







大家好,我是苍何。
我大概看了下,群里聊的最多的话题就是怎么用 AI 构建个人知识库了。
讲真的,自从 AI 起来后,我也一刻不停的在倒腾知识库,去年我尝试用 Notion 加微信助手来做个人知识库。
所有我看到的有用的知识我都通过微信助手发到 Notion,无论是微信聊天记录还是公众号文章,甚至小红书笔记,只要是我觉得有用的统统都会放到 Notion 知识库。

但是,用了一年后我发现一个问题,大部分被我放进知识库的东西,都躺在那儿吃灰。
知识库并不能很好的为我所用,比如我想找「如何用好提示词」,出来的却是一堆的文章或者聊天记录。
他还是需要我自己去总结,自己再重新去看文章。这就很原始,太慢了。
但自从我发现腾讯的 ima. copilot 后,我的知识管理,彻底起飞。
腾讯 ima. copilot 是腾讯旗下基于自研的混元大模型技术推出的 AI 智能工作台,主要面向学习、办公等场景。
目前 ima 已接入 DeepSeek-R1 模型,可以自建和共享知识库,将收集的优质内容(如网页、文档、公众号文章等)结构化存储,并基于此进行定制化问答。

我现在可以一股脑的将我的所有知识交给 ima. copilot,然后直接基于知识库对话,迅速查找我要的知识。
这其实完成了知识管理的一个闭环:输入+输出。
比如我将数十篇 DeepSeek 相关的文档丢给我在 ima 上创建的知识库
然后我现在突然想了解下「DeepSeek有哪些使用技巧」,要是以前,我得翻阅各种文档去提炼吧?
现在只需要对话框轻轻输入:“DeepSeek 有哪些使用技巧?”
