






YOLOV8
YOLOv8 是一款前沿、最先进(SOTA)的模型,基于先前 YOLO 版本的成功,引入了新功能和改进,进一步提升性能和灵活性。YOLOv8 设计快速、准确且易于使用,使其成为各种物体检测与跟踪、实例分割、图像分类和姿态估计任务的绝佳选择。
| 模型 | 尺寸 (像素) | mAPval 50-95 | 速度 CPU ONNX (ms) | 速度 A100 TensorRT (ms) | 参数 (M) | FLOPs (B) |
|---|---|---|---|---|---|---|
| YOLOv8n | 640 | 37.3 | 80.4 | 0.99 | 3.2 | 8.7 |
| YOLOv8s | 640 | 44.9 | 128.4 | 1.20 | 11.2 | 28.6 |
| YOLOv8m | 640 | 50.2 | 234.7 | 1.83 | 25.9 | 78.9 |
| YOLOv8l | 640 | 52.9 | 375.2 | 2.39 | 43.7 | 165.2 |
| YOLOv8x | 640 | 53.9 | 479.1 | 3.53 |
环境
需要Python>=3.8环境中安装ultralytics包
pip install ultralytics
也可以直接拉取项目进行代码测试:
git clone https://github.com/ultralytics/ultralytics
命令
YOLOv8 可以在命令行界面(CLI)中直接使用,只需安装完成环境以后输入 yolo 命令:
yolo predict model='模型路径 'source='图片路径'
也可以在 Python 环境中直接使用,并接受与上述 CLI 示例中相同的参数:
# 导入ultralytics包
from ultralytics import YOLO
# 加载模型
model = YOLO("yolov8n.pt") # 加载预训练模型(建议用于训练)
# 使用模型
results = model("图片路径") # 对图像进行预测
模型
也可以根据自己的需要进行训练模型
可以参考COCO数据集准备相应的文件以及yml配置,这里不做阐述。
使用
本次使用python的flask框架对yolov8做一些实践方面的应用。
先上代码:
import base64
import json
import cv2
from ultralytics import YOLO
import numpy as np
from flask_cors import CORS
from flask import Flask, request, Response
import logging
# 加载YOLOv8模型
model = None
# 加载本地摄像头
camera = cv2.VideoCapture(0)
# 初始化
def create_app():
global model
app = Flask(__name__)
logger = logging.getLogger(__name__)
logger.info('加载app成功')
CORS(app)
# 初始化模型
model = YOLO(model="./model/yolov8n-pose.pt")
print('模型加载成功')
# 加载路由和其它初始化过程
# 载入测试图片
test_img = cv2.imread('./model/wbb.jpg')
print('加载初始化图片')
# 模型预测
results = model(test_img)
print('进行初始预测')
frame = results[0].plot()
print('初始化预测成功')
