







从零开始的tinyhttpd项目
前言
TinyWebServer是c++服务器方向常见的一个项目,但该项目涉及的内容太多。由于本人接触linux网络编程不深,所以准备从tinyhttpd项目开始学起,因为该项目代码量不大,而且涉及模块少,对于不熟悉的虚拟机配置,linux配置和命令都有很大的练习作用,故选用该项目先试手一下。虽然说是从零开始,但还需要了解以下内容
- 基本c/c++语法
- linux简单命令
- 网络编程基础概念
虚拟机安装及配置
本人系统win10,所以安装用的virtualbox,市面上常见虚拟机都可配置。可到VirtualBox官方网址下载。安装网上教程很多,导入镜像文件系统建议用centos,据说该系统作为服务器比ubuntu效果好,本人也在试用中。CentOS7的阿里云镜像网址:http://mirrors.aliyun.com/centos/7/isos/x86_64/。
可以参考该教程安装VirtualBox并且配置CentOS7:使用VirtualBox安装CentOS7。
注意:上面这个博客已经够自己配好环境了,但我安装时还是查了很多教程。配环境是第一步,但也需要懂各个层次和顺序,这里简单介绍一下:
- 首先安装VirtualBox(如果你主机不是linux系统的),这个软件是虚拟机,可以在你现在用的win平台上运行其他系统,简单来说这个工具可以帮你安装不同版本的系统,只不过你的主机系统是宿主平台,其他系统通过你的主机系统访问资源及调用命令。
安装方法也很简单,只需要在官网下载好打开安装包,改好文件存放目录即可运行。 - 其次先下载好阿里云镜像的centos7镜像系统,该文件是操作系统,需要将该光盘导入VirtualBox的linux系统(版本Red-Hat 64bit),类似于你的主机是裸机,需要导入windox操作系统才能进行运行。按照上面的博客安装即可。
- 如果直接运行centos7,那打开后会发现界面全是命令行,对于不熟悉linux的小白来说很不友好,所以还要在安装centos7系统时,软件安装选择GNOME桌面,也可以选择其他可视化界面,这样可以方便我们操作。
部署tinyhttpd项目
这一步我建议大家先让项目运行起来而不要管这样操作为什么这么改,先跑起来能用后我们再一步步读懂源码然后改进。
- 安装并解压缩原项目
原项目下载网址:https://sourceforge.net/projects/tinyhttpd/。下载后安装在虚拟机上,然后解压缩成一个文件,如下图:

源文件是tinyhttpd-0.1.0.tar.gz。我们解压缩到桌面形成文件夹tinyhttpd-0.1.0。打开文件夹tinyhttpd-0.1.0是这样的,如下图所示。

新手注意!!!:可以在virtual用命令行下载,也可以下载在本机上把文件复制到虚拟机里。新手会发现virtualbox的虚拟机和本机复制粘贴操作和文件拖动是无法操作的,其实这里只需要设置一下即可,如下图:在第一步安装增强功能完成后,将共享粘贴板设置为双向即可使主机和虚拟机的复制粘贴操作一致,将拖放设置为双向即可使主机下好的安装包拖动到虚拟机的桌面上。

- 修改
在文件夹中打开httpd.c文件和Makefile文件,按照下面博客修改代码:tinyhttpd在Linux编译。
然后在终端打开到该目录下,不会操作的新手可以用ls(显示列表命令)和cd(打开目录命令)操作即可,如图:
cd 桌面
cd tinyhttpd-0.1.0/

进入文件夹输入命令make会生出httpd.c文件,完成后输入命令运行httpd。运行后的httpd running on port后面跟的就是你的本地端口号。
./httpd
注意!:此处可能有和我一样的新手忘了联网导致失败,具体可以在终端ping通一下百度网址和自己的主机localhost,命令为:
ping localhost
ping www.baidu.com
如果网络没有问题就按上面步骤操作完后,打开浏览器输入网址localhost:本地端口号。如果连不上说明没有联网,参考博客ping: www.baidu.com: 未知的名称或服务
运行httpd后要注意!!!:
- 如果提交颜色后返回cgi页面没有显示,终端报错Can’t locate CGI.pm 后面跟color.cgi line 4,说明没有装cgi.pm模块。解决方式就是安装cgi.pm,参考:linux下perl及cgi.pm的安装(perl-5.22.1)。
- 一般来说需要先装CPAN再装CPi.pm,但是我们安装完CPAN,然后在CPAN下安装CPi.pm时候会发现安装网速过于慢,这是因为CPAN的默认源在国外,所以我们一定要将CPAN默认源换成阿里镜像源,可参考Perl Cpan配置国内站方法。这样就会很快安装完成。
- 安装cpi.pm后输入命令
perl -MCGI -e 'print "CGI.pm version $CGI::VERSION\n";'
如果出现CGI.pm version 4.54即可成功。如图:

