







文章目录
什么是泛型? 泛型有什么用?
要理解泛型, 就要从没有泛型的时候说起, 泛型是在 JDK 1.5 开始引入的, 在之前的版本中, 并不支持泛型, 只能使用 Object 类进行通用编程, 这样在处理 集合 这些数据结构的时候, 就需要显示类型转换, 为了解决这个问题, 就引入了泛型, 用大白话讲就是适用很多类型, 它把类型进行参数化, 在编译的时候可以进行类型检查, 并且减少了类型转换的代码.
- 目的是增强类型安全性和代码的可读性, 并减少运行时类型转换的错误.通过使用泛型, 可以在编译的时候捕获类型错误, 提供了更好的代码组织和抽象.
没哟使用泛型时:
// 没有使用泛型的例子
public class WithoutGenericsExample {
private Object data;
public WithoutGenericsExample(Object data) {
this.data = data;
}
public Object getData() {
return data;
}
public static void main(String[] args) {
WithoutGenericsExample example = new WithoutGenericsExample("Hello");
String str = (String) example.getData(); // 需要强制类型转换
System.out.println(str);
}
}
使用泛型后:
// 使用泛型的例子
public class WithGenericsExample<T> {
private T data;
public WithGenericsExample(T data) {
this.data = data;
}
public T getData() {
return data;
}
public static void main(String[] args) {
WithGenericsExample<String> example = new WithGenericsExample<>("Hello");
String str = example.getData(); // 不需要类型转换
System.out.println(str);
}
}
泛型原理是什么?
Java 泛型是使用类型擦除来实现的, 在Java中, 泛型的参数类型在编译后, 被擦除的机制, 比如 new ArrayList< Integer >() 变为 new ArrayList< >() , 这就是类型擦除.
类型擦除的好处有直接兼容兼容之前的代码, 节约了内存空间, 以及 jvm 层面实现简单.
Java 反射
什么是反射? 反射作用是什么?
反射是值程序在运行时, 动态的获取和操作类的一种能力.
通过反射机制, 可以在运行时动态的创建对象, 调用方法, 访问和修改属性, 获取类的信息等.
深入理解 Java 反射和动态代理
动态代理有几种实现方式? 有什么特点?
动态代理是一种方便运行时动态构建代理、动态处理代理方法调用的机制,很多场景都是利用类似机制做到的,比如用来包装 RPC 调用、面向切面的编程(AOP).
- JDK 动态代理(基于接口的动态代理), JDK 动态代理只能代理实现了接口的类或者直接代理接口
代理类与委托类实现同一接口,主要是通过代理类实现 InvocationHandler 并重写 invoke 方法来进行动态代理的,在 invoke 方法中将对方法进行处理。 - CGLIB 代理(基于类的动态代理), CGLIB 可以代理未实现任何接口的类, 另外, CGLIB 动态代理是通过生成一个被代理的子类来拦截被代理类的方法调用.
Java 注解
什么是注解, 作用是什么?
注解是 JDK 5 引入的新特性, 可以看作是一种特殊的注释, 主要用于修饰类, 方法, 变量, 提供某些信息供程序在编译或运行的时候使用.
注解详解
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
// 定义一个自定义的注解
@Retention(RetentionPolicy.RUNTIME) // 指定注解在运行时可见
@Target(ElementType.METHOD) // 该注解可以应用于方法
public @interface MyAnnotation {
// 定义注解的成员变量
String value(); // 使用value作为成员变量名
int priority() default 1; // 定义一个默认值为1的成员变量
}
Java I/O
什么是序列化?
- 序列化就是将对象转换为二进制数据.
- 反序列化就是将二进制数据转换为对象.
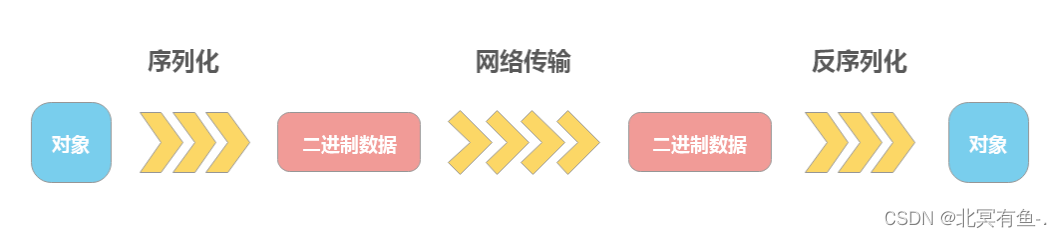
Java 是怎么实现系列化的?
JDK 中内置了一种序列化方式.
