






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
摘要
本周学习内容主要从超分辨率图像处理的方向进行入手,通过阅读文献,Real-world single image super-resolution:A brief review 来了解超分辨率技术的相关概念,学习该技术的处理过程的框架,从而形成一个比较完整的认识。在对该技术有了一定的了解后,看了两篇文献
A Fast and Efficient Super-Resolution Network Using Hierarchical Dense Residual Learning 和 A Fast and Accurate Super-Resolution Network Using Progressive Residual Learning ,对两种不同的残差学习方法进行学习和理解两者是如何对原有技术进行改进。
Abstract
This week’s learning content mainly starts from the direction of super-resolution image processing. By reading the literature, Real-world single image super-resolution: A brief review to understand the relevance of super-resolution technology. Concept, the framework for learning the processing process of the technology, so as to form a relatively complete understanding. After having a certain understanding of this technology, I read two documents , A Fast and Efficient Super-Resolution Network Using Hierarchical Dense Residual Learning and A Fast an D Accurate Super-Resolution Network Using Progressive Residual Learning, learns and understands how two different residual learning methods are Technology is improved.
文献阅读:简评现实世界中的单图像超分辨率
Title:Real-world single image super-resolution:A brief review
Author:Honggang Chen, Xiaohai He, Linbo Qing, Yuanyuan Wu, Chao Ren, and Ce Zhu
1、研究背景
近年来,深度学习在图像超分领域发挥着越来越重要的作用,往前的大部分方法,都是通过进行训练合成数据的深度学习模型来处理超分辨率图像。事实上,这种合成数据的方法往往难以解决真实世界中的图像超分辨率(RSISR)问题。为此,越来越多的学者便开始研究能解决现实场景中的超分辨率问题的算法。
2、超分辨率
2.1、什么是超分辨率
超分辨率,通过硬件或软件的方法提高原有图像的分辨率,通过一系列低分辨率的图像来得到一幅高分辨率的图像过程就是超分辨率重建。超分辨率重建的核心思想就是用时间带宽(获取同一场景的多帧图像序列)换取空间分辨率,实现时间分辨率向空间分辨率的转换。简短地来说,指的是将一张低分辨率的图像(LR),利用超分辨率算法,重构出一张对应的高分辨率图像(HR)。
2.2、超分辨率的实现思路
- 现实场景中有许多因素会导致图像退化(低分辨率,模糊),假如将这些导致图像退化的原因用参数来表示,则现实场景图像退化现象可写成如下图的表达式,其中X表示为高分辨率的图像,Y为退化后的低分辨率图像,
θ
\theta
θD表示为导致图像退化的参数。
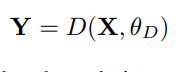
- 单超分辨率的思想就是退化的逆向思维,通过调整“复原”(超分辨率)参数来讲低分辨率图像重新转化为高分辨率的图像,这个“复原”过程可以写成如下图的表达式,这里的X表示的是复原后的高分辨率图像,Y表示为低分率图像,
θ
\theta
θR表示超分辨率参数。
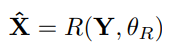
- 在现实的场景下,退化模型中分参数
θ
\theta
θD是未知的,且能获取的资料只有Y。于是转化思路,通过对高清图像进行模糊和下采样来模拟真实场景中的退化操作,整个退化的操作表达式可以表示为如下图的表达式,B和S分别表示模糊和下采样操作,n表示加性噪声。
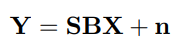
需要注意的是,现实场景下的退化过程是十分复杂的,很难通过简单的模糊加下采样就能够建模的。因此SISR方法依然难以在现实场景中获得较好的超分辨率效果。
3、评估指标
对超分辨率的评估指标的方法主要有两种方法,通过人眼评估,或使用评估指标进行客观评估。需要注意的是人眼评估主观性相对更强,且费时费力,对于大数据的评估,不建议使用。相比之下,客观评估指标方法简单、高效。注:个人认为,客观评估指标的信服度需要经受考验。目前,客观评估指标有下图几种。
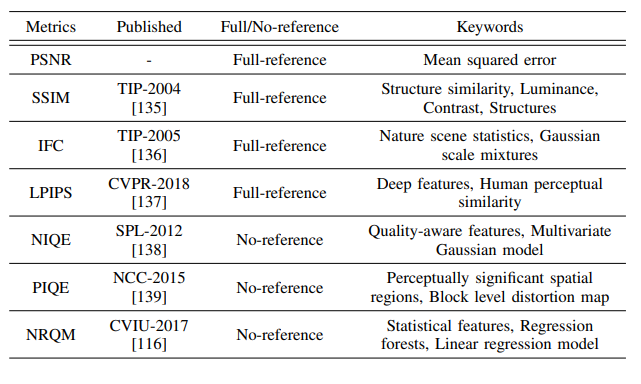
- PSNR:主要衡量的是算法结果超分辨率图像与高分辨率图像对应像素距离的接近程度,应用范围很广。