准备完上述报错再次运行,重新编译,输入命令make clean后会删除原本编译生成的httpd文件,然后在输入命令make生成httpd后运行 ./httpd命令,如下图:

在浏览器打开网址输入颜色即可返回正常颜色页面:(如果还没有成功可能是没有给cgi模块权限)


至此运行成功!!!
预备知识
在详细介绍代码前,先给不了解unix网络编程的新手普及一下相关概念。
我们先要对http协议和tcp协议有所了解,网上博客很多此处不赘述。对于http报文格式还需要有深入了解,后面代码解读部分也会提到。
然后还需要了解一下服务器客户端socket通信过程,先看这篇博客介绍linux下socket通信:Linux Socket编程。
通过调用socket的底层函数可以很方便的处理下面流程图的http通信,底层的tcp可以不用具体去管。

由于tinyhttpd实现的是B/S模型,不需要客户端程序,服务器端负责接收浏览器的http请求并处理,有可能返回静态页面,也有可能返回cgi脚本运行结果。可以了解一下这篇博客:C/S 与B/S 模型的联系与区别
代码解读
可参考博客Tinyhttpd精读解析。

先搞懂图中的流程后,我们一步一步看代码,顺序为 main -> startup -> accept_request -> execute_cgi。
不过在此之前先简单了解一下各个函数功能:
此处给新手一点建议,读代码要从main函数开始吗,而且最好不要看见一个函数就想知道它的具体实现,先了解所读模块的代码工作,对于涉及到的函数只需要知道该函数参数列表代表什么,返回值是什么,干的什么工作就可以了,不用了解具体实现,否则封装就没有了意义。弄清楚各个模块作用后,画出流程图,理解函数之间调用关系和顺序,然后逐步看具体实现。
所以新手一开始一定先要明白上面两张图和大概函数作用再看代码。
void accept_request(int);
处理从套接字上监听到的一个 HTTP 请求,在这里可以很大一部分地体现服务器处理请求流程。
void bad_request(int);
返回给客户端这是个错误请求,HTTP 状态吗 400 BAD REQUEST.
void cat(int, FILE *);
读取服务器上某个文件写到 socket 套接字。
void cannot_execute(int);
主要处理发生在执行 cgi 程序时出现的错误。
void error_die(const char *);
把错误信息写到 perror 并退出。
void execute_cgi(int, const char *, const char *, const char *);
运行 cgi 程序的处理,也是个主要函数。
int get_line(int, char *, int);
读取套接字的一行,把回车换行等情况都统一为换行符结束。
void headers(int, const char *);
把 HTTP 响应的头部写到套接字。
void not_found(int);
主要处理找不到请求的文件时的情况。
void serve_file(int, const char *);
调用 cat 把服务器文件返回给浏览器。
int startup(u_short *);
初始化 httpd 服务,包括建立套接字,绑定端口,进行监听等。
void unimplemented(int);
返回给浏览器表明收到的 HTTP 请求所用的 method 不被支持。
关于大部分代码注释来源:https://github.com/donkeywx/tinyhttpd/blob/master/tinyhttpd_source/tinyhttpd.c
一、先看main函数:创建一个用来监听的 sockfd(socket描述符)。在监听的过程中每建立一个连接,就创建一个线程去处理。
不过先得明白以下几点:
- accept函数返回值是什么意思:accept()函数成功时,返回非负整数,该整数是接收到套接字的描述符;出错时,返回-1,相应地设定全局变量errno。
- sockaddr_in结构体内容,可参考:socket编程——sockaddr_in结构体操作。
struct sockaddr {
sa_family_t sin_family;//地址族
char sa_data[14]; //14字节,包含套接字中的目标地址和端口信息
};
//socketaddr_in的改进:
struct sockaddr_in {
short int sin_family;
unsigned short int sin_port;
struct in_addr sin_addr;//struct in_addr{unsigned long s_addr;}
unsigned char sin_zero[8];
};
