







一、论文简述
1. 第一作者:Vibhas K
2. 发表年份:2024
3. 发表期刊:WACV
4. 关键词:三维重建、MVS、多尺度视图、几何一致性检查
5. 探索动机:现代方法使用平面扫描体隐式编码几何约束,并执行多视图几何一致性检查作为推理后的后处理来过滤深度图。然而,在学习过程中没有明确地模拟多视图几何约束。相反,学习多视图几何信息只能隐式地发生。
6. 工作目标:解决上述挑战。
7. 核心思想:首次展示了在训练期间使用跨多个源视图的几何一致性检查为模型提供明确的多视图几何线索(见下图),显著提高了准确性,同时显著降低了训练迭代要求。
- We propose a novel multi-view, multi-scale geometric consistency (GC) module during learning that encourages geometric consistency of reference view depthmaps across multiple source views.
- We show that this technique reduces the training iteration requirements to nearly half that of other models, by explicitly providing multi-view geometric cues during learning.
- We show that the module is highly general and can be plugged into different MVS pipelines to enhance geometric cues during training.
8. 实验结果:
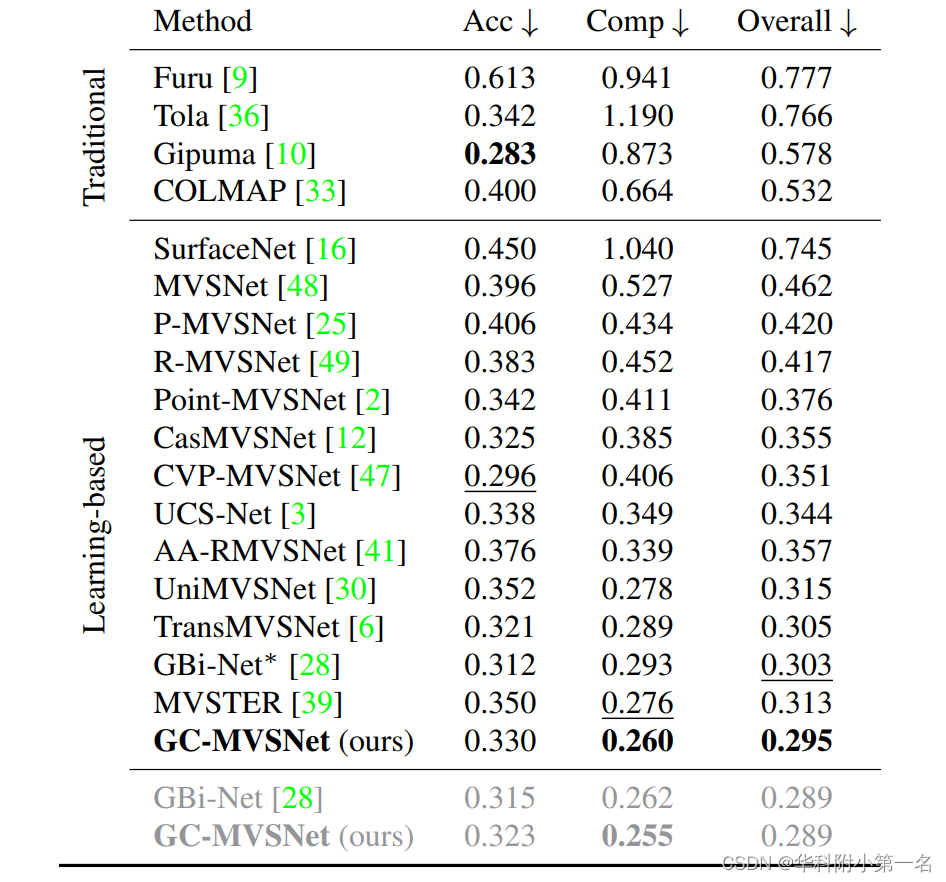
- Our approach also achieves a new state-of-the-art accuracy on DTU and BlendedMVS datasets, and competitive results on Tanks and Temples.
- To the best of our knowledge, GC-MVSNet is the first attempt to leverage multi-view, multi-scale geometric consistency checks during the training process.
