







!!! 有需要的小伙伴可以通过文章末尾名片咨询我哦!!!
💕💕作者:毕业通通通
💕💕个人简介:本人在读博士研究生,拥有多年程序开发经验,辅导过上万人毕业设计,支持各类专业;如果需要论文、毕设辅导,程序定制可以联系作者
💕💕各类成品java系统 。javaweb,ssh,ssm,springboot等等项目框架,源码丰富,欢迎咨询交流。学习资料、程序开发、技术解答、代码讲解、源码部署,需要请看文末联系方式。
摘 要
本研究设计并实现了一种基于朴素贝叶斯算法的垃圾邮件检测与过滤系统。随着电子邮件在日常通信中的广泛应用,垃圾邮件问题日益严重,不仅降低了用户的工作效率,也增加了网络的负担,并可能对用户的信息安全构成威胁。为有效解决这一问题,本系统采用了朴素贝叶斯分类器,依据邮件内容的文本特征进行学习和分类,以区分垃圾邮件和正常邮件。
系统开发过程中,首先对邮件文本数据进行预处理,包括词干提取、停用词过滤和分词等,旨在提取出对分类有帮助的有效信息。基于处理后的文本数据,选择具有代表性的关键词作为特征,构建特征向量。采用朴素贝叶斯算法,根据邮件内容计算其属于垃圾邮件和正常邮件的条件概率,通过比较这些概率的大小来完成邮件分类。
除了基础的邮件分类功能,系统还提供了敏感词过滤、训练集管理、黑白名单设置等高级功能。通过图形用户界面(GUI),用户可以轻松地进行邮件过滤规则的设置和调整,查看分类结果,以及管理屏蔽词和邮件发送者黑白名单,提高了系统的实用性和用户的操作便利性。系统的实现验证了朴素贝叶斯算法在垃圾邮件识别任务中的有效性和高效性。通过对不同训练集的学习和测试,系统展示了良好的分类性能和灵活的适应性。此外,系统的敏感词过滤和黑白名单功能,进一步增强了邮件过滤的准确性和用户体验。未来的工作将探索更多的特征选择方法和算法优化策略,以提升系统的整体性能。
关键词:朴素贝叶斯;垃圾邮件检测与过滤;实用性;高效性
ABSTRACT
This study designs and implements a spam detection and filtering system based on the Naive Bayes algorithm. With the widespread use of email in daily communications, the problem of spam has become increasingly serious, which not only reduces users' work efficiency, but also increases the burden on the network and may pose a threat to users' information security. In order to effectively solve this problem, this system uses a naive Bayes classifier to learn and classify based on the text features of email content to distinguish spam and normal emails.
During the system development process, the email text data was first pre-processed, including stemming, stop word filtering and word segmentation, etc., in order to extract effective information that is helpful for classification. Based on the processed text data, representative keywords are selected as features and feature vectors are constructed. The Naive Bayes algorithm is used to calculate the conditional probabilities of spam and normal emails based on the email content, and the email classification is completed by comparing the sizes of these probabilities.
In addition to basic email classification functions, the system also provides advanced functions such as sensitive word filtering, training set management, and black and white list settings. Through the graphical user interface (GUI), users can easily set and adjust email filtering rules, view classification results, and manage blocked words and email sender black and white lists, which improves the practicality of the system and user convenience. The implementation of the system verifies the effectiveness and efficiency of the Naive Bayes algorithm in spam identification tasks. Through learning and testing on different training sets, the system demonstrates good classification performance and flexible adaptability. In addition, the system's sensitive word filtering and black and white list functions further enhance the accuracy of email filtering and user experience. Future work will explore more feature selection methods and algorithm optimization strategies to improve the overall performance of the system.
