







什么是Scrapy框架?
爬虫中封装好的一个明星框架。
功能:
- 高性能的持久化存储
- 异步的数据下载
- 高性能的数据解析
- 分布式
一、为什么要使用Scrapy?
- 它更容易构建和大规模的抓取项目
- 它内置的机制被称为选择器,用于从网站(网页)上提取数据
- 它异步处理请求,速度十分快
- 它可以使用自动调节机制自动调整爬行速度
- 确保开发人员可访问性
二、Scrapy的特点
- Scrapy是一个开源和免费使用的网络爬虫框架
- Scrapy生成格式导出如:JSON,CSV和XML
- Scrapy内置支持从源代码,使用XPath或CSS表达式的选择器来提取数据
- Scrapy基于爬虫,允许以自动方式从网页中提取数据
三、Scrapy的优点
- Scrapy很容易扩展,快速和功能强大;
- 这是一个跨平台应用程序框架(在Windows,Linux,Mac OS和BSD)。
- Scrapy请求调度和异步处理;
- Scrapy附带了一个名为Scrapyd的内置服务,它允许使用JSON Web服务上传项目和控制蜘蛛。
- 也能够刮削任何网站,即使该网站不具有原始数据访问API;
四、Scrapy整体架构是什么样?
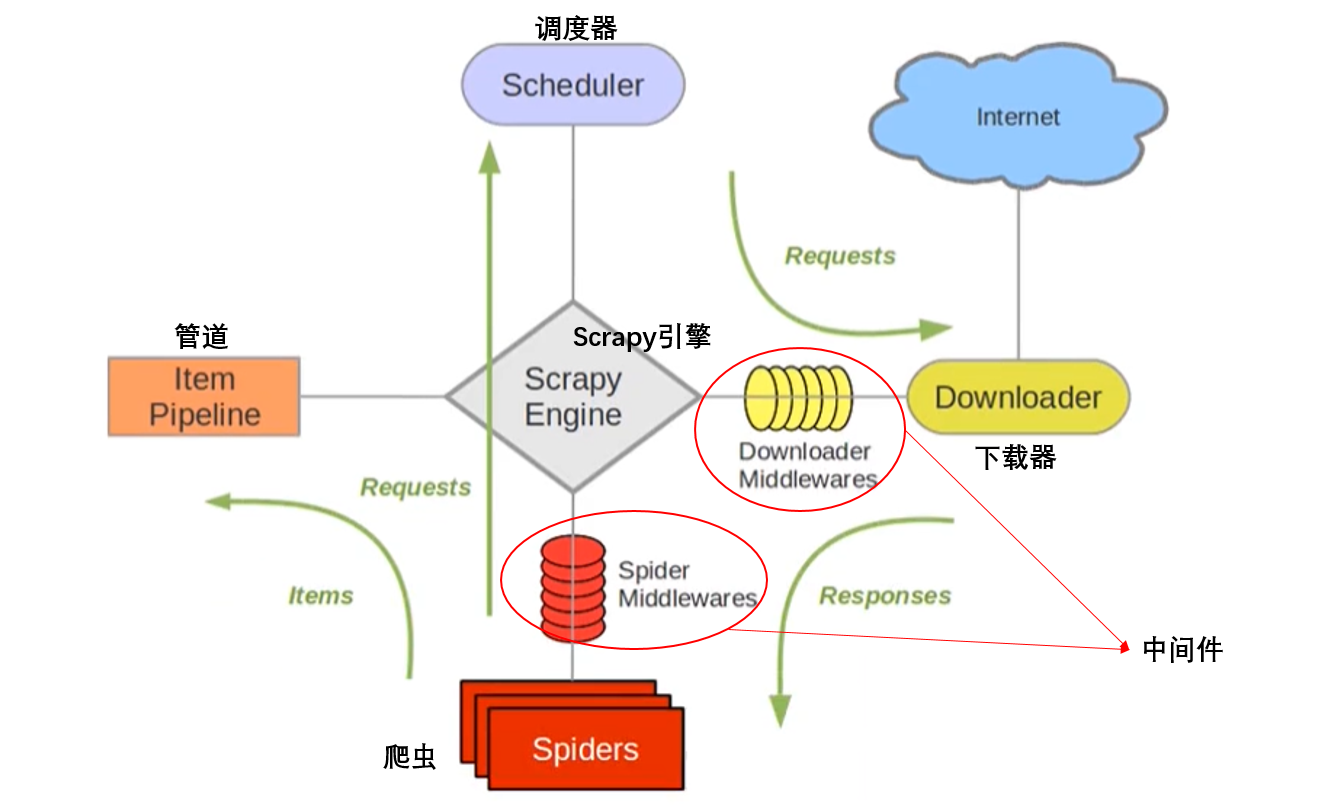
最简单的单个网页爬取流程是spiders > scheduler > downloader > spiders > item pipeline
五、组件介绍
- ScrapyEngine (引擎) 负责 Scheduler、Downloader、Spiders、Item Pipeline中间的通讯信号和数据的传递,相当于一个交通站。用来处理整个系统的数据流处理,触发事务(框架核心)。
- Scheduler(调度器) 简单地说就是一个队列,负责接收引擎发送过来的 request请求,然后将请求排队,当引擎需要请求数据的时候,就将请求队列中的数据交给引擎。
- **Downloader(下载器)**负责发送请求并下载数据,负责下载引擎发送过来的所有 request请求,并将获得的 response交还给引擎,再由引擎将 response交管给 Spiders来进行解析。
- Spiders(爬虫) 就是我们平时写 xpath、正则表达式的组件,我们会在Spider中写很多的解析策略,用于分析和提取数据。Spiders负责处理所有的 response,当然,如果 response中包含有其它的请求,比如说下一页等等,那么这个时候 Spiders会让 url提交给引擎,再由引擎再次扔到 Scheduler调度器里面。
- Item Pipeline(项目管道) 就是我们封装去重类、存储类的地方,负责处理 Spiders中获取到的数据并且进行后期的处理,过滤或者存储等等。
- Downloader Middlewares(下载中间件) 是一个自定义扩展组件,就是我们封装代理或者Http头用于隐藏我们的地方。
- Spider Middlewares(爬虫中间件) 也就是自定义扩展、引擎和Spider之间通信功能的组件,比如说进入Spider的 response和从 Spider出去的 request,它可以在中间做一些修改。
六、整个 Scrapy组件里面是如何进行流动的呢?