9. 论文下载:
https://arxiv.org/abs/2310.19583
二、实现过程
1. 概述
下图显示了方法的架构,称之为几何一致性MVSNet(或GC-MVSNet)。使用基于可变形卷积的特征金字塔网络(FPN)架构从输入图像中以粗到精的方式在三个阶段提取特征。在每个阶段,使用形状为N×H'×W'×C的特征图构建形状为H'× W'×D'×1的基于相关性的代价体,其中H',W'和C表示给定阶段的高度,宽度和通道数量,并且D为相应阶段深度假设的个数。用代价正则化网络对代价体进行正则化。使用赢家通吃的策略来估计每个阶段的深度图D0。在粗阶段,使用线性注意力的特征匹配来利用参考和源视图特征内部和之间的全局上下文信息。
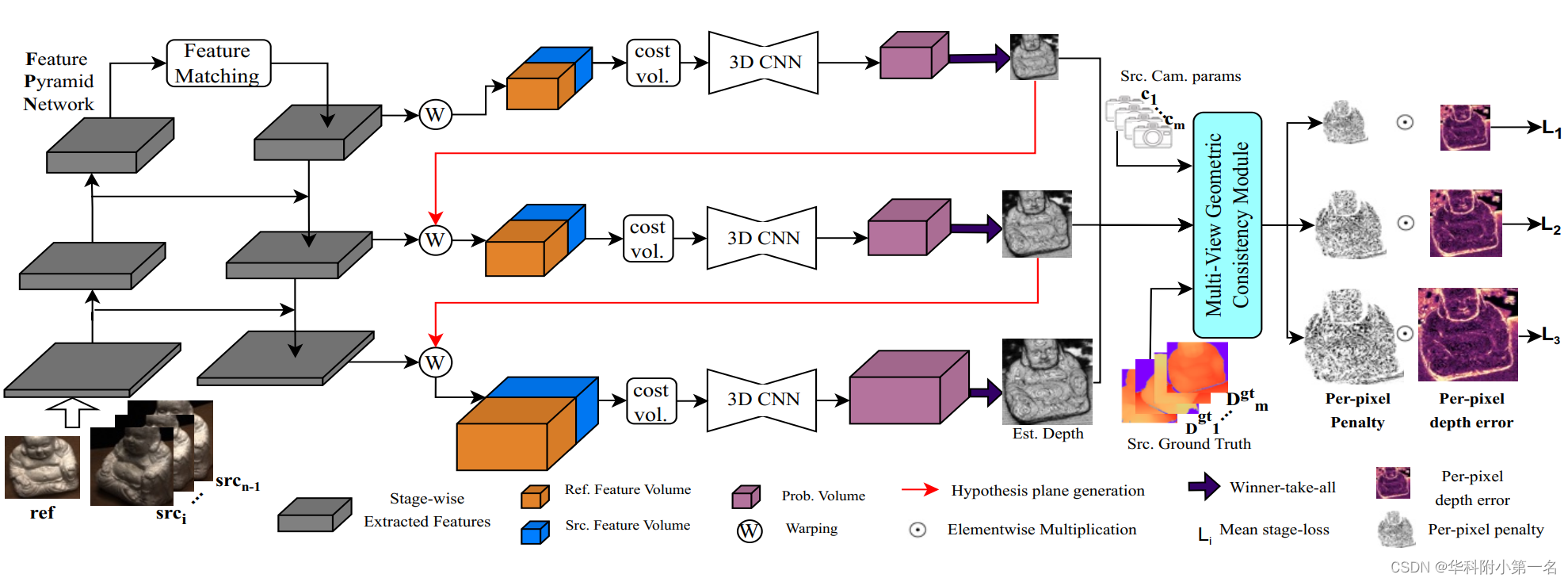
在每个阶段都使用GC模块。GC模块检查M个源视图中D0中每个像素的几何一致性,并生成ξp,这是一个像素因子,使用交叉熵函数计算,乘以每像素深度误差(ξd)。它惩罚D0中的每个像素在M个源视图中的不一致性,以加速训练期间的几何线索学习。TransMVSNet用交叉熵损失训练(TransMVSNet-B)是基线。
2. 多视图几何一致性模块
GC-MVSNet在三个不同分辨率的阶段估计参考深度图。在每个阶段,GC模块取深度图D0, M个源视图的GT深度和他们的相机参数作为输入。然后在每个阶段初始化GC模块,使其几何不一致性掩码和(或掩码总和)为零。这个掩码累加了M个源视图中每个像素的不一致性。对于每个源视图,GC模块执行D0的forward-backward重投影以生成惩罚,然后将其添加到掩码总和中。如下算法所示,forward-backward重投影(FBR)是一个至关重要的三步过程。

首先,使用内部(KR, KS)和外部(ER, ES)相机参数投影D0的每个像素P0到它的第i个邻源视图,得到相应的像素Pi’,并将相应的深度图表示为D(R→S)。其次,同样重新映射源视图的Digt以获得DSremap。最后,利用相机的内外参数将DSremap重新投影回参考视图,得到D′′P′′0。D0和D′′P′′0表示像素P0和P0′′的深度值。P0′′和D′′P′′0,计算像素位移误差(PDE)和相对深度差(RDD)。PDE是P0和P0之间的L2范数,RDD是D0和D′′P′′0之间的绝对值差。,如公式1所示。

