






目录
一、简介
朴素贝叶斯算法是一种基于贝叶斯定理的分类算法,它简单而高效。它的经典应用案例为人所熟知:文本分类(如垃圾邮件过滤)。本文将介绍朴素贝叶斯算法的原理和实现。
二、算法原理
1.朴素贝叶斯方法
朴素贝叶斯方法在分类任务中需要计算先验概率、条件概率和后验概率。
先验概率是基于结论计算的概率,条件概率是通过不同的条件由因推果计算的概率,后验概率则是由先验概率和条件概率共同计算的结果,是作为判断最终结果的依据。
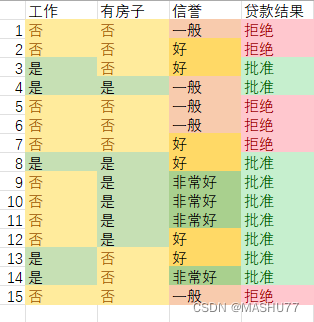
下面我通过一个数据集来直观的介绍这三种概率的计算方法。
2.先验概率
先验概率的计算公式如下:
其中,Y 是类别变量,c_i 是类别的取值,N_i 是属于类别 c_i 的样本数量,N 是总样本数量。
该数据集中贷款结果为拒绝的数量是6,批准的数量为9,因此先验概率由数据集的贷款结果来计算的结果为:
P(拒绝) = 6/15 P(批准) = 9/15
3.条件概率
条件概率是朴素贝叶斯算法中最重要的部分,它的计算公式如下:
基于条件概率可以通过P(B|A)求P(A|B)的就是贝叶斯定理:
其中,P(A∣B) 是在给定B条件下A发生的概率,P(B∣A) 是在给定A条件下B发生的概率,P(A) 和 P(B) 分别是A和B的概率。
若有一组数据(工作:否,有房子:否,信誉:非常好),假设贷款批准,则该数据的条件概率为:
P(工作:否|批准) = 4/9 P(有房子:否|批准) = 1/3 P(信誉:非常好|批准) = 4/9
4.后验概率
后验概率的计算是由先验概率和条件概率组成的,具体公式如下:
由于对所有的P(Y = c_i),上式的分母的值都是一样的,测算时可以忽略父母部分,因此最终的表示式为:
对于数据(工作:否,有房子:否,信誉:非常好),它的后验概率为:
P(批准|工作:否,有房子:否,信誉:非常好) = P(批准)*P(工作:否|批准)*P(有房子:否|批准)*P(信誉:非常好) = 9/15 * 4/9 * 1/3 * 4/9 = 16/405 = 0.0395
同理P(拒绝|工作:否,有房子:否,信誉:非常好) = 6/15 * 1 * 1 * 0 = 0,计算表明该数据应该判批准,但是出现的0和1就不得不让人考虑某些决定性因素导致的结果单一化,这可能会造成我们结果预测错误,为了解决这个问题就引入了拉普拉斯平滑。
5.拉普拉斯平滑
拉普拉斯平滑通过在概率估计中引入一个小的正数(通常为1)来平滑概率分布。改变的公式为:
a为指定系数,在我们的运算中取1,|Y=c_i|为特征c_i的数量,在计算先验概率时为2,即“拒绝”和“批准”。我们可以算出引入拉普拉斯平滑后的先验概率:
P(拒绝) = 7/17 P(批准) = 10/17
在按上述步骤可以算出该数据的条件概率、后验概率:
P(工作:否|拒绝) = 1039/1428 =0.7275 P(有房子:否|拒绝) = 1071/1309 = 0.8182 P(信誉:非常好|拒绝) = 85/882 = 0.0963
P(工作:否|批准) = 935/2040 = 0.4583 P(有房子:否|批准) = 459/1870 = 0.2455 P(信誉:非常好|批准) = 595/1980 = 0.3005
P(拒绝|工作:否,有房子:否,信誉:非常好) = 0.0236
P(批准|工作:否,有房子:否,信誉:非常好) = 0.0186
所以数据(工作:否,有房子:否,信誉:非常好)的最终结果是拒绝贷款。
三、代码实现
1.数据准备
# 样本数据
data = {
'工作': ['否', '否', '是', '是', '否', '是', '否', '否'],
'有房子': ['否', '否', '否', '是', '是', '否', '否', '是'],
'信誉': ['一般', '好', '好', '一般', '非常好', '好', '一般', '非常好'],
'贷款结果': ['拒绝', '拒绝', '批准', '批准', '批准', '批准', '拒绝', '批准']
}
X_train = np.array([
[0, 0, 0],
[0, 0, 1],
[1, 0, 1],
[1, 1, 0],
[0, 1, 2],
[1, 0, 1],
[0, 0, 0],
[1, 1, 2]
])
y_train = np.array([0, 0, 1, 1, 1, 1, 0, 1])
2.计算先验概率
# 计算每个类别的先验概率
self.class_probs = np.zeros(num_classes)
for i, c in enumerate(self.classes):
self.class_probs[i] = (np.sum(y == c) + self.alpha) / (float(num_samples) + num_classes * self.alpha)3.计算条件概率
# 计算每个特征的可能取值数量
self.num_values = np.zeros(num_features, dtype=int)
for feature in range(num_features):
self.num_values[feature] = len(np.unique(X[:, feature]))
# 计算每个类别下每个特征的条件概率
self.feature_probs = np.zeros((num_classes, num_features, np.max(self.num_values)))
for i, c in enumerate(self.classes):
X_c = X[y == c]
for feature in range(num_features):
for value in range(self.num_values[feature]):
self.feature_probs[i, feature, value] = (np.sum(X_c[:, feature] == value) + self.alpha) / (
float(len(X_c)) + self.num_values[feature] * self.alpha)4.计算后验概率