print("结果" + str(type(frame)))
return app
# 创建应用
app = create_app()
# 本机摄像头调用
def gen_frames():
while True:
success, frame = camera.read()
if not success:
break
else:
# YOLOv8预测
results = model(frame)
# 绘制预测结果
frame = results[0].plot()
# Encode as a jpeg image and return
ret, buffer = cv2.imencode('.jpg', frame)
frame = buffer.tobytes()
yield (b'--frame\r\n'
b'Content-Type: image/jpeg\r\n\r\n' + frame + b'\r\n')
# 网络接口
@app.route('/receive_image', methods=['POST'])
def receive_image():
# 从request中获取参数
data = request.data.decode('utf-8')
json_data = json.loads(data)
str_image = json_data.get("imgData")
img = base64.b64decode(str_image)
img_np = np.frombuffer(img, dtype='uint8')
new_img_np = cv2.imdecode(img_np, 1)
# YOLOv8预测
results = model(new_img_np)
# # 绘制预测结果
print("预测结果"+str(type(results[0])))
frame = results[0].plot()
ret, buffer = cv2.imencode('.jpg', frame)
frame = buffer.tobytes()
return Response(frame,
mimetype='multipart/x-mixed-replace; boundary=frame')
# 本机测试接口
@app.route('/video_feed')
def video_feed():
return Response(gen_frames(), mimetype='multipart/x-mixed-replace; boundary=frame')
if __name__ == "__main__":
app.run(debug=True)
- create_app函数:
- 初始化Flask应用,加载模型,进行一次测试预测
- 打印初始化日志,用于调试
- 返回构造好的Flask应用实例
- gen_frames函数:
- 从本地摄像头读取视频流
- 使用YOLOv8模型对每帧图像进行预测
- 将预测结果画框,编码为JPEG格式
- 生成视频流响应返回给前端显示
- receive_image接口:
- 接收前端base64编码的图像
- 解码图像,交给YOLOv8模型预测
- 将预测结果画框,编码为JPEG格式
- 返回图像响应给前端显示
- video_feed接口:
- 调用gen_frames函数获取本地摄像头视频流
- 将视频流通过Response返回给前端显示
在没写前端的情况下,通过接口/video_feed在网页中进行测试结果如图:
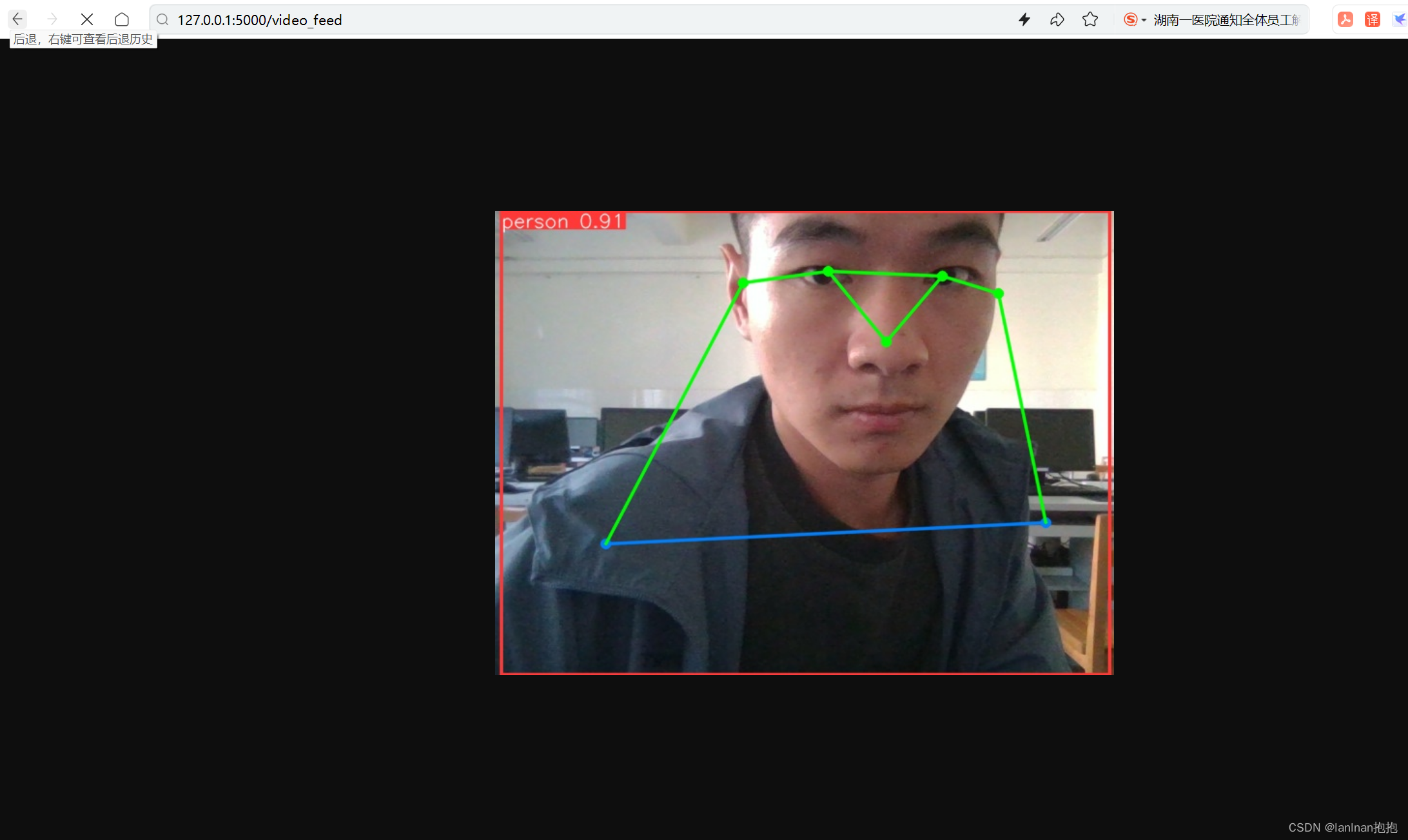
但是这里调用的是本机摄像头,只能通过本地部署才能实现效果,所以,我们需要远程部署的一个接口.