对于每个阶段,生成两个一致性像素的二进制掩码,PDEmask和RDDmask,通过应用阈值Dpixel和Ddepth,然后对两者进行逻辑或运算,以产生不一致像素的单个掩码。这些不一致的像素被赋值为1,所有其他像素,包括一致的和超出范围的像素,被赋值为0,以形成惩罚掩码。然后将这个惩罚掩码添加到掩码和中,它将M个源视图中的每个视图的惩罚掩码累加起来,生成一个值∈[0,M]的最终掩码和。每个像素值表示M个源视图中像素不一致的数量。
掩码和为每个像素生成不一致惩罚ξp。初始方法生成通过将掩码和除以M来归一化[0,1]。然而,使用ξp本身进行元素乘法将完全一致(零不一致)像素的贡献减少到零,从而阻止了这些像素的进一步改进。为了避免这种情况,添加1使得ξp的元素在[1,2]中。对初始的ξp施加参考视图二进制掩码,生成最终的ξp,如下图所示。

遮挡及其影响。遮挡像素在多视图立体中自然产生,因为3D点通常不是在所有视图中都可见。这些被遮挡的像素对几何约束有很大的影响,因为其对应的3D点被遮挡的参考视图像素被视为不一致。 因此,防止遮挡像素主导几何一致性损失是很重要的。虽然遮挡有时被明确建模,但由于以下三个考虑因素,该方法对遮挡具有天然的鲁棒性。首先,选择MVSNet中定义的最接近的M源视图以最小化不同源视图中遮挡像素的数量。然后,在FBR期间,重新映射Digt得到DSremap,进行反向投影。重新映射和反向投影在很大程度上处理了极端情况下的遮挡。最后,在上图的ξp上应用参考视图二进制掩码,将惩罚限制在有效的参考视图像素。这些步骤的组合帮助处理遮挡像素和损失爆炸。
3. 代价函数
大多数基于学习的MVS方法将深度估计视为回归问题,并在预测和真实值之间使用L1损失。延续AARMVSNet和UniMVSNet,将深度估计视为一个分类问题,并采用AA-RMVSNet的交叉熵损失公式。在每个阶段计算像素惩罚ξd,
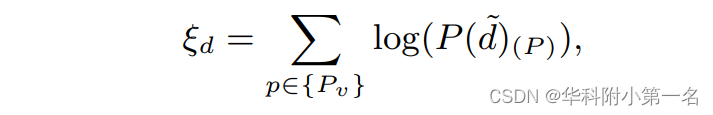