首先我们会在Spider里面写一个入口url,然后引擎会根据我们需要处理网站的url。
引擎会向调度器打招呼,
ScrapyEngine[引擎] 说:我这有个 request请求,你帮我 排序入队一下。
Scheduler[调度器] 说:好,我现在就给你排队。
ScrapyEngine 问 Scheduler :你排好了没有,你排好呢就把 request请求给我。
Scheduler[调度器] 说:好,给你,拿去下载吧,我已经排好队了。
调度器把队列里面的请求给引擎 [引擎这么高大上的组件能干这种活吗],然后引擎会把下载的活扔给下载器,不一会呢,下载器就下载好了。当然了,下载器也不是说总能把事办好,然后会把反馈交还给引擎,接着引擎会将没下载好的请求再扔给调度器,再次进行排队调度。
如果说下载好了,这时会将 response交给 Spider组件,Spider会进行数据的解剖,看看里面都有什么数据,有没有什么新的请求链接,然后Spider一顿操作猛如虎,拿出两部分数据,一部分数据就是我们要的数据,它呢会扔给管道进行数据存储或者清洗,另一部分是一些新的请求,将新的请求扔给引擎,然后再到调度器进行排队,再从排队调度到Spider解析进行循环,直到获取到全部的信息。
那么Scrapy各个组件之间相互协作,不同的组件完成不同的工作。由于 Scrapy是基于异步进行开发的,因此会很大限度的使用网络带宽,大大提高了抓取的效率。
七、Scrapy项目实战
抓取豆瓣电影top250数据,并将数据保存为 csv 和 json 存储到 mongo数据库中
目标站点:https://movie.douban.com/top250
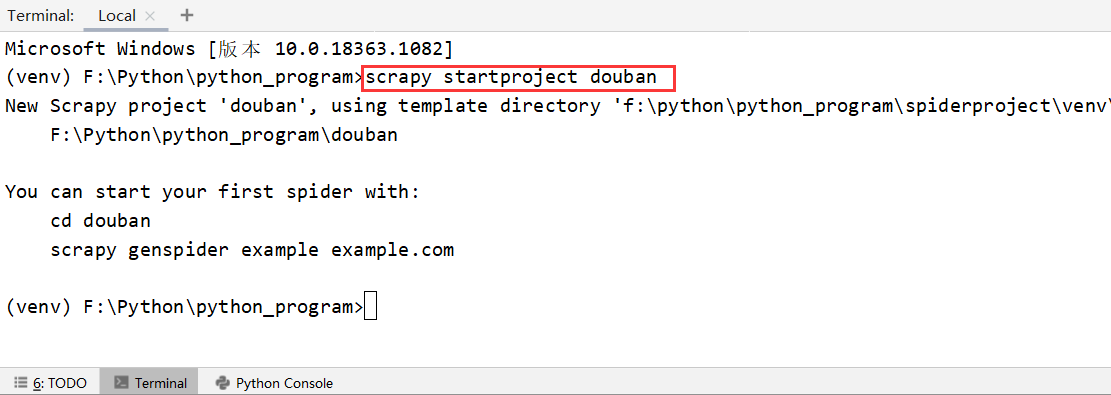
1、创建项目
-
