









 本文深入探讨了Intel Nehalem微架构的前端设计,详细介绍了取指单元(IFU)、指令队列(IQ)、指令译码器及微熔合机制。文章还讲解了循环流侦测器(LSD)的位置变动及其作用,以及分支预测处理的增强。
本文深入探讨了Intel Nehalem微架构的前端设计,详细介绍了取指单元(IFU)、指令队列(IQ)、指令译码器及微熔合机制。文章还讲解了循环流侦测器(LSD)的位置变动及其作用,以及分支预测处理的增强。
Front End Overview
下图展示了Nehalem微架构流水线前端的主要构成组件。取指单元IFU每个周期可以从一级指令缓存中读取16字节的对齐指令流,然后将其送到指令长度译码器ILD中。指令队列IQ保存有长度译码器处理过的x86指令,每个周期可以将4条指令发送给指令译码器。
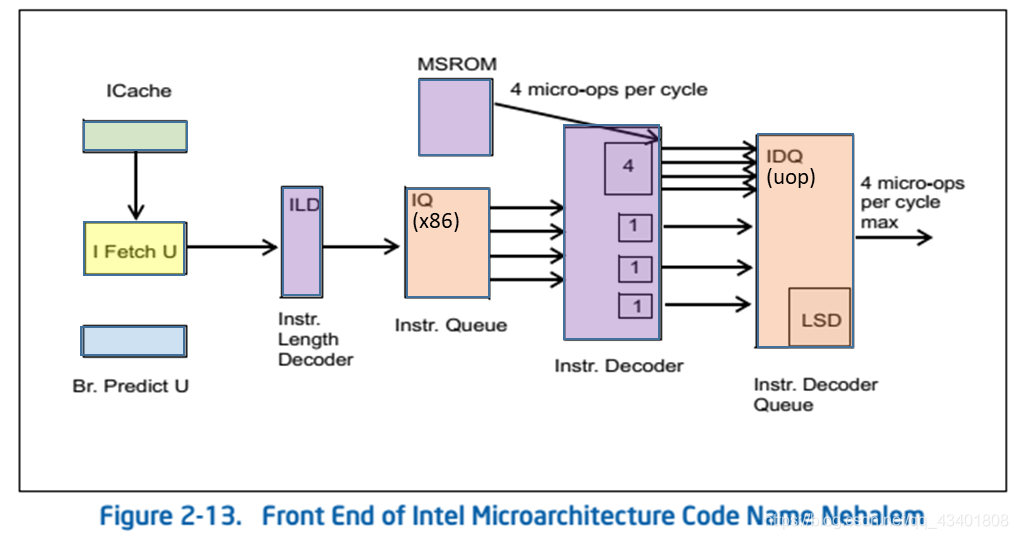
指令译码器有三个简单译码单元,每个单元每周期可以译码一条简单x86指令(即x86指令译码后只生成1条微指令)。另外有一个复杂译码器,可以每周期译码1至4微指令的x86指令(即译码后生成1条至4条微指令)。对于译码后超过4条微指令的x86指令,则必须由MSROM完成译码。无论是由指令译码器还是由MSROM译码,每个周期最多可以有4条微指令发送进入到译码后微指令队列IDQ中。
循环流侦测器(LSD)现在位于译码后微指令队列中,这样在执行短小的循环指令序列时可以节省功耗和提升前端效率。注:Intel Core微架构的LSD位于分支预测单元BPU中,处理的是x86指令;而Nehalem微架构中的LSD处理的则是微指令。当然x86的循环指令与微指令的循环指令也应该有固定对应关系。
指令译码器支持微熔合机制,可以提升前端吞吐量,增加调度器与重排序缓冲区ROB的实际容量。微熔合的规则与Intel Core微架构的规则类似。
指令队列IQ支持宏熔合机制,在可能的情况下,可以将相邻的x86指令合并在一起,生成一条微指令。在前代Intel Core微架构中,宏熔合支持的CMP/Jcc指令序列被限制为针对CF和ZF标志位的条件转移,而且64模式下不支持宏熔合机制。
Intel Nehalem微架构中,宏熔合可以支持64位模式,而且支持更多的指令序列熔合:
- CMP指令在做比较操作时,可以被熔合(与Core微架构相同)
寄存器-寄存器。例如CMP EAX, ECX; JZ label
寄存器-立即数。例如CMP EAX, 0x80; JZ label
寄存器-存储器。例如 CMP EAX, [ECX]; JZ label
存储器-寄存器。例如CMP [EAX], ECX; JZ label
- TEST指令可以与所有的条件转移指令熔合(与Core微架构相同)
- CMP可以与下列的条件转移指令熔合。这些条件转移指令检查CF和ZF标志位。可以做宏熔合的条件转移指令如下:(与Core微架构相同)
JA或JNBE(无符号大于)
JAE或JNB或JNC(无符号大于等于)
JE或JZ(等于)
JNA或JBE(无符号小于等于)
JNAE或JC或JB(无符号小于)
JNE或JNZ(不等于)
注:这条似乎与第一条有重叠?TODO。
- CMP可以与下列的条件转移指令熔合。(Nehalem微架构上的增强)
JL或JNGE(有符号小于)
JGE或JNL(有符号大于等于)
JLE或JNG(有符号小于等于)
JG或JNLE(有符号大于)
Nehalem微架构在分支预测处理上也做了多方面增强。分支预测缓冲区BTB增加了容量,提升了分支预测的准确率。寄存器重命名机制得到了返回栈缓冲区的支持,降低了代码中返回指令RET的预测错误率。而且,进一步的硬件增强提升了对分支预测错误恢复的处理能力:尽管资源已经被分配去执行错误的分支指令,但是通过快速地资源回收,前端不必一直等待译码代码架构分支中的指令(即正确的分支中最终会执行退役的指令)。相反,只要前端一开始译码架构路径上的指令,新的微指令流可以启动投入执行(参看以下英文原文)。
英文原文如下:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