- SSIM:从亮度、对比度和结构相似度三个方面来衡量超分辨率图像与高分辨率图像的差异。
- IFC:信息保真度准则利用超分辨率图像与高分辨率图像的互信息进行评估。
- LPIPS:在特征空间中计算超分辨率图像与高分辨率图像的L2距离,能与人眼主观评估保持较好的一致性。
- NIQE:利用多元高斯模型拟合提取的图像特征,计算两个多元高斯模型的距离来衡量图像质量。
- PIQE:人眼对图像空间中某些重要区域更为关注,将测试图像分成多个非重叠块,然后执行block-level分析来识别块的失真与等级。
- NRQM:先提取图像的局部频域特征、全局频域特征和空间特征,然后分别训练3个随机森林模型,最后通过线性组合这3个随机森林模型的结果得到最终的感知得分。
4、超分辨率方法
4.1、基于退化模型的方法
基于退化模型的方法的思路,是由人工设计一个退化模型,就如上面2.2中的退化模型 Y = SBX + n。设计出相关模型之后,利用这个退化模型对高分辨率图像进行参数调整,形成退化,生成低分辨率的图像,得到模型中的 X 与 Y ,利用低分辨率图像与高分辨率图像对进行模型训练。该类方法最大的问题在于难以建立合适的退化模型来生成低分辨率图像。
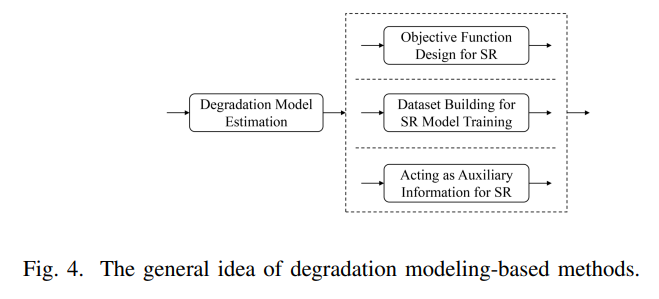
4.2、基于图像对的方法
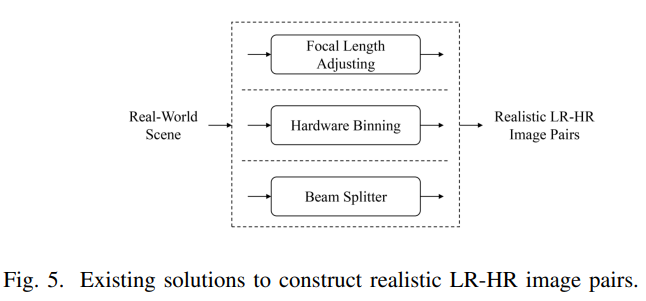
由于4.1的退化模型的方法的问题在于真实的退化模型难以模拟,于是研究人员就收集在同一场景下不同分辨率的图像,用于构建低分辨率与高分辨率之间的图像对,通过对比就能相对更好地训练RSISR模型了。如下图通过三种方法来获取这样的对比图像对。当然基于图像对的方法也有明显的缺陷,就是该方法难以获取两张完整一样的场景下的低分辨率和高分辨率图像,这样对于学习网络模型来说难以实现一个完美的效果。
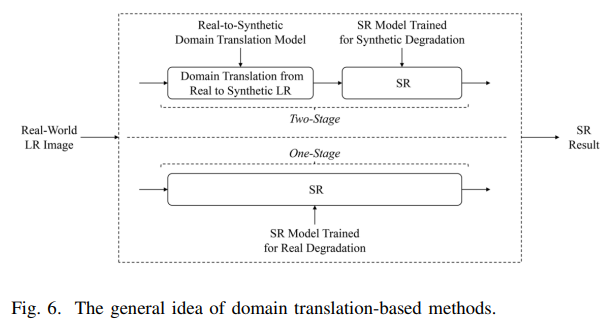
4.3、基于领域迁移的方法
因为基于图像对的方法难以获取十分对齐的低分辨率和高分辨率的图像对。基于领域迁移法则可以解决该问题,该方法思路就是将真实低分辨率图像、合成低分辨率图像以及高分辨率图像看成是来自不同的领域,想办法将真实低分辨率图像领域迁移到高分辨率图像领域。这些方法可分为two-stage和one-stage两种。
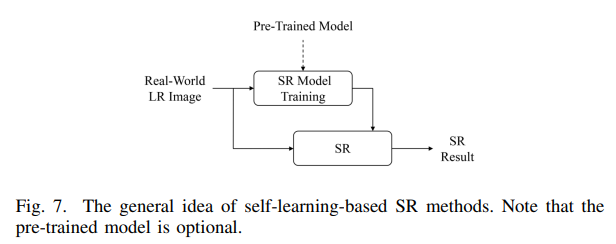
4.4、基于自学习的方法
由于现实中许多低分辨率的图像可能不具备训练图像的特点,即难以实现从低分辨率领域到高分辨率领域的迁移。为了减少训练测试不一致,研究学者提出利用低分辨率图像的内部信息来进行RSISR,即自学习方法,由机器模型自己学习其相关内部特征,这样就能兼容大部分现实的低分辨率图像,但自学习方法也存在两大缺点:1、在模型优化过程中只利用了低分辨率图像的内部信息,大量外部信息被丢弃了;2、自学习方法所需要的时间普遍都很大。
5、总结
