







一、论文简述
1. 第一作者:Hongjie Li
2. 发表年份:2024
3. 发表期刊:AAAI
4. 关键词:三维重建、MVS、块匹配、可变形
5. 探索动机:PatchMatchNet和PatchMatch-RL这些方法遵循基于Patch的搜索思想,提高了搜索结果的效率和质量。然而,它们只是将传统的管道转化为可训练的管道,而没有充分考虑深度传播和扰动过程中场景内隐含的深度分布来指导深度假设采样。这个缺陷直接降低了深度估计的性能。尽管PatchMatchNet引入了CNN采样的可变性,但它仍然对底层深度分布不敏感。这将阻碍最优假设的采样,从而给后续的学习模块带来额外的负担。
6. 工作目标:关于假设采样的两个关键问题:(i)应该学习哪些隐式深度分布?(ii)如何利用学习分布来指导假设抽样?
7. 核心思想:本文提出了一种可学习的DeformSampler,将其嵌入到PatchMatch MVS框架中,以促进复杂场景下深度的准确估计。提出的DeformSampler可以在传播和扰动过程中对分布敏感的假设空间进行采样。
- We develop a learnable PatchMatch-based MVS network (DS-PMNet) embedded with DeformSampler to learn implicit depth distribution for guiding the deformable hypothesis sampling.
- A plane indicator is designed to capture piece-wise smooth depth distribution for structure-aware depth propagation.
- A probability matcher is designed to model the multimodal distribution of depth prediction probabilities for uncertainty-aware perturbation.
8. 实验结果:
Experimental results on DTU and Tanks & Temples datasets demonstrate its superior performance and generalization capabilities compared to state-of-the-art competitors.
9. 论文&代码下载:
https://github.com/Geo-Tell/DS-PMNet
https://arxiv.org/abs/2312.15970
二、实现过程
1. 概述
在PatchMatch MVS范例中,每个图像依次用作参考图像Ir,而其余图像作为源图像Is,以协助估计Ir的深度图。评估过程包括初始化、传播、评估和扰动阶段,后三个阶段迭代多次。在这项工作中,在四个不同的特征尺度上进行优化,每个尺度只有一次迭代。DS-PMNet框架如下图及算法所示。

首先为每个输入图像提取一个特征金字塔Ψ = {φl},以捕获低级细节和高级上下文信息,如下:

式中,Fθ为编码器,且r∈{1,…, L}为多尺度特征的指标。在本工作中,特征金字塔由4个尺度构成,记为L = 4,分别对应原始图像尺寸的1/8、1/4、1/2和1。为了避免混淆,在下面的内容中只描述一次迭代的四个阶段,即去掉下标l。
在阶段1中,随机初始化Ir的深度图D0。首先在逆深度空间中将已知深度范围划分为m0个区间。然后,在每个间隔为每个像素随机采样一个深度候选点。这意味着每个像素被分配了m0个候选点{dj}m0,这确保了真实的假设可以在有限的迭代次数下快速传播。
在第二阶段,平面指示器Pθ通过捕获对象表面的隐式分段平滑深度分布来指导结构感知假设的传播。Pθ对视图内特征一致性进行编码,以估计Ir的平面流场F。对于每个像素,F为样本假设提供了m1个相邻的共面点,从而得到一个可靠的假设集合{dj}m0+m1。
在第三阶段,概率匹配器Mθ通过对深度预测概率的隐式多模态分布建模,增强了{dj}m0+m1中深度候选点的评价,并输出预测不确定性以指导随后的扰动。Mθ首先生成一个多视图代价体S={Si},其中每个元素Si编码一个由深度诱导的单应性矩阵集{Hj}在φr和φs之间引入的匹配代价。然后,对Ir中的每一个像素点,从S中解码拉普拉斯混合分布{ψi}的参数集来预测深度图D,对应的不确定度映射集U={Ui}。
在第四阶段,使用推断的拉普拉斯混合分布来引导不确定性感知扰动,并对细粒度假设集合{dj}进行采样。然后,将此集合进一步输入到阶段二, m0←m2。
2. 可变形传播平面指示器
平面指示器Pθ对参考视图内特征的自相似性进行编码,在整个PatchMatch求解器下学习场景结构与深度的关系,从而解码一个平面流场F∈H×W ×2M表示场景的平面区域。该场包含M个偏移图,其中偏移图中的每个元素表示同一场景平面中一个位置与其相邻点之间的方向位移。偏移映射的示例如下图所示。(a)偏移量图以光流的形式可视化,其中颜色表示相对于当前像素的相邻点方向,而颜色强度表示偏移量大小。(b)弱纹理和物体边界区域的可变形采样示例。(c)平面流场的场景对齐分布评分。利用这个F,引导每个像素从m1(m1≤M)个相邻点中采样可靠的深度假设。Pθ由两个部分组成:视图内相关金字塔C = {Cl}和平面流解码器Dθ。