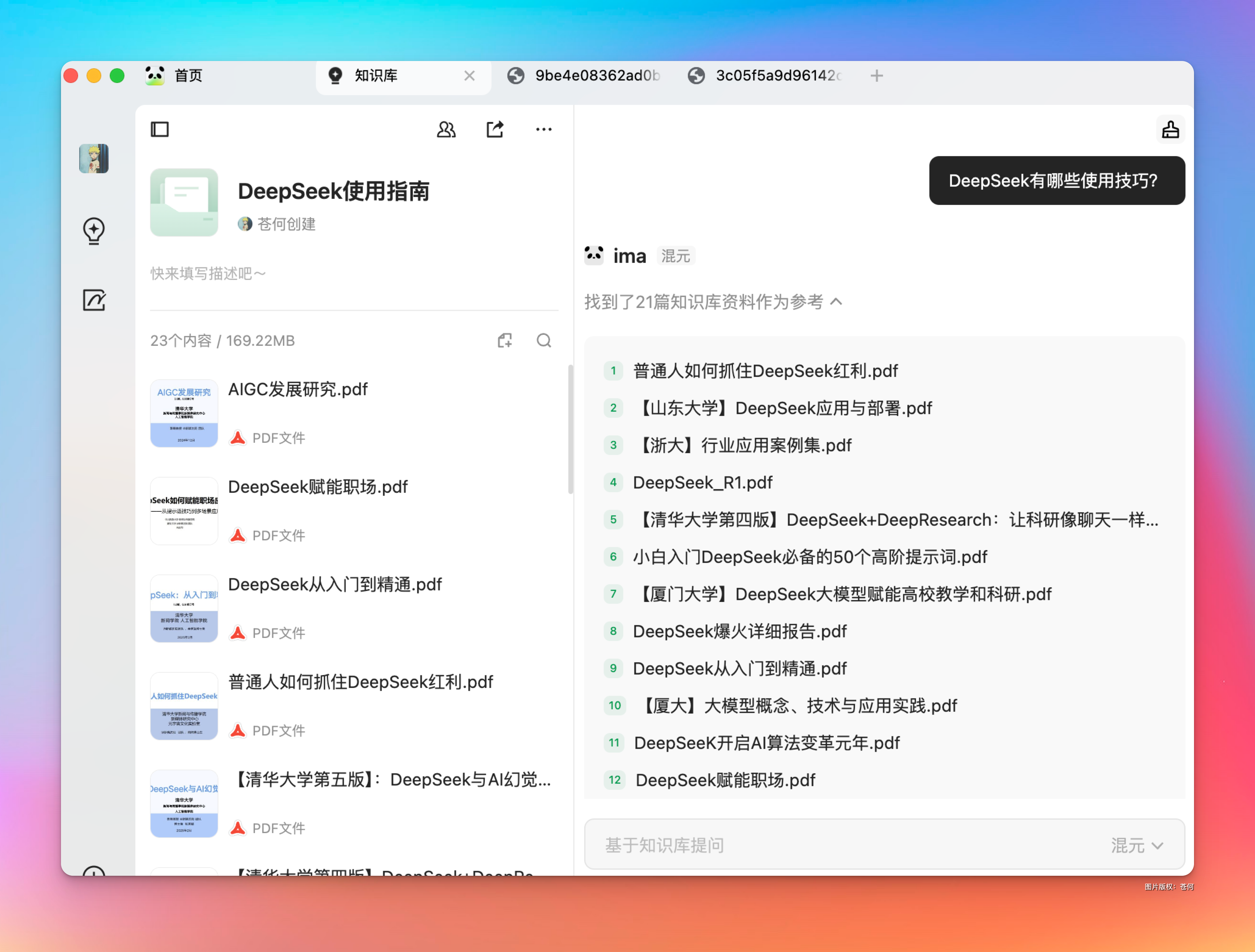
他就会自动取我知识库的文档里面检索,然后直接给出总结答案:
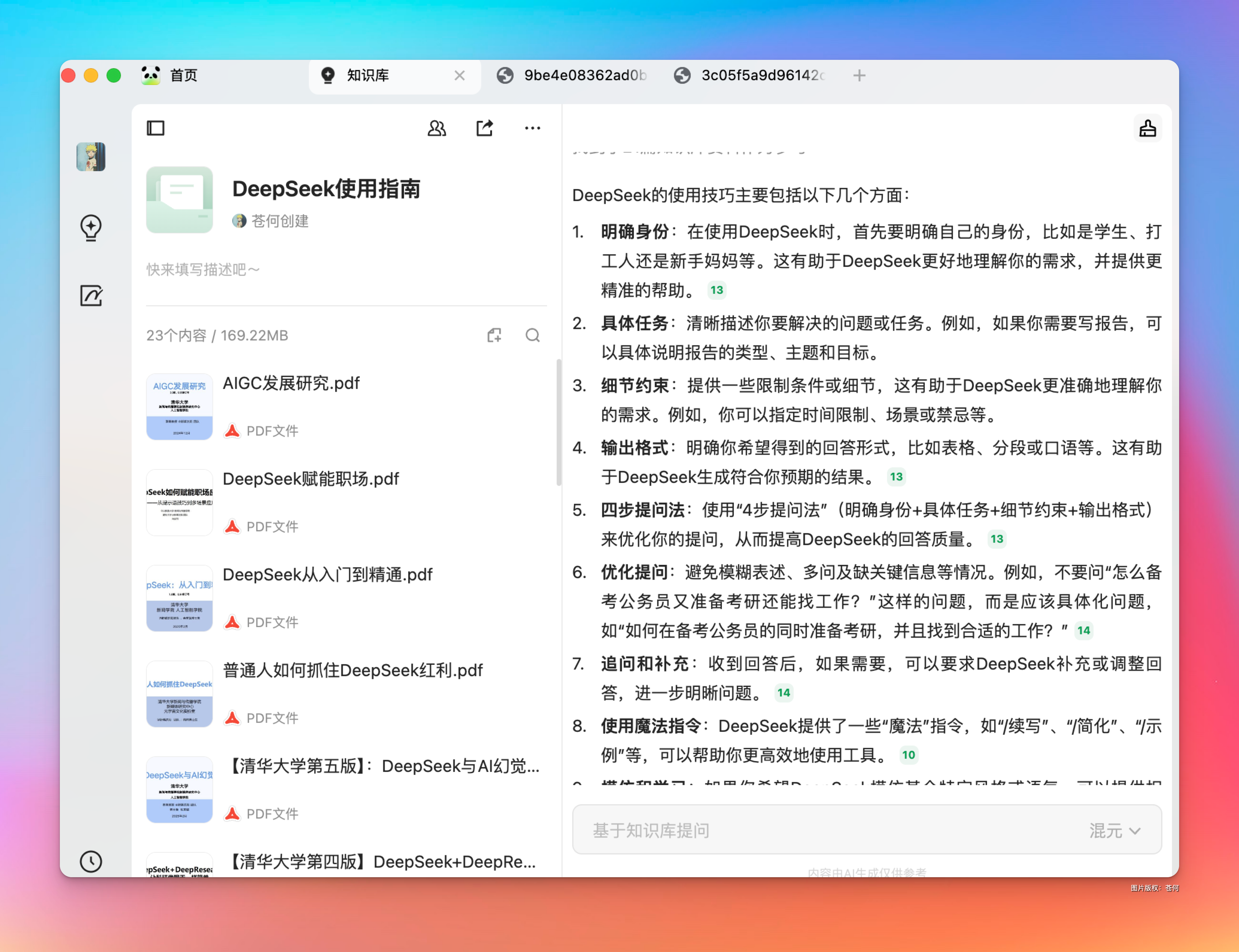
真的,这种提炼总结AI 太会了,也不会有什么幻觉,毕竟都是基于你投喂的数据来回答。
这还是基于腾讯自己的混元模型,甚至现在还可以免费使用 DeepSeek R1 来直接提问,效果相当炸裂。
比如我现在想看下北大新出的《DeepSeek提示词工程和落地场景》这里面都有哪些核心亮点。
要换做以前,找个亮点不得通读全文才能做到啊?而现在,只需要一个简单的 prompt:“帮我提炼北大的 DeepSeek 提示词工程和落地场景这篇文档的亮点,并以 markdown 格式输出”
