







机器学习 | 朴素贝叶斯
更多内容,关注wx公众号:数据分析这件小事儿
贝叶斯派与频率派
在参数估计上,有两个方法,MLE(最大似然估计) 和MAP(最大后验估计),分别代表了频率派和贝叶斯派。
频率派关心的是似然函数,认为用样本去计算出的概率就是真实的,而贝叶斯派关心的是后验分布,他们认为样本只是用来修正经验观点。
贝叶斯学派的思想可以概括为先验概率+数据=后验概率,即实际问题中需要得到的后验概率,可以通过先验概率和数据一起综合得到。
先验概率:指根据以往经验和分析,在实验或采样前就可以得到的概率。
后验概率:指某件事已经发生,想要计算这件事发生的原因是由某个因素引起的概率。
先验概率就是事先可估计的概率分布,而后验概率类“由果溯因”的思想。由于先验概率常常难以量化,所以这一点常常被频率派攻击,他们认为贝叶斯派假设的先验分布模型,比如正态分布,beta分布等,没有特定的依据。
贝叶斯公式
假设将训练数据分为k类,如果知道条件概率,则最优预测应最大化此条件概率,也称后验概率:
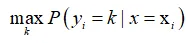
上式表明,对于y的预测,应使后验概率最大化,这种决策方法称为贝叶斯最优决策,由此得到的决策边界叫做贝叶斯决策边界。使用贝叶斯最优决策&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