主要就是拿到不同设备上的视频帧的数据流,这里使用web端的网页部署,代码如下:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link type="text/css" rel="styleSheet" href="./css/index.css" />
<script src="./js/jquery-3.6.1.min.js"></script>
<script src="./js/vue.js"></script>
<title>主页面</title>
</head>
<body>
<div id="app">
<div class="content">
<div class="v1">原视频</div>
<video id="video" autoplay></video>
<div class="res">
<div class="v2">识别结果</div>
<img id="resVideo" width=640 height=480 :src="src" crossOrigin="anonymous"></img>
<div class="slider">
<input type="range" min="100" max="2000" v-model="speed" value="1000"><br/>
<span>调节帧率,当前:{{speed}}</span>
</div>
</div>
</div>
</div>
<script src="./js/index.js"></script>
</body>
</html>
:root {
--primary-color: #3f51b5;
--bg-color: #f5f5f5;
--box-shadow: 0 5px 10px rgba(0,0,0,0.1);
}
body {
background: var(--bg-color);
font-family: 'Open Sans', sans-serif;
}
.content {
max-width: 1200px;
margin: 0 auto;
padding: 20px;
display: flex;
text-align: center;
flex-wrap: wrap;
align-items: flex-start;
gap: 20px;
}
.v1,
.v2 {
font-size: 1.2rem;
font-weight: 500;
margin-bottom: 10px;
}
#video {
flex: 1 1 500px;
width: 55%;
border-radius: 10px;
box-shadow: var(--box-shadow);
}
.res {
flex: 1 1 500px;
text-align: center;
}
#resVideo {
max-width: 100%;
border-radius: 10px;
box-shadow: var(--box-shadow);
transition: all 0.3s;
}
#resVideo:hover {
transform: scale(1.05);
}
.slider {
margin-top: 20px;
text-align: left;
}
.slider input {
width: 100%;
padding: 10px;
}
.slider span {
font-size: 0.9rem;
color: #666;
}
/* 平板 */
@media (max-width: 1024px) {
.content {
gap: 10px;
}
#video,
.res {
flex: 1 1 auto;
}
}
/* 手机 */
@media (max-width: 768px) {
.content {
flex-direction: column;
}
#video,
.res {
width: 100%;
}
#resVideo{
max-height: 23em;
}
}
js
var vm = new Vue({
el:"#app",
/*Model:数据*/
data:{
imgBlob:{},
speed:2000,
src:""
},
created() {
this.camera()
},
methods: {
startTimeout(){
setTimeout(()=>{
// 创建canvas元素
const canvas = document.createElement('canvas')
canvas.width = 320
canvas.height = 240
const context = canvas.getContext('2d')
// 绘制视频帧到canvas
context.drawImage(video, 0, 0, 320, 240)
// 获取图像数据
var imgData = canvas.toDataURL("image/jpg");
imgData = imgData.replace(/^data:image\/(png|jpg);base64,/,"")
var myHeaders = new Headers();
myHeaders.append("Accept", "*/*");
