







前言
情感分析属于自然语言处理的一部分,其任务是,给定一个文本,判断这个文本所表达的情感是正面的,中立的,还是负面的。这被广泛用于:
1. 商品好评度自动检测。
2. 微博推特等平台用户发言是开心赞美还是批评抱怨。
本次带领大家使用机器学习的方法对情感分析做一次实战。
注意:此次侧重于机器学习实战的一个流程,而不会详细讲具体的机器学习算法。对于想要体验一把的新手会比较友好。另外,对于新手,我要提醒的是,体验一个完整的流程并弄明白,耗时很久是很正常的事,切勿急躁哦。
相关数据
我们的数据是推特上用户发的推特,我们的任务是训练得到一个模型,给定一个没有见过的推特发言时,判断其是开心赞美(positive)还是批评抱怨(negative)还是中立(neutral)。比如给定“bullying me”(欺负我),模型需要能够输出“negative”。
本次数据已经上传至github。我们本次实战只用其中的train.csv文件。
实战
1. 导入相关包和模型。
import pandas as pd
import numpy as np
#将train.csv划分训练集和测试集
from sklearn.model_selection import train_test_split
#将文本变成向量,这是自然语言处理的常用技术
from sklearn.feature_extraction.text import TfidfVectorizer
#逻辑回归模型
from sklearn.linear_model import LogisticRegression
#支持向量机
from sklearn.svm import LinearSVC
#朴素贝叶斯
from sklearn.naive_bayes import MultinomialNB
#训练完成后,对模型的评价
from sklearn.metrics import accuracy_score,classification_report
#对于上面的包,你只需要会pandas和numpy两个包,其他不会不要紧,如果连pandas和numpy都不会,要么先去学(比较建议),要么看下去不懂再查。
2. 读取数据。此处路径需要改成自己数据所在路径。
data=pd.read_csv("data/tweet-sentiment-extraction/train.csv")
data.head(5)
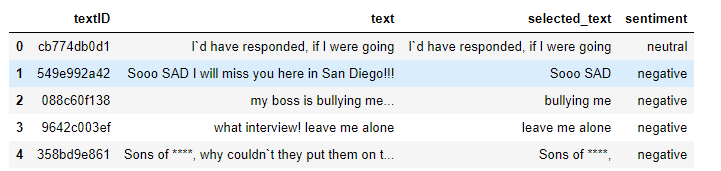
3. 构造模型的输入和输出,为了简便,输入我们选择selected_text,输出的标签是sentiment。其他两列不要了。
datax=data["selected_text"]
datay=data["sentiment"]
print(datax.shape)
print(datay.shape)

4. #划分训练集和测试集。其中测试集用来选择模型或者超参数。可以参考训练数据集如何划分验证测试集?
trainx,testx,trainy,testy=train_test_split(datax,datay,test_size=0.3,random_state=42)
print(trainx.shape)
print(testx.shape)
其中的random_state有什么用?可以参考sklearn中train_test_split函数中的random_state有什么用?
5. 处理缺失值。下面我处理的有点繁琐,如果没太明白也没关系,稍微看看大概流程,实践一遍即可。具体可以参考如何判断DataFrame中是否有缺失值None或者NaN(nan)?
#查看是否有缺失值
trainx.isnull().any()

将缺失值位置找出来,并填充一个固定字符串去(例如空格或者“#”),或者你可以直接将其删除也行。
#可以得到是否为空得true,false的同样shape的dataframe or series。
boolx=trainx.isnull()
#改成数值型,否则numpy无法处理。
boolx[boolx==True]=1
boolx

#必须要先将dataframe或者series转化成ndarray,否则argwhere会报错。
boolxn=np.array(boolx)
np.argwhere(boolxn==1)
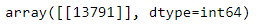
#由于随机状态固定了,所以分配的训练集和测试集每次都是那样的,即每一次索引都是13791。但是这个是顺序的那个索引,我们应该得到真正的index.
sindex=trainx.index
sindex[13791]

