






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
摘要
在本次的机器学习课程中学习的内容主要分类两部分,VAE模型以及Flow-based生成模型。在对VAE模型学习过程中,了解VAE与Auto-encoder之间存在着差异,相比之下也有着很大的提升;对VAE的工作原理以及其与Gaussian Mixture Model的关系有了大致了解。在Flow-based生成模型中,学习了其与真实数据之间的模仿过程,对模型的优化与VAE一样也是通过不断优化Likelihood的过程,其中对Jocobite矩阵计算的优化更是优化过程的重中之重。
Abstract
The content learned in this machine learning course is mainly divided into two parts: VAE model and Flow based generation model. In the process of learning VAE models, understanding the differences between VAE and Auto encoder has greatly improved; I have gained a general understanding of the working principle of VAE and its relationship with the Gaussian Mixture Model. In the Flow based generation model, we learned the imitation process between it and real data. The optimization of the model, like VAE, is also achieved through continuous optimization of the Likelihood process, with the optimization of the Jocobite matrix calculation being the top priority of the optimization process.
提示:以下是本篇文章正文内容,下面案例可供参考
一、VAE理论
1、VAE与Auto-encoder
VAE在本质上看与Auto-encoder的大致结构是相同的,都是拥有着一个Encoder以及一个Decoder,将输入经过两个单元处理后得到一个相应的输出。但是VAE的工作过程在其中有些许差异,VAE是在输入的数据中加入noise,然后再让加入noise的数据进行处理输出。
详细的步骤为,输入的数据经过Encoder处理得到两个向量mi和
σ
\sigma
σi,除此之外还从normal distribution中的产出一个向量ei,紧接着将这些向量进行这样的处理得到ci,ci = exp (
σ
\sigma
σi) x ei + mi,其中exp (
σ
\sigma
σi) x ei便是加入的noise此外为了让输入和输出越接近,给出了一下限制条件,使式子
∑
n
i
=
0
\underset{i=0}{\overset{n}{\sum}}
i=0∑n exp (
σ
\sigma
σi) - ( 1 +
σ
\sigma
σi ) + ( mi )2 达到最小。
2、VAE对于Auto-encoder的提升
- Auto-encoder的不足之处:生成的数据是一一对应,而无法做到两组相近的数据达到一个渐变效果。就比如一张满月的照片,以及弦月的照片,在Auto-encoder中无法在两者数据之间有效地得出一张介于满月以及弦月的照片,因为这些数据都是一一对应的,很难预测两组数据之间的数据的表现形式。
- VAE相比之下的提升:VAE在转化的过程中,会在数据中加入noise,从而让某个范围内的数据的输出都表现为该数据,这样当两组加入noise后范围增大的数据会形成一个交集,这样就能获得一个渐变的数据,实现Auto-encoder无法做到的情况。但是需要注意的是因为加入的noise是机器自己学习的,机器可能会存在偷懒的情况,让参数 σ \sigma σi变为0,从而无法加入noise,因此需要限制条件,使式子 ∑ n i = 0 \underset{i=0}{\overset{n}{\sum}} i=0∑n exp ( σ \sigma σi) - ( 1 + σ \sigma σi ) + ( mi )2 达到最小。
3、VAE过程的再理解
从上面小点可以知道,VAE整个的工作流程是将输入数据加入noise后,再通过Decoder将数据解码出来。换一个思路对这个过程的理解,就是不同的Distribution之间的转换,由开始输入数据的Distribution
经过添加noise得出一个新的Distribution,最后在经过转化得出一个与原来大致一样的Distribution。接下来的问题就应该是如何对这个Distribution用函数进行描述。
4、Gaussian Mixture Model
目标Distribution的函数P(x)可以理解为一个由多个Gaussian合成的集合体,由多个Gaussian进行sample后,由这些sample进行融合得出目标P(x),从这个角度上看,x是属于一个Cluster,在这些cluster中sample出对应的x构成P(x)。

5、VAE的Gaussian Mixture思路实现
- 由于Distributed representation的表现是优于Cluster的,实际上是x并不属于某个Cluster,而是由一个向量来描述它在不同方向的特性。因此VAE就是Gaussian Mixture在Distributed representation上的版本。
- 要实现这样的过程,首先要挑选出向量z,z是来自一个normal distribution,其也可以由一个Gaussian来表示,其的每个维度都表示着一个特性。假设z是如下图这样的Gaussian曲线,对z曲线,得到x/z ~ N ( μ \mu μ(z) , σ \sigma σ(z) ) ,其中 μ \mu μ(z) ,和 σ \sigma σ(z) 都是由一个神经网络计算出来的,这样得到多个Gaussian 进行合并便能得到最终的目标函数,即P(x) = ∫ \int ∫ z P(z)P(x/z) dz。
- 因为z也是也是一个Gaussian,因此需要利用神经网络得到 μ \mu μ’(x) 和 σ \sigma σ’(x)来sample出z。之后通过不断调整参数 z 来求出这个实际需要的 μ \mu μ(z) 和 σ \sigma σ(z)来获得最后的 P(x)。要找到 μ \mu μ(z) 和 σ \sigma σ(z)就需要通过已有的数据 x 求 L = ∑ x \sum_x ∑xlog P(x)的最大可能性来得出。

