







一、论文简述
1. 第一作者:Rafael Weilharter
2. 发表年份:2024
3. 发表期刊:WACV
4. 关键词:三维重建、MVS、熵滤波
5. 探索动机:几乎每个MVS方法都需要手动调整参数-通常是针对每个单独的场景-这可能是一项繁琐的任务。此外,融合是一个独立的、非学习的步骤,这使得很难评估网络的真实性能。
A photometric mask is often obtained by evaluating the probability weights of the network output, which is not explicitly learned.
For the geometric filtering, different fusion frameworks exist that project pixels into 3D space and have several similar parameters which can be tuned:
1) Interval scale. A parameter to influence the depth range in every view.
2) Consistent number of views. The number of source images that have to confirm the depth estimate to guarantee geometric consistency.
3) Back-projection error in pixels. The distance error when projecting one pixel into another view and back.
4) Relative depth error. The relative error of the back-projection in depth direction.
6. 工作目标:能够应用一组仅依赖于几何双视图一致性检查的融合参数从其深度图创建三维模型。
7. 核心思想:提出分层和内存高效的MVSNet,具有熵滤波重建(HAMMER)解决方案,无需繁琐的融合参数搜索,对训练的GPU要求非常低(大约6 GB)。
- A training method to produce a filter mask in addition to the required depth map. In contrast to many other methods, we directly learn these filter masks by applying our novel entropy-based loss at the output of a dedicated convolutional network block. This alleviates the problem of searching for the best parameters in the fusion step.
- We introduce randomized matched patches for the training phase. This allows us to use the full resolution of any available dataset without removing information by resizing images.
- We extend the multi-stage network design introduced by GBi-Net by an adjustable interval parameter ψ which enables the network to be trained on any arbitrary depth resolution without affecting the network’s memory requirements.
8. 实验结果:
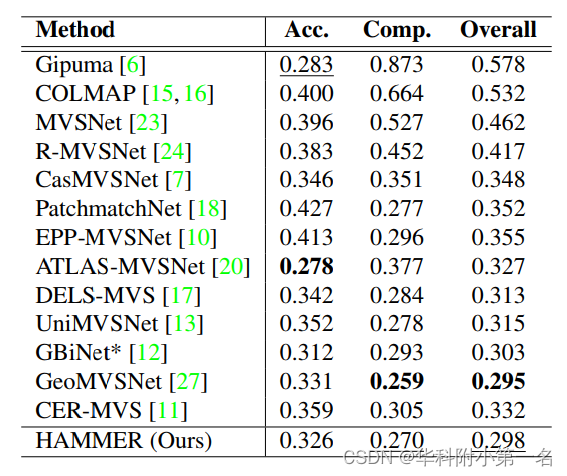
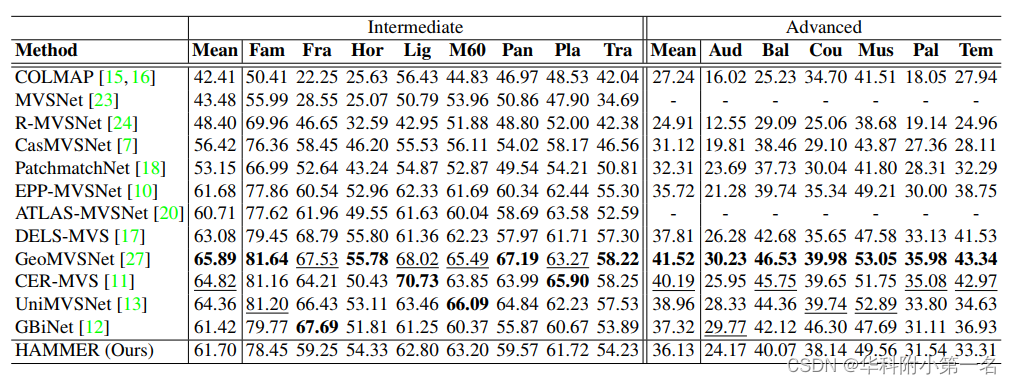
Additional to the traditional benchmark evaluations, we provide comparisons between network performances when the fusion parameters are kept at a fixed setting. We also conduct extensive evaluations to show that HAMMER ranks amongst the top methods on the DTU and the more challenging Tanks and Temples benchmarks when compared to the officially reported scores.