- 如果对线程创建不了解也不必可以看pthread相关,因为c++11后已经废弃pthread改用thread模版了。
int main()
{
int server_sock = -1;//server_sock是startup()函数返回的服务器套接字
u_short port = 0; //传入的端口为0
int client_sock = -1;//client_sock是accept()函数返回的客户端套接字
struct sockaddr_in client_name; //sockaddr_in数据结构用作网络编程函数的参数,指明地址信息。
int client_name_len = sizeof(client_name);
pthread_t newthread; //pthread_t用于声明线程ID
server_sock = startup(&port); //服务器端监听套接字设置
printf("httpd running on port %d\n", port);
/*多线程并发服务器模式*/
while(1)
{
/*主线程*/
//accept函数等待来自客户端的连接请求到达侦听描述符server_sock,第二个参数为填入客户端套接字地址(&client_name)
//返回一个已连接的描述符,若成功则为非负连接描述符,若出错则为-1
client_sock = accept(server_sock, (struct sockaddr *)&client_name, &client_name_len); //accept阻塞等待客户端连接请求
if (client_sock == -1) //accept未成功返回已连接描述符
error_die("accept"); //error_die函数将错误信息写到perror中。
/*派生新新线程用accept_request函数处理新请求*/
/*accept_request(client_sock);*/
//pthread_create为类Unix系统中创建线程的函数,成功则返回0,client_sock为向线程函数accept_request传递的参数
if (pthread_create(&newthread, NULL, accept_request, client_sock) != 0) //创建工作线程,执行回调函数accept_request,参数client_sock
perror("pthread_create"); //perror打印最近一次系统错误信息,此处为创建线程失败
}
close(server_sock); //关闭套接字,就协议栈而言,即关闭TCP连接
return 0;
}
二、按照main函数顺序看看startup函数具体工作:
在使用 bind 函数将 sockfd 和 sockaddr_in 绑定在一起时,有可能我们的 sockaddr_in 的端口号为0,此时在绑定的过程中就会动态为其重新分配一个可以使用的端口,随后我们使用 getsockname 获取被分配的端口号。
int startup(u_short *port)
{
int httpd = 0;
struct sockaddr_in name;
httpd = socket(PF_INET, SOCK_STREAM, 0); //创建服务器端套接字,成功但会非负,失败返回-1
//在代码中几乎都是本句的写法,这里注意PF_INET与AF_INET的区别(其实是可以混用的,是指不规范)
//AF_INET表明我们正在使用因特网
//SOCK_STREAM表示这个套接字是因特网连接的一个端点
if (httpd == -1)
error_die("socket");
memset(&name, 0, sizeof(name));
/*设置套接字地址结构*/
name.sin_family = AF_INET; //设置地址簇,sin_family表示address family,AF_INET表示使用TCP/IP协议族的地址
name.sin_port = htons(*port); //指定端口,sin_port表示port number,htons函数将主机的无符号短整型数转换成网络字节顺序
name.sin_addr.s_addr = htonl(INADDR_ANY); //通配地址,s.addr表示ip address,htonl将主机数转换成无符号长整型的网络字节顺序
if (bind(httpd, (struct sockaddr *)&name, sizeof(name)) < 0) //将httpd套接字绑定到指定地址和端口
//bind函数将name中的服务器套接字地址和套接字描述符httpd联系起来
//成功返回0,失败返回-1
error_die("bind");
if (*port == 0) //如果*port==0,则动态分配一个端口
