







 这篇博客介绍了神经张量网络在处理知识库补全任务中的应用,主要探讨了模型结构、训练目标和损失函数。模型通过计算三元组(e1,R,e2)的置信度来判断实体间的关系。使用tanh激活函数和张量运算增强模型的表达能力。训练目标确保正样本得分高于负样本,并引入L2正则化。作者个人认为,这种网络利用了输入的二次信息,提升了分类能力。"
103577748,8609794,Power BI 动态展示多维度指标,"['数据可视化', 'Power BI 报表', '数据筛选', '商业智能']
这篇博客介绍了神经张量网络在处理知识库补全任务中的应用,主要探讨了模型结构、训练目标和损失函数。模型通过计算三元组(e1,R,e2)的置信度来判断实体间的关系。使用tanh激活函数和张量运算增强模型的表达能力。训练目标确保正样本得分高于负样本,并引入L2正则化。作者个人认为,这种网络利用了输入的二次信息,提升了分类能力。"
103577748,8609794,Power BI 动态展示多维度指标,"['数据可视化', 'Power BI 报表', '数据筛选', '商业智能']
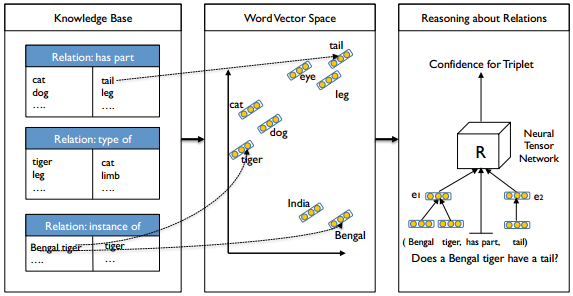
1. 问题描述
输入
一个三元组: (e1,R,e2) ,例如(Bengal tiger, has part, tail)。
输出
三元组 (e1,R,e2) 中, e1 和 e2 有关系 R 的置信度。
2. 模型
输出
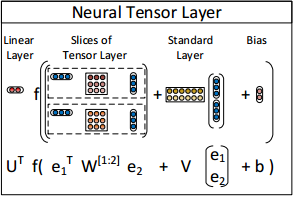
打分函数:
其中:
- uTR 是属于类别R的权值。
- f 是tanh激活函数,对输入的每个元素单独做tanh激活,即
f:Rn→Rn 。 - e1 和 e2 是输入的实体的向量表示,最初是直接赋随机值,训练时会更新。 e1∈Rd×1 文章后文中提到了两点改进:
- 不是每个输入实体对应一个向量,而是每个词语对应一个向量,实体向量由词向量求均值得到(作者提到,他们也采用了RNN进行实体向量的学习,但是由于数据中90%的实体都是由不超过两个词语构成,因而RNN并没有比简单的取平均更好)。同时在网络训练时候,也会对词向量进行更新。
- 对于词向量,采用已经训练好的词向量去作为初始化值会比随机初始化效果更好。
- W[1:k]R 为和类别 R 有关的张量,
W[1:k]R∈Rd×d×k 。 eT1W[1:k]Re2 可以看成 ⎡⎣⎢⎢eT
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1121
1121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