9. 论文下载:
二、实现过程
1. 概述
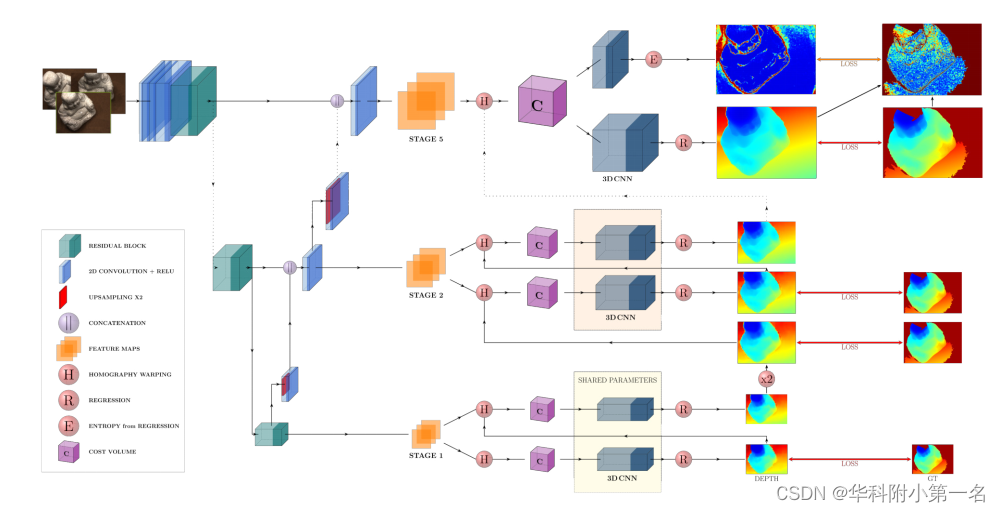
HAMMER结构如图所示。在实际训练网络之前,引入一种预处理技术,允许更灵活的MVS网络的内存训练,称之为随机匹配块。对于网络本身,从以前的网络中改编了几个表现出色的组件:首先,对参考图像及其n个源图像进行分层特征提取UNet,也被称为多尺度特征网,类似于以前的网络,如GBi-Net或ATLAS-MVSNet。设计网络的方式是,层次结构中最高层的输出分辨率为1/2的输入图像大小。然后,在正则化后扩张尺度为最终的代价体,以获得与输入图像相同的深度图分辨率。其次,单应性变形和深度初始化是用级联代价体公式完成的。扩展了该算法,并将每个特征阶段处理两次。第三,正则化每个特征阶段的2个代价体由可调间隔参数ψ定义的2种不同的深度分辨率,它设置独立于内存要求的任意深度分辨率。
2. 预处理:随机匹配块
当前可用数据的一个问题是,虽然相对高分辨率的图像(例如DTU有1600 × 1200)可用,在训练阶段使用全分辨率通常太占用内存。GBiNet提出在不增加训练开销的同时控制内存消耗的情况下,裁剪随机块进行训练以学习更好的特征。虽然对于像DTU这样定义良好的数据集来说,这种方法已经足够好了,但它无法在像BlendedMVS这样视点差异很大的数据集中获得重叠的块。因此,引入了随机匹配的块:从任何给定的参考图像中,在训练期间随机裁剪图像的一部分,使其适合网络的任意大小(在示例中512×512)。当真实深度图和相机参数已知时,可以将参考块的像素投影到源图像中。为了找到一个对应的块,首先在中心像素周围投影p个像素,并检查是否至少25%是有效的,即不在源图像之外或包含无效的深度值。然后,计算有效点的质心,得到源图像块的中心像素(见下图)。这个过程可以在线完成,对所有源图像重复进行,并保证块之间有明显的重叠。如果找不到有效的匹配,则在参考图像中随机选择一个新的块。在极少数情况下,这个过程会失败20次,跳过图像。

如果参考图像(左)和源图像(右)之间的视点发生了显著变化,那么在两幅图像中随机裁剪相同的块可能几乎没有重叠(红色方块)。RMP方法仅在参考图像中随机选择一个块,并将几个点(红色叉)投影到源图像中,以找到一个保证重叠的块(绿色方块)。
3. 特征提取
