






简单起见,该系列算法多只考虑二分类情况。
简单分类器(na ̈ıve classifier)
简单分类器
假设我们什么都不知道的情况,不需要用到任何特征,只知道在训练集的患有此病的比例是34%,那我们肯定会选择不患病的比例66%去预测测试集的都是不患病的。最后的正确率就是测试集中不患病的病人的人数占总人数的比例。
贝叶斯分类器(na ̈ıve bayes classifier)
贝叶斯决策基础:
对于每一个特征,都有一个被归为两种不同类别的概率大小。这里的概率是条件概率(conditional probabilities)。贝叶斯分类器有一个贝叶斯决策边界(Bayes decision boundary),也就是概率等于1/2的点组成的空间。比如下图的紫色边界线,就是概率为1/2所围成的曲线,大于1/2概率分为其一边,小于的分到另一边。

逻辑斯蒂回归(Logistic Regression)
说逻辑回归之前,先说一下线性回归:
线性回归模型不适合用在分类问题(qualitative response)。假设我们要根据一个急诊室病人的基本症状判断此人是得中风(stroke),还是药剂过量(drug overdose),还是癫痫发作(epileptic seizure)。我们用1代表中风,2代表药剂过量,3代表癫痫,特征X1,X2,... ,Xp。但是,这种编码(coding)本身就已经给三个不同类型的病况规定了顺序和大小,其实这三种病本身却并没有这些差异。比如1和3的距离会大于2和3的,默认了中风和癫痫,药剂过量和癫痫两个差异是不同。换一下编码的顺序,会得到不同的答案。每一种编码方法都会建立一个不同的线性模型。当然如果你是判断病人患病程度,而不是类型,比如轻度,中度,重度,这些数据本身是考虑顺序的,那利用线性模型还挺合理的。但实际生活中,大多数都不是这样的。那可能你会想用哑变量编码方式呢,比如中风和药剂过量分别用0,1表示。但是线性回归可能会预测出负值,你怎么解释呢?毕竟概率不可能为负,同样的问题也会出现在当特征很大的时候,预测的概率大于1。如果不加限制,原则上来说,我们总是可以预测出概率大于1小于0的值。所以它不适合用在分类问题上。前面已经声明该系列算法仅考虑二分类情况,所以后面就不用再管线性回归模型。
为了解决这个问题,我们必须建立一个模型,让其输出限定在0和1之间。逻辑斯蒂回归就是其中的一个例子,其运用逻辑斯蒂函数构建输出,控制其不小于0也不大于1。
逻辑斯蒂函数:

odds,下列等式左边称为odds。它的取值范围是0到∞,相应地,对应到概率从0到∞。

logit(log odds),下列等式左边称为logit,对数函数是指数函数的反函数,指数函数的取值范围是0到∞,(所以等式左边的logit可能会出现负数情况。如果用R语言进行逻辑斯蒂回归,拟合出来的值出现负值是正常的。如果想转换为response变量的类别标签值,可以在预测predict函数的参数里设置type等于response。)
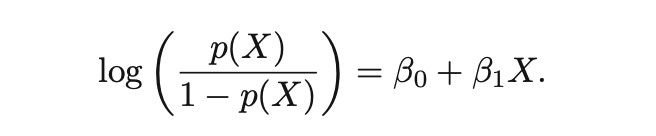
模型需要估计beta参数,根据最大似然估计可以得出。然后就可以用这个模型去做预测了,给定测试集的X,就可以算出其概率,大于1/2归一类小于1/2归另一类。
线性判别分析(linear discriminant analysis(LDA))
逻辑斯蒂回归模型是在给定分类情况就两种的情况下,直接用逻辑斯蒂概率函数建模估计概率。现在我们再来考虑一个可选的,或者说不那么直接的方法去估计概率。
现在,我们不直接用X的概率(逻辑斯蒂函数)去概率,我们用X的概率分布函数去估计呢?
K邻近(K-nearest neighbours(KNN))
理论上来说,人们都喜欢用贝叶斯分类器去分类问题。但是实际上,在给定X的情况下Y的概率是不知道的。贝叶斯分类器可以说是一个黄金准则但是是一个不可达到的黄金准则。所以实际应用中,多是尝试估计出给定X的情况下Y的条件概率分布。K邻近K-nearest neighbors (KNN) 就是实际中用的一个方法。
给定正整数K和一个测试集的观察值x0的情况下,计算距离K个点中出现两种类别的概率大小(频率)。可以用数学公式表示:
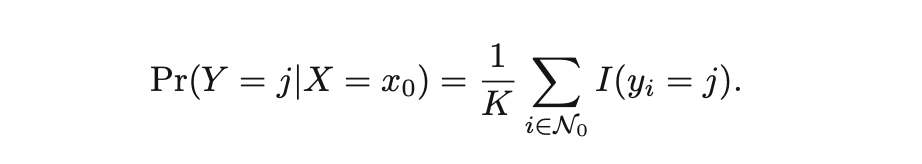
很直观,也很好理解。落入yi里面几次就计数几次,得到频率就是其条件概率。
如下图K=3,x0=“黑色叉”,属于蓝色概率是2/3,橙色的是1/3。蓝色概率大,就把x0归类到蓝色。

注意,KNN比较特殊,是不需要在训练集上凿模型的。但是K的选择就很关键,直接影响概率的大小。K值选太大太小都不好,比如K选1,x0附近的一个点,那就意味着附近那个点是什么类别就被归为什么类别。如果K选太大,比如超过观察值总数,那概率就直接由两个类别的比例大小决定,不管你放进去什么类别的测试集的x0,它都会被归为比例大的那个类里。
岭回归(ridge penalised logistic regression)
LASSO回归(LASSO penalty logistic regression)
广义相加模型(generalised additive logistic regression(GAM))















 747
747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