{
int namelen = sizeof(name);
//在以端口0调用bind后,getsockname用于返回由内核赋予的本地端口号
if (getsockname(httpd, (struct sockaddr *)&name, &namelen) == -1) //getsockname用于获取套接字的地址结构
//在这里是以端口号0调用bind之后,用于返回内核赋予的本地端口号
//成功返回0,失败返回-1
error_die("getsockname");
*port = ntohs(name.sin_port); //网络字节顺序转换为主机字节顺序,返回主机字节顺序表达的数
}
if (listen(httpd, 5) < 0) //listen将httpd将主动套接字转化为监听套接字,之后可以接受来自客户端的连接请求
//5这个参数暗示了内核在开始拒绝连接请求之前,应该放入队列中等待的未完成连接请求的数量,通常设置为1024
error_die("listen");
return(httpd);
}
三、accept_request 函数:这个函数比较重要,用来解析并处理 http 请求。
看懂这部分需要对照http报文格式来看,http 报文分为请求报文和响应报文,建议搜索别的博客认真对照各个字段意思。以下两个例子请新手认真记住。
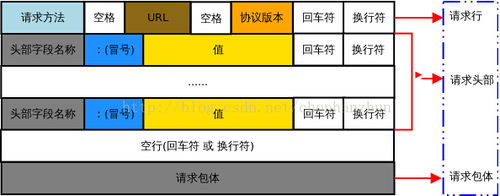
举一个本项目的例子:请求报文post为:
POST /htdocs/index.html HTTP/1.1 \r\n
Host: www.somenet.com \r\n
Content-Length: 9 \r\n
\r\n
color=red
响应报文格式为:
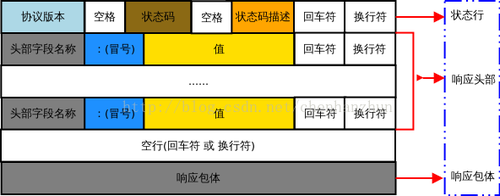
同样该项目例子为:
HTTP/1.1 200 OK \r\n
Content-Type:text/html \r\n
Content-Length: 362
\r\n
//以下表示页面内容
<html>
.....
详细代码解读,重点在于如何处理报文字符流:
void accept_request(int client)
{
char buf[1024];
int numchars;
char method[255]; //请求方法,GET或POST
char url[255]; //请求的文件路径
char path[512]; //文件的相对路径
size_t i, j;
struct stat st; //stat结构体是用来描述一个linux系统文件中文件属性的结构
int cgi = 0; //cgi标志位,用于判断是否是动态请求
char *query_string = NULL;
numchars = get_line(client, buf, sizeof(buf)); //从client中读取指定大小http数据到buf
i = 0; j = 0;
//接收客户端的http请求报文
//接收字符处理:提取空格字符前的字符,至多254个
while(!Isspace(buf[j]) && (i < sizeof(method) - 1))
{
method[i] = buf[j]; //根据http请求报文格式,这里得到的是请求方法
i++; j++;
}
method[i] = '\0';
//忽略大小写比较字符串,判断使用的是那种请求方法
if (strcasecmp(method, "GET") && strcasecmp(method, "POST"))
{
unimplemented(client); //两种支持的方法都不是,告知客户端所请求的方法未能实现
return;
}
if (strcasecmp(method, "POST") == 0) //如果是POST方法
cgi = 1; //设置标志位,Post表示是动态请求
i = 0;
while (ISspace(buf[j]) && j < sizeof(buf)) //过滤掉空格字符
j++;
while (ISspace(buf[j]) && (i < sizeof(url) - 1) && (j < sizeof(buf)))
{
url[i] = buf[j]; //得到URL(互联网标准资源的地址)
i++; j++;
}
url[i] = '\0';
if (strcasecmp(method, "GET") == 0) //如果方法是get
{
query_string = url; //请求信息
while ((*query_string != '?') && (*query_string != '\0')) //跳过?前面的字符
query_string++; //问号前面是路径,后面是参数