ObjectInputStream 和 ObjectOutputStream
Java 通过对象输入输出流来实现序列化和反序列化:
- java.io.ObjectOutputStream 类的 writeObject() 方法可以实现序列化,
- java.io.ObjectInputStream 类的 readObject() 方法用于实现反序列化.
常见的序列化协议有哪些?
常见的序列化协议包括:
-
Java 序列化(Java Serialization):Java 自带的一种序列化协议,通过实现
java.io.Serializable接口来实现对象的序列化和反序列化。虽然易于使用,但它具有一些局限性,例如不跨语言、不具备灵活性等。 -
JSON(JavaScript Object Notation):一种轻量级的数据交换格式,易于阅读和编写,也易于机器解析和生成。由于其简洁性和广泛的支持,被广泛应用于网络传输和配置文件等领域。
-
XML(eXtensible Markup Language):一种标记语言,具有与 JSON 类似的跨平台、跨语言特性。XML 格式的数据可以通过各种方式解析和处理,但相对于 JSON 而言,XML 的语法较为繁琐,文件体积相对较大。
-
Protocol Buffers(Protobuf):由 Google 开发的一种高效的序列化协议。Protobuf 使用二进制格式编码数据,相对于 JSON 和 XML,它的体积更小、解析速度更快。Protobuf 支持多种编程语言,并且生成的代码具有良好的可读性。
-
Apache Avro:另一种由 Apache 开发的序列化协议,类似于 Protobuf。Avro 使用 JSON 格式定义数据结构,并支持动态生成代码。它具有较好的跨语言支持和数据压缩能力。
-
MessagePack:一种高效的二进制序列化协议,数据格式紧凑且可读性良好。MessagePack 支持多种数据类型,并且在多种编程语言中都有相应的实现。
BIO/NIO/AIO 有什么区别?
简单来说, BIO就是传统的 IO 包, 它诞生的最早, 它是同步的, 阻塞的, NIO 是对 BIO 的改进, 提供了多路复用的同步非阻塞IO, 而 AIO 是NIO 的升级, 提供了 异步非阻塞IO.
-
BIO (同步阻塞IO): 现成发起请求后, 一直阻塞 IO, 知道缓冲区数据就绪后, 再进入下一步操作, 针对网络通信是一问答一响应的方式, 虽然简化了上层的应用开发, 但是在性能可可靠性上又巨大瓶颈, 在高并发场景下, 资源很快就会被耗尽.
-
NIO (同步非阻塞IO): 为了解决 BIO 性能, 引入了 NIO, NIO 提供了 channel , Select , Buffer 等新的抽象, 可以构建多路复用, 可以通过单线程或少量线程处理多个通道的事件.
-
AIO (异步非阻塞IO): 是 NIO 的升级版本, 基于事件和回调函数实现, 也就是在引用操作之后会直接返回, 不会阻塞在那里, 当后台处理完成, 操作系统会通知相应的线程进行后续的操作.
IO 多路复用是什么?
I/O 多路复用是一种高效的 I/O 编程模式,用于同时监视多个 I/O 流的状态,并在有数据可读、可写或者有异常时立即对其进行处理,而不需要为每个 I/O 流创建一个对应的线程。
在传统的阻塞 I/O 模型中,每个 I/O 操作都需要一个独立的线程来处理,当有大量的并发连接时,会导致大量的线程创建和上下文切换,降低系统性能。
而在多路复用模型中,通过使用特定的系统调用(如 select、poll、epoll 等),可以同时监听多个 I/O 流的状态。一旦有 I/O 事件发生,操作系统会通知应用程序,应用程序就可以根据事件类型来进行相应的处理,而无需阻塞等待。这样就可以用较少的线程来处理大量的并发连接,提高系统的并发能力和性能。
select 和 epoll 有什么区别?
-
select 每次调用都需要将文件描述符集合从用户态拷贝到内核态,而且随着文件描述符数量的增加,这个拷贝的开销会变得非常大。
每次调用都需要线性扫描整个文件描述符集合,效率较低。 -
epoll 使用一个文件描述符来管理多个文件描述符,减少了拷贝文件描述符集合的开销。
通过红黑树和双链表来管理文件描述符,实现了 O(1) 时间复杂度的事件注册和删除,提高了效率。
支持水平触发(LT,Level Triggered)和边缘触发(ET,Edge Triggered)两种模式,更灵活。
select()函数基于数组,fd个数限制1024,poll()函数也是基于数组但是fd数目无限制。都会负责所有的fd,
epll()基于红黑数实现,fd无大小限制,平衡二叉数插入删除效率高.















 438
438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











