







spark中的checkpoint
持久化/缓存可以把数据放在内存中,虽然是快速的,但是也是最不可靠的;也可以把数据放在磁盘上,也不是完全可靠的!例如磁盘会损坏等。
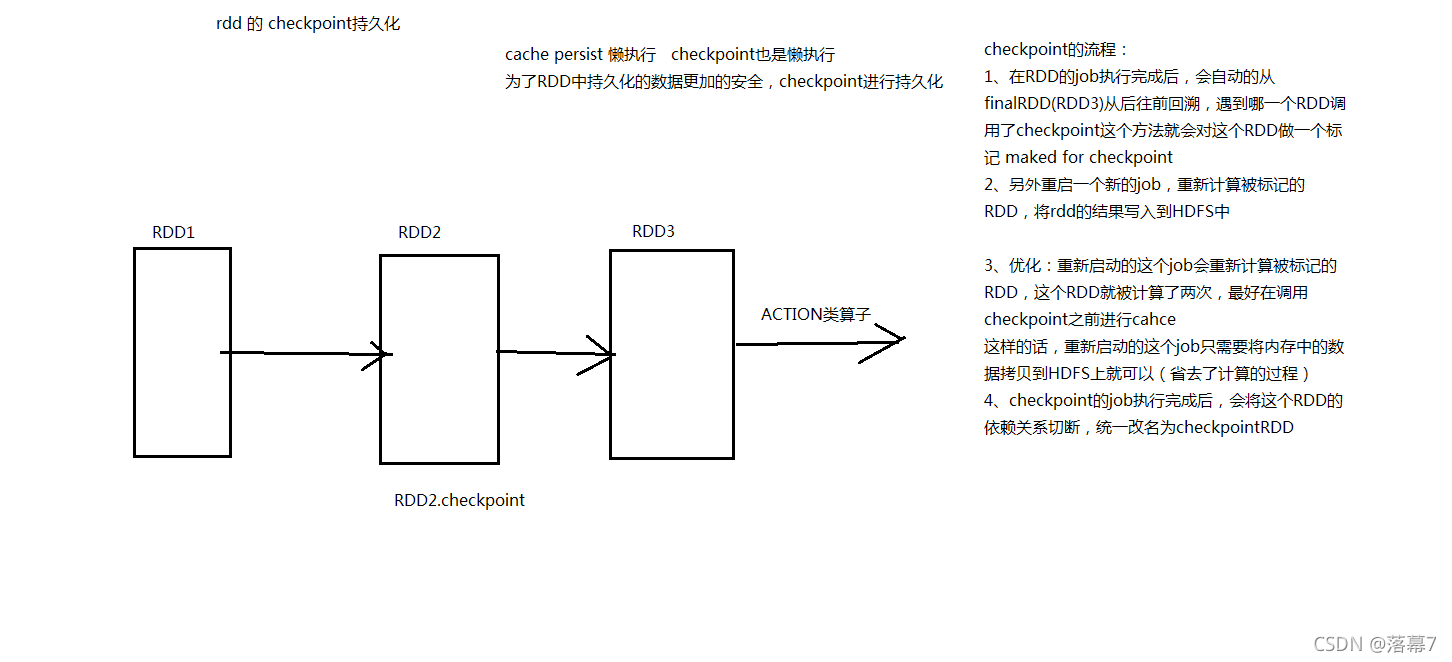
Checkpoint的产生就是为了更加可靠的数据持久化,在Checkpoint的时候一般把数据放在在HDFS上,这就天然的借助了HDFS天生的高容错、高可靠来实现数据最大程度上的安全,实现了RDD的容错和高可用。
具体用法:
sc.setCheckpointDir("hdfs://master:8020/ckpdir")
//设置检查点目录,会立即在HDFS上创建一个空目录
val rdd1 = sc.textFile("hdfs://master:8020/wordcount/input/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
rdd1.checkpoint //对rdd1进行检查点保存
rdd1.collect //Action操作才会真正执行checkpoint
//后续如果要使用到rdd1可以从checkpoint中读取
持久化和Checkpoint的区别
1.位置
Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存–实验中)
Checkpoint 可以保存数据到 HDFS 这类可靠的存储上
2.生命周期
Cache和Persist的RDD会在程序结束后会被清除或者手动调用unpersist方法
Checkpoint的RDD在程序结束后依然存在,不会被删除
3.Lineage(血统、依赖链–其实就是依赖关系)
Persist和Cache,不会丢掉RDD间的依赖链/依赖关系,因为这种缓存是不可靠的,如果出现了一些错误(例如 Executor 宕机),需要通过回溯依赖链重新计算出来
Checkpoint会斩断依赖链,因为Checkpoint会把结果保存在HDFS这类存储中,更加的安全可靠,一般不需要回溯依赖链
idea中运行示例:
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object DemoCheckPoint {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("DemoCheckPoint")
val sc: SparkContext = new SparkContext(conf)