Keywords: Naive Bayes; spam detection and filtering; practicality; efficiency
目 录
随着电子邮件的广泛使用,垃圾邮件问题已成为影响电子邮件通讯质量的重要挑战之一。垃圾邮件不仅浪费了用户的时间和网络资源,还可能包含恶意内容,对用户造成安全威胁。为了解决这一问题,本文提出了基于朴素贝叶斯的垃圾邮件检测与过滤系统设计。朴素贝叶斯是一种简单而有效的机器学习算法,通过统计学习来预测给定数据点的分类概率。本系统通过建立基于文本特征的朴素贝叶斯分类器,对电子邮件进行分类,将其分为垃圾邮件和非垃圾邮件。通过实验验证,本系统在垃圾邮件检测方面表现出良好的性能,为用户提供了高效的电子邮件过滤服务。
随着互联网的普及和电子邮件的广泛应用,垃圾邮件问题日益严重,给用户的网络体验带来了不小的困扰。垃圾邮件不仅占用了用户的宝贵时间,还可能传播恶意软件、诈骗信息等危险内容,对个人和企业的信息安全构成威胁。因此,设计高效的垃圾邮件检测与过滤系统具有重要的研究意义和实际价值。
垃圾邮件检测与过滤系统能够提高用户的电子邮件使用体验。传统的手动过滤方式效率低下且不够智能化,而基于机器学习算法的自动化系统可以更准确地识别垃圾邮件,有效减少用户接收到的垃圾信息,提高了用户的工作效率和生活质量。
垃圾邮件检测与过滤系统对网络安全具有重要意义。垃圾邮件往往伴随着恶意链接、恶意附件等,用户误点击可能导致个人隐私泄露、金融信息被窃取等严重后果。通过及时过滤掉这些垃圾邮件,可以有效降低网络攻击的风险,维护用户的信息安全。
垃圾邮件检测与过滤系统还对企业的邮件管理和运营效率有着积极影响。企业经常面临大量的电子邮件通讯,如果没有有效的垃圾邮件过滤系统,会浪费大量的人力和时间去处理垃圾信息,影响了企业的正常运营。而引入高效的垃圾邮件检测与过滤系统,则可以节省企业的成本,提高邮件管理的效率和质量。
综上所述,设计基于朴素贝叶斯的垃圾邮件检测与过滤系统不仅有助于提升用户的电子邮件使用体验,保障网络安全,还可以提高企业的运营效率,具有重要的研究意义和实际应用价值。
垃圾邮件检测与过滤系统是信息安全领域的一个重要研究方向,吸引了国内外众多研究者的关注与探索。本节将从国内外两个方面对垃圾邮件检测与过滤系统的研究现状进行探讨。
-
-
- 国内研究现状
-
在国内,针对垃圾邮件检测与过滤系统的研究取得了一系列进展。传统方法主要包括基于规则的过滤方法和基于特征工程的机器学习方法。随着机器学习技术的发展,基于机器学习的垃圾邮件检测系统成为主流。
近年来,国内研究者在垃圾邮件检测领域进行了大量实证研究,以提高分类器的准确性和鲁棒性。常用的机器学习算法包括朴素贝叶斯、支持向量机、决策树等。其中,朴素贝叶斯算法因其简单高效,得到了广泛应用。