if (*query_string == '?') //得到问号,表明是动态请求
{
cgi = 1;
*query_string = '\0';
query_string++; //此时指针指向问号的下一位
}
}
//下面是项目中htdocs文件下的文件
sprintf(path, "htdocs%s", url); //获取请求文件路径
if (path[strlen(path) - 1 == '/') //如果文件类型是目录(/),则加上index.html
strcat(path, "index.html");
//根据路径找文件,并获取path文件信息保存到结构体st中,这就是函数stat的作用
if (stat(path, &st) == -1) //如果失败
{
//丢弃headers的信息
while (numchars > 0 && strcmp("\n", buf)) //
numchars = get_line(client, buf, sizeof(buf)); //
not_found(client); //回应客户端找不到
}
else //如果文件信息获取成功
{
//如果是个目录,则默认使用该目录下index.html文件,stat结构体中的st_mode用于判断文件类型
if ((st.st_mode & S_IFMT) == S_IFDIR)
strcat(path, "/index.html");
if ((st.st_mode & S_IXUSR) || (st.st_mode & S_IXGRP) || (st.st_mode & S_IXOTH))
cgi = 1;
if (!cgi) //静态页面请求
serve_file(client, path); //直接返回文件信息给客户端,静态页面返回
else //动态页面请求
execute_cgi(client, path, method, query_string); //执行cgi脚本
}
close(client); //关闭客户端socket
}
四、execute_cgi函数:
在看该函数之前回顾一下工作流程:
(1) 服务器启动,在指定端口或随机选取端口绑定 httpd 服务。
(2)收到一个 HTTP 请求时(其实就是 listen 的端口 accpet 的时候),派生一个线程运行 accept_request 函数。
(3)取出 HTTP 请求中的 method (GET 或 POST) 和 url。对于 GET 方法,如果有携带参数,则 query_string 指针指向 url 中 ? 后面的 GET 参数。
(4) 格式化 url 到 path 数组,表示浏览器请求的服务器文件路径,在 tinyhttpd 中服务器文件是在 htdocs 文件夹下。当 url 以 / 结尾,或 url 是个目录,则默认在 path 中加上 index.html,表示访问主页。
(5)如果文件路径合法,对于无参数的 GET 请求,直接输出服务器文件到浏览器,即用 HTTP 格式写到套接字上,然后跳到(10)。其他情况(带参数 GET,POST 方式,url 为可执行文件),则调用 excute_cgi 函数执行 cgi 脚本。
(6)读取整个 HTTP 请求并丢弃,如果是 POST 则找出 Content-Length. 把 HTTP 200 状态码写到套接字。
(7) 建立两个管道,cgi_input 和 cgi_output, 并 fork 一个进程。
(8) 在子进程中,把 STDOUT 重定向到 cgi_output的写入端,把 STDIN 重定向到 cgi_input 的读取端,关闭 cgi_input 的写入端 和 cgi_output 的读取端,设置 request_method 的环境变量,GET 的话设置 query_string 的环境变量,POST 的话设置 content_length 的环境变量,这些环境变量都是为了给 cgi 脚本调用,接着用 execl 运行 cgi 程序。
(9) 在父进程中,关闭 cgi_input 的读取端 和 cgi_output 的写入端,如果 POST 的话,把 POST 数据写入 cgi_input,已被重定向到 STDIN,读取 cgi_output 的管道输出到客户端,该管道输入是 STDOUT。接着关闭所有管道,等待子进程结束。
(10) 关闭与浏览器的连接,完成了一次 HTTP 请求与回应,因为 HTTP 是无连接的。
此处需要重点讲述一下7-9步骤的管道通信:
pipe函数用于创建一个管道实现进程间通信,int pipe(int fd[2]);通过pipe函数创建的两个文件描述符fd[0],fd[1]分别构成管道两端,fd[0]只能从管道读取数据,fd[1]从管道写入数据,建立双向数据传输需要使用两个管道。