通过U-Net运行每个图像块,在不同分辨率的5个阶段分层提取特征。首先应用4个卷积层,依次将通道数量从3 (RGB图像)增加到32。为了缩小特征,使用由2个卷积层组成的残差块,第一层步长设为2。因此,最细粒度的特征图具有1/2全分辨率输入图像的大小,将最低尺度的特征进行放大,得到各阶段的特征图。这种设计确保了最大的代价体只需要覆盖正则化前输入图像分辨率的一半,这有助于保持3D CNN的低内存需求。
4. 代价体组装
根据之前的方法,利用单应性变化通过基于方差的形式构建代价体。为了控制代价体的大小,采用了GBiNet的策略,该策略使用两个级联的代价体,每个特征阶段只有4个深度假设。然而,在每次通过正则化网络后将深度间隔减半,这导致了固定深度分辨率的僵硬网络结构。本文引入了一个区间参数ψ,它允许在不改变网络内存要求的情况下自由选择深度分辨率。通过将整个深度范围除以4(基于每个代价体的4个深度假设)找到第一个深度区间后,可以简单地将该参数与之前的深度区间相乘以获得新的深度区间。为了达到细化每一阶段的深度间隔的目的,如下所示0 < ψ < 1。ψ = 0.55的值很好地适用于5级网络设计(每个阶段应用参数两次),这导致深度分辨率为0.25×0.55(10−1)≈0.001倍的全深度范围。
5. 网络输出
为了从代价体中去除噪声,将其通过一个由5个残差块组成的正则化网络,每个残差块包含2个卷积层。对于每个特征阶段,网络通过回归输出2张深度图。这些深度图用于初始化每个后续阶段的深度假设并计算损失。在最后阶段,还通过2个单独的残差块计算熵图。其思想是,高熵值表明网络对所有深度假设应用等概率,表明高不确定性。在训练阶段,通过施加额外的损失来强制执行这种行为。
6. 损失函数
首先,计算每个深度图的损失。由于每个特征图尺度的深度范围不同,得到了5个阶段的10张深度图。由于精细代价体的初始化必须使用深度图的放大版本,因此也将损失应用于放大版本。损失就是:
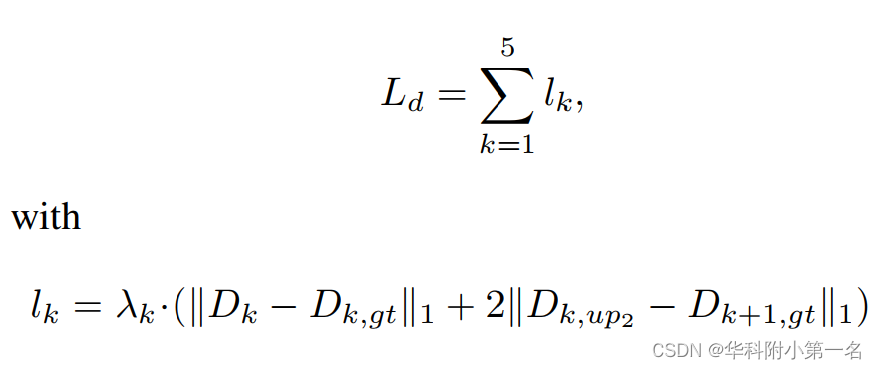
其中λk是一个权重因子,每一步增加2倍,Dk是当前阶段的输出深度图,Dk,up2为其放大版,Dk,gt为真实深度图。
如前所述,对于最终输出,还计算熵图。然而,由于网络是通过回归而不是分类来训练的,所以不能保证对于良好的深度估计熵是低的。这是由于这样一个事实,即良好的深度估计也可以通过概率的均匀分布来实现,这只是在回归中被视为不同的权重。然而,希望鼓励网络将单个强概率应用于正确的深度估计,从而使该方法更接近分类任务。
为了在正确的深度估计上强制执行低熵,在熵和深度误差映射ME = |Dk−Dk,gt|之间施加额外的损失,可以通过计算获得:
