







大家好,我是苍何。
要说今年什么赛道比较火,那新能源绝对能排上名。新能源是一个大而全的总称,这个行业里面细分还包括:新能源汽车、动力电池、储能、光伏等。
进入一个热门赛道,除了薪资可观,发展也是相当不错的。那我们来看看 2024 新能源大厂薪酬待遇情况吧。
首先是新能源汽车:

新能源汽车大家都比较熟悉了,蔚来、理想、比亚迪,都是大厂。其中理想给的最高能有 32.2 w 的年包。
综合来看的话,平均年薪也能到 26.95 w。当然如果是在这些新能源大厂搞计算机,薪资也是相当可观的。
就比如今年理想的计算机校招薪资,大家看看:
- 后端:28K* 16,北京,硕士 985
- 算法:40K* 16,杭州,硕士 985
- 大模型:42K* 16,北京,海归 985
- 嵌入式:32K* 16,上海,硕士 985
- 安全工程师:32K* 14,杭州,硕士 211
而且公积金还是交的 12%,还是相当香的。
说到新能源那就不得不提,动力电池的宁王,我们看看他今年的薪资情况:
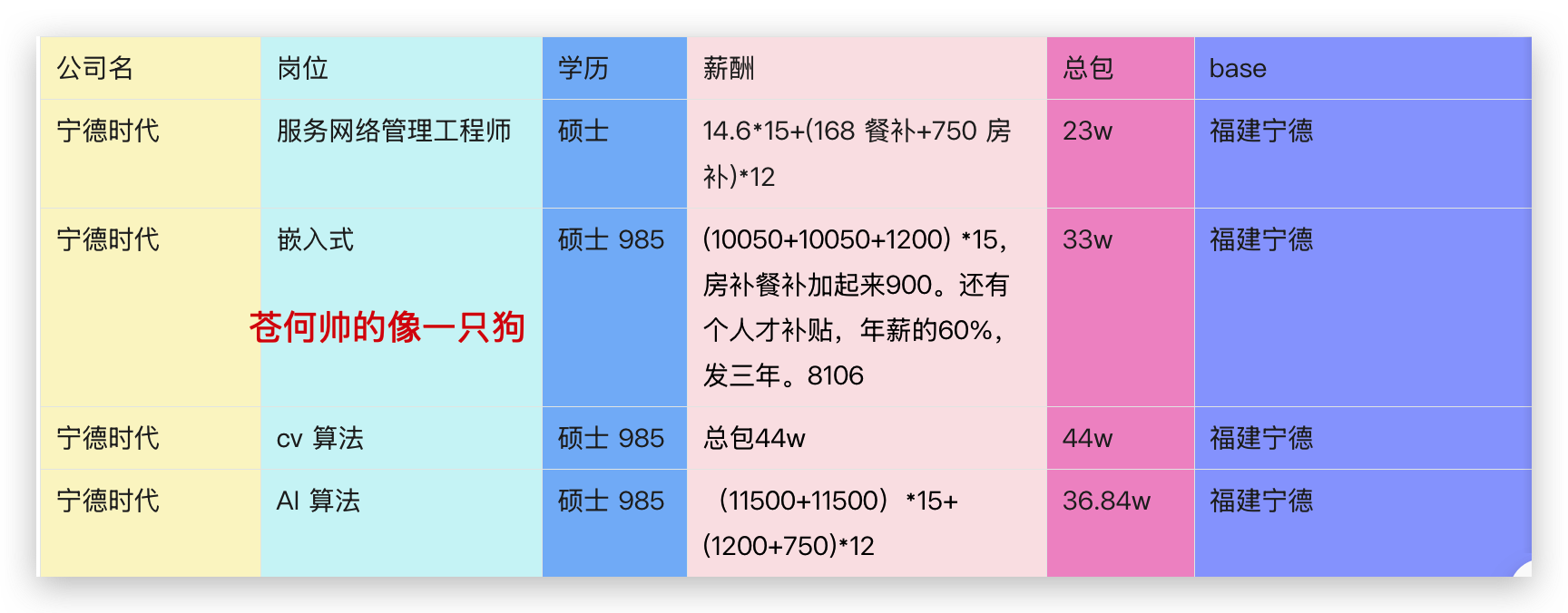
其中算法岗能到 36-40 w 的年包,真的是猛。
然后就是家喻户晓的比亚迪,今年开奖的薪资也很不错,做个总结:
- 211 本、985 本能开到 9k-15k(包括硕)
- 985 硕能开到 18k(c9 居多)
- 20k 以上的凤毛麟角(海龟、清北)
这些新能源公司的福利待遇也相当不错的,大家看看:

