







文章来源:《Learning Symmetric and Low-Energy Locomotion》
INTRODUCTION
目前的DRL可以使机器人从A点移动到B点并且不摔倒,但往往动作显得奇怪和不流畅。
本文提出了一种训练对称和节能的运动模式的方法。创新之处:
- 为了使能量消耗最小,很自然的想法是往action加正则项,使每次输出只有几个action作贡献。然而这种做法与主要的目标——走路和保持平衡相悖。本文使用了curriculum learning,即添加额外的物理辅助工具,让机器人从简单的开始学起,随着学习的深入,逐渐削弱辅助工具的作用最后完全移除。
- 为了使动作对称,前人的做法是评估state的对称性,然而效果不太好。本文评估action的对称性,即在action 网路的损失函数加上不对称惩罚项。
BACKGROUND
定义
定义state ,其中两个是关节角度和关节速度,c表示各个关节是否与地面接触,v是机器人质心的速度。
定义action 为各个关节的扭矩。
定义reward:,其中,
,
表示期望速度。该项使实际速度尽可能与期望速度一致。
,
表示躯干或头的方向,该项使头或躯干尽量保持直立。
,
表示质心在前进方向的坐标。该项尽量使机器人不偏移轨迹。
是action的正则项。
强化学习算法
本文采用ppo
LOCOMOTION CURRICULUM LEARNING
用PD( 比例微分)控制器产生两个力——保持平衡的力和推力作用在机器人身上。 定义一个欧式空间坐标度量此二力。机器人学习到最后这两个力都应该移除,即x=(0,0)。
curriculum该怎么设计呢?本文提出了两种方法:Learner-Centered Curriculum learning 和 Environment-Centered Curriculum Learning ,直接贴图:
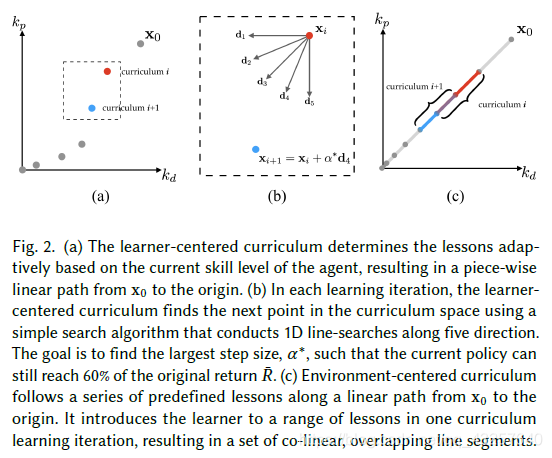


简单地说,Learner-Centered Curriculum learning,每次更新x,从五个方向中选取reward没有下降很大且距离最远的那个点作为。因为
的选择取决于机器人的学习情况,所以是Learner-Centered。
Environment-Centered Curriculum Learning,x的轨迹是人为确定好的,就是Fig(2c)中的过原点的直线。每个curriculum学习直线上的一小段,可以部分重叠。有点分治的思想在其中。
SYMMETRY LOSS
提出:若状态s经过action网络输出为a,那么s的镜像s'对应的输出a'应与a互为镜像。比如从(1,1)走向原点要朝左下的方向,那么从(-1,-1)出发就要朝右上的方向。数学表达为,其中
表示镜像。当然不可能严格地要求满足这个式子,要将它转化为一个松弛约束:
,其中B表示采样个数。最后将
加入action网络的损失函数就OK啦。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