此外,国内的研究者还致力于探索深度学习在垃圾邮件检测中的应用。深度学习模型如卷积神经网络(CNN)和循环神经网络(RNN)等在处理自然语言文本方面具有优势,能够更好地捕捉文本中的语义信息,提高垃圾邮件检测的效果。
-
-
- 国外研究现状
-
在国外,垃圾邮件检测与过滤系统的研究也十分活跃。与国内类似,国外的研究重点也在于提高分类器的准确性和泛化能力。
许多国外研究者将注意力放在特征工程和特征选择上,通过提取邮件文本的各种特征来增强分类器的性能。常用的特征包括词频、字符频率、邮件头部信息等。
此外,国外的研究还涉及到对抗性机器学习方法,旨在提高垃圾邮件检测系统对抗攻击的能力。通过引入对抗性样本,研究者探索如何让分类器在面对恶意攻击时保持高准确率。
在垃圾邮件检测系统的实际应用方面,国外的研究者也着重考虑系统的可扩展性和实用性。他们致力于设计高效的算法和系统架构,以应对大规模邮件流量和实时性要求。
国内外对垃圾邮件检测与过滤系统的研究取得了一系列进展,从传统方法到基于机器学习和深度学习的方法,不断提高了系统的检测准确性和鲁棒性。未来,随着技术的不断发展和新挑战的出现,垃圾邮件检测与过滤系统仍将是研究者们关注的重要领域,需要进一步探索和创新。
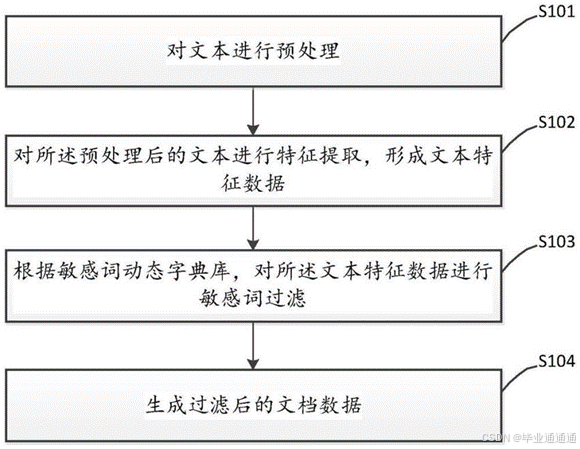
- 数据处理与建立词典:研究将文本文件中的正常邮件和垃圾邮件作为训练集,通过统计词频建立词典,用于训练贝叶斯算法。这一步骤是构建垃圾邮件过滤系统的基础,需要有效地处理文本数据并建立特征词典。
- 贝叶斯垃圾邮件过滤算法:研究实现贝叶斯算法,用于判断邮件是否为垃圾邮件。此外,支持两种不同的贝叶斯算法,并提供了结合使用的选项,以提高分类准确性。
- 邮件过滤系统功能:设计并实现一套完整的邮件过滤系统,包括邮件展示、错误学习、黑白名单、屏蔽词、测试、数据统计等多个功能,以提供用户友好的界面和强大的管理功能。

图1 邮件内容过滤运行机制
3.2. 预期目标
- 产出一个完整的基于机器学习的自动垃圾邮件过滤系统,该系统具有高准确性,能够有效分类和过滤垃圾邮件,提高用户的电子邮件体验。
- 改进用户界面管理功能,使系统易于使用和配置,用户可以方便地管理邮件过滤规则和白名单/黑名单。
- 加强敏感词检测功能,提高系统对敏感内容的检测和过滤能力,以确保用户不会收到不适当的邮件。
- 实现实时垃圾邮件检测,使系统能够及时识别并处理新的垃圾邮件威胁。
算法选择:采用贝叶斯分类算法,并实现了两种贝叶斯算法的组合,可以提高判断的准确性。贝叶斯算法在文本分类任务上效果较好。
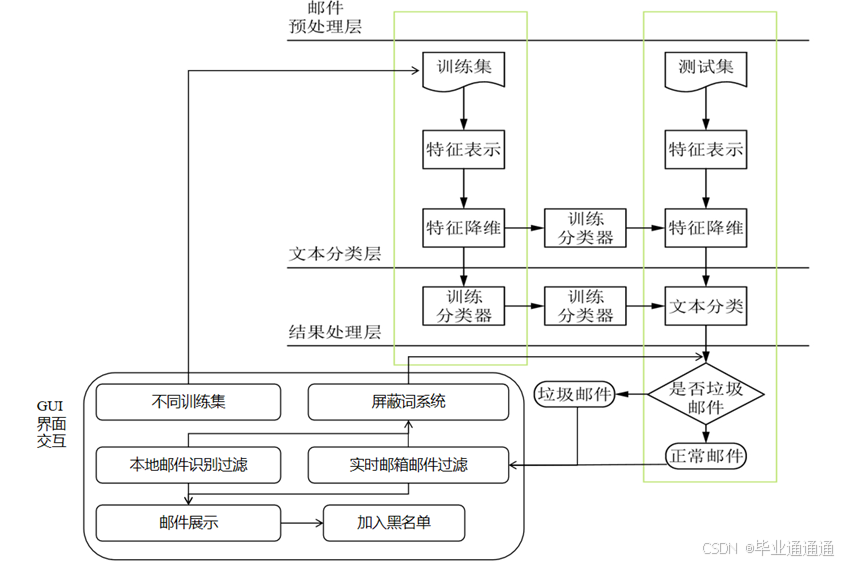
