1}^{k}Sip=S_{1p}+S_{2p}+S_{3p}+...S_{kp}=S_{(1,k)}-S_{(2,1)}-S_{(2,3)}+...+S_{(k,k-1)}-S_{(k,1)} ∏i=1kSip=S1p+S2p+S3p+...Skp=S(1,k)−S(2,1)−S(2,3)+...+S(k,k−1)−S(k,1) 由双线性映射的性质我们可以得到 ∑ i = 1 k S i p = 0 \sum_{i = 1}^{k}Sip=0 ∑i=1kSip=0 所以:
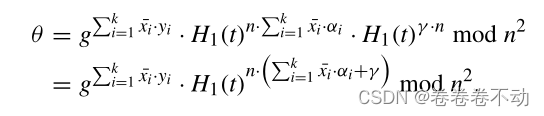
在这里可以将 H 1 ( t ) ∑ i = 1 k x i ˉ ⋅ y i + γ H_1(t)^{\sum_{i = 1}^{k}{\bar{x_i}·y_i+\gamma}} H1(t)∑i=1kxiˉ⋅yi+γ 看作一个随机数那么,上述的式子就是一个Paillier 密文 θ = g m ˉ ⋅ r n \theta=g^{\bar{m}}·r^{n} θ=gmˉ⋅rn 可以通过 D ( s k , c ) D(sk,c) D(sk,c)解密。恢复明文如下:

这里对原文中说: m ˉ 可 以 是 正 的 ( < n / 2 ) 也 可 以 是 负 的 ( > n / 2 ) \bar{m} 可以是正的(<n/2)也可以是负的(>n/2) mˉ可以是正的(<n/2)也可以是负的(>n/2) 有点不太理解
恢复
m
m
m后,
P
P
P可以更新轮
t
+
1
t+1
t+1 轮 :
x
t
+
1
←
∑
i
=
1
k
(
N
i
/
N
)
x
i
=
m
x^{t+1}\leftarrow\sum_{i = 1}^{k}{(N_i/N)x_i=m}
xt+1←∑i=1k(Ni/N)xi=m
P
P
P将开始下一轮训练,重复上述所有步骤,直到全局模型达到预期性能。
总结
在本文中,我们为F-MCS应用程序提出了一个隐私保护方案,称为FedSky。FedSky通过扩展经典的FedAvg算法,基于CG-skyline技术选择合格的工作者,并安全聚合模型更新来训练全局模型。特别地,与FedAvg相比,我们的方案考虑了工人的动态性和异质性。该方法可以显著提高F-MCS模型训练过程的效率。在此基础上,设计了一种新的隐私保护数据聚合协议。该协议专为跨设备FL设置而设计,在模型训练过程中不需要操作者之间的交互。安全性分析表明,该方案保护了隐私。在一个真实的图像分类任务上进行了大量的实验。比较结果验证了工人选择的效率和FedSky对异质工人的鲁棒性。为了将来的工作,我们将在现实世界的物体检测问题中扩展FedSky。
参考
1、群智感知 https://www.jianshu.com/p/3d250028bd61















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









