







背景
一般情况下,我们有了Loss之后,
loss.backward()
就计算好了梯度,其他的根本不用管,例如标题的那两个函数。但是最近碰到一些定制化需求,上述知识已经不够,遂记录下来。
torch.autograd.grad()
torch.autograd.grad(
outputs, # 计算图的数据结果张量--它就是需要进行求导的函数
inputs, # 需要对计算图求导的张量--它是进行求导的变量
grad_outputs=None, # 如果outputs不是标量,需要使用此参数
retain_graph=None, # 保留计算图
create_graph=None, # 创建计算图
allow_unused=False#inputs如果有不相关的变量,
#即不对Outputs产生贡献的,比如你随便乱写一个inputs在那里,会报错,
#改为True就不会报错,此时对这个垃圾inputs梯度为None返回。
)
作用:计算并返回outputs对inputs的梯度。看起来平平无奇对不对,但是,计算谁对谁的梯度, 通过这个函数,你可以自由控制啦。我们看个例子:
import torch
x=torch.rand(2,2,requires_grad=True)
print(x)
y=x+2
print(y)
z=torch.sum(y)
print(z)

这个时候,如果我们要求z对x的梯度怎么办?我们当然直接
z.backward()
print(x.grad)
对不对。但是我问你,我想求z对y的梯度怎么办?你做到这一点有点麻烦对不对,此时这个函数就可以帮我们实现:
torch.autograd.grad(z,y)
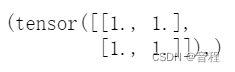
然后,我们再说一下其中的参数grad_outputs,其他的比如retain_graph我们就不说了,这个东西我早在其他文章说过,属于必修内容。
grad_outputs到底是什么呢?我们上面求了z对y的导数,如果我们想要在此基础上求解z对x的导数怎么办呢?显然不能z.backward(),因为这不是在z对y的导数的基础上,而是相当于重新求导一切了。
这个时候,我们就可以用上grad_outputs,这个东西就会充当dz/dy的作用,那么我门只需要求解dy/dx即可,然后相乘,(dz/dy)*(dy/dx)=dz/dx,就得到了我们最终想要的。
一个例子如下:
x=torch.rand(2,2,requires_grad=True)
print(x)
y=torch.pow(x,2)
print(y)
z=torch.sum(y)
print(z)
dzdy=torch.autograd.grad(z,y,retain_graph=True)[0]
dzdx=torch.autograd.grad(y,x,grad_outputs=dzdy)[0]
print(dzdx)

补充:其实这个grad_outputs有一个名字,即Jacobian vector products中的"vector "。下面看一个图(下面的l就是我们的z):
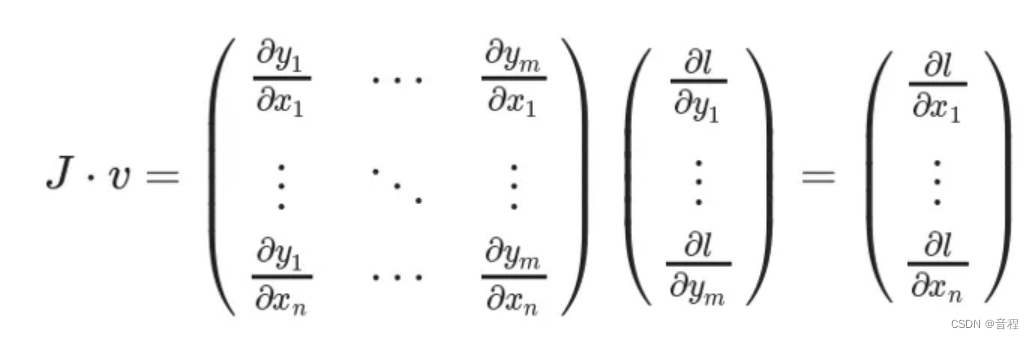
你发现了没有,上面这个图展示了链式求导法则,前面那个矩阵dy/dx我们叫做J,矩阵和向量乘积称之为product。另外,我们提供的grad_outputs就是上面那个v向量dz/dy,有人说,我上面提供的不是一个矩阵吗?

这个没事,他内部会自动view(-1)。
小提示:代码中
dzdx=torch.autograd.grad(y,x,dzdy)[0]
y和dzdy需要形状相同,这其实本来就一定要啊,对y的导数和y的数量当然是一样的。
torch.autograd.backward()
这个很简单,搞明白torch.autograd.backward(tensor)和tensor.backward()等价即可。


















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