图2 技术路线图
文本特征工程
(1) 数据清洗:过滤邮件中的非文本内容
(2) 文本分词:切分邮件文本,提取词
(3) 特征提取:统计词频,作为邮件的特征向量
(4) 特征处理:删除停用词,词干提取等
贝叶斯分类模型
(1) 收集并标注邮件数据集,分割训练集和测试集
(2) 计算词在正常邮件和垃圾邮件中的条件概率
(3) 建立贝叶斯分类模型,计算后验概率
模型训练:使用文本邮件作为训练集,分别统计正常邮件词频和垃圾邮件词频,建立词典。然后基于词频进行贝叶斯分类。
模型评估:通过测试错误率或准确率来评估模型效果。并提供错误学习功能进一步优化。
模型应用:在图形界面上,对新邮件进行词频统计,然后将特征输入到训练好的贝叶斯模型中,输出分类结果和概率。
可视化和交互:采用tkinter构建GUI,使整个过程可视化和交互,方便用户使用。
模块化设计:不同功能分成不同模块,提高代码的复用性和维护性。
获取真实数据:调用邮件API获取真实邮件数据,提高实用性。
- 相关工作
垃圾邮件检测与过滤系统是信息安全领域的重要研究方向,吸引了众多研究者的关注。本节将介绍一些相关工作,涵盖了传统方法和基于机器学习的方法。
-
- 传统方法
- 规则过滤方法
- 传统方法
早期的垃圾邮件过滤方法主要采用规则过滤方法,即根据事先定义好的规则集来识别和过滤垃圾邮件。这些规则可以涵盖关键词、特定字符、邮件格式等多个方面。例如,规则可以包括含有明显的广告词汇、特定的URL链接、大量的拼写错误等等。当邮件满足这些规则中的某一条或多条时,就会被标记为垃圾邮件并进行过滤。
尽管规则过滤方法在早期起到了一定的作用,但是其存在一些局限性。首先,规则集需要人工设计和维护,这需要耗费大量的时间和人力成本。其次,规则过滤方法缺乏灵活性,很难应对垃圾邮件发送者不断变化的策略。随着垃圾邮件发送者采取新的欺骗手段和技巧,规则集需要不断更新和调整才能保持有效性。此外,规则过滤方法往往会产生较高的误判率,即将合法邮件误判为垃圾邮件,或者将垃圾邮件误判为合法邮件,从而影响用户的邮件收发体验。
尽管规则过滤方法存在上述问题,但在垃圾邮件检测的早期阶段,它仍然是一种常用的方法。随着技术的进步和机器学习算法的发展,后续出现了更加智能和高效的垃圾邮件检测方法,规则过滤方法在一定程度上逐渐被取代。
-
-
- 基于特征工程的方法
-
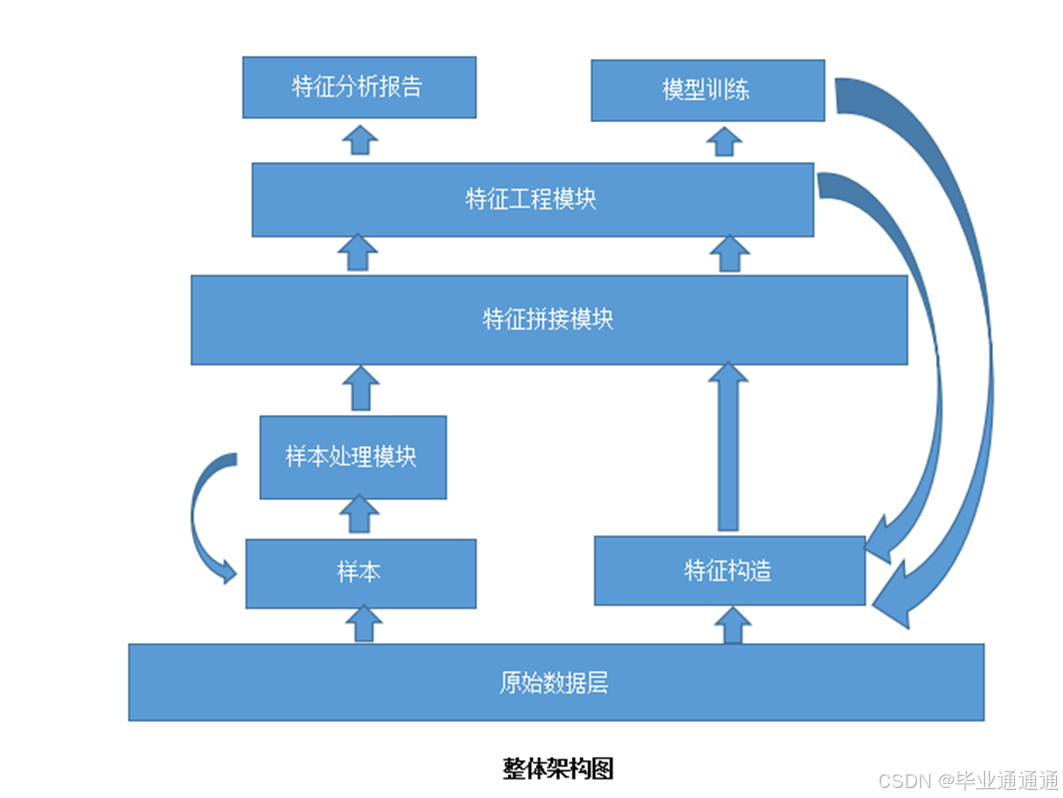