近年来,现实世界图像的超分辨率越来越受到关注,回顾了现实图像的最新超分辨率方法,包括基于退化建模的算法、基于图像对的算法、基于域翻译的算法和基于自学习的算法。此外,尽管过去几年在RISISR方面取得了一些进展,但仍有挑战需要进一步解决,例如用于模型训练和测试的现实数据集、用于现实世界图像超分辨率的特定模型和重建性能评估。希望研究人员更好地了解现有研究,也希望它能吸引更多的关注,以推进现实世界图像超分辨率技术的进展和应用。
文献阅读:基于分层密集残差学习的快速高效超分辨网络
Title:A FAST AND EFFICIENT SUPER-RESOLUTION NETWORK USING HIERARCHICAL DENSE RESIDUAL LEARNING
Author:Vinh Van Duong, Thuc Nguyen Huu, Jonghoon Yim, and Byeungwoo Jeon
From : Department of Electrical and Computer Engineering Sungkyunkwan University, Kore
1、研究背景
单图像超分辨率是一个经典的图像恢复问题,仍然是最热门的研究课题之一。它旨在从低分辨率图像中恢复具有详细纹理和重要信息的高分辨率图像。现实中许多应用都需要该高分辨率图像,如果能顺利地完成从低分辨率图像转化为高分辨率图像,能有效地帮助更多更具想象力的应用。随着使用卷积神经网络的超分辨率首次引入,与最先进的非深度学习方法相比,它取得了令人印象深刻的结果。在那之后,许多深度卷积神经网络已经开发出来,并被证明可以显著提高性能,但是在显著提高性能的同时,也存在着不少的问题。
2、研究目的
近年来,许多的神经网络已经普遍运用在解决单图像超分辨率的问题上,不乏缺乏残差网络的神经网络结构,但是这些神经网络结构大多数都是使用的是双层连接结构,这些网络两层结构使用的都是不同的网络结构,如下图所示。尽管这些双层连接结构的神经网络已经取得十分不错的成绩,但是依然存在几个问题,一、这些双层结构的设计没有注重层与层之间的配合连接,其实就是每一层各干各的,无法彼此配合提取到更多信息;二、因为要实现这样双层结构的连接,需要包含大量的参数,这样整个网络结构就需要大量的计算以及耗费大量的存储量,从而无法实现一个小而精简的结构用在移动设备上。为了解决这些问题,便提出了分层密集残差网络的设想。
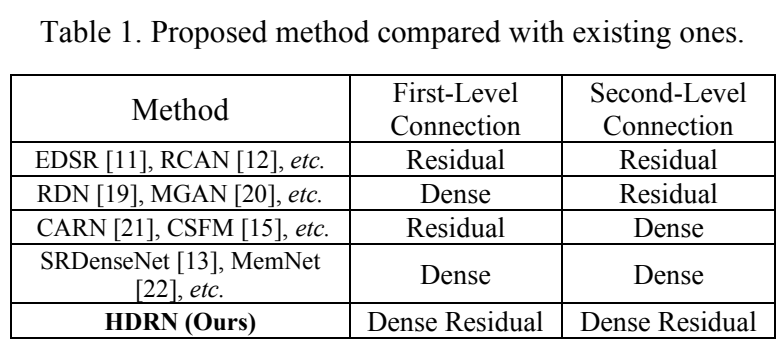
3、研究思路
3.1、提出分层密集残差网络的结构
如下图所示,设计出一个分层密集残差网络的结构,这个结构主要包括三个部分,浅层特征提取、深层特征提取及特征重构。其中在深层特征提取部分包含着许多的密集紧凑残差组(DCRG),每个组里也包含着许多的紧凑残差块。密集紧凑残差组通过每个紧凑残差块来提取输入低分辨率图像的丰富特征,以及通过紧凑残差块们改善低分辨率图像的图像特征信息,这样就能重构出高分辨率图像所需要的残差信息。为了减少计算负担,在每个DCRG的第一个CRB前添加一个1x1的卷积提取层,能够有效地压缩输入的数据,这样不仅能压缩数据,更能有效地让整个网络变得紧凑。