6、Maximizing Likelihood
对log P(x)进行如下推导可以得到 log P(x) = Lb + KL( q (z/x) || p (z/x) ),KL( q (z/x) || p (z/x) )表示的是 q (z/x) 与 p (z/x) 之间的距离,所以该值就必须是大于等于0。于是要Maximizing log P(x)就转化成了Maximizing Lb,通过不断调整 q (z/x) 使其增大,在不断优化的过程中 q (z/x) 会不断接近直到与p (z/x) 重合。这样KL距离就变成0,让log P(x) = Lb 。于是再对 Lb 优化过程进行细化,可以变成
∫
\int
∫ z q(z/x) log P(x/z) dz - KL( q(z/x) || P(Z) ) ,问题最后也就变成了Maximizing
∫
\int
∫ z q(z/x) log P(x/z) dz 以及 Minimizing KL( q(z/x) || P(Z) ) 。

对于 KL( q(z/x) || P(Z)),其实就是调整 x 进入q函数对应的NN’得到的过程
μ
\mu
μ’(z) 和
σ
\sigma
σ’(z)的过程,使其与normal distribution P(z)的距离到最小。对于
∫
\int
∫ z q(z/x) log P(x/z) dz ,其实就是在q(z/x) 中sample一些数据z使得log P(x/z) 的值最大。这两个过程也就对应着下图的过程。

7、VAE的问题
由前面的学习可以知道,VAE的工作原理是让生成的数据与实际图像尽可能相似,尽可能不断优化两者之间的差距,实质上就是一个模仿的过程。在这个模范的过程中对细节的处理往往都是不到位的,因为其不是真正意义上的生成以假乱真的数据集,在某些地方还是能看出模仿与生成之间的差距的,比如下图对某个像素的处理,一个是7下沿的延续,另外一个则是放到与7无关的位置,但是VAE认为这两张图的差距不会很大,这也就是VAE模仿与生成之间的细节处理不到位的缺点。

二、Flow-based生成模型
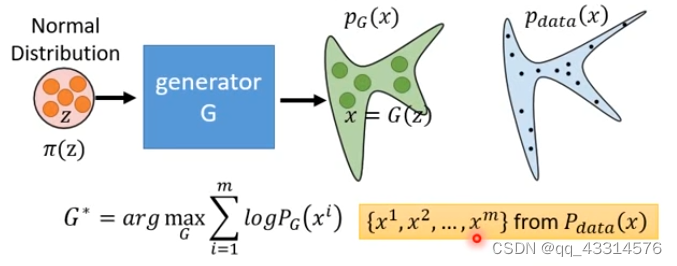
1、Flow-based的工作原理
首先会有一个Normal Distribution,
π
\pi
π(z),其会通过Generator产生另外一个Distribution PG(x),这个过程与GAN的前半部分是类似的,不同的是后半部分。在现实中会有一个Distribution Pdata(x),然后在其中sample出一些数据集,让PG(x)产生的数据集与这些数据进行比较,得出一个生成几率数值,最后这个优化的问题就变成了使这个生成几率数值越大越好,实际上这个调整几率的过程就是在缩小 PG(x)与Pdata(x)的KL divergence。但是与GAN相比还是有着性能上的差距,但是相比之下Flow-based生成模型就更加好进行优化。
2、Flow-based的数学基础Distribution之间的转换
- 一维的转化:如下图所示,当
π
\pi
π(z’)转化到P(x’)后对应的z’与x’也会有相应的变化,假如z变化了
Δ
\Delta
Δz,而x变化了
Δ
\Delta
Δx,就有这样的等式P(x’) =
π
\pi
π(z’) x dz / dx。