整体架构图描述了基于特征工程的垃圾邮件检测系统的整体工作流程和各个模块之间的关系。首先,原始数据层包含了待处理的邮件文本数据,包括邮件正文和邮件头部信息。在特征构造阶段,从原始数据层获取的信息经过文本预处理、特征提取和特征选择等步骤转换成可用于模型训练的特征表示。然后,特征工程模块负责对邮件文本进行特征提取和处理,将原始文本转换成特征向量表示。接着,特征拼接模块将不同特征之间的特征向量进行拼接,形成完整的特征向量表示。样本处理模块用于对数据集进行预处理和清洗,包括去除重复样本、处理缺失值、平衡正负样本比例等操作。最后,模型训练阶段利用已准备好的特征向量和处理好的样本数据训练机器学习模型。整个系统的流程清晰地展示了从原始数据到模型训练的完整过程,为垃圾邮件检测提供了可靠的基础。
-
- 基于机器学习的方法
- 朴素贝叶斯算法
- 基于机器学习的方法
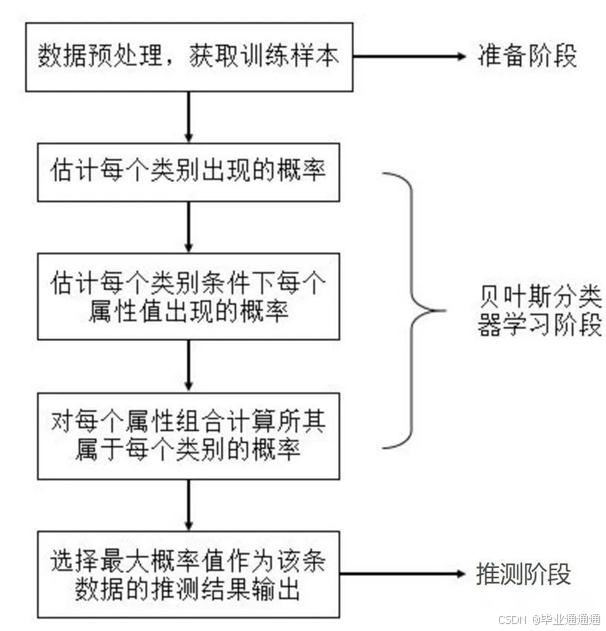
朴素贝叶斯算法是一种基于概率统计的简单而有效的分类算法,在垃圾邮件检测领域广受欢迎。该算法的核心思想是基于贝叶斯定理,假设各个特征之间相互独立,然后通过计算给定特征下每个类别的条件概率来进行分类。
在垃圾邮件检测中,朴素贝叶斯算法将邮件的特征(如词频、字符频率等)视为独立的变量,然后利用训练数据集中不同类别(垃圾邮件和非垃圾邮件)的特征分布情况,计算给定邮件特征下属于每个类别的概率。具体而言,对于新的未知邮件,朴素贝叶斯算法会根据其特征向量计算出属于每个类别的概率,然后将其分类为具有最高概率的类别。
朴素贝叶斯算法具有计算简单、速度快、易于实现等优点,特别适用于处理高维度特征的情况,因此在垃圾邮件检测等文本分类任务中被广泛应用。然而,朴素贝叶斯算法假设特征之间相互独立,在某些实际情况下可能不太符合实际情况,导致分类结果出现偏差。因此,在实际应用中,需要根据具体情况综合考虑算法的优缺点,选择合适的分类方法。
-
-
- 支持向量机(SVM)
-
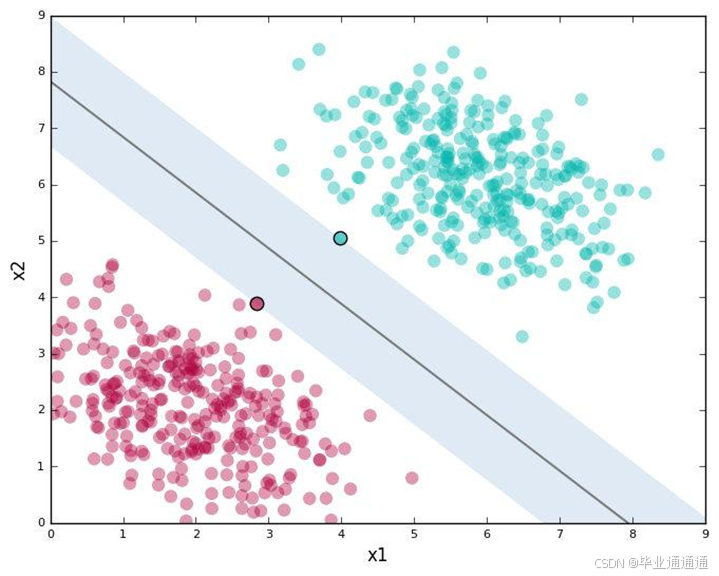
支持向量机(SVM)是一种强大的二分类模型,在垃圾邮件检测等领域展现了良好的分类性能。其核心思想是找到一个最优的超平面,使得不同类别的样本在特征空间中的间隔最大化。这个超平面被称为决策边界,能够有效地将不同类别的样本分开。
SVM在垃圾邮件检测中的应用表现出了一些优势。首先,SVM能够处理高维特征空间下的分类问题,因此适用于文本分类等需要处理大量特征的任务。其次,SVM的间隔最大化原则使其在处理样本数据较少、且数据分布复杂的情况下表现出了较好的泛化能力。此外,SVM还可以通过核函数将非线性问题映射到高维空间中进行处理,进一步提高了分类的准确性。
然而,SVM也存在一些挑战和限制。首先,SVM的训练时间复杂度较高,在处理大规模数据集时可能会面临较长的训练时间。其次,SVM对参数的选择和调整比较敏感,需要通过交叉验证等方法来确定最优参数设置。此外,SVM在处理大规模高维度数据时,可能会面临内存消耗和计算资源限制的问题。