var requestOptions = {
method: 'POST',
headers: myHeaders,
body: JSON.stringify({"imgData": imgData})
};
fetch("https://localhost:5000/receive_image", requestOptions)
.then(response => response.blob())
.then(blob => {
const url = URL.createObjectURL(blob);
this.src = url;
})
.catch(error => console.log('error', error));
this.startTimeout()
},this.speed)
},
camera(){
navigator.mediaDevices.getUserMedia({ video: true })
.then(stream => {
// 视频元素显示流
const video = document.getElementById('video')
video.srcObject = stream
this.startTimeout();
})
.catch(error => {
console.error('访问用户媒体设备失败:', error)
})
}
},
});
主要流程如下:
- 获取摄像头视频流,显示在页面的 元素中。
- 每隔一段时间(由 data 中的 speed 控制间隔),从视频流中截取一帧图像,绘制到 canvas 中。
- 将 canvas 图像数据转成 base64 格式,发送到后端 /receive_image 接口。
- 接收后端返回的预测结果图片,设置到 src 数据中展示出来。
- 创建一个递归的定时器,不停重复上述过程,从而实现摄像头实时预测效果。
- 通过设置 speed 的值可以控制截图预测的频率。
关键在于:
- 获取和显示视频流
- 截图并编码为 base64 格式
- 递归调用来不断发送截图预测
- 展示后端返回的预测结果
效果如下:

也可以在不同设备进行测试:
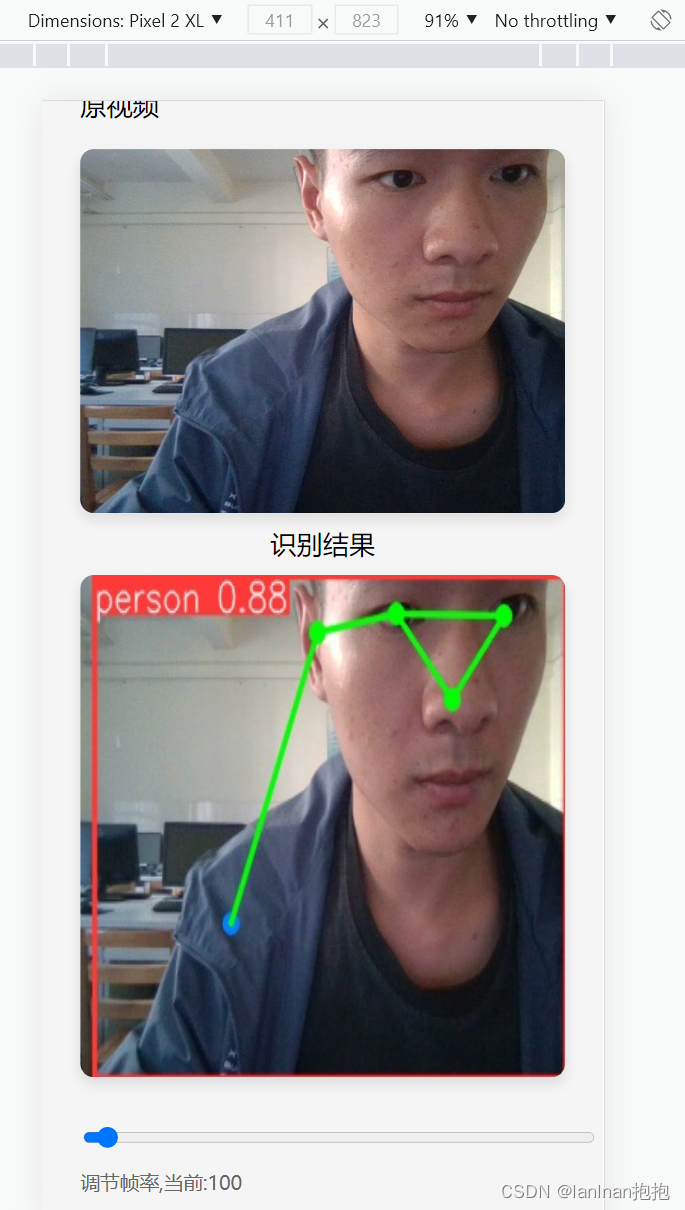
这样可以实现一个伪全平台的检测功能。
这里主要通过settimeout对调用接口的速率进行控制
setTimeout在这个场景中的作用是设置一个定时器,以一定的时间间隔(由speed控制)重复执行一个函数。
具体用法:
- setTimeout接受两个参数,第一个参数是一个函数,第二个参数是时间间隔,单位是毫秒。
- 在setTimeout内部的函数中,包含了截取视频帧、编码为base64、发送到后端、展示结果等一系列操作。
- 最关键的是,在这个函数的最后又调用了setTimeout,并传入了这个同一个函数。这就创建了一个递归的定时器。
- 每次定时器执行结束,就会再设置一个定时器,周而复始地重复执行这个函数。
- 这样就可以周期性地截取视频帧并预测,实现实时效果。
- 通过修改speed的值可以控制每次定时器的时间间隔,来调整预测的频率。
这是利用 JavaScript 的 setTimeout 来周期性执行某个操作的用法。可以很好地配合其他逻辑来实现需要定时或周期执行的功能。
然后传输至后端的/receive_image
前端发送base64编码图像 -> 后端解码为OpenCV矩阵 -> YOLOv8预测 -> 绘图 -> 编码为jpg -> 返回预测结果图
- 接收到前端通过POST方法发送来的JSON数据
- 从JSON中提取出key为imgData的值,这是base64编码后的图像数据
- 使用base64.b64decode()对其解码,转换为字节数据
- 使用np.frombuffer()将上一步得到的字节数据转换为Numpy数组
- 使用cv2.imdecode()对数组进行解码,还原为OpenCV图像矩阵
- 将得到的图像矩阵传给YOLOv8模型的forward方法,进行预测
- 从预测结果中取出第一个检测框,使用plot()方法在图像上绘制出来
- 使用cv2.imencode()来编码处理后的图像,转为jpg格式
- 将编码后的jpg图像数据包装到Response对象中返回给前端
对yolov8的总结
- YOLOv8是一个目标检测模型,可以对图像进行多类别目标的识别和定位。
- 该项目需要对摄像头视频流进行人体姿态预测,YOLOv8可以满足这个需求。
- 在后端代码中,加载了YOLOv8的模型文件,并初始化了模型对象。
- 在receive_image接口中,将前端发送来的图像输入到YOLOv8模型中进行预测。
- YOLOv8模型会输出检测到的人体目标框以及类别等信息。
- 从YOLOv8输出中取出需要的预测框位置信息,在图像上进行绘图标注。
- 这样就完成了对视频图像的人体检测和 LOCALIZATION。
- 最终编码后的预测结果图像返回给前端展示。
如需模型文件可访问该项目git地址:https://gitee.com/taritaris/yolov8-as-human-detection/blob/master/model/yolov8n-pose.pt















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