1 在我们当前项目下Terminal控制台中,输入 scrapy startproject douban 即可创建 scrapy项目
-
2 然后open打开刚刚创建的 scrapy项目
2、文件介绍
-
scrapy.cfg 是项目的配置文件,定义了项目配置文件路径、部署信息等内容。
-
items.py 是定义item数据结构的地方,所有的item数据定义都可以在这里面进行编写。
-
settings.py 是项目的设置文件,可以定义项目的全局设置
-
比如说http的user-agent:在17行进行设置,例如谷歌浏览器的 (Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4238.2 Safari/537.36);
-
还有ROBOTSTXT_OBEY协议:在20行,也可以进行更改,一般为False;
-
下载延迟:下载延迟,改为0.5秒等等。
-
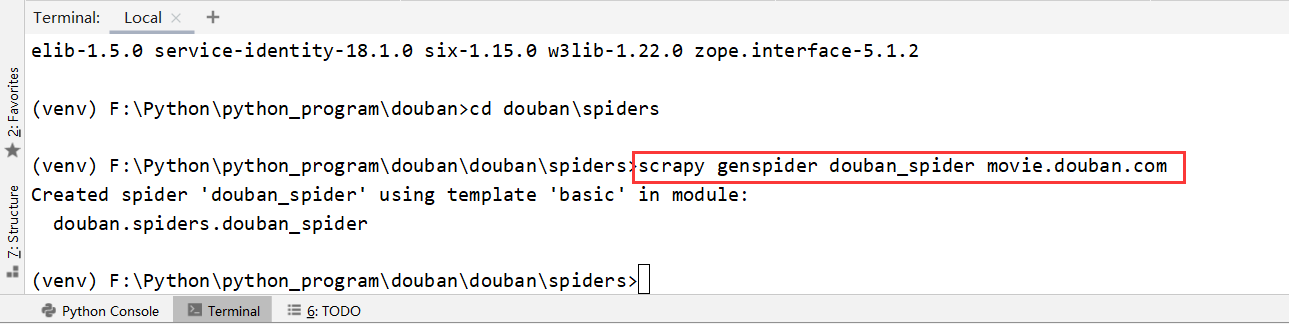
还有一个更重要的文件,spiders文件,这是我们编写xpath和正则表达式的地方,但是这个文件需要我们自己生成。
进入到douban项目里的spiders文件目录下,输入scrapy genspider douban_spider movie.douban.com。在输入创建spider文件命令之前,我们还需要安装 Scrapy,直接命令 pip install Scrapy进行安装
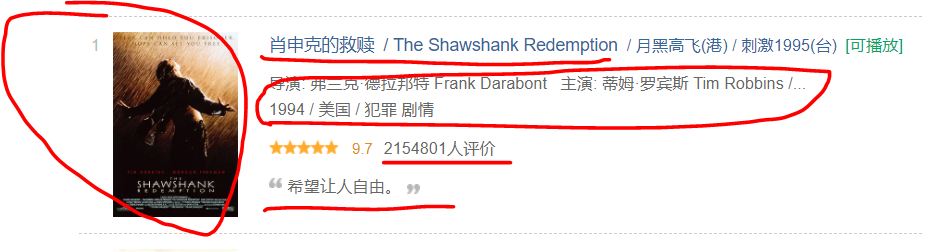
3、明确我们需要抓取的目标
打开目标地址 https://movie.douban.com/top250
-
3.1 在items.py中定义我们的数据结构