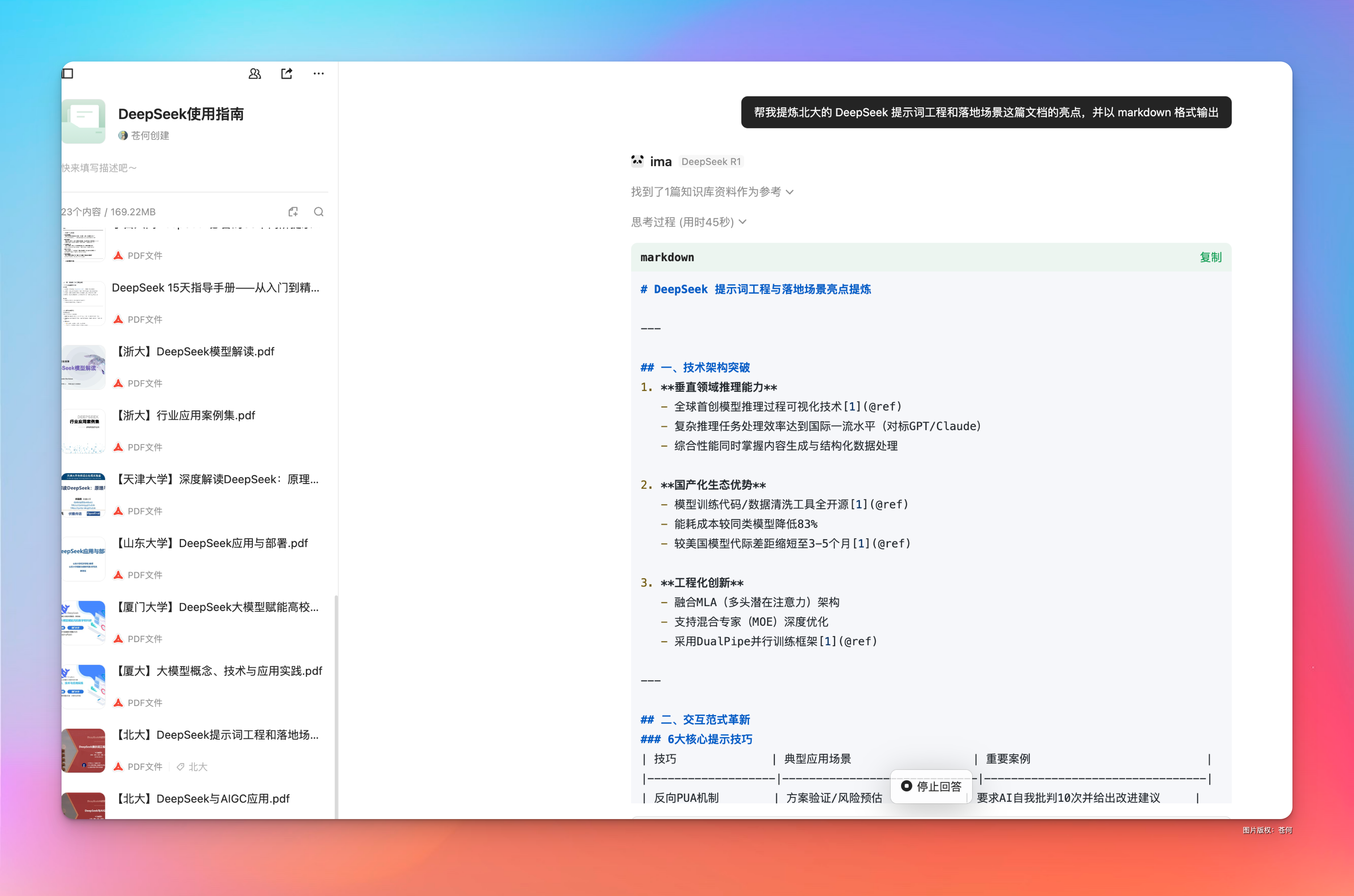
噼里啪啦几下子,就给我总结完了,这里让他以 markdown 格式输出后,甚至我可以直接将他导入到思维导图软件中。
方法也简单的爆,复制他产生的内容。
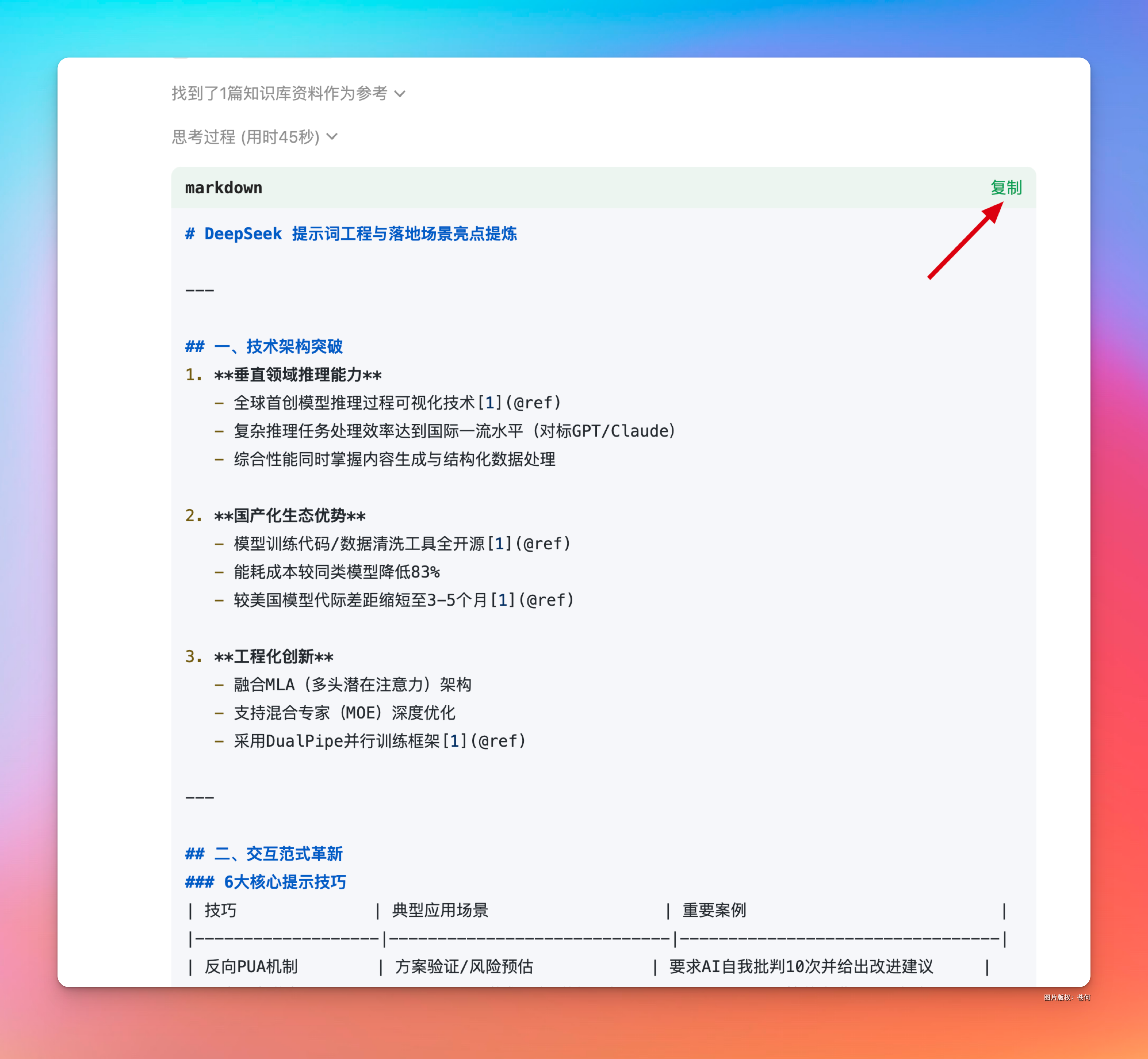
然后本地新建一个 txt 文档,把这个内容贴进去,玩了之后将. txt 后缀改成. md,一个 md 文档就做好了。
接下来打开思维导图软件,点击软件,选择导入,选择 markdown,就 OK 了。
(快速做思维导图的方法其实都差不多)你就可以看到下面的思维导图。