(1)子进程负责运行cgi脚本;
(2)父进程负责从浏览器接收数据,并通过管道发送给cgi脚本处理;通过管道得到cgi脚本结果,并发送给浏览器。
不了解fork函数创建子进程的新手可以参考:fork()函数详解
void execute_cgi(int client, const char *path const char *method, const char *query_string)
{
char buf[1024];
int cgi_output[2];
int cgi_input[2];
pid_t pid;
int status;
int i;
char c;
int numchars = 1;
int content_length = -1;
buf[0] = 'A'; buf[1] = '\0';
if (strcasecmp(method, "GET") == 0) //GET方法:一般用于获取/查询资源信息
while ((numchars > 0) && strcmp("\n", buf)) //读取并丢弃头部信息
numchars = get_line(client, buf, sizeof(buf)); //从客户端读取
else //POST方法,一般用于更新资源信息
{
numchars = get_line(client, buf, sizeof(buf));
//获取HTTP消息实体的传输长度
while ((numchars > 0) && strcmp("\n", buf)) //不空,且不为换行符
{
buf[15] = '\0';
if (strcasecmp(buf, "Content_Length:") == 0) //是否为Content_Length字段
content_length = atoi(&buf[16]); //Content_Length用于描述HTTP消息实体的传输长度
numchars = get_line(client, buf, sizeof(buf));
}
if (content_length == -1)
{
bad_request(client); //请求的页面数据为空,没有数据,就是我们打开网页经常出现的空白页面
return;
}
}
sprintf(buf, "HTTP/1.0 200 OK\r\n");
send(client, buf, strlen(buf), 0);
//pipe函数建立管道,成功返回0,参数数组包含pipe使用的两个文件的描述符,fd[0]:读入端,fd[1]:写入端
//必须在fork中调用pipe,否则子进程不会继承文件描述符。
if (pipe(cgi_output) < 0)
{
cannot_execute(client); //管道建立失败
return;
} //管道只能具有公共祖先的进程间进行,这里是父子进程之间
if (pipe(cgi_input) < 0)
{
cannot_execute(client);
return;
}
//fork子进程,这样创建了父子进程间的IPC(进程间通信)通道
if ((pid = fork()) < 0)
{
cannot_execute(client); //创建失败
return;
}
/* 实现进程间的管道通信机制 */
//子进程继承了父进程的pipe,然后通过关闭子进程output管道的out端,input管道的in端;
//关闭父进程output管道的in端,input管道的out端
//管道分为有名管道和无名管道,这里使用的是无名管道,
//两个进程若不存在共享祖先进程则不能使用无名管道,这里是父子进程的关系
//有名管道可以在一个系统中的任意两个进程之间通信
//子进程
if (pid == 0) //这是子进程,用于执行cgi脚本程序
{
char meth_env[255];
char query_env[255];
char length_env[255];
//复制文件句柄,重定向进程的标准输入输出
//dup2函数在管道实现进程间通信中重定向文件描述符
dup2(cgi_output[1], 1); // 1表示stdout,0表示stdin,将系统标准输出重定向为cgi_output[1]
dup2(cgi_input[0], 0); //将系统标准输入重定向为cgi_input[0]
close(cgi_output[0]); //关闭cgi_output中的out端
close(cgi_input[1]); //关闭cgi_input中的in端
//cgi标准需要将请求的方法存储到环境变量中,然后和cgi脚本进行交互
sprintf(meth_env, "REQUEST_METHOD=%s", method);
putenv(meth_env); //putenv函数的作用是增加环境变量
if (strcasecmp(method, "GET") == 0) //get
{
//设置query_string的环境变量
sprintf(query_env, "QUERY_STRING=%s", query_string);
putenv(query_env);
}
else //post
{
//设置content_Length的环境变量
sprintf(length_env, "CONTENT_LENGTH=%d", content_length);
putenv(length_env);
}
execl(path, paht, NULL); //exec函数簇,执行cgi脚本,获取cgi的标准输出作为相应内容发送给客户端
//因为通过dup2完成了重定向,标准输出内容进入管道output的输入端
exit(0); //子进程退出
}
else //如果是父进程
{
close(cgi_output[1]); //关闭cgi_output中的in通道,注意这里是父进程的cgi_output变量,和子进程区分开
close(cgi_input[0]); //关闭cgi_input的out通道
/* 通过关闭对应管道的端口通道,然后重定向子进程的某端,这样就在父子进程之间构建了一条单双工通道
* 如果不进行重定向,将是一条典型的全双工管道通信机制
*/
if (strcasecmp(method, "POST") == 0) //post方式,将指定好的传输长度字符发送
/* 接收post过来的数据 */
for (i = 0; i < content_length; i++)
{
recv(client, &c, 1, 0); //从客户端接收单个字符
write(cgi_input[1], &c, 1); //写入cgi_input的in通道
//数据传送过程:input[1](parent) --> input[0](child)[执行cgi函数] --> STDIN --> STDOUT
// --> output[1](child) -- > output[0](parent)[将结果发送给客户端]
}
while (read(cgi_output[0], &c, 1) > 0) //读取输出内容到客户端
send(client, &c, 1, 0); //
close(cgi_output[0]); //关闭剩下的管道端
close(cgi_input[1]);
waitpid(pid, &status, 0); //等待子进程终止
}
}
至此我们项目的核心内容已经搞清楚了,其他函数可以参见参考链接9。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









