







 本文探讨了如何利用机器学习和大数据技术构建音乐流行趋势预测模型,通过歌曲聚类、时间粒度分解和SVM预测,提供短时空间和趋势变化。同时,系统实现了音乐评分数据采集、推荐算法应用,以及大数据平台的搭建,为音乐平台的运营提供商业价值。
本文探讨了如何利用机器学习和大数据技术构建音乐流行趋势预测模型,通过歌曲聚类、时间粒度分解和SVM预测,提供短时空间和趋势变化。同时,系统实现了音乐评分数据采集、推荐算法应用,以及大数据平台的搭建,为音乐平台的运营提供商业价值。
!!! 有需要的小伙伴可以通过文章末尾名片咨询我哦!!!
💕💕作者:毕业通通通
💕💕个人简介:本人在读博士研究生,拥有多年程序开发经验,辅导过上万人毕业设计,支持各类专业;如果需要论文、毕设辅导,程序定制可以联系作者
💕💕各类成品java系统 。javaweb,ssh,ssm,springboot等等项目框架,源码丰富,欢迎咨询交流。学习资料、程序开发、技术解答、代码讲解、源码部署,需要请看文末联系方式。
摘 要
基于机器学习构建音乐流行趋势预测模型仅使用了离预测目标时间段较近范围的数据。本文对歌曲聚类后进行分组实验:以模糊集理论为基础,分解时间信息粒,构建“triangle”模型;采用SVM预测triangle模型的low,R,up参数,可得到准确的短时空间和趋势变化。这对于平台中原创行为、使用行为以及运营商的营销活动都有重要的指引作用。
系统实现用户对音乐评分的搜集(Python爬虫爬取数据),后端使用大教据推荐算法构造,前端使用MVC框架搭建大数据音乐推荐系统。系统教据序使用了关系型教据库MySQL。前端收集过用户行为数据后传到后端使用基于用户的协同过滤算法来推荐出用户可能喜欢的音乐。采用BS架构,使用Java程序设计语言、MySQL数据库、Hadoop离线分析、 java 开源工具Eclipse编写程序、Java的JRE运行环境、JSP页面等工具开发而来。
音乐流行趋势预测为企业预测未来流行音乐走向、预判黑马音乐提供了理论支撑和决策上的技术支持,具有重要的商业价值。相比传统预测方法,基于机器学习构建预测模型不仅理论完善,而且在实践中有强大的鲁棒性和泛化能力,可直接移植到平台中应用。
关键词:大数据;Hadoop;Python;Java;音乐数据分析;音乐推荐
Music pop trend prediction and recommendation analysis based on big data
Abstract
The music pop trend prediction model construction based on machine learning uses only the data close to the predicted target time period. In this paper, the grouping experiment is conducted after song clustering: based on the fuzzy set theory, decompose the time information particles and construct the "triangle" model; to predict the low, R and up parameters of the triangle model by SVM, we can get accurate short-time space and trend change. This is an important guiding role in the original behavior, usage behavior and carrier marketing activities on the platform.