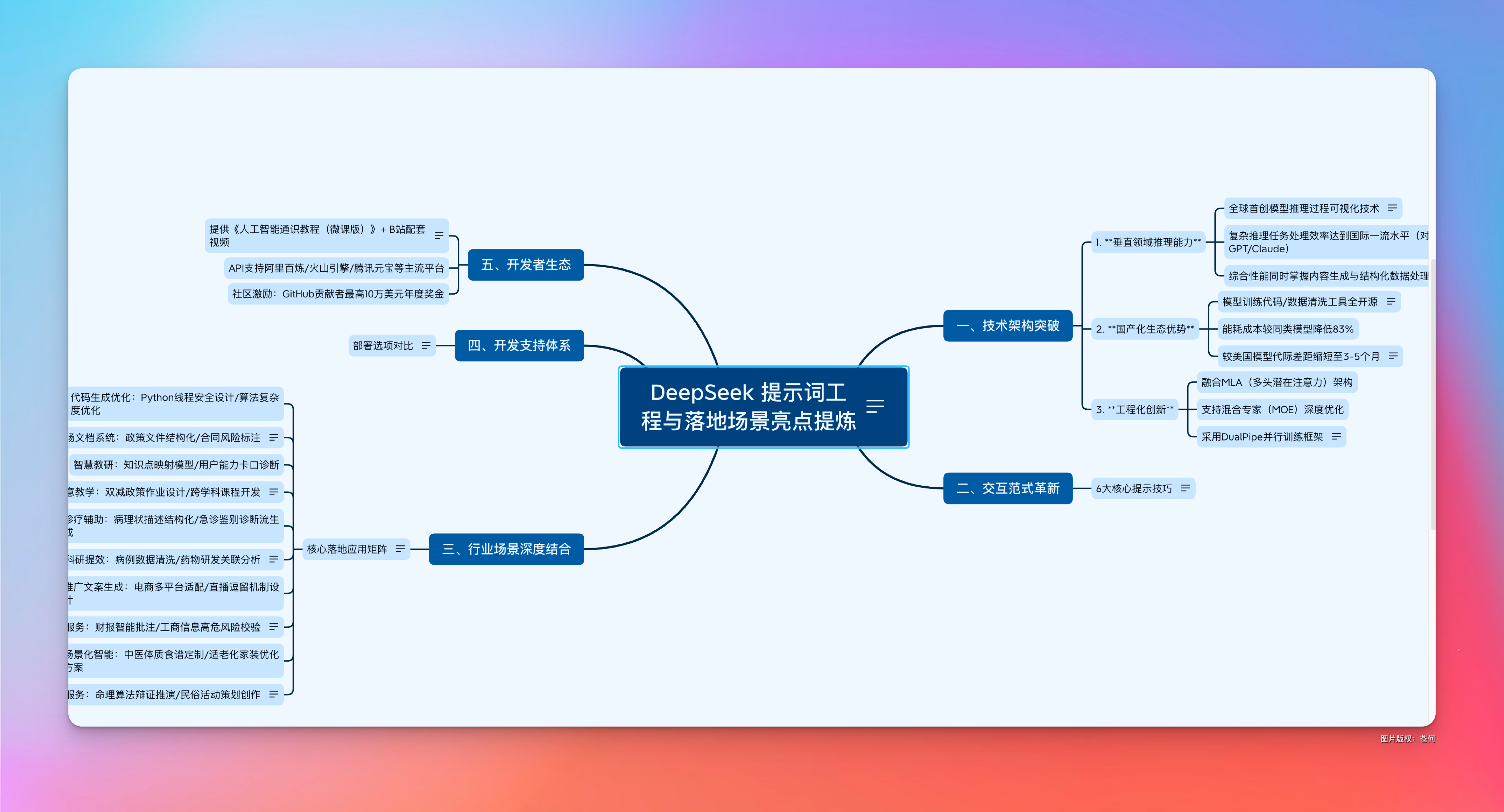
太牛逼了,这才是效率啊。
这样,我收藏的内容,他不再躺在那里吃灰,所有东西都能为我所用,这才是知识库最大的意义。
你以为这就完了?最牛逼的是,这东西可以直接在微信上使用,无论是公众号文章,还是微信聊天中的文件,通通都可以丢给他。
比如我可以选择微信聊天中的文件,直接导入:
导入到自己的知识库之后,就可以对其进行提问了:
现在微信端的输入都是以小程序作为载体,但还不支持微信聊天记录的传入,还不支持自动打标签,自动分类。
我们每天在微信产生了那么多的聊天数据,要是这些都能通通给到知识库,然后做提炼。
你可以想象一下,这个事情会有多么的刺激。
微信生态最牛逼的地方就在于联系,那种基于人和人之间的联系,或许是未来,我们活在这个世界上最珍贵的。
属于我们个人的数字资产。
如果都能最后做成知识库,你可以想象一下,未来的哪一天,你想了解自己再一年前见了什么人,说了什么话,交了哪个朋友。
你只需要轻轻的来一句:hi,Siri,
哦,不。
是,hi,ima,我在 3 月 8 日女神节这天给谁发祝福啦。
你就可以在 10 年后查到今年的女神节,你给哪个女神发红包发祝福了。
是不是挺有意思?
我很兴奋。
我希望我能见证这正在发生的一切,我也希望自己能记录这一切。
这或许是创作本身最大的价值。
感谢你喜欢我的文章,我们下期见。


















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