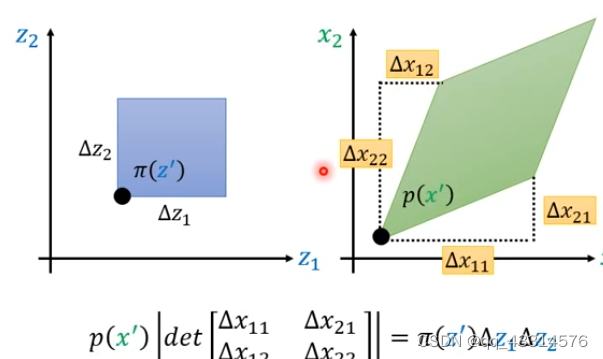
- 二维的转化:如下图所示,假如
π
\pi
π(z’) 在两个方向上经过
Δ
\Delta
Δz1和
Δ
\Delta
Δz2的变化,于此同时P(x’)也经过一系列变化,得到图中的等式,假如将
Δ
\Delta
Δz1和
Δ
\Delta
Δz2移到等式左边就能得到这样的式子P(x’) | det(Jf) =
π
\pi
π(z’) 。因此可以往高维的方向上进行推导,最后得到的也是该等式。
3、Maximizing Likelihood的转换
由前面的推导可以知道PG(xi) = π \pi π(zi) | det(JG-1) |,其中zi 经过Generator生成xi,因此可以由以下的式子 zi = G-1(xi)。因此对 log PG(xi) 的Likelihood可以写成 log PG(xi) = log π \pi π(G-1(xi)) + log |det(JG-1)|。可是经过这样的转化会引出两个问题,第一个是G-1函数到底是什么样子的,第二个是如何计算det(JG)。
4、设计G-1函数架构
因为为了使G函数可逆,就必须让输入和输出的数据的维度一致,就比如输入和输出的数据维度都是100 x 100的规模大小,但是又因为输入Generator的输入数据维度往往是比输出数据的维度小的,为了解决这个问题就必须引入多个Generator来对数据维度进行修改,经过这些处理,需要Maxmize的式子也就变成了log Pk(xi) = log
π
\pi
π(zi) +
∑
k
h
=
1
\underset{h=1}{\overset{k}{\sum}}
h=1∑k log |det(JG-1)|
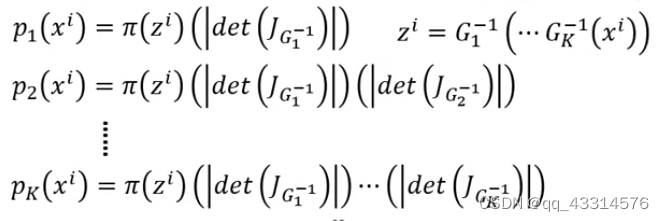
需要注意的是,经过上述变化,从开始训练G变成训练G-1,假如为了让 log
π
\pi
π(zi) 越大越好,就相当于让zi变成0向量,但是这样会让det(JG-1)变为0,而让log |det(JG-1)|变成无穷而无法缩小其值。所以还需要对数据z做出一定的限制。
5、设计简单的det(JG)
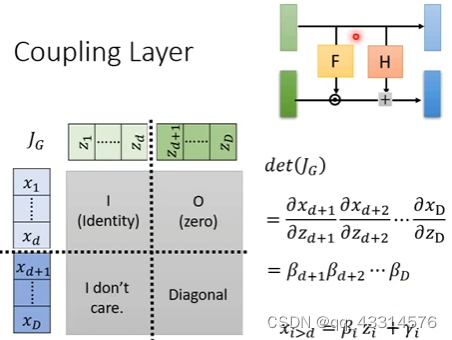
-
Coupling Layer:如下图所示,将输入向量z与输出向量分开成两个部分,前半部分的z只需经过复制得到前半部分的x,后半部分的则是x = β \beta βz + γ \gamma γ。于是det(JG)的计算便可以及进行简单计算,因为在JG矩阵中被分为了四部分,左上部分因为只是简单的复制,于是就是一个简单的单位矩阵,右上矩阵则是因为两者之间不存在关系则为0矩阵,因为分块矩阵的计算中,右上部分矩阵为0则无需再去计算,最后的右下部分矩阵则是经过一系列的简单线性运算,则最后det(JG)便能更简单地得到。当然需要注意的是经过多次的G后,上层矩阵不能一直进行复制,而需要不断变换复制顺序,就好像上层复制到下层复制,再到上层复制,以此往复。
-
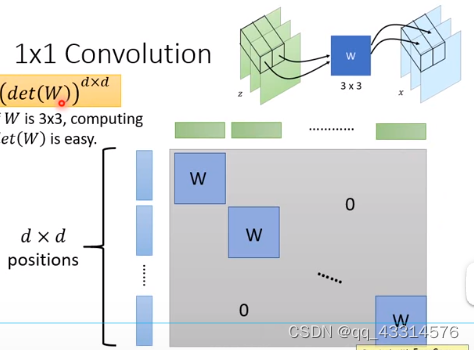
1 x 1 Convolution :该方法与Convolution的思路很类似,就是对局部分块进行变化操作,只要将整体分块对每块数据集进行变化操作,这样就能让JG矩阵只让对应矩阵产生实际有用的数字,这样就能形成一个对角线的分块矩阵,计算det(JG)就能降低计算量。
总结
在本次学习中学习了另外两种生成式模型,在这里见识到了“抽样合成”、“模仿”两种的生成方法,意识到了曾经见到过“模仿字迹”的AI机器人的原理便是类似Flow-based的工作原理,真的无比希望未来能够自己动手复现出一次。当然在这次的学习中更了解到Maximizing Likelihood的重要性,这是一种全新的优化思路,未来必须动手对其掌握!















 84
84











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