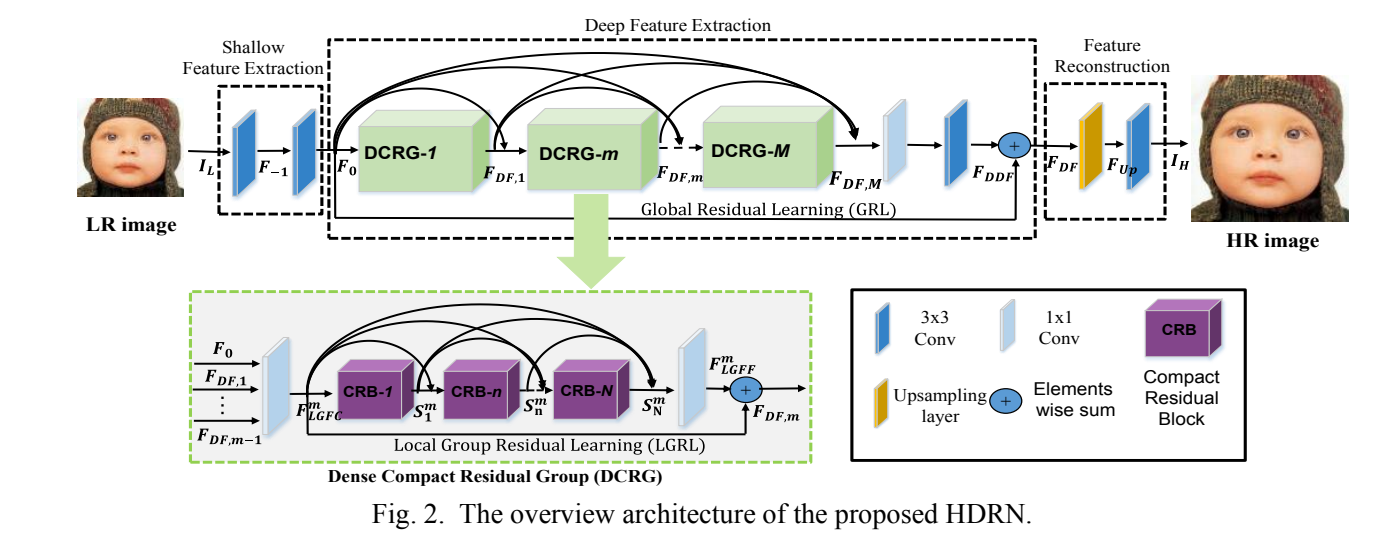
3.1.1、 密集紧凑残差组 Dense Compact Residual Group
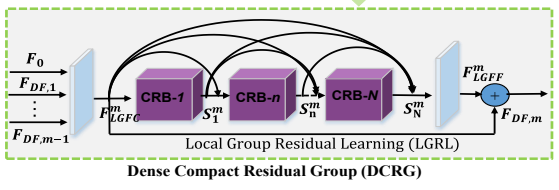
密集紧凑残差组包含四部分,局部组特征压缩(LGFC)、密集连接的一系列紧凑残余块(CRB)、局部组特征融合(LGFF)和局部组残余学习(LGRL)。局部组特征压缩(LGFC)表示的是通过开头的1x1 Conv层对数据进行压缩,之所以要对数据压缩,是因为密集的连接结构,直接融合所有特征图是不可行的,这会导致大量特征的输入而难以得到精准处理。随后通过多个CRB对压缩后的数据进行提取。局部组特征融合(LGFF),是经过CRB提取后的数据再次经过1x1 Conv层压缩数据。最后局部组残余学习(LGRL)将未经过CRB处理的数据和经过CRB处理的数据进行融合,不仅稳固了原来的训练结果,也提高了整个网络训练性能。
3.2、模型测试
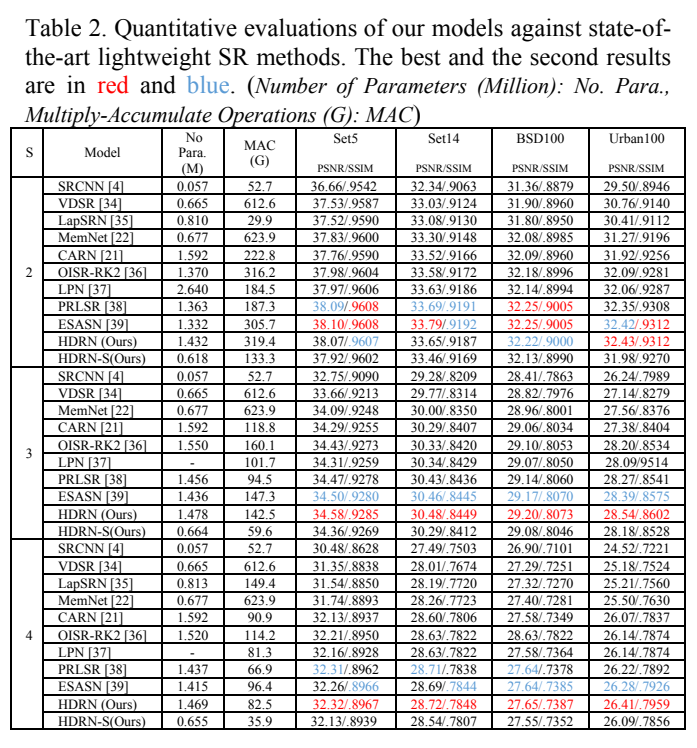
模型在经过在DIV2K数据集训练后,使用四种不同的数据集Set5 、Set14 、BSD100和 Urban100 对训练完的模型进行性能测试,使用的测试指标为PSNR以及SSIM,最后在x2、x3及x4的影响因素下,得到如下图所示的结果。由图可以知道随着影响因素的倍数增加,HDRN的测试结果表现得越来越好,这也表明提出分层密集残差网络的结构在处理超分辨率图像上有着提升与优势。除了这些测试之外,还与RDN 和DLRN 等小模型进行了比较测试,在所需要参数更小的情况下,性能均表现得更优。
4、结论
本文通过利用分层密集剩余学习,提出了一个分层密集的剩余网络(HDRN),用于快速高效的单图像超分辨率任务。具体来说,构建致密紧残基团(DCRG)是为了利用密集连接的紧致残余块(CRB)系列中丰富的局部特征。实验结果验证了HDRN与最先进的方法相比,在重建准确性和计算成本方面都取得了一个不错的成绩。
文献阅读:基于渐进残差学习的快速高精度超分辨率网络
Title:A FAST AND ACCURATE SUPER-RESOLUTION NETWORK USING PROGRESSIVE RESIDUAL LEARNING
Author:Hong Liu1, Zhisheng Lu1, Wei Shi1, Juanhui Tu2
1、研究背景
单图像超分辨率(SISR)是一项基本的计算机视觉任务,主要任务就是对低分辨率图像进行重构,转换为高分辨率图像。单图像超分辨率是一个活跃的领域,它能够在医疗图像处理和监控系统等许多应用中克服分辨率限制。自SRCNN网路模型推出以来,为解决单图像超分辨率问题给出一个新的解决思路,提出了各种具有出色性能的神经网络算法。这样能够推动单图像超分辨率在其他应用上的突破。
