






目录
一、关于KNN算法
1、对于KNN算法的理解
- KNN 的全称是 K Nearest Neighbors,意思是 K 个最近的邻居。KNN 的原理就是:当预测一个新样本的类别时,根据它距离最近的k个样本点是什么类别来判断该新样本属于哪个类别。
- 它的工作原理是利用训练数据对特征向量空间进行划分,并将训练集的划分结果作为最终算法的分类模型。存在一个样本数据集合,也称作训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的数据后,将这个没有标签的数据的每个特征与样本集中的数据对应的特征进行比较,然后提取样本中与其特征最相近的数据的分类标签。
- 一般而言,我们只选择样本数据集中前k个最相似的数据,这就是KNN算法中K的由来,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的类别,作为新数据的分类。如何选择一个最佳的K值取决于数据。一般情况下,在分类时较大的 K 值能够减小噪声的影响,但会使类别之间的界限变得模糊。因此 K 的取值一般比较小 (K<20)。
2、KNN算法的优缺点
1)优点
- 理论成熟,思想简单,易于理解,无需建模与训练,易于实现。
- 适合对稀有事件进行分类。
- 可以处理回归问题,也就是预测。
2)缺点
- 效率低,当数据集较大时计算复杂度较高。因为每一次分类或者回归,都要把训练数据和测试数据都算一遍,如果数据量很大的话,需要的算力会很惊人,但是在机器学习中,大数据处理又是很常见的一件事。
- 对训练数据依赖度特别大,虽然所有机器学习的算法对数据的依赖度很高,但是KNN尤其严重,因为如果我们的训练数据集中,有一两个数据是错误的,刚刚好又在我们需要分类的数值的旁边,这样就会直接导致预测的数据的不准确,对训练数据的容错性太差。
3、KNN算法的描述
(1)计算测试数据与各个训练数据之间的距离;
(2)按照距离的递增关系进行排序;
(3)选取距离最小的K个点;
(4)确定前K个点所在类别的出现频率
(5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
4、KNN算法的流程
(1)计算测试数据与各个训练数据之间的距离;
(2)按照距离的递增关系进行排序;
(3)选取距离最小的K个点;
(4)确定前K个点所在类别的出现频率
(5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
5、k值的选取
如下图所示,图中红色矩形就是我们要预测的那个点。假设K=3,那么KNN算法就会找到与它距离最近的三个点,判断哪种类别多一些,比如这个例子中是蓝色三角形多一些,这样红色矩形就归类到蓝三角形的类别。假设K=5,则同理可得,此时红色矩形被归类为橙色圆形的同类。
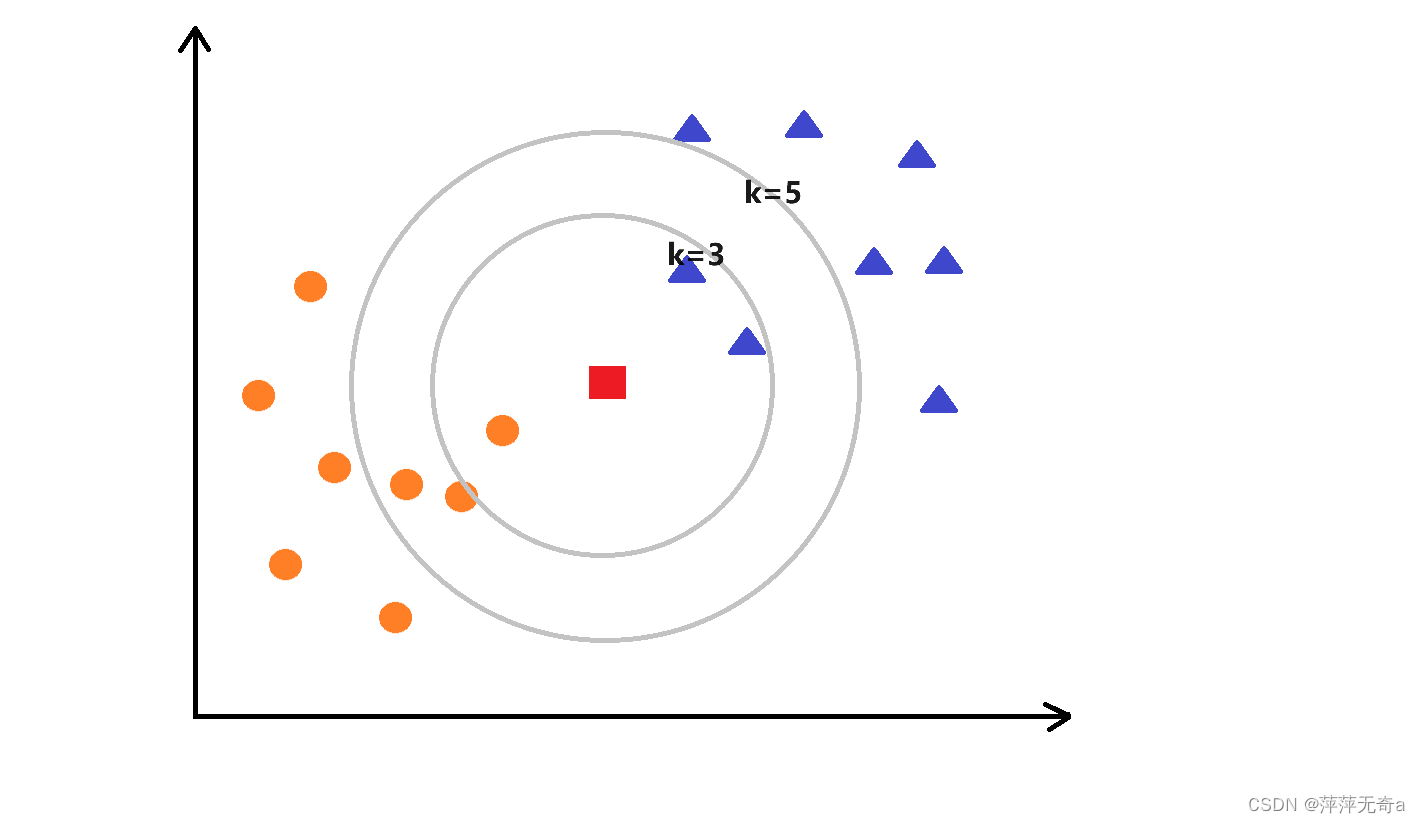
通过上面那张图我们知道K取值的不同会影响到样本点的归类,那么该如何确定K的取值。答案是通过交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据),从选取一个较小的K值开始,不断增加K的值,然后计算验证集合的方差,最终找到一个比较合适的K值。此次实验数据共150条,数据量并不多,不会存在较大的误差,因此个人采取的K值为3。如若需要得到具体K值如何求取可以看看其他关于K值求取的博客。
k值应该如何选取。——k=1的K近邻算法被称为最近邻算法,此时将训练集中与测试样本点最接近的点的类别作为测试样本的分类标签。
k比较小时:
优点:只有与输入实例较近的的训练实例才会对预测起作用。
缺点:因为参考的点很少,所以其“学习”的估计误差会增大,预测结果对近邻的点非常敏感。预测可能出错的概率比较大。
k比较大时:
优点:有效的减少“学习“的估计误差。