def predict(self, X):
num_samples = X.shape[0]
y_pred = np.zeros(num_samples)
for i in range(num_samples):
probs = []
for j, c in enumerate(self.classes):
# 计算后验概率
prob = self.class_probs[j]
for feature, value in enumerate(X[i]):
prob *= self.feature_probs[j, feature, value]
probs.append(prob)
y_pred[i] = self.classes[np.argmax(probs)]
return y_pred.astype(int)5.计算结果分析
测试数据
X_test = np.array([
[0, 0, 2],
[1, 0, 1]
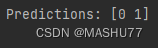
])结果
分析
与上述计算结果相同,数据(工作:否,有房子:否,信誉:非常好)的结果为拒绝贷款。
另一组测试数据(工作:是,有房子:否,信誉:好)的结果为批准贷款。
6.完整代码
import numpy as np
class NaiveBayes:
def __init__(self, alpha=1):
self.alpha = alpha
self.class_probs = None
self.feature_probs = None
def fit(self, X, y):
num_samples, num_features = X.shape
self.classes = np.unique(y)
num_classes = len(self.classes)
# 计算每个类别的先验概率
self.class_probs = np.zeros(num_classes)
for i, c in enumerate(self.classes):
self.class_probs[i] = (np.sum(y == c) + self.alpha) / (float(num_samples) + num_classes * self.alpha)
# 计算每个特征的可能取值数量
self.num_values = np.zeros(num_features, dtype=int)
for feature in range(num_features):
self.num_values[feature] = len(np.unique(X[:, feature]))
# 计算每个类别下每个特征的条件概率
self.feature_probs = np.zeros((num_classes, num_features, np.max(self.num_values)))
for i, c in enumerate(self.classes):
X_c = X[y == c]
for feature in range(num_features):
for value in range(self.num_values[feature]):
self.feature_probs[i, feature, value] = (np.sum(X_c[:, feature] == value) + self.alpha) / (
float(len(X_c)) + self.num_values[feature] * self.alpha)
def predict(self, X):
num_samples = X.shape[0]
y_pred = np.zeros(num_samples)
for i in range(num_samples):
probs = []
for j, c in enumerate(self.classes):
# 计算后验概率
prob = self.class_probs[j]
for feature, value in enumerate(X[i]):
prob *= self.feature_probs[j, feature, value]
probs.append(prob)
y_pred[i] = self.classes[np.argmax(probs)]
return y_pred.astype(int)
# 样本数据
data = {
'工作': ['否', '否', '是', '是', '否', '是', '否', '否'],
'有房子': ['否', '否', '否', '是', '是', '否', '否', '是'],
'信誉': ['一般', '好', '好', '一般', '非常好', '好', '一般', '非常好'],
'贷款结果': ['拒绝', '拒绝', '批准', '批准', '批准', '批准', '拒绝', '批准']
}
X_train = np.array([
[0, 0, 0],
[0, 0, 1],
[1, 0, 1],
[1, 1, 0],
[0, 1, 2],
[1, 0, 1],
[0, 0, 0],
[1, 1, 2]
])
y_train = np.array([0, 0, 1, 1, 1, 1, 0, 1])
X_test = np.array([
[0, 0, 2],
[1, 0, 1]
])
# 实例化和拟合模型
nb = NaiveBayes(alpha=1) # 设置拉普拉斯平滑参数alpha
nb.fit(X_train, y_train)
# 预测并输出结果
predictions = nb.predict(X_test)
print("Predictions:", predictions)
四、总结
朴素贝叶斯算法是一种简单而有效的分类方法,在入门机器学习和处理文本数据时具有重要意义。通过本文抛砖引玉,希望读者能够对朴素贝叶斯算法有所了解,若有错误和建议请在评论区中提出。















 9724
9724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