// 设置CheckPoint 存储的位置
sc.setCheckpointDir("spark/data/checkpoint")
// 读取学生数据构建RDD
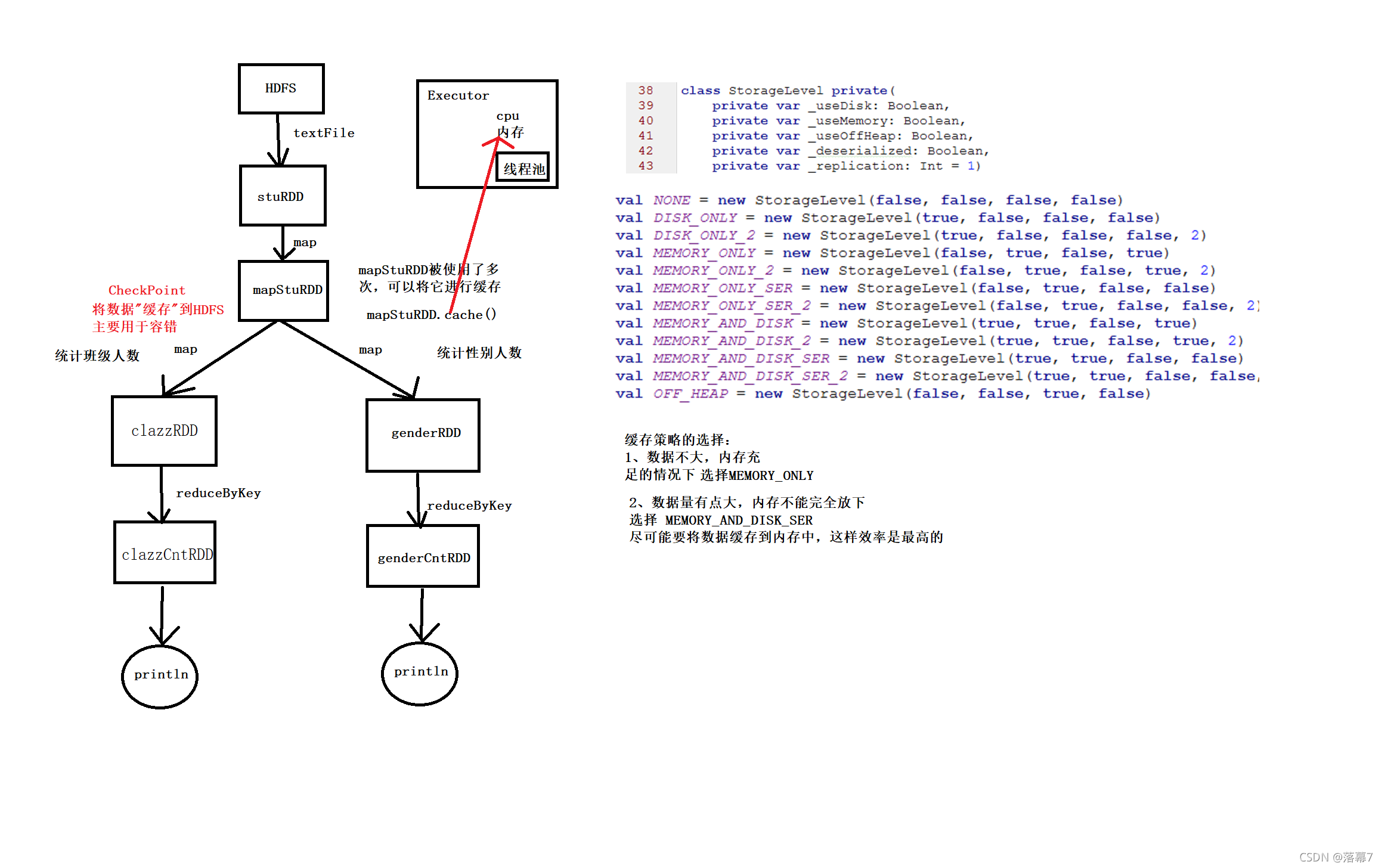
val stuRDD: RDD[String] = sc.textFile("spark/data/student.txt")
val mapStuRDD: RDD[String] = stuRDD.map(line => {
println("=====stu=====")
line
})
// 对使用了多次的RDD进行缓存
// cache() 默认将数据缓存到内存当中
// mapStuRDD.cache()
// 如果想要选择其他的缓存策略 可以通过persist方法手动传入一个StorageLevel
// mapStuRDD.persist(StorageLevel.MEMORY_AND_DISK_SER)
// 因为checkpoint需要重新启动一个任务进行计算并写入HDFS
// 可以在checkpoint之前 先做一次cache 可以省略计算过程 直接写入HDFS
mapStuRDD.cache()
// 将数据缓存到 HDFS
// checkpoint主要运用在SparkStreaming中的容错
mapStuRDD.checkpoint()
// 统计班级人数
val clazzRDD: RDD[(String, Int)] = mapStuRDD.map(line => (line.split(",")(4), 1))
val clazzCntRDD: RDD[(String, Int)] = clazzRDD.reduceByKey(_ + _)
clazzCntRDD.foreach(println)
// 统计性别人数
val genderRDD: RDD[(String, Int)] = mapStuRDD.map(line => (line.split(",")(3), 1))
val genderCntRDD: RDD[(String, Int)] = genderRDD.reduceByKey(_ + _)
genderCntRDD.foreach(println)
// 用完记得释放缓存
// mapStuRDD.unpersist()
}
}
















 909
909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