The system realizes the collection of music score (Python crawler crawl data), the back end uses the big teaching data recommendation algorithm construction, and the front end uses the MVC framework to build the big data music recommendation system. The systematic reference order uses the relational reference library MySQL. The front end collected user behavior data and passed it to the back end using a user-based collaborative filtering algorithm to recommend music that the user may like. The BS architecture was developed by using the Java programming language, MySQL database, Hadoop offline analysis, java open source tool Eclipse programming, Java's JRE running environment, JSP page and other tools.
Music pop trend forecast provides theoretical support and decision-making technical support for enterprises to predict the future pop music trend and predict the dark horse music, which has important commercial value. Compared with traditional prediction methods, building prediction models based on machine learning is not only theoretically perfect, but also has strong robustness and generalization ability in practice, which can be directly transplanted to the platform for application.
Key words: big data; Hadoop; Python; Java; music data analysis; music recommendation
目录
2.1.1 全球开源的Linux系统-Ubuntu..................................................................... 8
2.1.2 开源分大数据处理平台Hadoop..................................................................... 8
3.2.1 音乐格式转换与时长处理............................................................................ 12
3.6.1 HMM算法(隐马尔可夫模型)........................................................................ 27
第1章 前 言
1.1 研究背景
互联网在如今的爆发式发展中已经完完全全地改变了的生活方式。互联网上资源的爆发时增长让上网冲浪者获取有效信息成为了如今新的难题。用户接触到的信息十分有限。于是很多学者了很多提出帮助用户快速精准找到所需信息的解决方案,比如说搜索引擎,推荐系统等。
目前大型的音乐门户类网站的歌曲库往往包含上千万首的歌曲,这些歌曲被划 分成不同的语种、流派、年代、主题、心情、场景等,包含的信息非常的丰富,存在着 严重的信息过载。对于系统中每一位音乐用户来说,都不可能去收听曲库内的每一首歌, 很多时候用户的需求往往是“一首或几首好听的歌曲”这种模糊的需求,如何根据用户 在系统中产生的行为信息去庞大的歌曲库中挖掘出用户可能感兴趣的音乐,这就需要个 性化音乐推荐系统综合考虑用户偏好、时间、地点、环境等各种复杂的特征,准确的从 上千万的海量歌曲库中筛选出此时此刻最适合这个用户聆听的个性化音乐,给广大的用户带来美的享受,真正做到众口可调[6]。
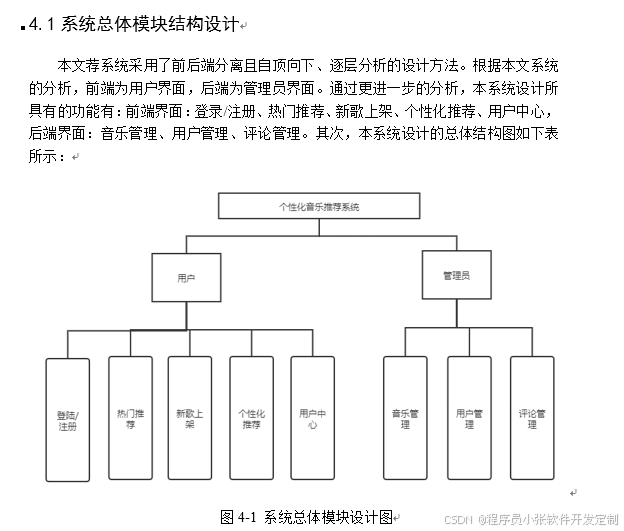
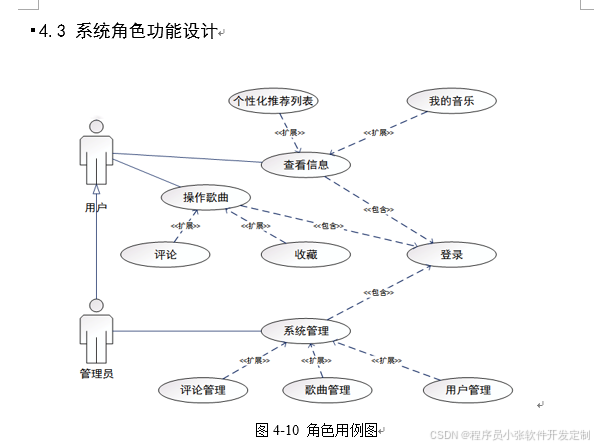
论文基于大数据的音乐流行趋势预测及推荐分析,主要目的是给用户推荐用户可能喜欢的音乐,使用了较为先进的基于用户的协同过滤算法。用户登录本系统可以享受在遨游在音乐海洋里的感觉,能够听自己喜欢的歌曲,真正释放真正的自己。为了方便用户能够尽情的享受本系统,系统的管理员账户可以对不正当音乐、评论、用户进行管理,还可以发布新歌等。
时代风云变幻,技术日新月异,音乐平台个性化是大势所趋。大数据的时代下,如果连顺势而为都做不到,更别提做时代的弄潮儿了。今天的推荐系统是这样的,明天可能就是那样了,我们要紧抓时代的运势。本系统做到了管理员与用户相分离,互不影响。在系统中将音乐推荐设为一项自动服务,每天早晨六点自动更新运行,能让用户每天都有一个新鲜感。除却推荐之外,用户在本系统中还能做到追赶潮流,发现当今热门,还能够去发现最近发行的专辑等。回过头来,用户甚至可以到用户中心,查看自己在本系统都有过哪些行为(点赞收藏,播放等)。随着用户数量的增多,管理员的作用表现得越发的重要。管理员的存在对净化系统,保护系统内歌曲环境有着至关重要的作用。
随着时间的推移,系统将会被更多的有志同道合的音乐发烧友加入进来,为大家庭做出一份不可或缺的力量。在用户和管理员的共同努力下,可以相信,本系统将会变得更加纯粹美好,让音乐宠幸的人们在这个系统内将会找到家的归属感。
1.2 研究现状
1.2.1 国内研究现状
国内的音乐推荐技术发展相比国外来说较慢。国内一些音乐网站采用的推荐系统技术并不是很成熟,好多是针对用户群体做的分类推荐,个性化成分不多。不过,近些年国内相关技术也在不断地发展壮大,也有一些优秀的个性化音乐推荐系统在市面上崭露头角,比如说网易云音乐、qq音乐、酷狗音乐等。网易云音乐是一个偏重于社交的音乐网站。在网易云音乐中,每一位用户都可以去查看自己好友最近在听哪些音乐,喜欢的音乐等等。并且网易云音乐中音乐分类非常的齐全,推荐列表可以每日更新。而且,系统通过用户听歌习惯等,可以找到相同兴趣的听者,更准确地做出推荐[9]。
1.2.2 国外研究现状
