







前言
论文原文:Reasoning With Neural Tensor Networks
for Knowledge Base Completion。
作者比较有名,有吴恩达。
这个神经网络是2013年提出来的,所以非常简单,你现在看他就跟玩一样,尤其是你如果训练过词向量(2013年mikolov那篇)的话,这篇的讲解你会跟喝水一样简单。
思想
为什么说简单?因为2013年的时候NLP流行做嵌入,这里也不例外,所以是无监督模型。
这篇论文的目的就是说:我们要设计一个网络,给定一个知识图谱的三元组(e1,r,e2),判断这个三元组合不合法,合法你就输出高一点的值,不合法就输出低一点的值。
比如对于输入的三元组(孟加拉虎,有,尾巴),你的神经网络需要输出高一点的值。
有人会问,我们直接把上面那个三元组在知识图谱里面查询不就完事了嘛?查到了就是合法,查不到就是不合法。
现在的问题在于,知识图谱是不完整的,比如知识图谱里面只有这样的信息:孟加拉虎属于老虎,老虎有尾巴。如果是用逻辑的方法是可以推出来(孟加拉虎,有,尾巴),但是,现在我们不想用逻辑的方法,因为逻辑需要事先制定好规则,耗费人力,我们要用神经网络的方法。
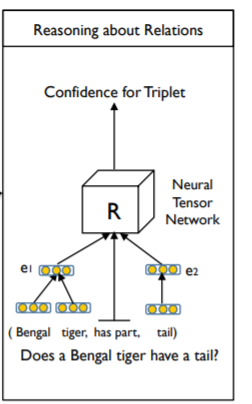
NTN
你要是学过开头说的那个词向量,就会这么做:把知识图谱已有的三元组当作正样本,然后替换已有的三元组,比如把(老虎,有,腿)替换成(苹果,有,腿)等等。这样,我们就有了很多很多的正样本和负样本。然后扔到神经网络中,希望正样本输出大值,负样本输出小值。解决!
那么现在很简单了,我们只需要设计好这个网络,其接受一个三元组作为输入,输出一个值。
Neural Tensor Network:为什么叫做tensor,有人懵逼,甚至有人不知道为什么Pytorch里面也叫tensor,这是因为,通常matrix矩阵特指二维,高维的都叫张量,即tensor,numpy中叫做ndarray,即n dimensional array,n维数组,也行吧。
既然NTN以tensor命名,说明其里面有高维数组,即如下的
W
R
W_{R}
WR
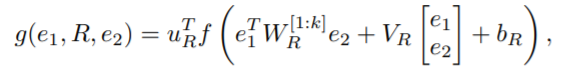

上面这个公式,配合下面食用。
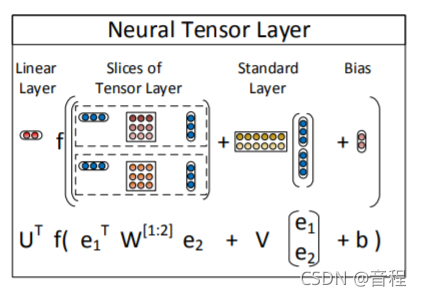
点评:所以,如果你学过多头注意力机制,其实那个tensor你可以认为其实就是k个头,分别变换k次,然后把结果拼在一起。
最后,我们神经网络定义好了,就希望正样本输出越大越好,负样本输出越小越好,也就是说正样本的输出-负样本的输出越大越好(最大化边际margin),从而有如下损失函数
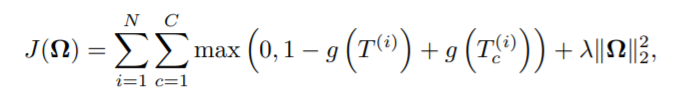
那个c就是负样本,最后面那个是一个正则项。
上面这个函数已经见多不怪了,你在知识图谱的嵌入学习里面会见到好多这个。
原论文解读,你还可以参看这位兄弟的:https://blog.csdn.net/yexiaohhjk/article/details/86374735,我只是负责介绍网络。不过,话说回来,这篇论文挺好懂得,我跟你说了思想后,你可以直接看原文了。


















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