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class DoubanItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 序号 serial_number = scrapy.Field() # 电影名称 movie_name = scrapy.Field() # 电影介绍 introduce = scrapy.Field() # 电影星级 star = scrapy.Field() # 电影评论数 evaluate = scrapy.Field() # 电影描述 describe = scrapy.Field() -
3.2 spider文件的编写
import scrapy class DoubanSpiderSpider(scrapy.Spider): # 爬虫名 name = 'douban_spider' # 允许域名,如果不在这个域名里边的 url不会进行抓取 allowed_domains = ['movie.douban.com'] # 入口 url,引擎会将入口 url扔到调度器里面 start_urls = ['https://movie.douban.com/top250'] def parse(self, response): """ 在这里进行数据的解析 """ print(response.text) -
3.3 如何运行我们的 scrapy项目?
-
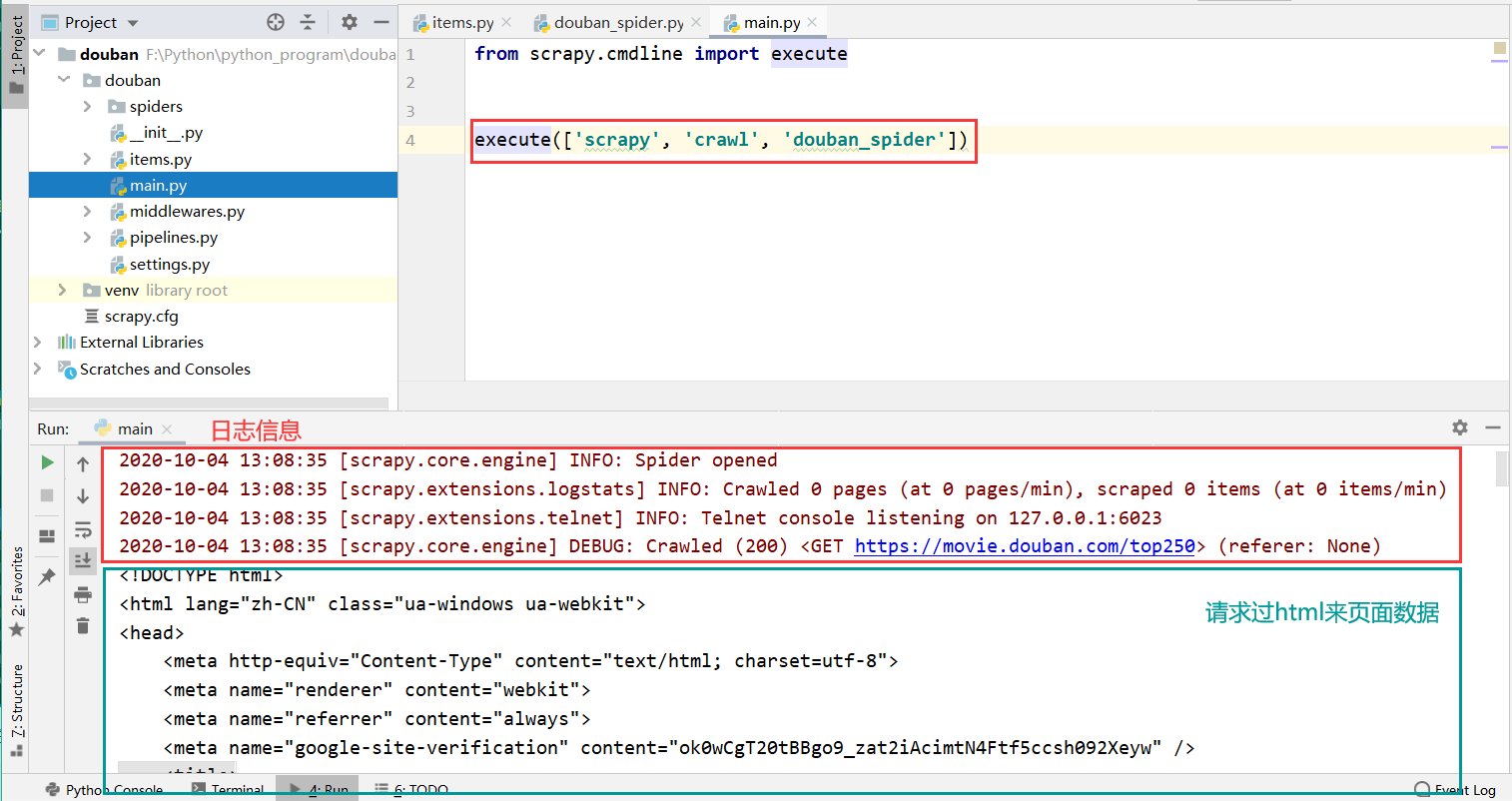
1、在终端控制台中以命令方式运行:scrapy crawl douban_spider
-
2、在douban模块下创建一个 main.py文件,并编写代码,然后右键Run ‘main’