综上所述,支持向量机在垃圾邮件检测等领域展现了良好的分类性能,尤其适用于处理高维特征空间下的分类问题。然而,在实际应用中需要综合考虑其优缺点,并根据具体情况选择合适的分类方法。
-
-
- 深度学习方法
-
近年来,深度学习方法在垃圾邮件检测领域取得了显著进展,其中卷积神经网络(CNN)和循环神经网络(RNN)等模型发挥了重要作用。这些深度学习模型能够更好地捕捉文本的语义信息,从而提高了垃圾邮件检测的准确性和鲁棒性。
卷积神经网络(CNN)通过卷积层和池化层来提取文本中的局部特征,并利用多层网络结构学习更高级别的语义表示。这种结构能够有效地捕捉文本中的空间局部信息,从而在垃圾邮件检测中取得了良好的效果。
循环神经网络(RNN)能够捕捉文本中的时间序列信息,从而更好地理解文本的语义结构。RNN通过循环结构将前一时刻的信息传递到下一时刻,从而实现对文本序列的建模。这种模型在处理长文本或者具有复杂语义结构的文本时表现出了优势,因此在垃圾邮件检测中也得到了广泛应用。
除了CNN和RNN,还有许多其他深度学习模型被应用于垃圾邮件检测中,如长短期记忆网络(LSTM)、门控循环单元(GRU)等。这些模型在不同方面具有特点,能够根据不同的数据特点和任务需求进行选择和调整。
总的来说,深度学习方法在垃圾邮件检测领域展现了巨大的潜力,通过利用大量的数据和强大的计算能力,这些模型能够更好地理解文本的语义信息,提高了垃圾邮件检测的效果。然而,深度学习方法也需要大量的数据和计算资源,同时对模型的调优和参数设置要求较高,因此在实际应用中需要进行充分的实验和调整。
检测系统实现的界面设计和流程主要集中在提供一个用户友好的界面,通过这个界面,用户可以轻松地进行邮件过滤相关的操作。下面是具体的设计方案:
界面设计
标题:“欢迎使用邮件过滤系统”位于主界面的顶部中央位置。这个标题使用黑体字体,字号设定为25,以突出显示系统的主要功能和目的。
训练集训练按钮:在界面中上方设置一个按钮,标签为“选择训练集进行训练!”。点击此按钮后,会弹出一个新的界面或对话框,让用户可以选择不同级别的训练集进行模型训练。这一步骤对于提高垃圾邮件过滤的准确性至关重要。
屏蔽词系统按钮:“屏蔽词系统!”按钮位于训练集训练按钮的下方。点击此按钮后,用户进入屏蔽词设置界面,在这里可以添加或移除特定的屏蔽词,以优化邮件过滤效果。
邮件号输入:界面下方提供一个文本输入框,用户可以在此输入待测试的邮件编号。这允许用户针对特定邮件进行垃圾邮件检测。
开始判断按钮:“开始判断”按钮位于邮件号输入框旁边。用户输入邮件号后,点击此按钮系统将根据提供的邮件号进行垃圾邮件的自动判断。
