









留个笔记自用
xMUDA: Cross-Modal Unsupervised Domain Adaptation for 3D Semantic Segmentation
做什么
Instance segmentation实例分割

目标检测( Object detection)不仅需要提供图像中物体的类别,还需要提供物体的位置(bounding box)。语义分割( Semantic segmentation)需要预测出输入图像的每一个像素点属于哪一类的标签。实例分割( instance segmentation)在语义分割的基础上,还需要区分出同一类不同的个体。

这里就是从2D图像的分割转移到了点云上的分割,无非就是在位置信息上多了一维
做了什么

跨模态算法,2D图像和3D点云共同作用于3D语义分割,这里是分离了2D和3D的私有信息和共享信息,然后进行相互学习。
上图展示的是对比的结果,单单只有2D图片的分割效果和只有3D点云分割效果均有问题,而二者结合进行的分割效果较好。
在此之上,还使用了无监督的方法来进行算法模型的训练。
怎么做

首先还是定义一下输入和输出,源数据集S,每个样本包含一个2D图片x2d∈R(H,W,3)和一个3D点云x3d∈RN×3和对应的3D分割标签y3d,还有一个目标数据集T,包含的样本内容和上面相同,但没有标签y。
然后就是具体的结构实现
首先2D图片和3D点云都需要经过一个feature extractor来提取特征,2D采用的是Resnet,3D采用的是Unet,二者都结合上了稀疏卷积
稀疏卷积
分别得到两个feature map
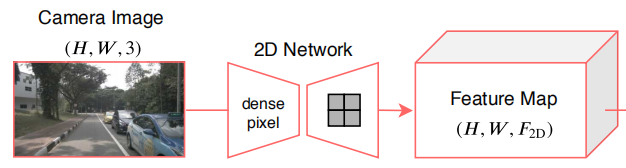
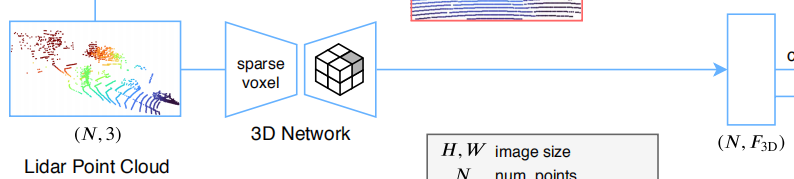
然后在两个feature map后加一个全连接层,再接上一个softmax得到各自点的分割结果(也就是分类结果)
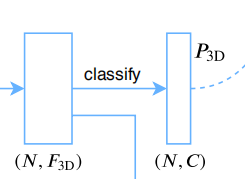
这里稍微有点区别的就是2D图片如果要获得3D的feature map的分类结果,还需要结合点云映射下的2D图,然后再sample至N个点的特征情况

同时这里为了建议2D和3D的联系,设计了一个模仿损失,比如利用2D得到的feature map去模拟3D点云的分割结果,也就是使用当前模态去模拟另一个模态的输出,一个跨模态优化目标将两个模态的输出对齐。

这里设计的方法也就是构造了四个分割头,两个各自输出各自模态下的分割结果,另外两个模拟另外一个模态下的分割结果
然后是网络训练的LOSS
首先是3D分割的结果LOSS,Lseg,这个LOSS是在源数据上计算的
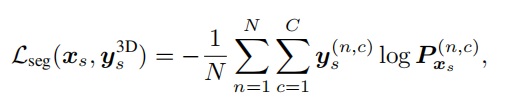
这里是采用的cross-entropy的形式,x可以是2D图片也可以是3D点云,P就是预测的逐点结果,y是点分割的GT
然后是跨模态学习的LOSS,这里是无监督学习的一个双重LOSS,一个LOSS是希望做到前面的2D和3D的转模态适应,Lxm
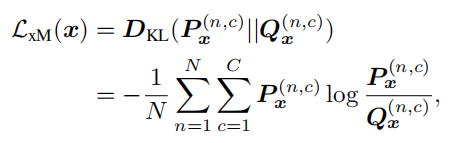
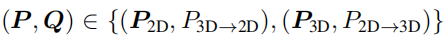
其中P是主要预测的目标分布,将通过模拟预测Q进行估计,简单来说,这里就是双重匹配,P2D是2D的branch预测的概率,P2D->3D是用2D图像跨模态预测3D的branch的概率,另外两个同理,这里要做的就是使任意两者尽可能相似,做到无监督跨模态的效果

然后
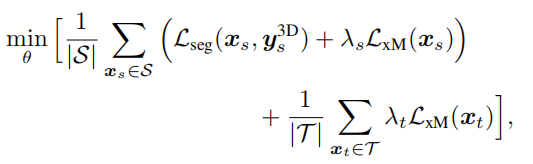
这里的意思是在源数据集上使用需要GT的Lseg来进行训练,跨模态损失Lxm作为一种辅助,而在没有GT的目标数据集上使用Lxm直接进行拟态训练
在此之外,这里还设计了一种附加的方法
在使用上式在源数据集和目标数据集上训练过后,使用训练完的模型在目标数据集上进行预测,预测出来的结果作为Pseudo-Labels伪标签,然后将其作为GT进行训练
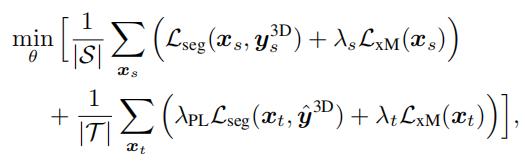

总结
1.一种常见的监督后无监督后自监督的方法,框架的构造方式值得学习,挺有意思的,感觉所有跨模态的做法都可以这么做成互相预测异模态的方式















 450
450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