个性化推荐系统的定义是 Resnick和Varian 在 1997 年给出的:“它是利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销 售人员帮助客户完成购买过程”。从最初在电子商务网站的深度剖析,到当下在的音乐、电影、学习资料等不同领域的广泛应用。在三十多年的时间里,个性化 推荐系统一直是学术界和工业界的关注的焦点。其优点在于主动性。它能自发地 收集并分析用户的行为数据,为用户的兴趣建模,得到用户的兴趣偏好后,匹配系 统中资源的特征,为用户做出有效的个性化推荐。同时,推荐引擎要一直监测系统 中的项目变化和用户在不同行为下的兴趣特征变迁,针对不同的变动,做出相应推 荐策略的调整。各平台为增加用户的黏着性,以及用户对推荐结果的准确度要求,使得推荐系统的核心技术层出不穷,比较成熟的推荐技术有:基于内容的推荐、协同过滤(基于相似度的最邻近协同过滤算法、基于潜在因子的矩阵分解推荐算法)、深度学习、基于标签的推荐系统、混合推荐算法等[10]。
1.3 发展趋势
音乐疗法的研究和临床案例表明,音乐的某些物理特征会与人的神经系统产生共鸣,从而导致人体生理指标发生有益的变化。此外,音乐还可以产生心理节奏,这与人们的生理结构和功能非常一致。因此,取决于不同人的生理和心理反应,可以匹配不同的治疗音乐,并且可以实现个性化的音乐推荐。针对音乐推荐技术当前存在的问题,从“人文关怀”的角度出发,提出了音乐推荐技术研究与开发的新方向,其中生理指标与生理指标联系在一起。可以通过这些生理参数来修改特定类型音乐的人的心理状态,并将其与情绪状态实时组合以找到相应的音乐资源。
这项新技术的发展可以有效避免音乐推荐的商业化。无需比较点击率,用户关注度或音乐评级信息,因此不会因用户的心理或情感变化而出现明显的冷启动,稀有性或可扩展性问题。人性化的音乐推荐技术。
1.4 研究主要内容
本文数据集来源于阿里云音乐平台。本文以用户的历史播放数据为基础,通过对目标时间内艺人歌曲播放量的预测,挖掘出即将成为潮流的艺人,从而实现对一段时间内音乐流行趋势的准确把控。具体做法是分析用户行为信息和<艺人一一歌曲>信息后,预测歌手在未来一段时间内的播放热度。图1描述了整体的实验流程,主要包括以下几部分工作:
(1)分析并处理数据集。对音乐吸引用户成为平台忠实用户的原因进行分析,挖掘用户行为、歌曲信息、艺人信息潜在的规律,筛选出有效信息进行数据清洗、数据集成和数据转换。
(2)基于机器学习构建预测模型。针对音乐平台中象征流行趋势的月榜、周榜、每日金曲榜,采用人工神经网络和支持向量机分别预测月播放量、周播放量、日播放量。在人工神经网络模型中完成特征选择工作,支持向量机进行验证实验。
(3)构建组合组合预测模型。将人工神经网络和支持向量机两种算法进行线性组合构建音乐流行趋势的预测模型,并与单一模型进行对比。实验结果表明,组合模型可明显提升预测性能。
(4)变化预测模型的构建与分析。针对传统音乐流行趋势预测模型的构建仅使用了离预测目标时间段较近范围的数据,本文提出对艺人进行聚类分组,纪合模糊粒化方法与支持向量机构建新模型。实验表明可以准确预测出未来几天睦播放量的变化趋势和变化空间。
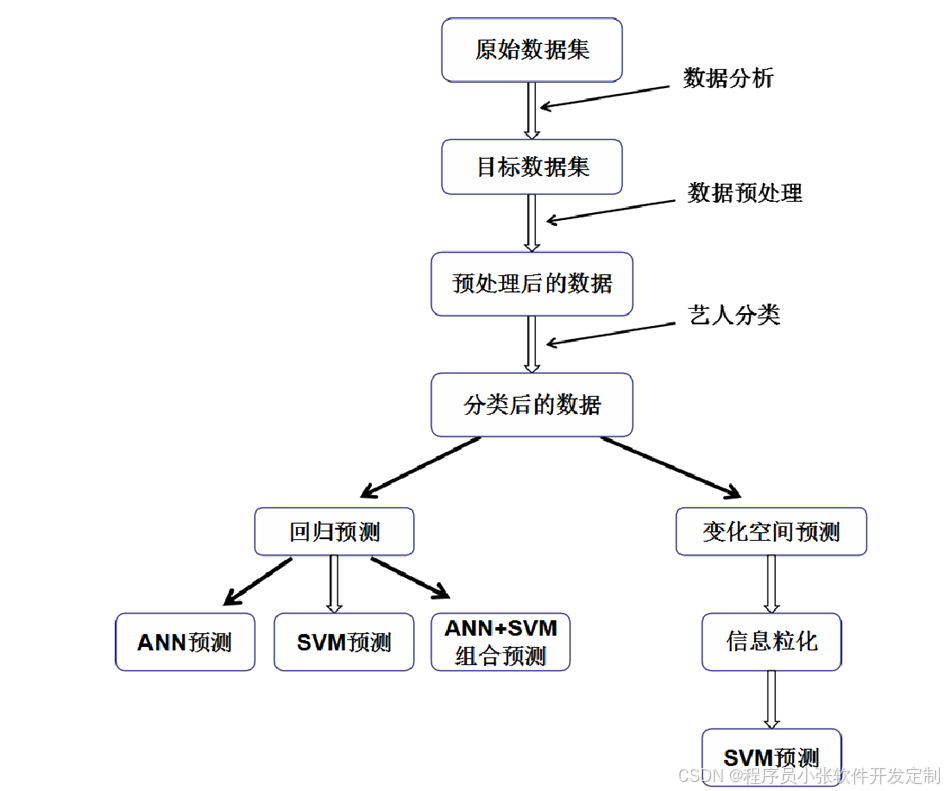
图1音乐流行趋势预测流程图
第2章 技术与原理
2.1 大数据环境
2.1.1 全球开源的Linux系统-Ubuntu
Linux是一个开放源码的、免费分发的类unix操作系统,适用于世界各地的pc和工作站,Ubuntu是Linux的一个分支发行套件。Ubuntu这个名字来源于南非祖鲁语或豪萨语“Ubuntu”,意思是“存在,因为每个人都存在”。这是非洲的传统和古老的价值观,即为每个人而生。自从Ubuntu诞生以来,一个巨大的社区诞生了。人可以从社区为Ubuntu做贡献,并且很容易从社区获得帮助。
Ubuntu不仅在个人桌面和服务器操作方面令人惊叹,而且在大数据方面也令人惊叹。其包容的态度提供了大数据处理平台(Hadoop)单机、伪分布式和分布式三种部署方式。它提供了强大的处理能力、交互能力、扩展能力,使数据可以在主机之间自由移动和快速处理。