判断邮箱中的邮件按钮:“判断邮箱中的邮件”按钮设置在界面底部。点击此按钮后,系统将自动对邮箱中的所有邮件进行扫描,识别并处理垃圾邮件。
流程设计
启动系统:用户打开邮件过滤系统,首先看到的是主界面,上面有清晰的操作按钮和输入框。
训练模型:用户通过点击“选择训练集进行训练!”按钮,选择适合的训练集对过滤系统进行训练,以提高垃圾邮件识别的准确率。
设置屏蔽词:用户可以点击“屏蔽词系统!”按钮,进入屏蔽词设置界面,根据需要添加或删除特定词汇,自定义过滤规则。
输入邮件编号:用户在邮件号输入框中输入特定的邮件编号,准备对指定邮件进行垃圾邮件检测。
邮件判断:点击“开始判断”按钮后,系统根据用户输入的邮件号进行分析,判断该邮件是否为垃圾邮件,并给出相应的反馈。
全邮箱扫描:用户还可以选择点击“判断邮箱中的邮件”按钮,让系统自动扫描整个邮箱,识别并处理垃圾邮件,优化用户的邮箱使用体验。
通过这种界面和流程设计,用户可以高效、直观地使用邮件过滤系统,有效减少垃圾邮件的干扰。

输入框:顶部有一输入框,用户可以输入想要屏蔽的词汇。
加入按钮:“加入”按钮位于输入框旁边,点击后将输入的词汇加入屏蔽词列表。
内置敏感词选择:提供两个复选框,分别为“营销类词语”和“攻击类词语”,用户可以选择启用。
使用已有的敏感词表按钮:下方提供一个按钮,点击后根据复选框的选择加入预设的屏蔽词。
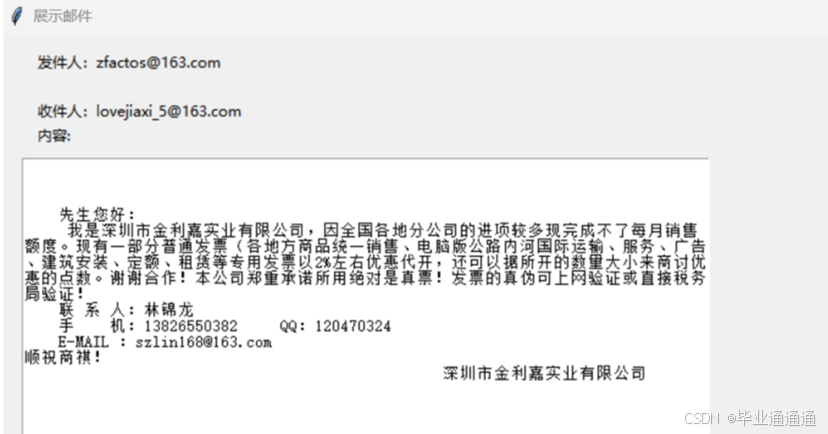
邮件信息展示:在用户选择查看邮件内容后,会弹出一个新窗口,展示邮件的发件人、收件人和邮件内容。
内容展示区域:邮件内容在一个文本框内展示,支持滚动查看。
-
- 163邮箱实时检测
实时163邮箱垃圾邮件检测流程设计旨在有效识别和过滤垃圾邮件,提高邮件处理效率,保护用户免受不必要的信息干扰。以下是一个大致的流程,包含关键步骤和技术细节:
用户认证与服务器连接:首先,使用POP3协议与163邮箱服务器建立安全连接。这需要用户的邮箱账号和密码(通常使用授权码代替密码以增强安全性)。Python的poplib库可以方便地实现这一步骤。
邮件检索与解析:连接建立后,通过发送相应的POP3命令检索邮箱中的邮件列表,选择需要检测的邮件。对选定的邮件,使用email库对邮件内容进行解码和解析,获取邮件的主题、发件人、正文等信息。
贝叶斯过滤器训练与应用:使用已经训练好的贝叶斯过滤器模型对邮件内容进行分析。贝叶斯过滤器通过学习大量的垃圾邮件和正常邮件,识别出垃圾邮件的特征。这一步骤涉及到词频统计、特征提取和概率计算等技术。
垃圾邮件判断与处理:根据贝叶斯过滤器的分析结果,判断邮件是否为垃圾邮件。对于判定为垃圾的邮件,可以选择标记、移动到垃圾邮件文件夹或直接删除,根据用户的偏好设置。