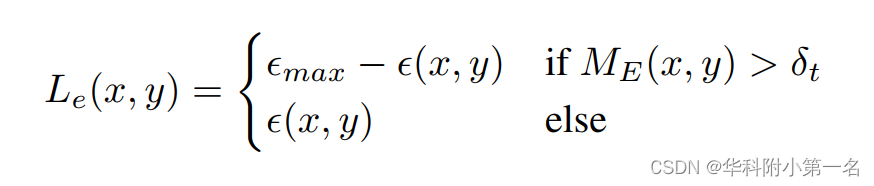
其中Le(x, y)是像素位置(x, y)的损失,e (x, y)是熵值,δt是深度图中误差的阈值。每个像素位置的熵e(x,y)定义为:
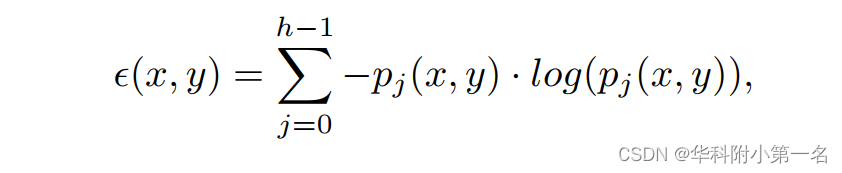
其中h为平面假设的个数,pj(x, y)为网络赋予每个假设平面j的概率。通过对所有假设设置相同的概率,可以得到理论的ϵmax。整个图像的熵损失是所有位置的均值。最后,总损失L计算为:
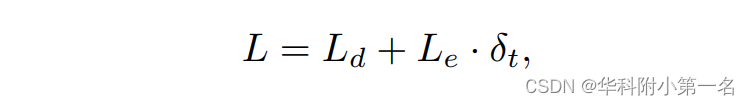
其中阈值δt作为加权因子来平衡损失。以这样一种方式计算阈值δt,它接近于每个视图中的最佳深度分辨率。
7. 后处理
和大多数网络一样,网络的最终输出是深度图。然而,基准测试通常只评估点云,即融合的3D模型。这是非常关键的一步MVS和基准测试结果在很大程度上取决于融合参数的正确选择。大多数方法通过尝试不同的设置来获得这些参数,这通常需要花费大量时间,并且如果需要评估许多不同的场景,这是不可行的。本文只使用熵掩模和一个简单的双视图一致性检查与固定的参数,直接评估深度图的质量。与大多数最先进的MVS网络相比,够通过对每个数据集和场景使用相同的设置来获得高质量的点云。
8. 实验
8.1. 实现细节
通过将输入块设置为512x512,该方法的训练只需要大约6gb的内存,在单个Nvidia GeForce GTX 1080 Ti上训练网络。为了测试,需要3.1 GB的DTU图像(1600×1152)和3.6 GB的Tanks and Temples的图像(1920 × 1024)。使用N = 5来评估DTU,使用N = 10来评估Tanks and Temples
时,性能会有所提高。一致的视图数设置为2,这意味着我们只检查单个源图像像素是否确认参考图像中的深度估计。请注意,这是一个非常不常见的选择,特别是对于Tanks and Temples数据集,其他方法经常使用6+视图进行几何验证,避免3D模型中的异常点。相信这是从学习熵中获得的滤波器掩模的一个优点。通过保持这个参数较低,可以在许多不同的场景中重建3D点,即使图像之间很少有重叠。反向投影误差和相对深度误差分别固定在0.2像素和0.001。
8.2. 与先进技术的比较




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