视图内相关金字塔结构。通过计算第l层特征图中的每个像素与其指定邻域内的所有像素之间的点积来生成每个Cl。搜索半径R1决定了邻域范围。具体地说,给定特征图φr, Cl∈H×W×R1中的每个元素cr(p,η)定义为:

式中,h表示第h个特征图的通道数,p是特征图像上的一个坐标,η为从这个位置的偏移量。偏移量被限制为∥η∥∞≤r1。符号[·]用于从特征图中提取特定坐标处的特征。每个关卡的搜索半径R1保持不变。因此,半径覆盖的是最上层最大的特征图区域,随着每一层的增加,半径逐渐减小。
平面流解码器。该解码器Dθ从金字塔中逐级推导出平面流场Fl∈H×W×2M,最终得到精细化的场F。解码器包含四个ConvBN-LeayReLU (CBL)块和一个预测器,如下图所示。在四个区块之间增加密集连接,增强信息交换。在这里,当输入来自不同金字塔级别的元素时,在预测器中进行了轻微的调整。在层l=1时,预测器给出一个粗平面流场F1∈H×W×2M。在随后的水平上,预测器产生残差F≈∈H×W×2来进一步细化粗场,即,

式中,p∈为场坐标,γ为上采样因子,1M为M×1单位矩阵。↑、[·]和⊗表示上采样、取操作和
Kronecker点积操作。

3. 形扰动的概率匹配器
设计了概率匹配器Mθ对深度预测概率的多模态分布进行建模,以指导扰动期间的细粒度采样。采用包含两个分量的拉普拉斯混合模型(K = 2)来解决这个多峰问题,即

其中ψ ={µ,α1, α2, σ1, σ2}为待估计的分布参数集,α1 + α2 = 1, y为特定像素的深度。两个分量的平均值µ设为相同,以确保只存在一个峰值。此外,通过通过设置σ1为常数,前者代表最准确的深度预测,并且施加约束σ2 > σ1 > 0,后者可以模拟较大的误差。下图显示了一个逐像素分布参数的示例。 颜色越亮表示值越大。物体边缘区域具有较高的不确定性,即较高的σ2。

概率匹配器。Mθ以视图间的代价金字塔作为输入,金字塔的每一层都包含一个由源图像引入的多视图代价体S = {Si}。对于金字塔的每一层,匹配器预测参考图像中每个像素的分布参数集{ψi},表示参考图像与不同源图像之间匹配的不确定性。详细的结构如图所示。

这个匹配器包含两个分支。在第一个分支中,S被编码为不确定性嵌入,然后对每个像素解码为σ2
,α1,α2。根据推断的参数,通过计算每个像素上的深度预测概率,可以得到参考图像与源图像之间的不确定性映射集U={Ui},即ui=P (|y−µ| < R2),
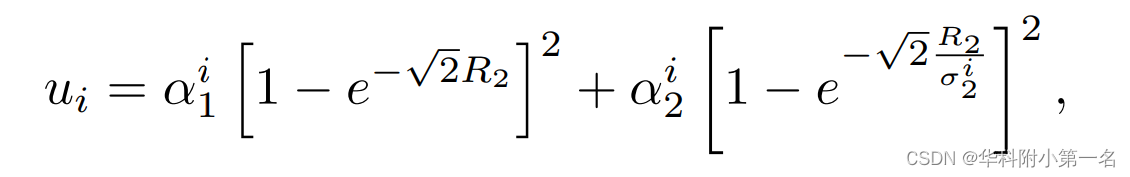
其中ui是Ui上特定坐标的元素,R2是决定真实值与预测深度图之间可接受偏差的超参数。利用可见性图{Ui},对UiSi进行求和,得到统一的代价体。 在第二个分支中,采用基于3D CNN的正则化器对统一的代价体进行处理以估计加权深度图D(µ)表示采样深度假设。
随机扰动。采用σ2来指导假设采样,因为它具有较高的匹配不确定性。首先将不同视角的方差求和为一个统一的值E(σ2) = ∑uiσ2i。然后,定义每个像素的采样空间为[µ±εE(σ2)],其中ε为超参数。然后,将这个范围分成m2个bin,每个bin包含相同比例的概率质量。这确保了具有低不确定度样本候选的像素更接近µ,而具有高不确定度样本的像素更分散的候选来校正µ。随后,将每个bin的中点作为潜在深度候选点进行采样。因此,第j个深度候选者定义为:

