







 本文详细介绍了SIFT(尺度不变特征变换)算法,包括其不变性特点、检测过程以及在图像匹配中的应用。通过实例展示了如何使用OpenCV进行SIFT特征检测和匹配,包括关键点定位、方向确定和描述子计算。最后,文章讨论了BFMatcher的kNN匹配方法,以及如何通过调整ratio来提高匹配准确性。
本文详细介绍了SIFT(尺度不变特征变换)算法,包括其不变性特点、检测过程以及在图像匹配中的应用。通过实例展示了如何使用OpenCV进行SIFT特征检测和匹配,包括关键点定位、方向确定和描述子计算。最后,文章讨论了BFMatcher的kNN匹配方法,以及如何通过调整ratio来提高匹配准确性。
一、SIFT的介绍
- 概念
SIFT称为尺度不变特征变换(Scale-invariant feature transform,SIFT),是用于图像处理领域的一种描述。这种描述具有尺度不变性,可在图像中检测出关键点,是一种局部特征描述子。 - SIFT的特点
①SIFT特征是图像的局部特征,其对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性;
②区分性(Distinctiveness)好,信息量丰富,适用于在海量特征数据库中进行快速、准确的匹配;
③多量性,即使少数的几个物体也可以产生大量的SIFT特征向量;
④高速性,经优化的SIFT匹配算法甚至可以达到实时的要求;
⑥可扩展性,可以很方便的与其他形式的特征向量进行联合。
二、SIFT特征检测过程
- 尺度空间极值检测
搜索所有尺度上的图像位置。通过高斯微分函数来识别潜在的对于尺度和旋转不变的兴趣点。 - 关键点定位
在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择依据于它们的稳定程度。 - 方向确定
基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。 - 关键点描述
在每个关键点周围的邻域内,在选定的尺度上测量图像局部的梯度。这些梯度被变换成一种表示,这种表示允许比较大的局部形状的变形和光照变化。
三、利用SIFT实现两张图片的匹配
- 实例化sift
import numpy as np import cv2 from matplotlib import pyplot as plt imgname1 = 'E:/SIFTDemo/test1/test1_1.jpg' imgname2 = 'E:/SIFTDemo/test1/test_1_2.jpg' #实例化的sift函数 sift = cv2.xfeatures2d.SIFT_create() - 图片灰度化
img1 = cv2.imread(imgname1) gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY) #灰度处理图像 img2 = cv2.imread(imgname2) gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)#灰度处理图像 hmerge = np.hstack((gray1, gray2)) #水平拼接 cv2.imshow("gray", hmerge) #拼接显示为gray cv2.waitKey(0)
- 获取关键点
对于获得的关键点信息其存储是kp1, des1 = sift.detectAndCompute(img1,None) #des是描述子 #sift.detectAndComputer(gray, None)计算出图像的关键点和sift特征向量 参数说明:gray表示输入的图片 #des1表示sift特征向量,128维 print("图片1的关键点数目:"+str(len(kp1))) #print(des1.shape) kp2, des2 = sift.detectAndCompute(img2,None) #des是描述子 print("图片2的关键点数目:"+str(len(kp2)))[<KeyPoint 000001781B561150>, <KeyPoint 000001781B5613C0>]
可以采用下面的属性获取每个关键点的一些信息
pt:关键点的位置
size:关键点的范围
angle:关键点角度
response:能够给某个关键点更强烈响应的检测器,有时能够被理解为特性实际存在的概率
octave:标示了关键点被找到的层级,总是希望在相同的层级找到对应的关键点
class_id:标示关键点来自于哪一个目标