其中{Pv}为具有有效地真值的像素子集,P(d ~)(P)表示深度假设d在像素P处的估计概率,d~表示所有假设中最接近真值的深度值。通过惩罚每个像素在不同源视图中的不一致性来进一步增强one-hot监督。每个阶段的ξd和ξp使用元素之间的乘法(⊙)。平均阶段损失Li计算为:
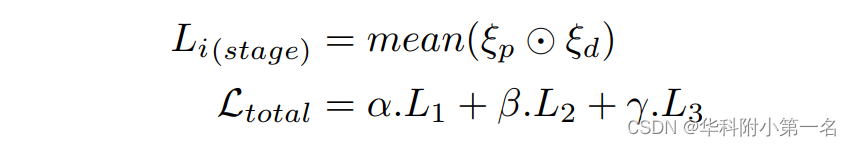
式中Li(stage)为平均阶段损失,Ltotal为总损失。α, β和γ是阶段权重。这种带有像素级不一致惩罚的代价函数公式明确地迫使模型学习生成多视图几何一致的深度图。
4. 其他的修改
除了几何一致性模块,还对MVS管道进行了另外两个主要修改。首先,在保持特征提取网络结构为FPN的同时,将其卷积层替换为可变形层。已知可变形层会根据模型要求调整采样位置。这有助于提取更好的特征来加速学习。
其次,大多数MVS方法在训练过程中使用批归一化和批同步。如文献[14]所观察到的,批归一化在大批的训练中提供了更一致和稳定的训练,但在小批的训练中,它是不一致的,并且有降级的影响。MVS方法被限制为非常小批处理大小,通常为1,因为需要大量内存。因此,在整个网络中用组大小为4的组规范化层代替批规范化。组归一化在多个通道上执行归一化,而这些通道与批处理中的示例数量无关。还对网络中的所有层实现了权值标准化。
5. 实验
5.1. 实现细节
在8个NVIDIA RTX A6000 GPU上训练模型,批处理大小为3,使用约9小时。采用Fusibile算法进行深度融合。
4.2. 与先进技术的比较
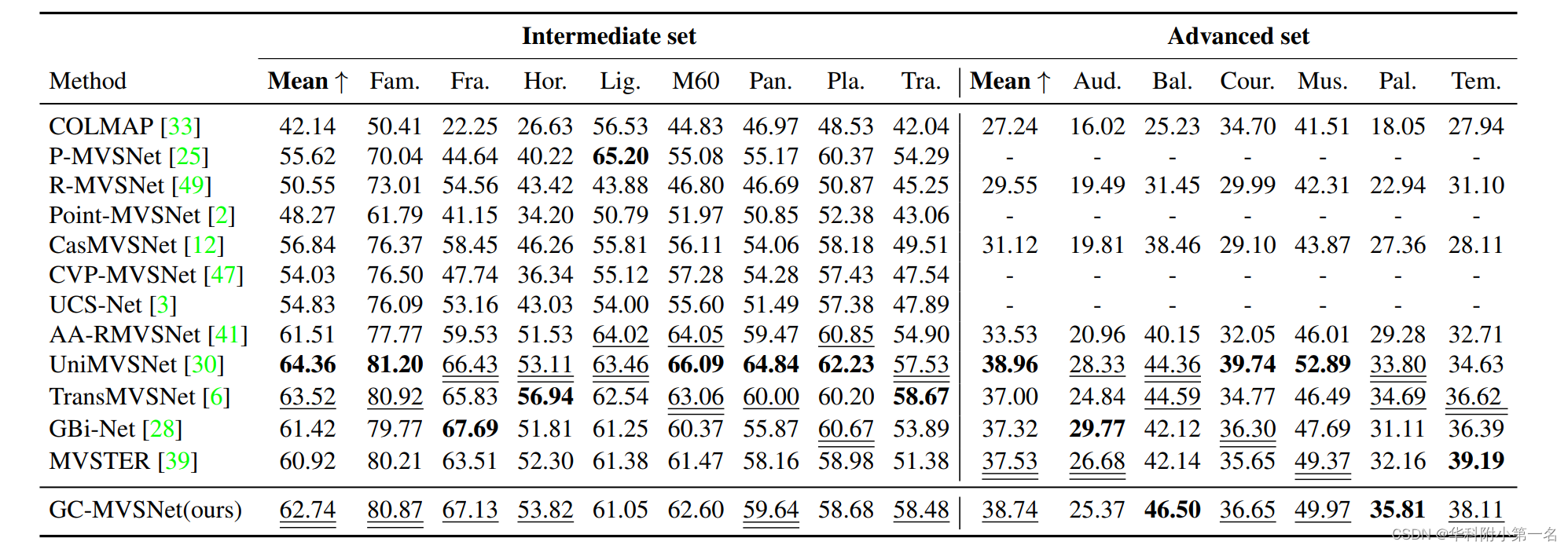
6. 限制
像任何其他MVS方法一样,GC-MVSNet在学习过程中需要超参数调优。深度间隔比、阶段深度假设数、初始深度假设数、深度间隔衰减因子等超参数影响模型性能。GC模块的超参数Dpixel、Ddepth和M也需要调优才能达到最佳性能。随着GC模块的超参数,真值的质量也直接影响其性能,因为它使用源视图真值深度图进行多视图几何一致性检查。



















 6277
6277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