2.1.2 开源分大数据处理平台Hadoop
Hadop是基于Apche软件基金会的开源分布式计算平台,可为用户提供系统底层细节的透明结构。为方便使用而开发,具有非常强大的跨平台工作功能,可以将其部署在较为廉价的计算机集群中。 MapReduce是Google MapReduce的开源实现。这让用户可以更容易去开发并行应用程序,不用了解分布式系统的基本细节。使用MapReduce将数据集成到分布式文件系统中可以使数据分析和处理更加高效。借助Hadoop,程序员可以轻松地创建分布式并行程序,并在廉价的计算机群集上运行它们,这样就可以完成大量数据的存储和计算。
2.1.3 shell
shell是Linux系统用户专有的界面,它的作用时给用户提供和linux内核交互的命令行界面。Shell页面端用来获取用户输入的信息,并将其提交给linux内核进行运行,之后将运行结果输出在shell页面端口。
2.1.4 kettle
Kettle是用纯Java编写的外部开源ETL工具,在Windows,Linux和Unix上均可运行,而且数据提取非常高效稳定。
Kettle的中文名叫做水壶。 该项目的主要程序员MATT希望用户将各种数据放入水壶中,能够以任意所指定的格式输出。
2.1.5 Scala
Scala是一种类似java的编程语言,设计初衷是为了既能继承java的优点,有用来弥补Java的缺点的一款全能编程语言。
2.2 数据获取与处理
2.2.1 Pymysql
Mysql是如今最为普遍的数据库里,而python作为比较流行的语言之一,自然少不了与mysql做交互,其中pymysql就是使用最多的工具库了。Python导入pymysql之后,配置完数据库就可以直接操作数据库内各种表等。
2.2.2 Urllib.request
Urllib.request 模块定义了适用于在各种复杂情况下打开 URL(主要为 HTTP)的函数和类 --- 例如基本认证、摘要认证、重定向、cookies 及其它。Requests 继承了urllib2的所有特性。Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。Requests的文档非常完备,中文文档也相当不错。Requests能完全满足当前网络的需求,支持Python 2.6—3.8,而且能在PyPy下完美运行。
2.2.3 besutifulsoup4
HTML 文档本身是结构化的文本,有一定的规则,通过它的结构可以简化信息提取。于是,就有了lxml、pyquery、BeautifulSoup等网页信息提取库。一般会用这些库来提取网页信息。其中,lxml 有很高的解析效率,支持 xPath 语法(一种可以在 HTML 中查找信息的规则语法);pyquery 得名于 jQuery(知名的前端 js 库),可以用类似 jQuery 的语法解析网页。
BeautifulSoup(下文简称 bs)翻译成中文就是“美丽的汤”,这个奇奇怪怪的名字取自于《爱丽丝梦游仙境》,bs 最大的特点就是简单易用,不需要像正则和 xPath 等工具必须牢记很多特定的语法。虽然效率更高更直接,但对大多数 python 使用者来说,好用会比高效更重要。
2.3网页端
2.3.1 tomcat9
Tomcat是Apache Software Foundation的Jakarta项目的核心组件,该项目是由Apache,Sun和一些公司和个人开发的轻量级Web应用程序服务器。是Servlet和JSP规范的开源实现。由于其技术非常先进,而且工作稳且性能高,它深受java爱好者的追捧,很多开源边界者都对他赞赏有加。目前呢已经成为最流行流行的Web应用程序服务器。
2.3.2 spring