163邮箱实时检测结果如下:
操作反馈:在用户选择将发件人加入黑名单或白名单后,系统会弹出提示框,确认操作并展示当前的黑/白名单列表。
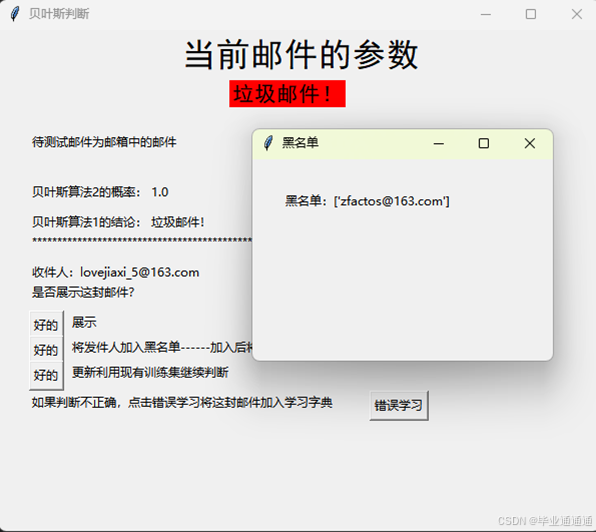
在设计一个邮件过滤系统时,错误学习和准确率更新是两个关键的功能,它们帮助系统不断自我优化,以更准确地识别垃圾邮件。以下是4.7错误学习与准确率更新流程的具体描述:
错误学习按钮
界面布局:在邮件判断界面,提供一个明显的“错误学习”按钮。这个按钮允许用户对系统的判断结果进行反馈。如果系统将一封正常邮件误判为垃圾邮件,或者未能识别出一封垃圾邮件,用户可以通过点击这个按钮来告诉系统其判断是错误的。
操作流程:
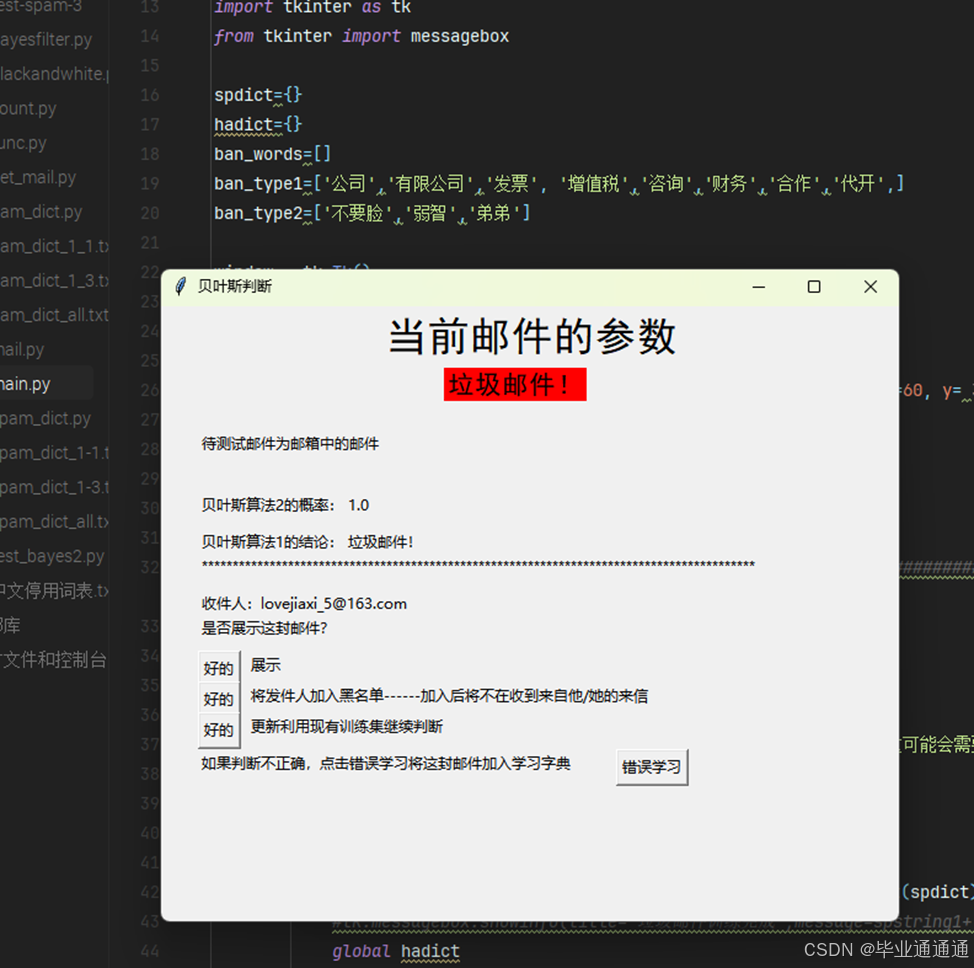
用户在邮件判断界面,对一封邮件的分类结果有异议时,点击“错误学习”按钮。
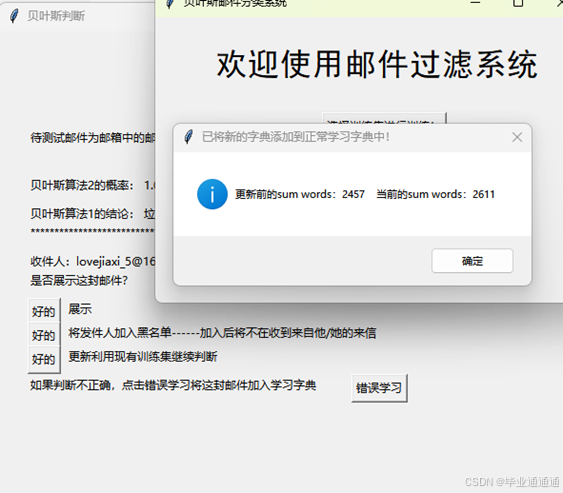
弹出确认对话框,让用户确认是否将该邮件加入对应的学习集(垃圾邮件学习集或正常邮件学习集)。
用户确认后,系统将该邮件的特征加入到相应的学习集中,并重新训练过滤模型。
系统弹出提示框,告知用户学习完成,并提示当前的黑/白名单列表更新。
准确率显示与更新
准确率显示:在主界面的显眼位置显示当前训练集下的准确率。这个准确率可以是通过最近一次训练或测试得到的,它给用户一个直观的感受,了解系统过滤垃圾邮件的效能。
更新按钮:
在准确率显示旁边提供一个“更新”按钮。用户在进行了错误学习或者更换了训练集后,可能需要刷新这个准确率显示。
用户点击“更新”按钮后,系统重新计算准确率,这可能涉及到对一定量的测试邮件集进行再次检测。
准确率数据更新后,系统在主界面上更新显示的准确率数值。
系统交互体验
整个系统通过简洁直观的图形界面,为用户提供了包括邮件过滤、训练集管理、屏蔽词设置等功能。错误学习与准确率更新功能的设计,实现了与用户的交互,使系统能够根据用户的反馈进行自我优化,从而提供更加个性化和准确的邮件过滤服务。通过不断的学习和调整,系统的过滤效果将随时间改进,减少误判,提高用户的邮箱使用体验。
更多项目:
另有10000+份项目源码,项目有java(包含springboot,ssm,jsp等),小程序,python,php,net等语言项目。项目均包含完整前后端源码,可正常运行!
!!! 有需要的小伙伴可以点击下方链接咨询我哦!!!


















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