缺点:“学习”的近似误差会增加,此时离实例较远的点也会对预测起作用,使得出现预测错误的概率加大。其实K值加大意味着模型变得简单,如果K=样本点数,那么所有的测试点的类标签都是训练集中出现最多的那一类标签。
二、实验问题的引入与解决
- 基于对knn算法的学习,此次实验我从网络上查找了一些数据集,最终选定了比较经典的鸢尾花数据集来作为此次实验的数据集。这个数据集中一共有150条数据样例,共4个属性(萼片长度, 萼片宽度,花瓣长度, 花瓣宽度)。
- 我的数据集(点击可下载/查看)
- 原理:采用欧氏距离来计算不同数据样本之间的距离:
。
三、代码实现
1、导入所需要的库
- 导入一些需要用到的库
from sklearn import datasets # 从sklearn自带数据库中加载鸢尾花数据
from sklearn.model_selection import train_test_split # 引入train_test_split函数
from sklearn.neighbors import KNeighborsClassifier # 引入KNN分类器
from sklearn.metrics import accuracy_score2、数据集导入
- 设置训练集数据,目标
iris = datasets.load_iris() # 将鸢尾花数据存在iris中
iris_X = iris.data # 指定训练数据iris_X
iris_y = iris.target # 指定训练目标iris_y3、分割数据集
- 采用 train_test_split 用于分割数据集,设置测试集比例为30%
- X_train, X_test, y_train, y_test = train_test_split(train_data, train_target, test_size, random_state, shuffle)
- X_train:划分的训练集数据
- X_test:划分的测试集数据
- y_train:划分的训练集标签
- y_test:划分的测试集标签
- train_data:还未划分的数据集
- train_target:还未划分的标签
- test_size:分割比例,默认为0.25,即测试集占完整数据集的比例
- random_state:随机数种子,应用于分割前对数据的洗牌。可以是int,RandomState实例或None,默认值=None。设成定值意味着,对于同一个数据集,只有第一次运行是随机的,随后多次分割只要rondom_state相同,则划分结果也相同。
- shuffle:是否在分割前对完整数据进行洗牌(打乱),默认为True,打乱。
x_train, x_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.3)4、调用、训练分类器
- 采用自带的knn分类器对数据进行训练并预测测试集数据,输出最终结果。
knn = KNeighborsClassifier() # 调用KNN分类器
knn.fit(x_train, y_train) # 训练KNN分类器
y_pred = knn.predict(x_test)
print(y_pred) # 预测值
print(y_test) # 真实值
print("准确率:", accuracy_score(y_pred, y_test)) # 计算准确率四、实验结果
1、结果一

2、结果二

3、结果三

4、实验结果分析
实验结果输出的是测试集测试的准确率,但是实际上每次输出的结果都有所不同,因为训练集和测试集是随机划分的。
KNN算法是一个简单且有效的分类算法。它的原理是基于距离度量的分类方法,通过计算新数据点与已知数据点之间的距离来进行分类。在实现KNN算法时,需要确定K值和距离度量方法。
















 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