2、研究目的
正是因为使用了神经网络模型来对单图像超分辨率处理有着不错的性能,越来越多人更倾向用神经网络模型来解决该问题。但是对于图像的处理需要对图像特征进行精确地提取,需要更多层数的网络模型来完成,但是发现越多层数的网络模型会出现冗余,性能不足的情况。随着残差学习的思路推出,便解决了冗余问题,于是许多算法倾向于使用更深的超分辨率(SR) 模型来获得更好的准确性。然而,神经网络要增加层数总是带来很高的计算成本。从这个意义上说,迫切需要设计一个能够满足现实世界场景需求的轻量级SR模型。
3、研究思路
3.1、提出渐进残差学习的快速高精度超分辨率网络结构
如下图所示,设计出一个渐进残差学习的快速高精度超分辨率网络结构,这个结构主要包括三个部分,浅层特征提取、深层特征提取及特征重构。其中在深层特征提取部分包含着许多的渐进式残差块(PRB),PRB通过逐步下采样和上采样特征图,以探索多尺度特征并减少冗余信息。在PRB中,包含着HFP模块,HFP模块会在向下采样特征图之前保存高频信息,然后将高频特征信息添加到向上采样的特征图中。也正是得益于HFP模块这样的特性能够有效地减少计算负担,其次得益于残差学习的特性,整个模型的深度可以达到一个可观的水平,便能实现一个卓越的超分辨率重构性能。

3.2、模型测试
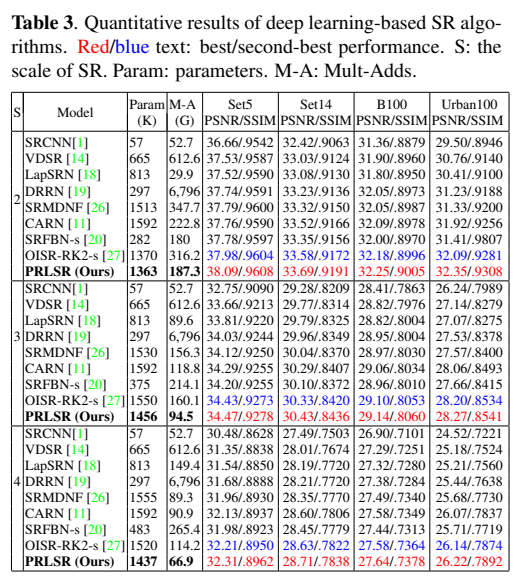
将训练好的PRLSR模型与8种轻量级S-R方法在x2、x3和x4四种不同的超分辨率尺度上进行比较。测试集的评估标准使用的是PSNR和SSIM。如下图所示,PRLSR在每个尺度上都取得了最佳性能,在四个数据集中都与其他模型有着不同程度的超越。除此之外,在三个尺度上不同模型的Mult-Adds(代表乘法加法操作的数量)和参数的比较可以看出,一些模型的参数很少,但Multi-Add很大,相比其他模型,PRLSR在性能和速度之间进行了最佳权衡,与参数和Mult-Adds较少的LapSRN相比,PRLSR在PSNR和SSIM中具有较大的性能值,表现更好。与具有相似性能的OISR-RK2-s相比,PRLSR的参数和MultAdds(近一半)。特别是在规模x4上,拟议的PRLSR的Mult-Adds接近SRCNN[!]只有三层。可以看出,与最先进的方法相比,PRLSR在高频细节方面表现得更好。
3.3、性能出色原因分析
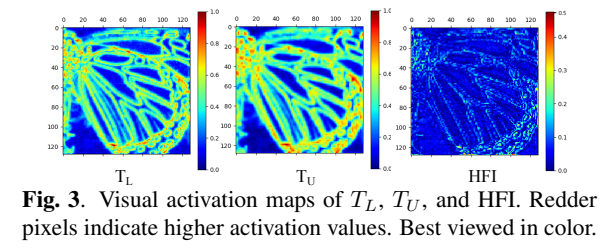