- 绘制关键点
img3 = cv2.drawKeypoints(img1,kp1,img1,color=(255,0,255)) #画出特征点,并显示为红色圆圈 #img3 = cv2.drawKeypoints(gray, kp, img) 在图中画出关键点 参数说明:gray表示输入图片, kp表示关键点,img表示输出的图片 #print(img3.size) img4 = cv2.drawKeypoints(img2,kp2,img2,color=(255,0,255)) #画出特征点,并显示为红色圆圈 hmerge = np.hstack((img3, img4)) #水平拼接 cv2.imshow("point", hmerge) #拼接显示为gray cv2.waitKey(0)
- 关键点匹配
kNN匹配的说明:# BFMatcher解决匹配 bf = cv2.BFMatcher() matches = bf.knnMatch(des1,des2, k=2) #print(matches) #print(len(matches)) # 调整ratio good = [] for m,n in matches: if m.distance < 0.75*n.distance: good.append([m]) #img5 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,matches,None,flags=2) img5 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2) cv2.imshow("BFmatch", img5) cv2.waitKey(0) cv2.destroyAllWindows()
近邻匹配,在匹配的时候选择k个和特征点最相似的点,如果这k个点之间的区别足够大,则选择最相似的那个点作为匹配点,通常选择k=2,也就是最近邻匹配。
kNN算法的核心思想
如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
cv2.drawMatchesKnn(img1,kp1,img2,kp2,matches,None,flags=2)下的匹配效果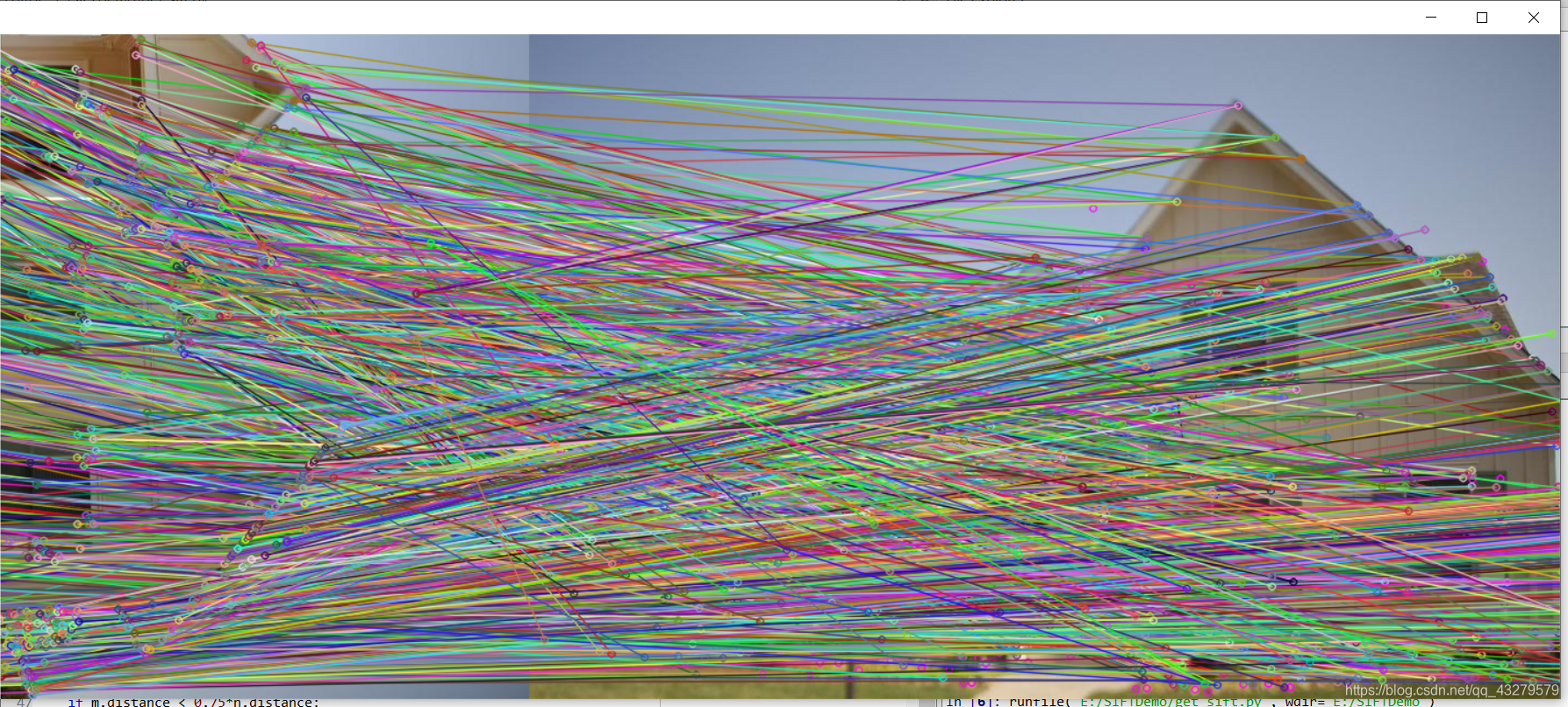
整个线条比较杂乱,并且还有比较多的匹配错误
cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2)下的匹配效果

明显优于上面的匹配
当调整ratio的时候,匹配也会发生变化,会过滤一些错误的匹配点。根据经验,ratio一般取值为0.6,0.7。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