Spring框架是Rod Johnson启动的开源J2EE应用程序框架,而Rod Johnson是用于bean生命周期管理的轻量级容器。 Spring解决了J2EE开发过程中开发人员遇到的较多常见问题,还提供了非常实用的功能,例如IOC,AOP,Web MVC等。 Spring甚至可以单独构建,也可以与Struts,Webwork和Tapstry等桌面应用程序结合以创建JEE,桌面和小型应用程序。
4.5 大数据平台搭建设计
4.5.1 hadoop的安装与配置
大数据平台的搭建都是在Ubuntu16.04下搭建完成的。在搭建Hadoop,需要安装java,并合理的配置好java的环境变量。这里选择的java版本为:1.8.0_162。首先将其解压到/usr/bin/下,在terminal下输入sudo tar -zxvf java包 -C /usr/bin/之后,系统会自动解压java安装包到指定目录下。为了之后配置环境更加方便,将解压过后的文件夹重命名为java。之后需要对java进行环境配置,将java安装目录配置到bashrc文件中。在terminal下输入sudo vim ~/.bashrc,在文件第一行添加环境配置语句,如下图。

图4-16 Java配置
配置好之后,保存文件并退出。在terminal中输入java和javac,若输出如下图所示,则jva环境配置成功。
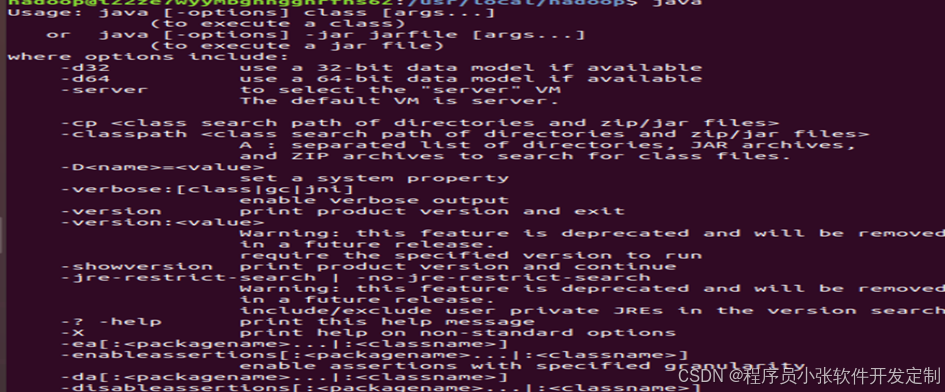
图4-17 Java环境检验

图4-18 Javac环境检验
配置好java后,开始配置Hadoop。首先在terminal中输入sudo tar -zxvf hadoop安装包 -C /usr/local/,之后系统会帮把Hadoop安装包解压到指定目录下。为了之后查找和使用方便,将Hadoop解压过后的文件夹重命名为hadoop。因hadoop分单机模式,伪分布模式和分布式模式三种,所以要自行选择配置文件配置。这里选择配置伪分布式模式,于是需要修改三个文件。将/usr/local/Hadoop/etc/Hadoop/下的core-site.xml修改为图所示。将/usr/local/Hadoop/etc/Hadoop/下的hdfs-site.xml修改为图所示。
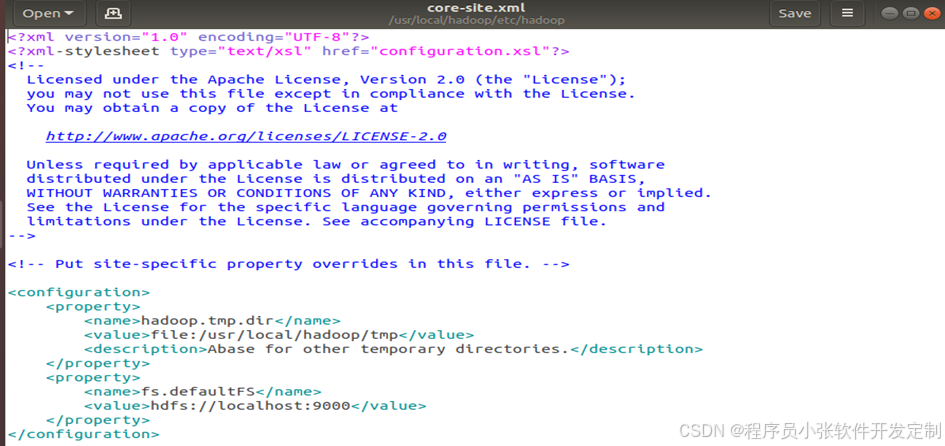
图4-19 core-site.xml配置
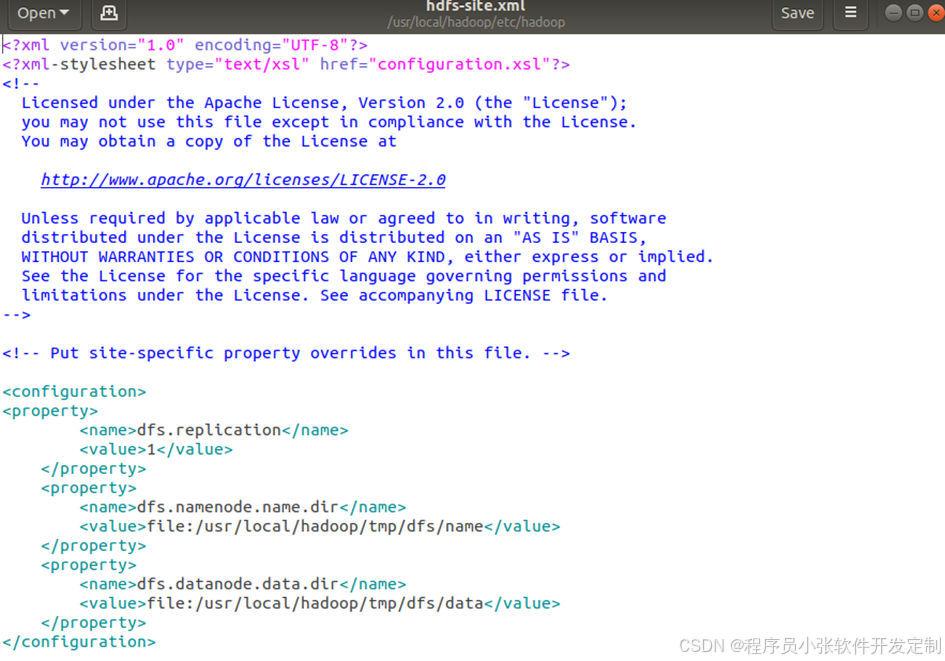
图4-20 Hdfs-core.xml配置
修改完成之后,要执行名称节点的格式化。需要在terminal中输入:cd /usr/local/Hadoop ./bin/hdfs namenode -format。如果格式化成功,terminal中会出现successfully formatted 和Exiting with status 0的提示信息。之后需要启动hadoop去检查hadoop是否正常启动。在terminal中输入start-all.sh之后,再次输入jps。输出如下图所示,为hadoop安装成功。
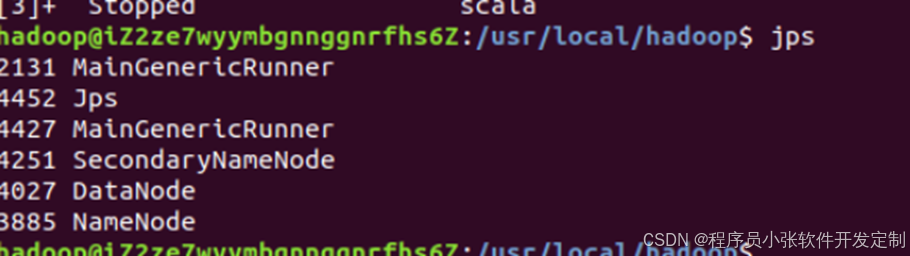
图4-21 Hadoop安装检验
4.5.2 spark的安装
Spark的安装部署模式有四种:单机模式,集群模式,yarn模式,mesos模式。这里为了搭配hadoop一起使用,采用单机部署模式。首先将spark安装包解压到/usr/local/下,在terminal中输入 tar -zxvf spark安装包 -C /usr/local/。为了之后操作方便,将解压后的文件夹重命名为spark。之后,在spark-env.sh中添加spark的配置信息。配置完成之后,可以通过spark自带的实力sparkpe来测试spider是否正常运行。在terminal中输入bin/runexample spiderpi,输出如下图所示。即spark安装成功。