-
4、解析我们所需要爬取的数据
-
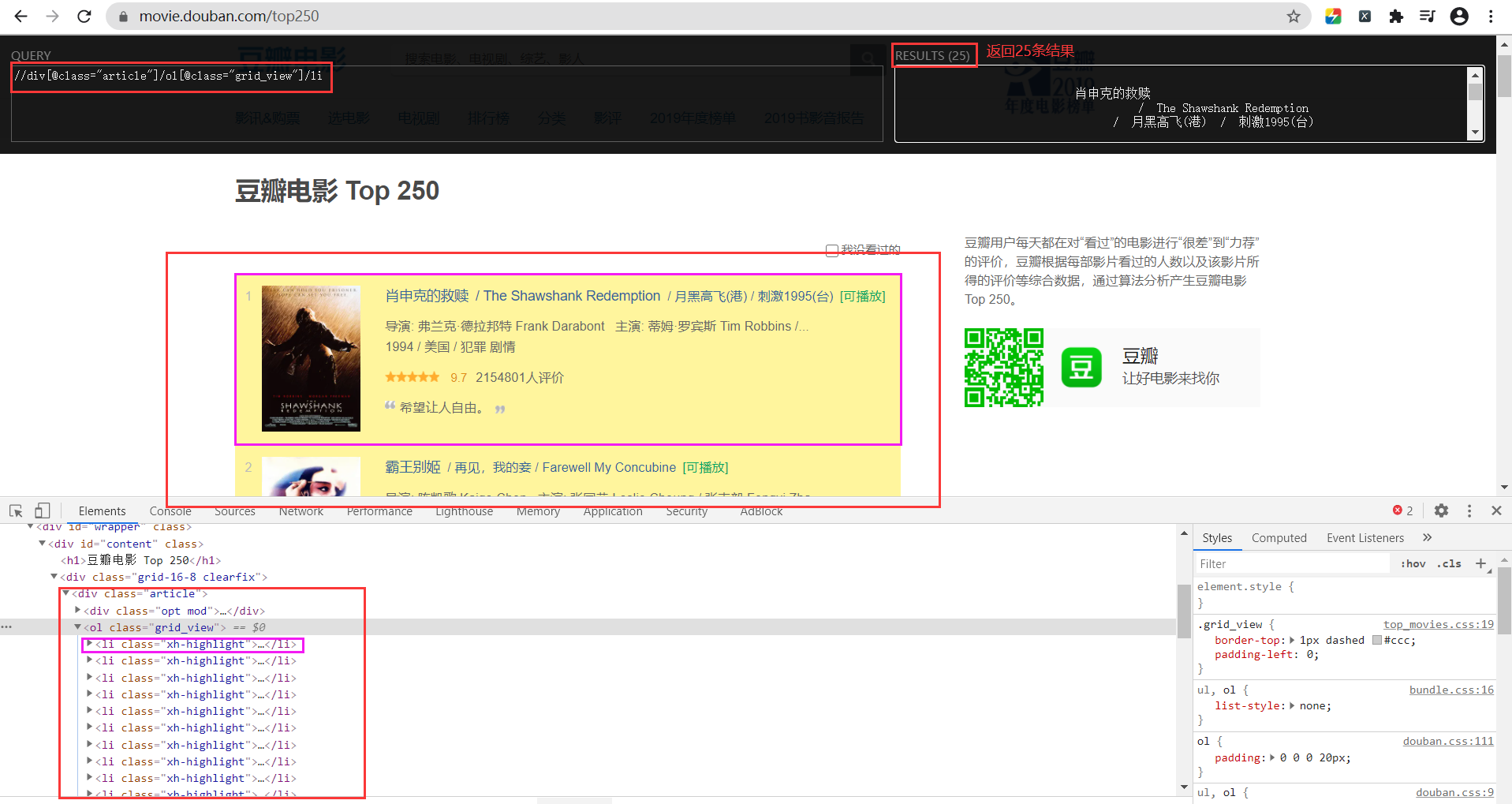
4.1 使用xpath工具定位到我们所需爬取内容的节点
-
4.2 在代码中进行数据解析
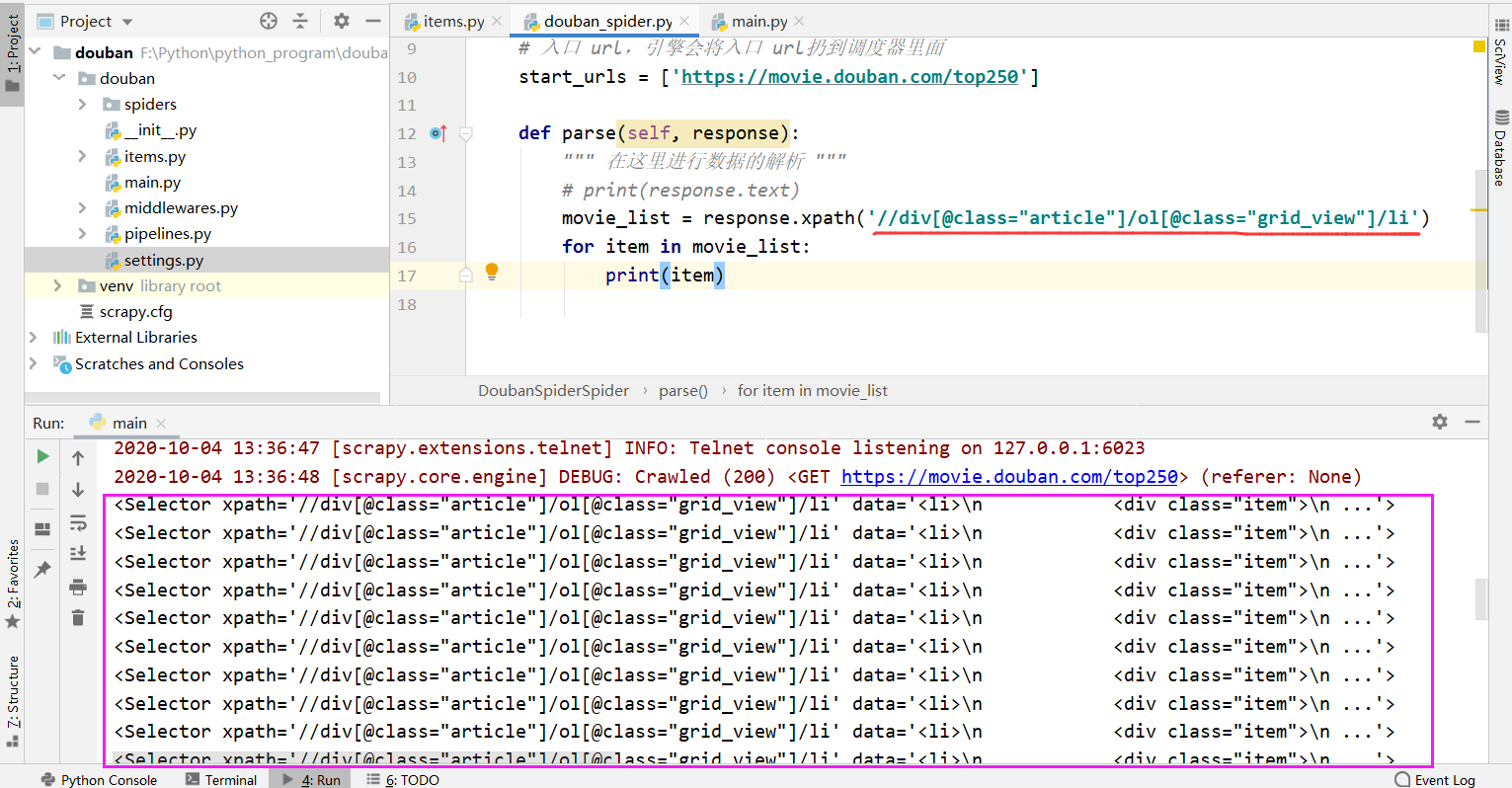
这里可以看到,我们获取出来的item对应的就是页面中每一个li标签元素,通过遍历转成 Selector对象,
然后再从每个Selector对象中解析出我们所要获取的数据。
-
4.3 导入我们之前定义好的 items模块,在 spider中解析出我们所要获取的数据
这里以 “serial_number” 为例,其它的写法也一样,注意xpath中的规则就行了:
from douban.items import DoubanItem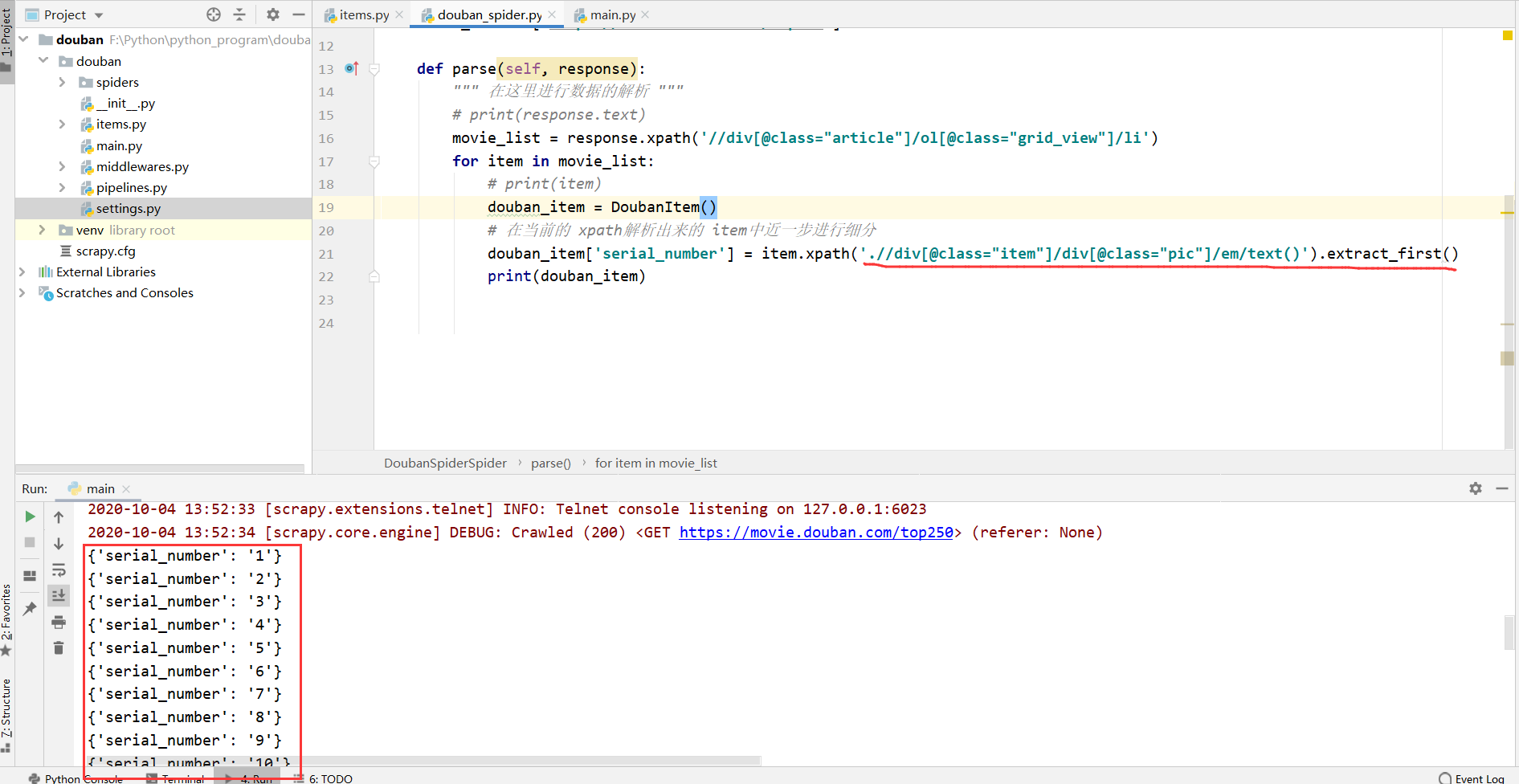
extract_first():https://blog.csdn.net/ebzxw/article/details/102163887
import scrapy
from douban.items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
# 爬虫名
name = 'douban_spider'
# 允许域名,如果不在这个域名里边的 url不会进行抓取
allowed_domains = ['movie.douban.com']
# 入口 url,引擎会将入口 url扔到调度器里面
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
""" 在这里进行数据的解析 """
