







URL
https://arxiv.org/pdf/2212.04488
TL;DR
2022 年 12 月 CMU + 清华 + adobe 的文章。提出一种基于几张图片做 ip 保持的方法,可以支持多个 ip 出现的同一张图片里面。
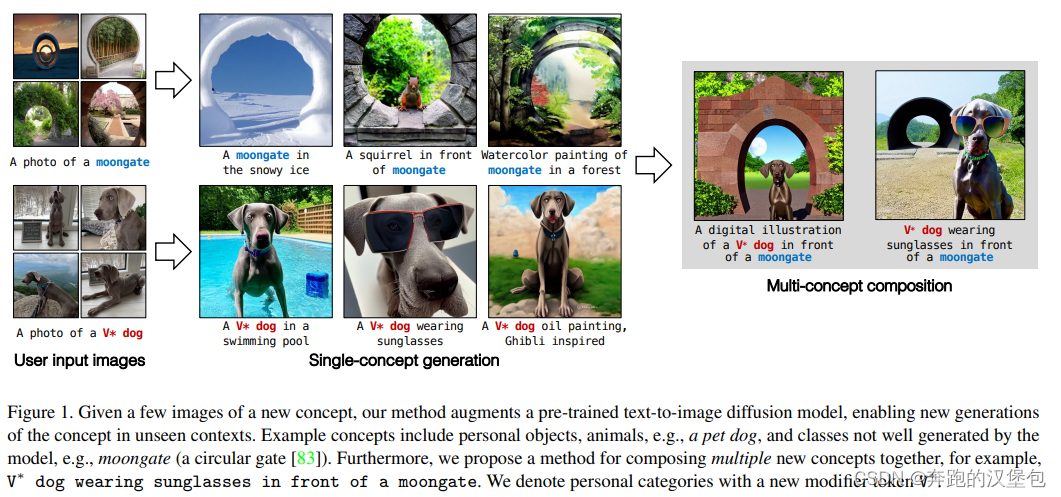
Model & Method
框架整体如下图。训练数据除了特定的角色和场景,还额外引入了特定角色/场景相关联的图片,这样做是为了防止 language shift 现象,即所有关联词都生成特定的图片。
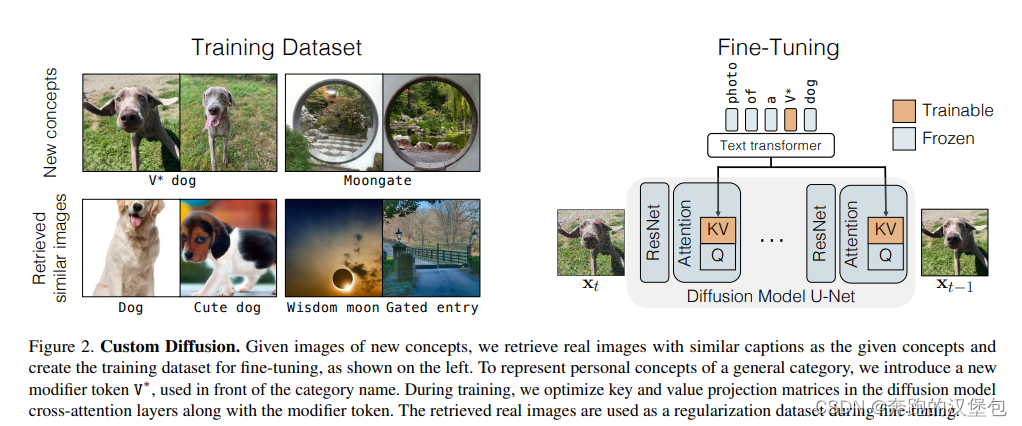
训练过程其实没有啥特别的地方,只 finetune 模型中的 cross attn(里面的 K、V),并且特定任务会增加 rare token。
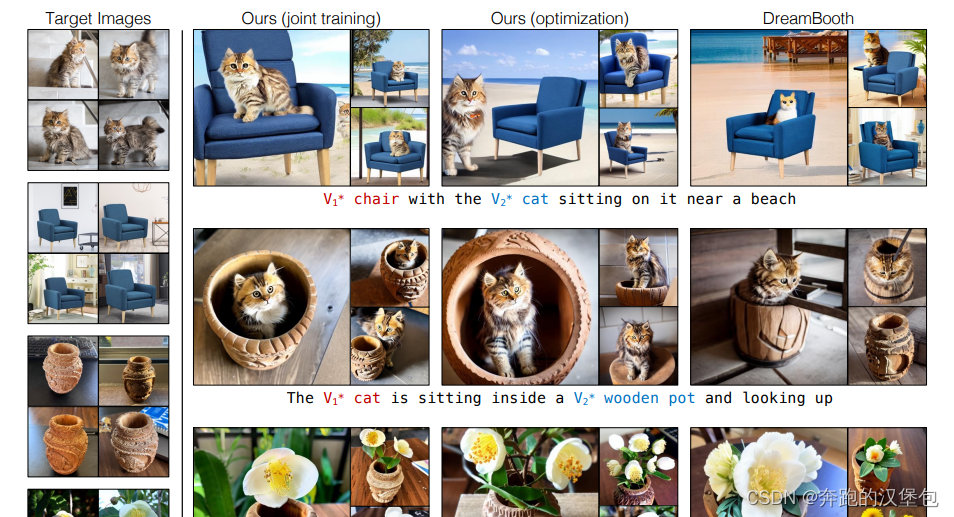
多 ip 保持,给出了两种训练方法:
- 联合训练:不同的物体给不同的 rare token,其他没有特殊的地方
- 分别训练然后融合权重
Dataset & Results
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1654
1654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