图4-22 Spark测试
4.6 推荐算法设计
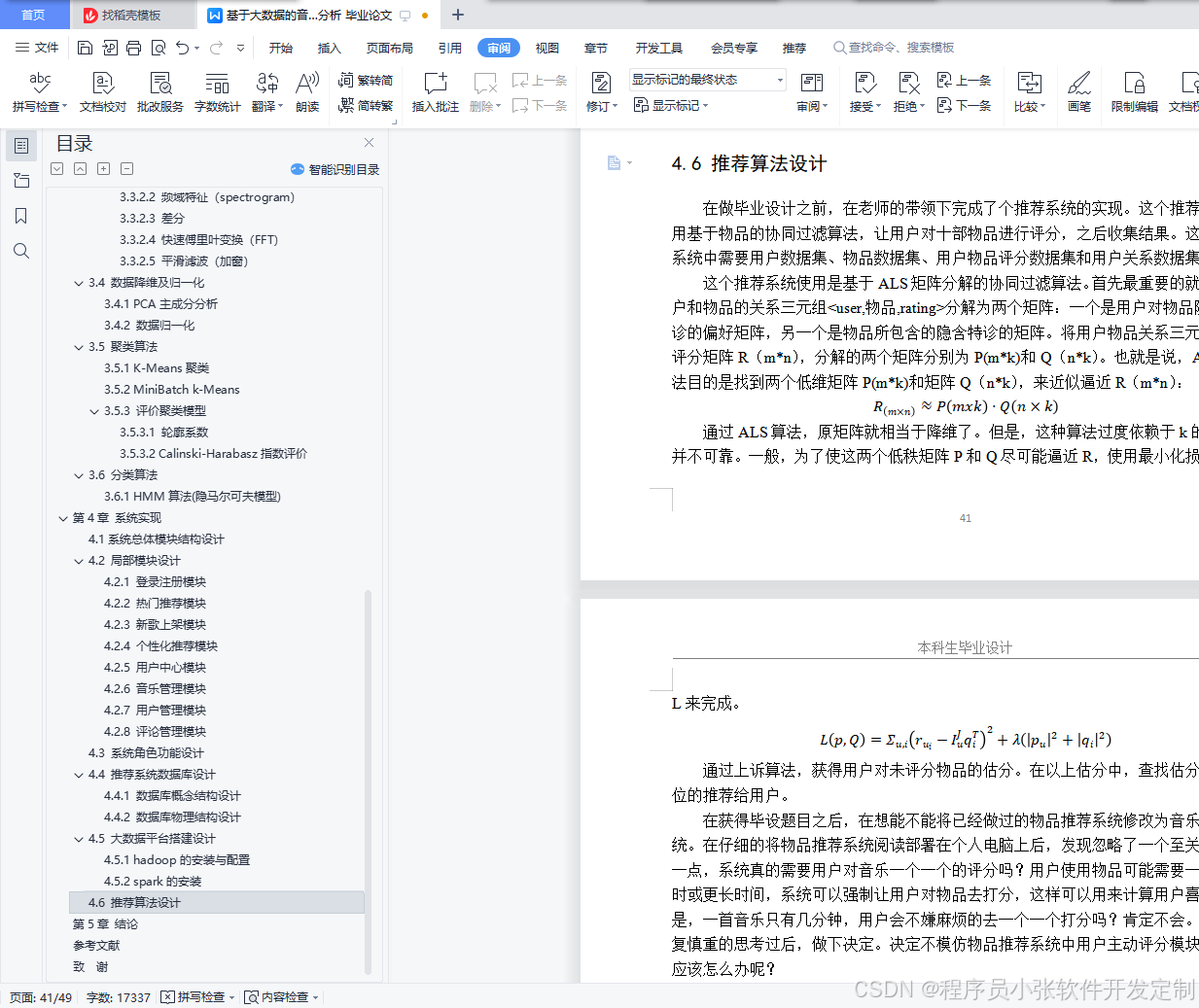
在做毕业设计之前,在老师的带领下完成了个推荐系统的实现。这个推荐系统采用基于物品的协同过滤算法,让用户对十部物品进行评分,之后收集结果。这个推荐系统中需要用户数据集、物品数据集、用户物品评分数据集和用户关系数据集。
这个推荐系统使用是基于ALS矩阵分解的协同过滤算法。首先最重要的就是将用户和物品的关系三元组<user,物品,rating>分解为两个矩阵:一个是用户对物品隐含特诊的偏好矩阵,另一个是物品所包含的隐含特诊的矩阵。将用户物品关系三元组看作评分矩阵R(m*n),分解的两个矩阵分别为P(m*k)和Q(n*k)。也就是说,ALS算法目的是找到两个低维矩阵P(m*k)和矩阵Q(n*k),来近似逼近R(m*n):
Rm×n≈Pmxk⋅Qn×k
通过ALS算法,原矩阵就相当于降维了。但是,这种算法过度依赖于k的取值,并不可靠。一般,为了使这两个低秩矩阵P和Q尽可能逼近R,使用最小化损失函数L来完成。
Lp,Q=Σu,irui-IuJqiT2+λpu2+qi2
通过上诉算法,获得用户对未评分物品的估分。在以上估分中,查找估分在前几位的推荐给用户。
在获得毕设题目之后,在想能不能将已经做过的物品推荐系统修改为音乐推荐系统。在仔细的将物品推荐系统阅读部署在个人电脑上后,发现忽略了一个至关重要的一点,系统真的需要用户对音乐一个一个的评分吗?用户使用物品可能需要一两个小时或更长时间,系统可以强制让用户对物品去打分,这样可以用来计算用户喜好。可是,一首音乐只有几分钟,用户会不嫌麻烦的去一个一个打分吗?肯定不会。经过反复慎重的思考过后,做下决定。决定不模仿物品推荐系统中用户主动评分模块了。那应该怎么办呢?
左思右想还是想不到怎么在不让用户打分的情况下去获取用户对音乐的评分。突然,注意到酷狗音乐音乐也没有收集用户对音乐的评分。那酷狗音乐是怎么实现的呢?通过调查分析,了解到了酷狗音乐音乐采用的是行为数据分析。这个点子刺激到了,不如对用户的行为也进行分析。

图4-23 听众行为
一般用户在音乐平台的操作分为:播放,喜欢,下载,评论等。不如就将这些操作分别赋予不同的权值,用户进行操作时,进行记录并作为用户对音乐的内心评分。这里,用户每点击一次播放这首音乐,那么用户对这首音乐的评分加一分;用户点击下载这首音乐,那么用户对这首音乐的评分加两分;用户点击收藏这首音乐,那么用户对这首音乐的评分加五分。如果之前加权之和超过十分,按十分计算。那么通过用户的行为,就可以获得用户对该音乐的评分了。
图4-24 生成用户音乐评分表
既然数据已经获取好了,那接下来应该获取什么推荐算法呢?一般来说基于物品的协同过滤算法在电子商务、电影、图书等应用领域中得到了广泛使用,而基于用户的协同过滤算法适合应用于新闻推荐、微博话题、音乐推荐等应用场景。于是,为了推荐算法更加的合理准确,选择基于用户的协同过滤算法来做个性化音乐推荐算法[3]。
基于用户的协同过滤算法主要包括两个步骤:1.找到和当前用户兴趣相同的用户集合。2.找到这个音乐集合中当前用户可能喜欢,但是当前用户并没有听过的歌曲。
步骤一的实现是通过计算当前用户与其他用户的兴趣相似度。在其他用户中找到与当前用户兴趣相似度最高的那位或几位。步骤二的实现通过计算当前用户与未听过的歌曲之间的兴趣度。在计算多个数值后,选取数值最高的那几位推荐给当前用户[5]。
具体算法如下所示,需要计算用户与其他用户的兴趣相似度,可以采用欧式距离算法计算用户之间的相似度,即:
L=1+i=0kki-ki+12
