







knn算法概述
- KNN —— K Nearest Neighbors
- 监督学习
- 核心:采用测量不同特征值之间的距离进行分类
- 原理:存在一个训练样本集,已知样本集中每一数据的所属分类。当输入没有标签的新数据后,选择新数据与样本数据特征最相似(k近邻)的分类作为新数据的分类
knn算法流程
- 1、计算已经知类型样本集中的点与待分类点之间的距离
- 2、按距离递增次序排序
- 3、选取与当前点距离最小的 k 个点
- 4、确定前 k 个点所在类别出现频q率
- 5、返回前 k 个点出现频率最高的类别作为当前点的预测分类
图解
- KNN的原理就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别

- 图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。

- 但是,当K=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。从这个例子中,我们就能看得出K的取值是很重要的。
距离计算
- 欧式距离
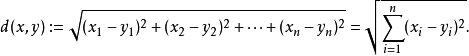
- 曼哈顿距离
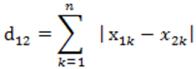
K值选择
- 1、靠经验
- 2、交叉验证 ( 将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据)
- 3、初始最小值
- 4、一般取奇数
knn算法特点
-
KNN是一种非参的,惰性的算法模型
-
非参的意思并不是说这个算法不需要参数,而是意味着这个模型不会对数据做出任何的假设,与之相对的是线性回归(我们总会假设线性回归是一条直线)。也就是说KNN建立的模型结构是根据数据来决定的,这也比较符合现实的情况,毕竟在现实中的情况往往与理论上的假设是不相符的。
-
惰性又是什么意思呢?想想看,同样是分类算法,逻辑回归需要先对数据进行大量训练(tranning),最后才会得到一个算法模型。而KNN算法却不需要,它没有明确的训练数据的过程,或者说这个过程很快。
knn算法优缺点
- KNN算法优点
- 1、简单易用,相比其他算法,KNN算是比较简洁明了的算法。即使没有很高的数学基础也能搞清楚它的原理。
- 2、模型训练时间快,上面说到KNN算法是惰性的,这里也就不再过多讲述。
- 3、预测效果好。
- 4、对异常值不敏感
- KNN算法缺点
- 对内存要求较高,因为该算法存储了所有训练数据
- 预测阶段可能很慢
- 对不相关的功能和数据规模敏感
















 933
933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