# print(response.text)
movie_list = response.xpath('//div[@class="article"]/ol[@class="grid_view"]/li')
for item in movie_list:
# print(item)
douban_item = DoubanItem()
# 写详细的 xpath,进行数据的解析
douban_item['serial_number'] = item.xpath('.//div[@class="item"]/div[@class="pic"]/em/text()').extract_first()
douban_item['movie_name'] = item.xpath('.//div[@class="info"]/div[@class="hd"]/a/span[1]/text()').extract_first()
content = item.xpath('.//div[@class="info"]//div[@class="bd"]/p[1]/text()').extract()
for con in content:
# 空格字符处理
content_str = "".join(con.split())
douban_item['introduce'] = content_str
douban_item['star'] = item.xpath('.//div[@class="star"]/span[2]/text()').extract_first()
douban_item['evaluate'] = item.xpath('.//div[@class="star"]/span[4]/text()').extract_first()
douban_item['describe'] = item.xpath('.//p[@class="quote"]/span/text()').extract_first()
# 将数据 yield到 pipelines里面
yield douban_item
# 获取下一页[解析下一页],取后页的 xpath
next_link = response.xpath('//div[@class="paginator"]/span[@class="next"]/link/@href').extract_first()
# 如果有下一页就进行提取
if next_link:
# 将新的 url提交到调度器,通过 callback回调函数再进行数据的解析
yield scrapy.Request('https://movie.douban.com/top250?' + next_link, callback=self.parse)
5、保存数据
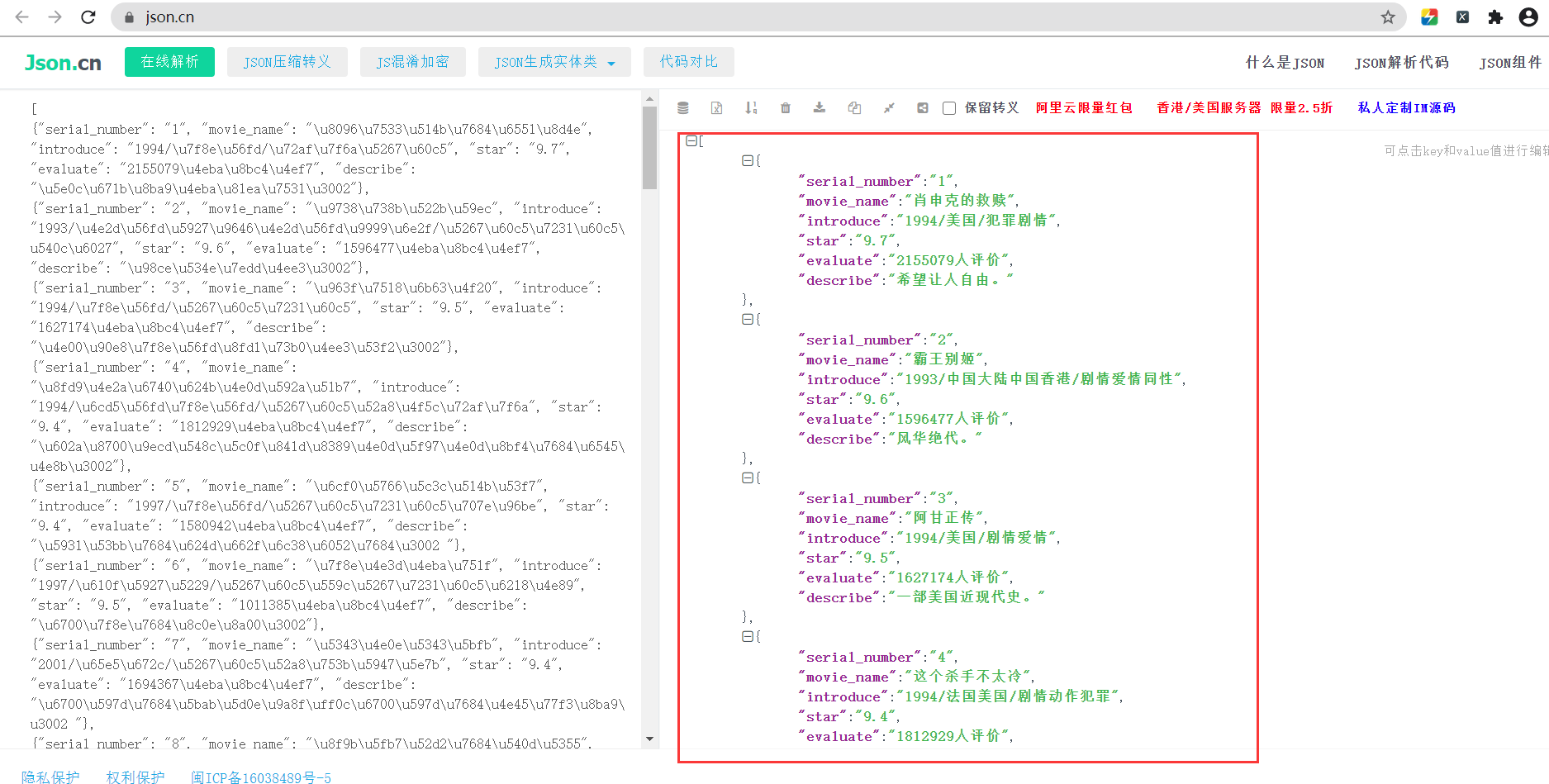
1)保存在文件中
在终端控制台中输入:scrapy crawl douban_spider -o douban.json
如果要保存为 csv文件:scrapy crawl douban_spider -o douban.csv
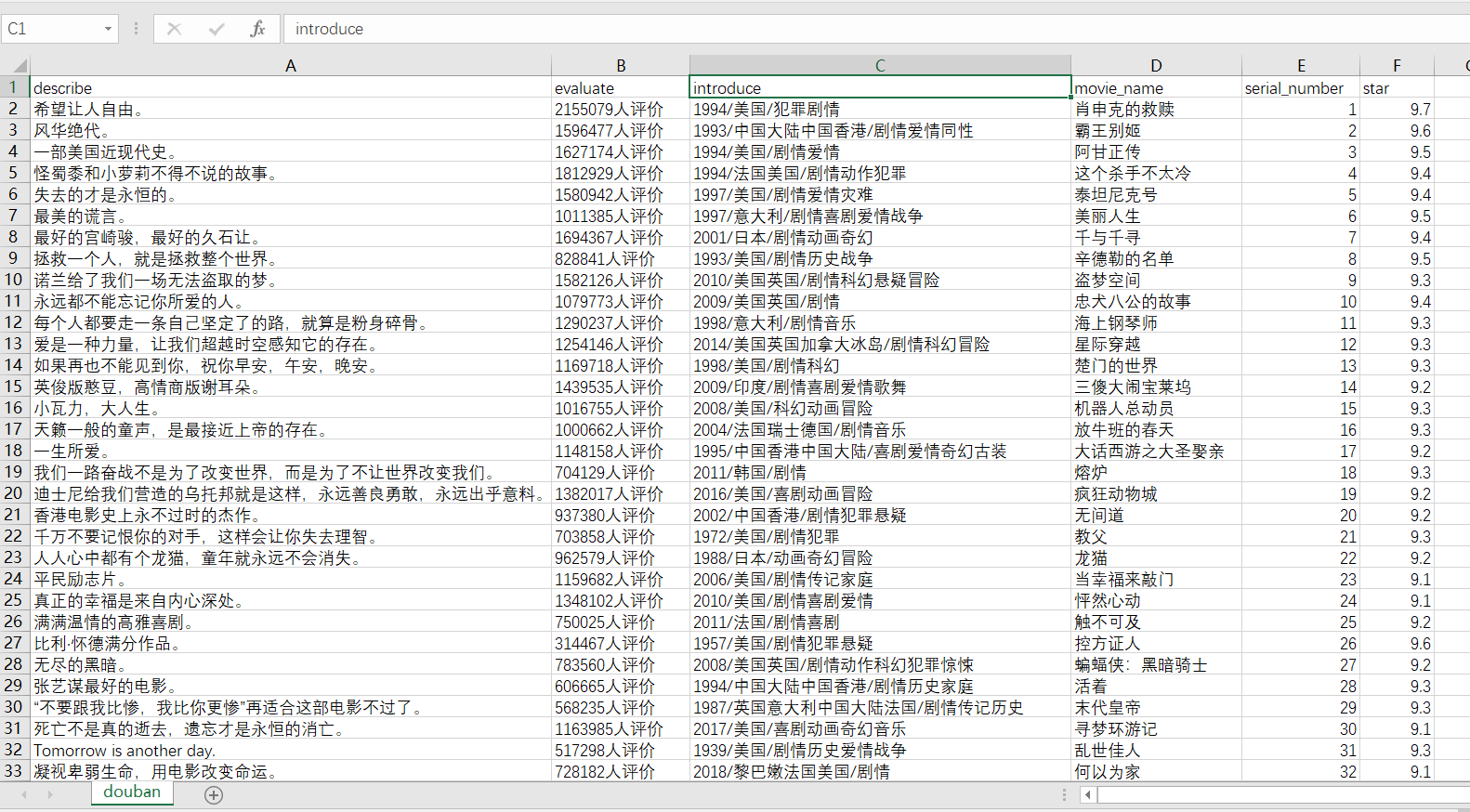
关系 csv文件打开乱码问题 :
原因:CSV是用UTF-8编码的,而EXCEL是ANSI编码,由于编码方式不一致导致出现乱码。
解决,用记事本打开,另存为为ANSI编码即可。
2)保存到MongoDB数据库里面
-
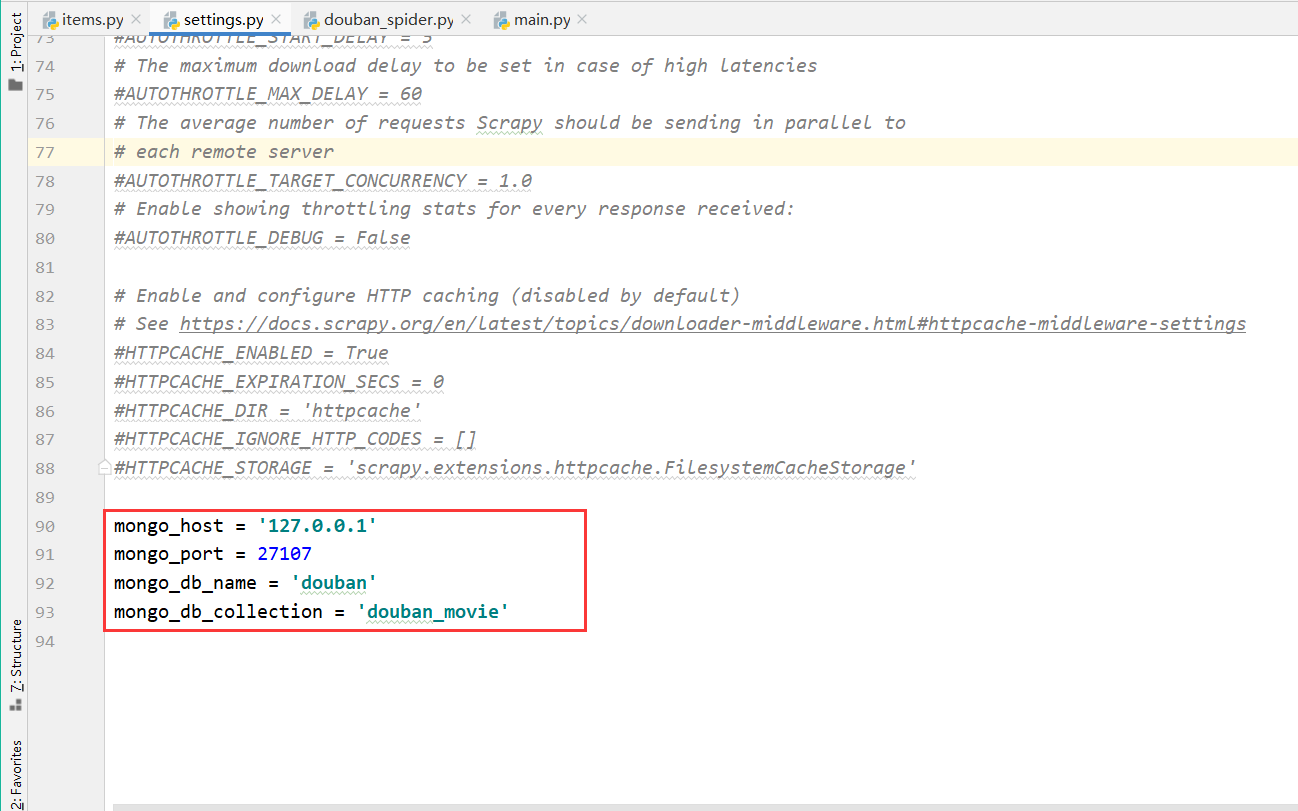