在欧式距离中,面临到把每相邻两项之间差值的平方相加在取根号下,这很耗费计算机的性能。不如将其根号取下,换成差方之和除以k,这将会减掉不少计算器的性能。变形后的公式如下所示。
L=i=0kki-ki+12k
如果采用未变形之前的公式,计算式子的结果,会介于(0,1)之间,且越接近与1,二者的相似度越高。变形之后的公式的取值范围就较为广泛了。如果式子的值越大则表明二者之间的相似度越高。
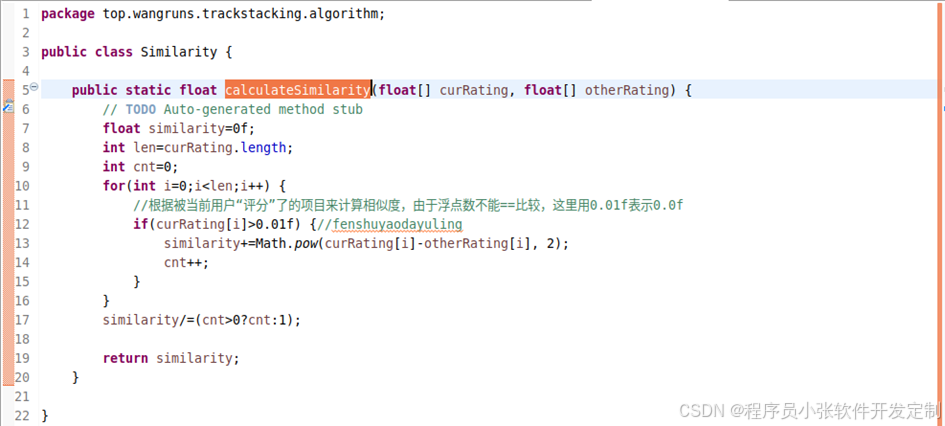
图5-25 用户兴趣相似度计算
系统采用上述式子,一一计算当前用户与其他用户之间的相似度,并将计算出结果写入到堆中,以便之后计算出有高于之前的将其替换掉。
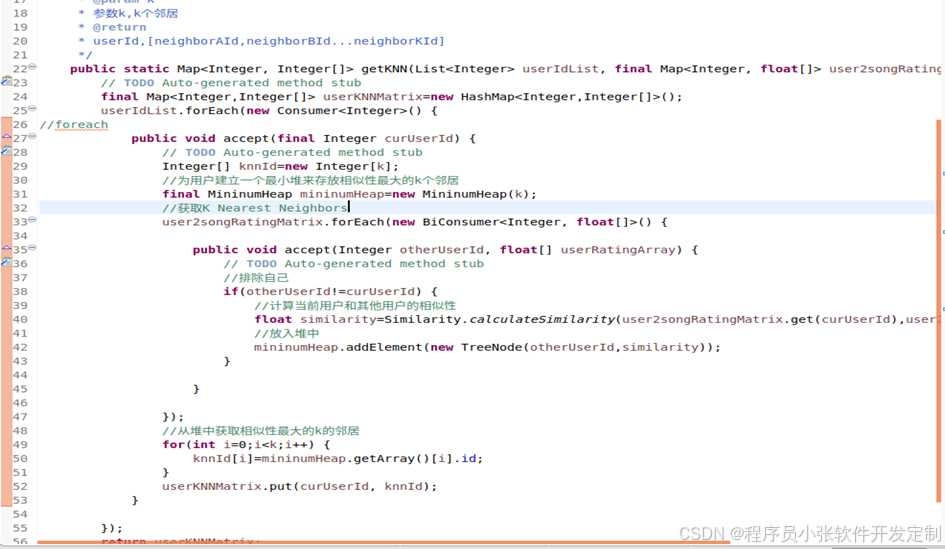
图5-26 设置堆存储相似度最高的用户id
既然已经获得了与用户之间相似度最高的几位用户了,就可以从中得到用户没有听过哪些歌曲,并开始计算用户与歌曲之间的相似度了。计算用户对音乐的相似度,根据我们已经获得了的评分音乐来计算相似度similarity。根据上述公式改写成java程序如下所示。
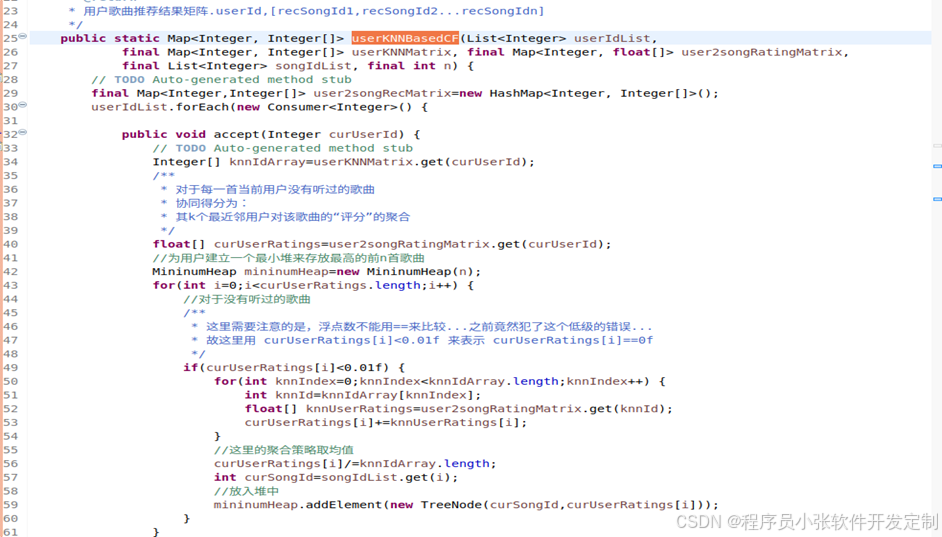
图4-27 计算用户对物品的相似度
系统中的推荐算法部分已经完成了,可是每计算用户一次推荐结果都要耗费大量的时间和算力。于是,我们将推荐算法部分设为一个服务,定时让其运行一次。为了用户每天都能获得一次推荐结果,系统将其设置为早晨六点开始运行计算所有用户的推荐列表。
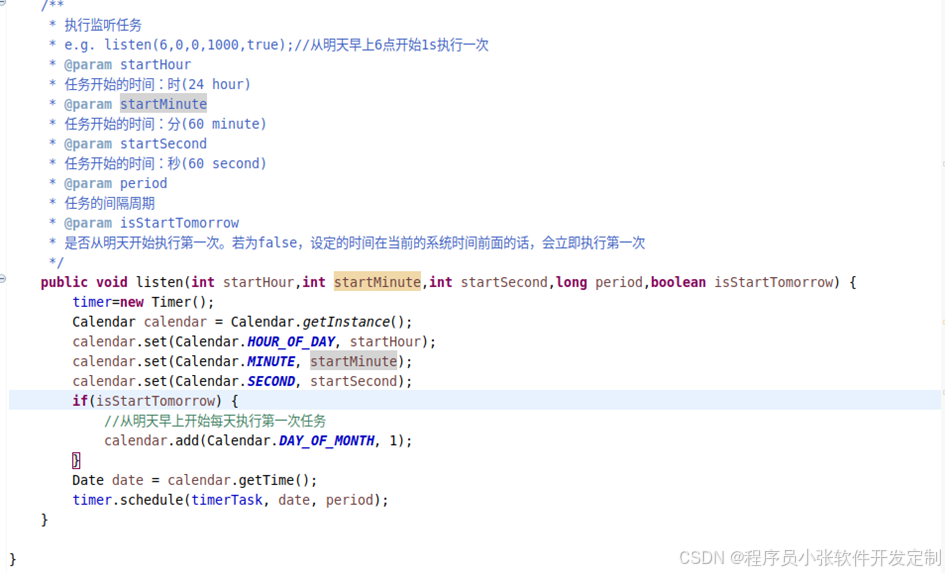
图4-28 设置音乐推荐算法开启时间
推荐系统的推荐算法本应写到这里就算结束了,但是,只是考虑怎么去实现未免太过于心急。在算法最开始的地方,我需要去收集用户的行为数据。可是,一个新的用户进入系统,我怎么去把握用户的喜好呢?于是,推荐算法从一开始就错了吗?不,没错。系统都是从没有数据到有数据一步步走来的,没有数据我们可以让用户去主动点击创造数据。
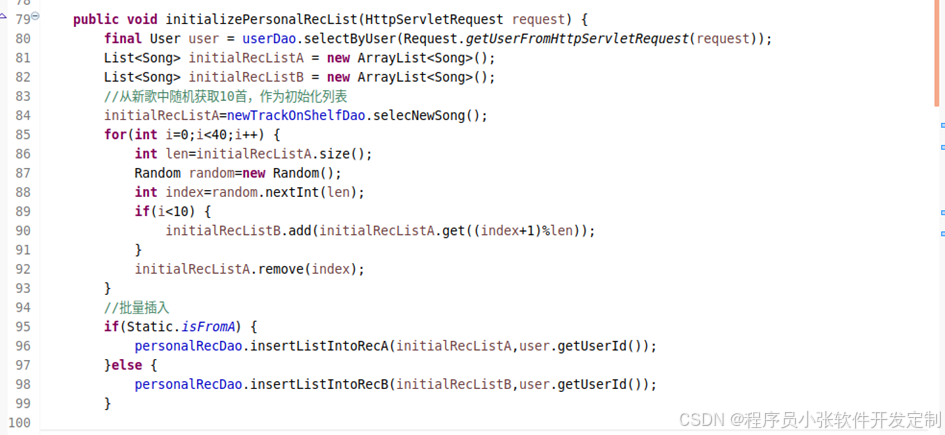
图4-29 开启冷启动
这里我认为需要引入冷启动的概念。在用户进入推荐系统之后,我们没有掌握用户的行为数据,可以先为用户推荐当下热门的几首歌曲,这样一来系统就可以不失风趣的开始推荐之旅了。
论文 源码效果截图:

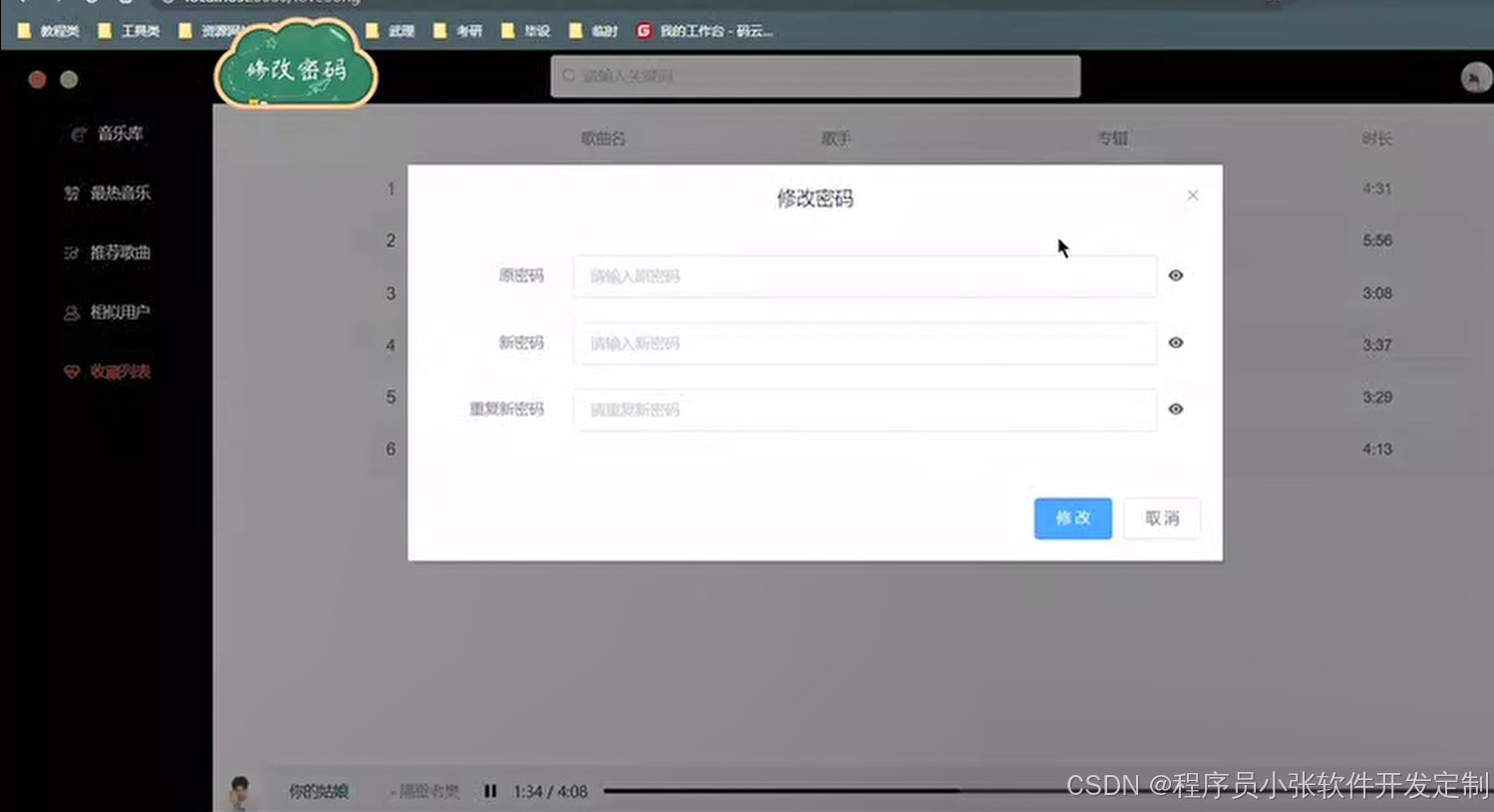
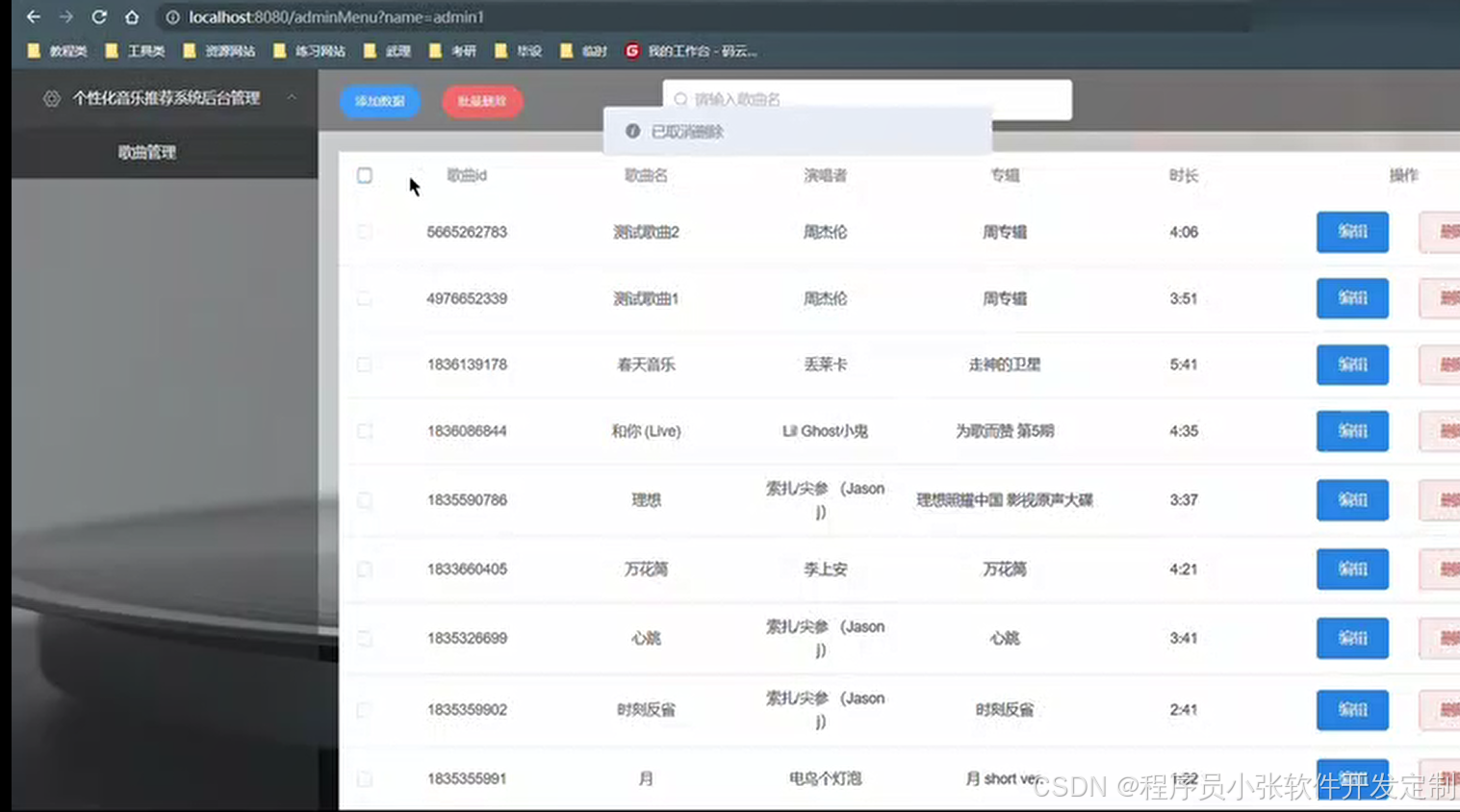
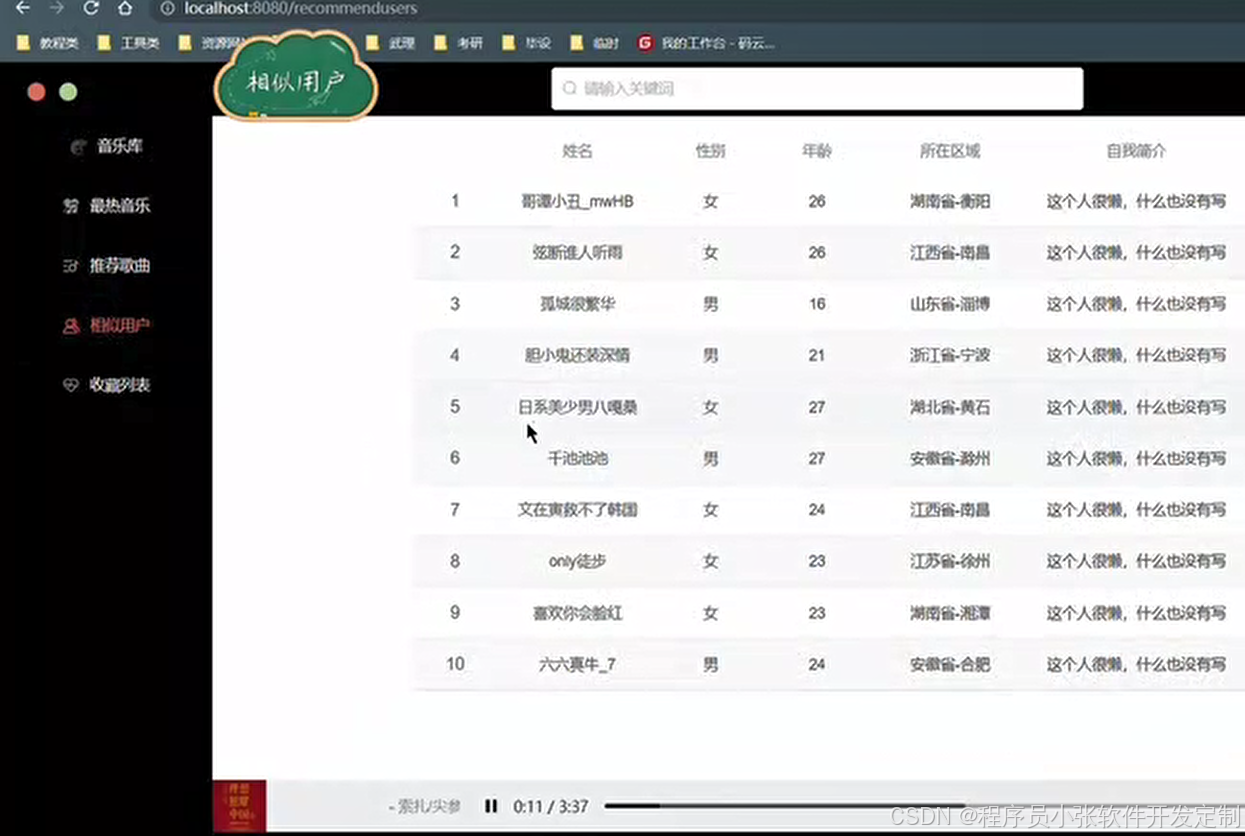

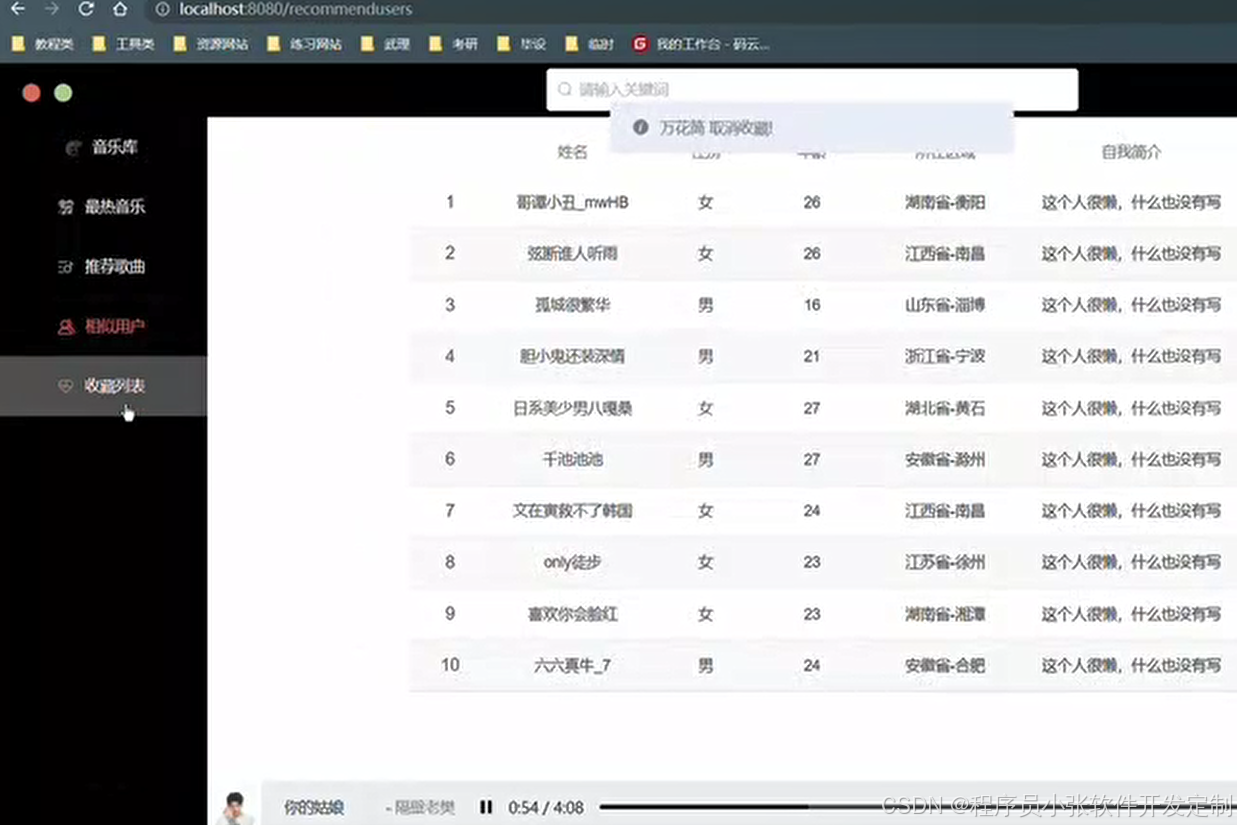

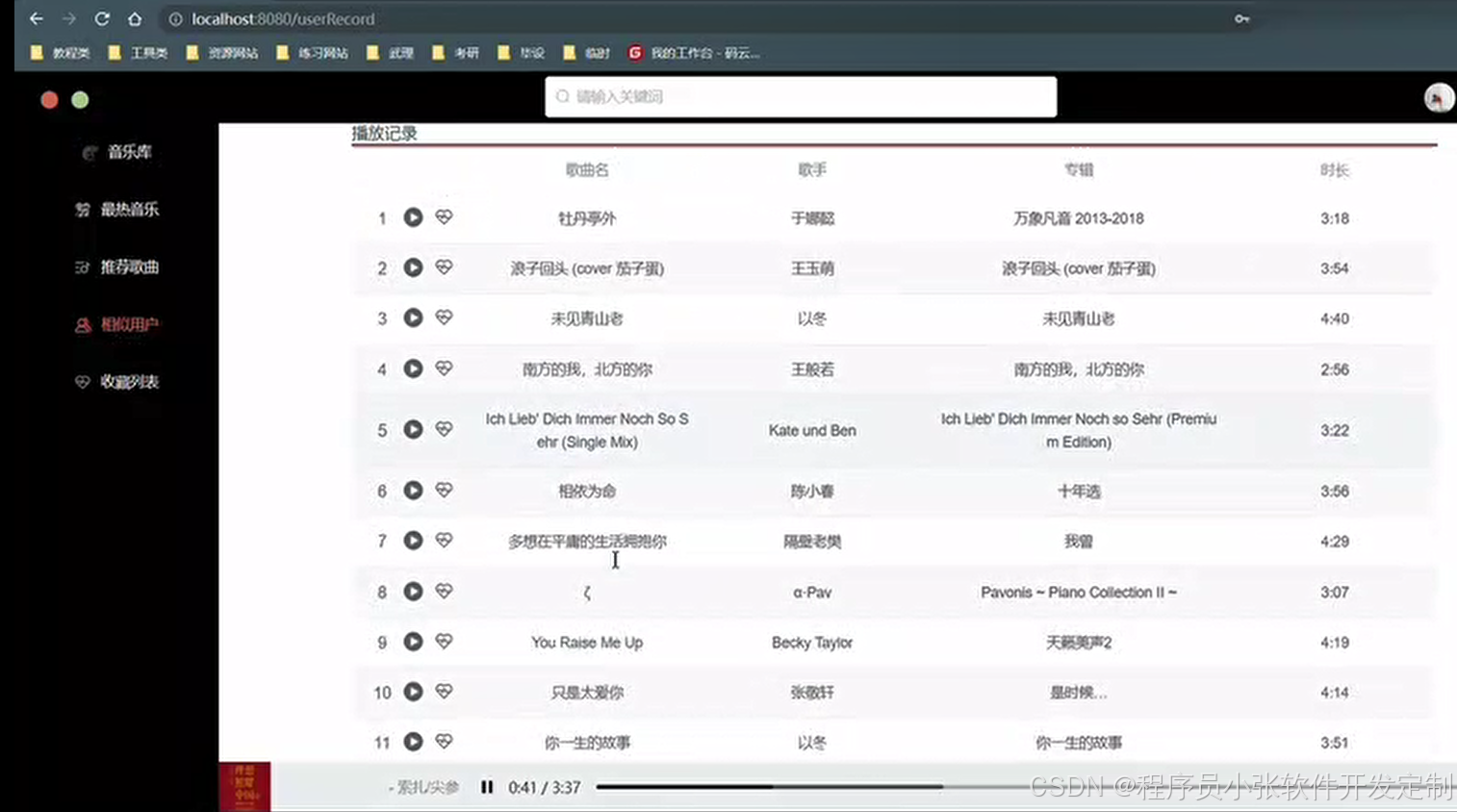
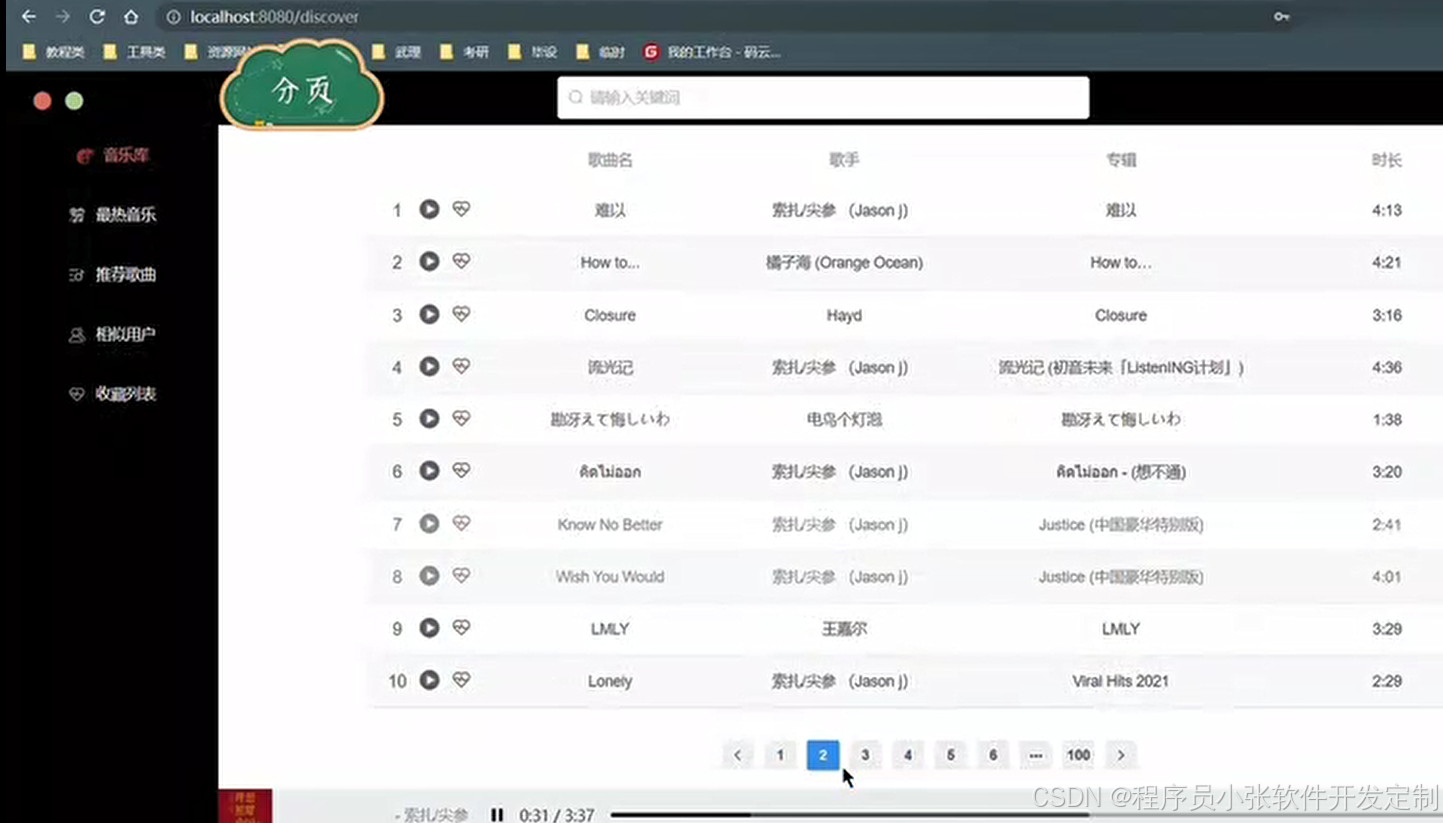
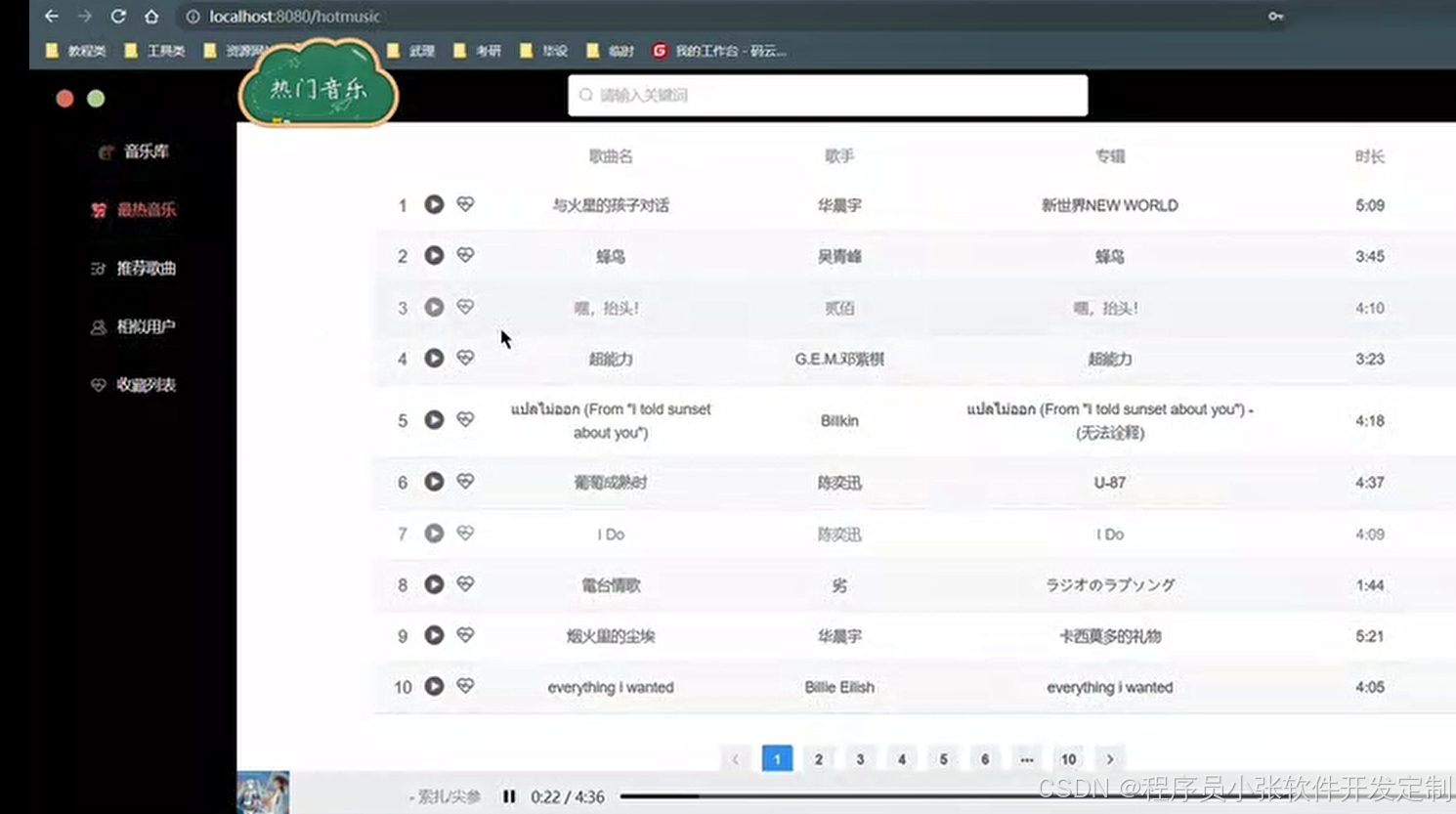
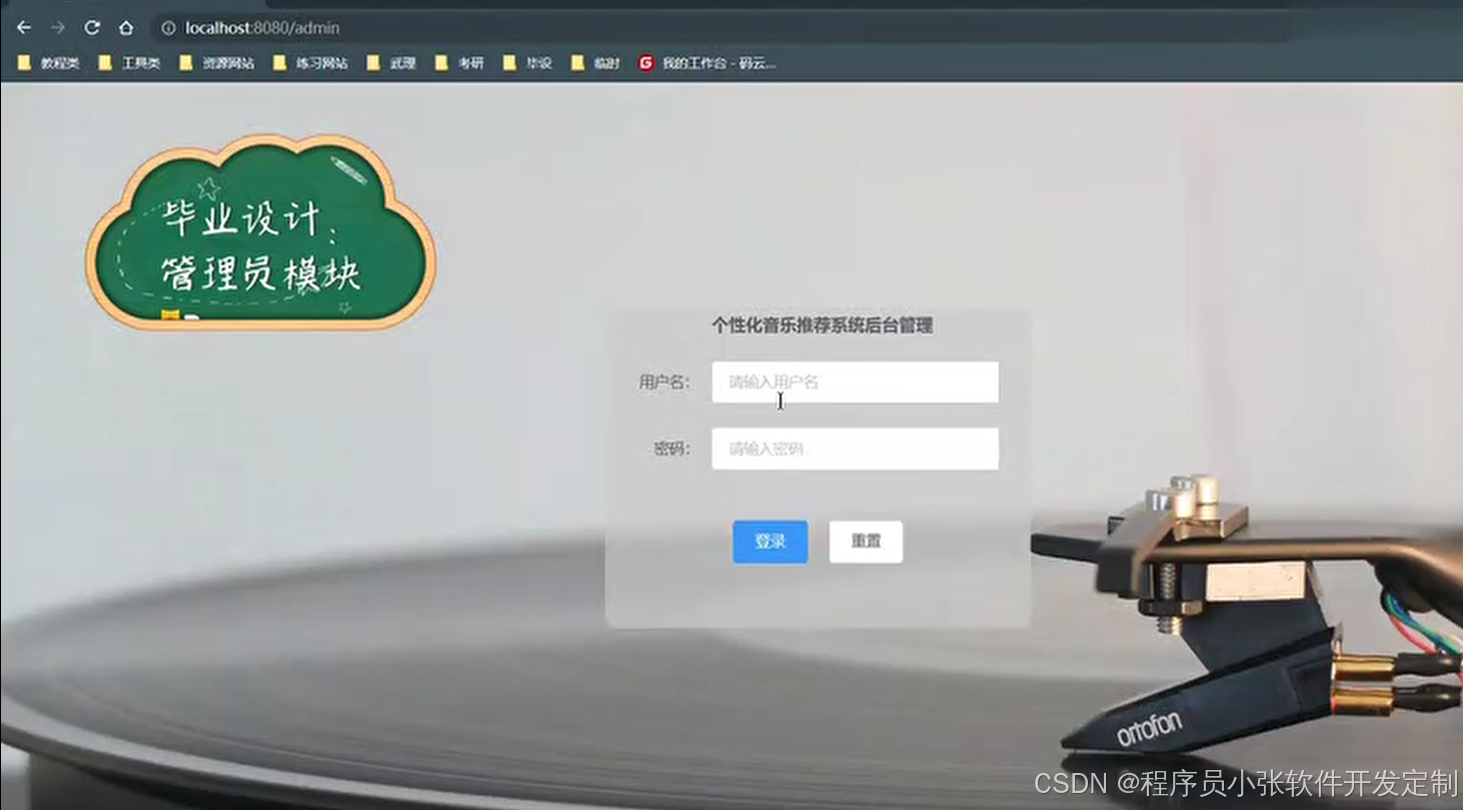
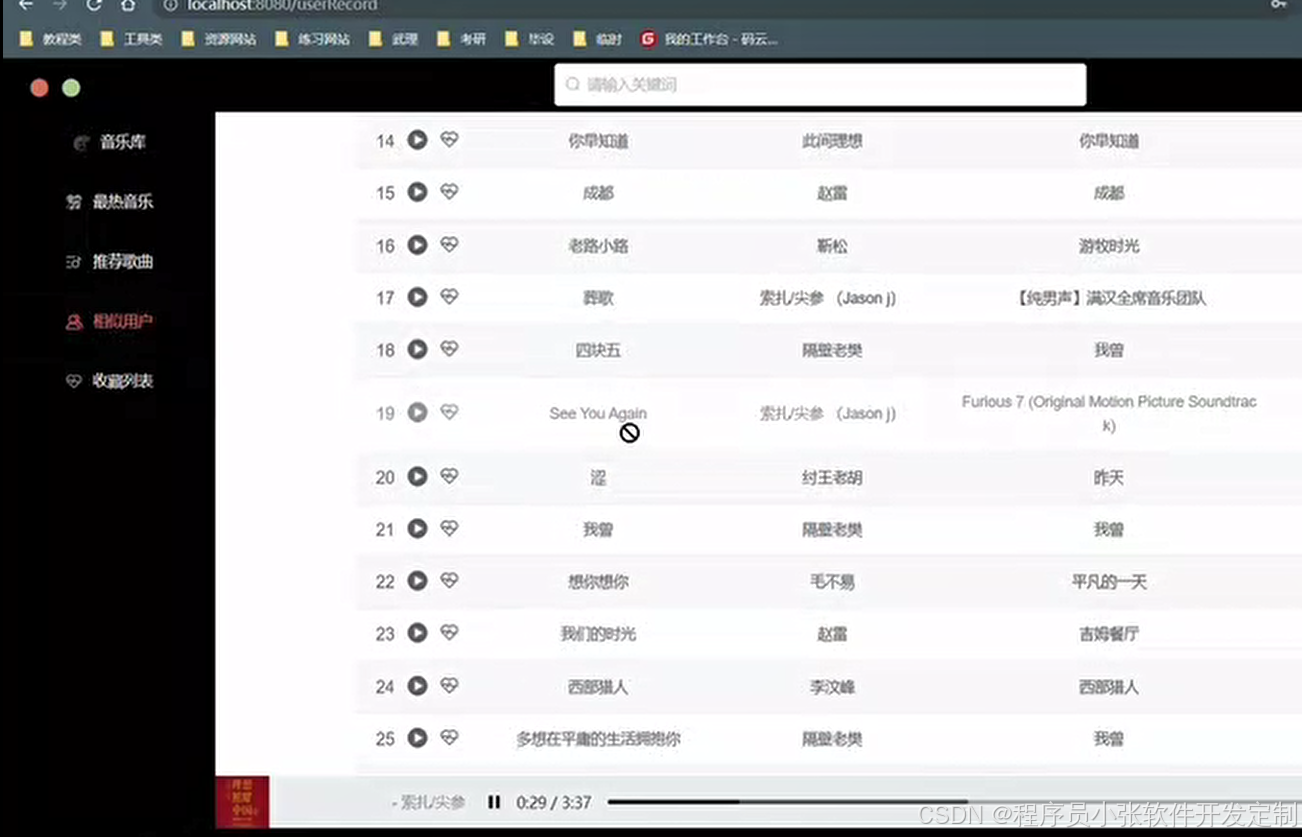
更多项目:
另有10000+份项目源码,项目有java(包含springboot,ssm,jsp等),小程序,python,php,net等语言项目。项目均包含完整前后端源码,可正常运行!
!!! 有需要的小伙伴可以点击下方链接咨询我哦!!!


















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