与其他模型相比,PRLSR能实现如此好的成绩,是使用了渐进式残差块,渐进式残差块中包含着最主要的两部分,RLA和HFP,其中RLA用来提取图片细节的特征,HFP则是用来保留高频信息,当然其中也是用了残差学习的连接结构,这样就能将整个网络层数实现地非常深,这样能提取到的信息更多,对图像信息的细节处理也能更加地到位。如下图所示,TL为原始图像,TU为经过网络处理的图像,HFI为提取出来的高频信息,可以看出TU比TL 显得更加地平滑,不会出现类似马赛克一样的锯齿,有锯齿的图像通常会显得分辨率不高,由此可以看出RLA提取图片细节特征以及HFP对高频信息的保留的重要性。
4、结论
为了解决SISR问题,提出了一个名为PRLSR,渐进残差学习的快速高精度超分辨率网络结构。在PRLSR中,其主要功能部件渐进式残差块 (PRB)旨在通过逐步利用下采样和上采样操作来减少多阶段的特征冗余。在渐进式残差块中,为了减少在PRB中分辨率降低造成的细节损失,提出了一个高频信息存储模块(HFP)来保留高频信息。在PRB的每个阶段,使用基于RL的架构 (RLA) 来提取多级特征。最终在实验表明,渐进残差学习的快速高精度超分辨率网络结构在保持高效率的同时,在四个基准上实现了最先进的性能。
两种方法对比
从两篇论文提出的方法与神经网络结构图可以看出,两者的方法总体思路是一致的,当然也有些许不同的地方,下面对两者相同之处与不同之处做出对比。
- 相同之处:第一、总体的结构相同,神经网络的框架总体都是分为三部分,浅提取、深提取以及特征重构;第二、深提取部分都是使用了残差神经网络结构对整体的提取特征模块进行优化,这样不会导致整个网络因为深度过深而导致冗余情况的出现;第三、深提取部分都是使用了多重提取特征的模块对特征进行提取,进行多次提取能有效地将图像的突出信息保留下来,并利用这些有用的信息对图像进行重构。
- 不同之处:主要的不同之处就是对图像数据处理的细节上有差异。在分层密集残差网络上,每个信息提取组都会有conv层与提取结构以串联的形式对信息进行压缩后再进行提取,这样去掉了冗余信息,当然前一次的信息也会传到后一层一起处理,防止出现有用的信息被遗漏,这样经过多次的压缩及提取便能得到所需要的最终信息。在渐进残差学习的快速高精度超分辨率网络上,对图像信息的提取则没有使用串联的形式,而是使用并联的结构,通过并联对所有的信息进行提取,将提取到有用的信息保留下来,因为这样得到的数据会过于巨大,在输出到下一个提取结构前会进行压缩。
总结
经过上星期对残差网络的学习,意识到残差网络结构对神经网络发展有着里程碑的意义,因为它的特殊结构,能让多层次结构的神经网络变得不再冗余,这样便能够随着神经网络层次的增加而提取到更多有用的信息,这样便能在许多领域有所突破。比如这星期学习了解的单图像超分辨率,假如神经网络能够在低分辨率图像中提取到更多有用的信息,便能利用这些有用的信息进行重构刷新,将有用的信息放大从而能使整张图片显得更加地清晰。过些日子也要开始动手实现残差网络的相关代码,让自己感受下其的魅力。

















 512
512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