其中Φ(·)用于将累积概率转换为拉普拉斯分布的坐标,m2为bin的数量,P≈是范围覆盖的概率质量

4. 损失函数
首先计算了所有预测深度图{Dl}与真值之间的损失Ldepth = ∑||Dgt−D L||。然后,采用负对数似然损失LNLL来监督拟合的混合拉普拉斯分布,即

因此,总损耗Ltotal定义为Ltotal = λ1Ldepth +λ2LNLL,其中λ1、λ2是权重因子。
5. 实验
5.1. 实现细节
对于训练,使用6张512×640的DTU图像作为输入。在评估DTU时,使用6个输入图像
1152×1600分辨率(N=6)。对于Tanks and Temples数据集,N设置为8,图像分辨率为1024×1920。
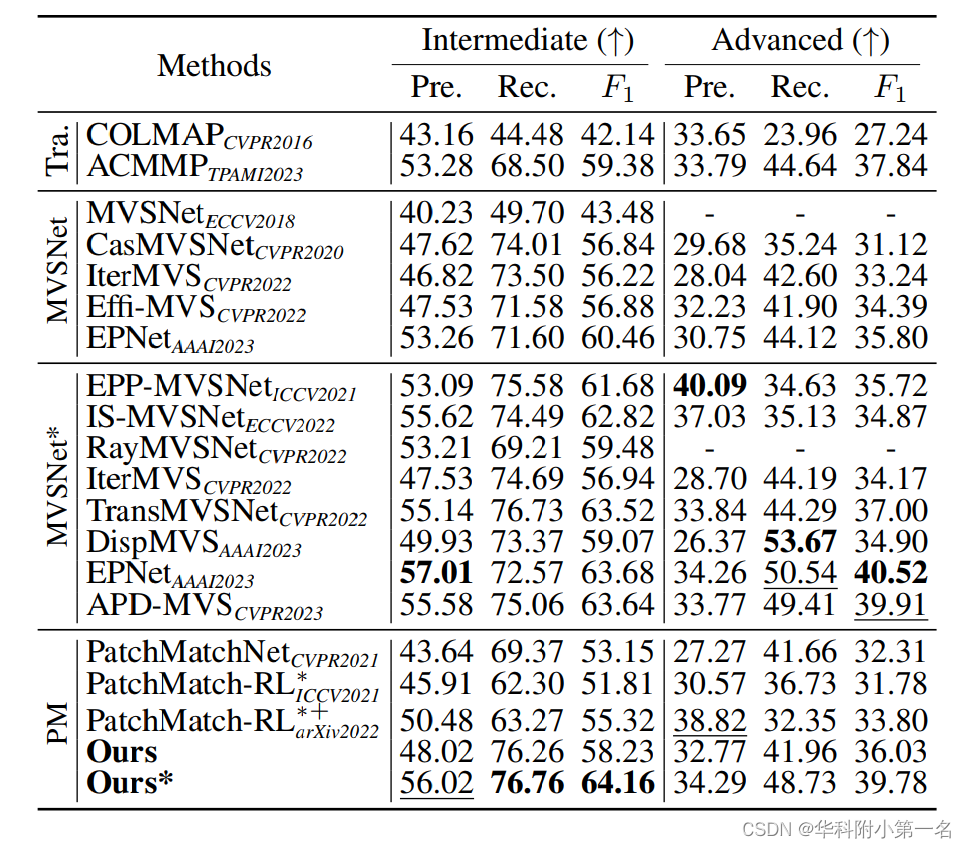
5.2. 与先进技术的比较
















 1157
1157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