好啦,关于新能源大厂的薪资,你有什么补充的呢?欢迎评论区讨论。
…
回归主题。
今天来一道比亚迪开发考过的一道面试算法题,给枯燥的牛马生活加加油😂。
题目描述
平台:LeetCode
题号:49
题目描述:字母异位词分组
给定一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列单词的所有字母得到的一个新单词。
示例 1:
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
示例 2:
输入: strs = [""]
输出: [[""]]
示例 3:
输入: strs = ["a"]
输出: [["a"]]
提示:
1 <= strs.length <= 10^40 <= strs[i].length <= 100strs[i]仅包含小写字母。
解题思路
核心思路:
- 字母异位词的特点是,它们的字母排序后会形成相同的字符串。例如:“eat”、“tea” 和 “ate” 排序后都为 “aet”。
- 可以将排序后的字符串作为字典的键,原始字符串作为值,放入一个哈希表中。
- 最终,哈希表的值即为每组字母异位词。
步骤:
- 初始化一个哈希表,用于存储排序后的字符串(键)及其对应的字母异位词列表(值)。
- 遍历字符串数组,对每个字符串排序,将排序后的结果作为键,将原始字符串添加到哈希表中对应的值列表。
- 遍历哈希表,提取所有值,得到字母异位词的分组结果。
时间复杂度分析:
- 排序字符串的时间复杂度为 O(klogk)O(k \log k),其中 kk 为字符串的长度。
- 遍历数组的时间复杂度为 O(n)O(n),其中 nn 为字符串数组的长度。
- 总时间复杂度为 O(n⋅klogk)O(n \cdot k \log k),其中 kk 是字符串的平均长度。
代码实现
Java代码:
import java.util.*;
public class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
// 创建一个哈希表,用来存储排序后的字符串和对应的字母异位词组
Map<String, List<String>> map = new HashMap<>();
for (String str : strs) {
// 对字符串进行排序
char[] charArray = str.toCharArray();
Arrays.sort(charArray);
String sortedStr = new String(charArray);
// 将排序后的字符串作为键,原始字符串加入值列表中
map.putIfAbsent(sortedStr, new ArrayList<>());
map.get(sortedStr).add(str);
}
// 返回哈希表中所有值
return new ArrayList<>(map.values());
}
}
C++代码:
#include <vector>
#include <string>
#include <unordered_map>
#include <algorithm>
using namespace std;
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
// 创建哈希表,存储排序后的字符串和对应的字母异位词组
unordered_map<string, vector<string>> map;
for (const string& str : strs) {
// 对字符串进行排序
string sortedStr = str;
sort(sortedStr.begin(), sortedStr.end());
// 将排序后的字符串作为键,原始字符串加入值列表中
map[sortedStr].emplace_back(str);
}
// 提取哈希表中所有值
vector<vector<string>> result;
for (const auto& pair : map) {
result.emplace_back(pair.second);
}
return result;
}
};
Python代码:
from collections import defaultdict
class Solution:
def groupAnagrams(self, strs):
# 创建一个哈希表,键为排序后的字符串,值为字母异位词组
anagrams = defaultdict(list)
for s in strs:
# 对字符串进行排序
sorted_str = "".join(sorted(s))
# 将排序后的字符串作为键,原始字符串加入值列表中
anagrams[sorted_str].append(s)
# 返回哈希表中所有值
return list(anagrams.values())
复杂度分析
-
时间复杂度:O(n⋅klogk)O(n \cdot k \log k)
- nn 是数组中的字符串数量,kk 是字符串的平均长度。
- 对每个字符串排序的时间复杂度为 O(klogk)O(k \log k),总计为 O(n⋅klogk)O(n \cdot k \log k)。
-
空间复杂度:O(n⋅k)O(n \cdot k)
- 哈希表中存储了所有字符串的副本,最多需要 O(n⋅k)O(n \cdot k) 的空间。
ending

你好呀,我是苍何。是一个每天都在给自家仙人掌讲哲学的执着青年,我活在世上,无非想要明白些道理,遇见些有趣的事。倘能如我所愿,我的一生就算成功。共勉 💪
点击关注下方账号,你将感受到一个朋克的灵魂,且每篇文章都有惊喜。
更多更全更热门的「笔试/面试」相关资料可访问排版精美的 合集新基地 🎉🎉


















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