#为了追究data中到底是什么,我们得到了其索引是314,由于这个是从0开始的,所以索引和iloc都是一样的。
data.iloc[314,:]
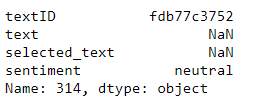
我们发现,有一条训练数据什么话也没说NaN,情感分析标记成了中立的。
#这里我需要给一个暗号,为了便于处理,将空值一律替换成空格或者#都可以。
trainx.iloc[13791]="#"
trainx.iloc[13791]
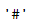
6. 将文本trainx给向量化。可以参考一个例子来使用sklearn中的TfidfVectorizer。
#下面将文本trainx给向量化。
tv=TfidfVectorizer(stop_words="english",ngram_range=(1,1),max_df=0.8,min_df=2)
tv_fit=tv.fit_transform(trainx)
#从此,trainx变成了tv_fit的toarray,也就是说已经变成了向量。
trainxv=tv_fit.toarray()
trainxv

trainxv.shape
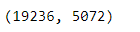
同理,对于testx也要转成向量。注意是用上面已经弄好的tv转成,而不是重新弄一个tv,否则testxv中记录的维度可能和trainxv不一样,可能不是5072,那么基于trainxv训练的模型(只接受5072维度),使用testxv去验证测试的时候,肯定是输入不进去的。
testxv=tv.transform(testx)
testxv
#下面显示是稀疏矩阵,压缩存储了,我真是笑了,我觉得这个说明了一个问题,这个testx里面有很多生词,这样不太好啊,因为感觉预测效果将不会太好。

7. 训练模型。
#由于我们要用很多个机器学习模型来分类,而且都有一个共同点,都是fit,predict,所以干脆写成一个函数。
def train_model(model_name,model,trainx,trainy,testx,testy):
print("this is the model of",model_name)
model.fit(trainx,trainy)
trainy_pred=model.predict(trainx)
testy_pred=model.predict(testx)
print("accuracy on training data:",accuracy_score(trainy,trainy_pred))
print("accuracy on testing data:",accuracy_score(testy,testy_pred))
print("classification report on testing data:")
print(classification_report(testy,testy_pred))
#使用逻辑回归模型,
import warnings
warnings.filterwarnings("ignore")
model_lr=LogisticRegression()
train_model("logistic regression",model_lr,trainxv,trainy,testxv,testy)
#使用支持向量机模型来进行分类。
model_svm=LinearSVC()
train_model("support vector machine",model_svm,trainxv,trainy,testxv,testy)
#使用朴素贝叶斯模型来分类。
model_nb=MultinomialNB()
train_model("naive bayes",model_nb,trainxv,trainy,testxv,testy)
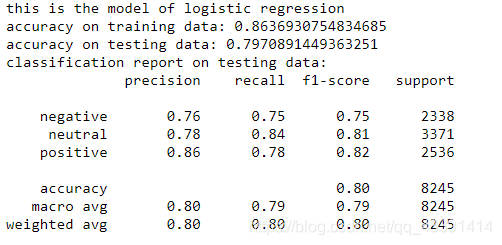
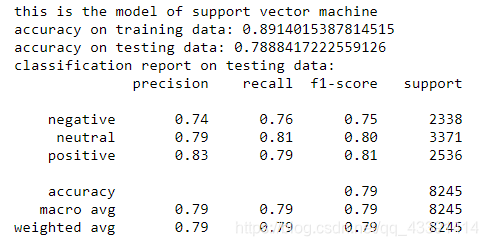
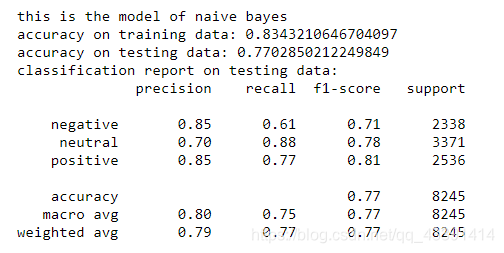
我们上面使用了3个模型来训练,至于最后挑哪个,你可以看测试集上的正确率,或者看测试集和训练集的加权(比如相加除以2)正确率来选择你最终的模型。
结束
个人建议把这篇好好弄明白,不算很长,也不涉及什么太难的,一点一点积累。我没有写明白的地方,尽管提问。


















 7614
7614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