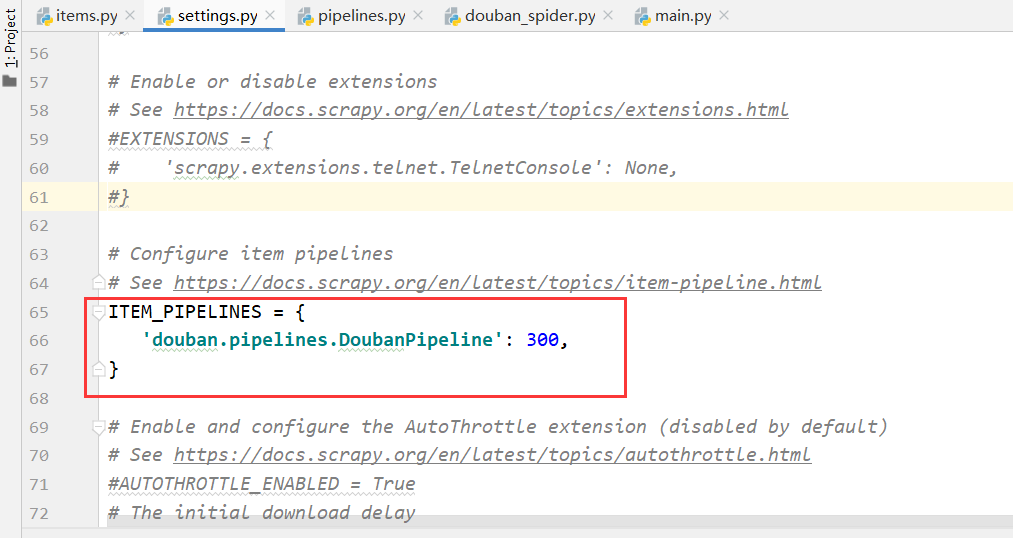
1、在 settings.py文件中填写主机地址、端口、数据库名、数据库表并开启ITEM_PIPELINES
-
2、在 pipelines.py文件中进行编写
在编写之前需要下载 pymongo模块
pip install pymongo# useful for handling different item types with a single interface from itemadapter import ItemAdapter import pymongo from douban.settings import mongo_host, mongo_port, mongo_db_name, mongo_db_collection class DoubanPipeline: def __init__(self): host = mongo_host port = mongo_port dbname = mongo_db_name sheetname = mongo_db_collection # 获取 MongoDB的连接 client = pymongo.MongoClient(host=host, port=port) # 指定数据库 mydb = client[dbname] # 指定数据库表 self.post = mydb[sheetname] def process_item(self, item, spider): """ 进行数据的插入 """ data = dict(item) self.post.insert(data) return item然后在 main.py中右键运行即可。
-
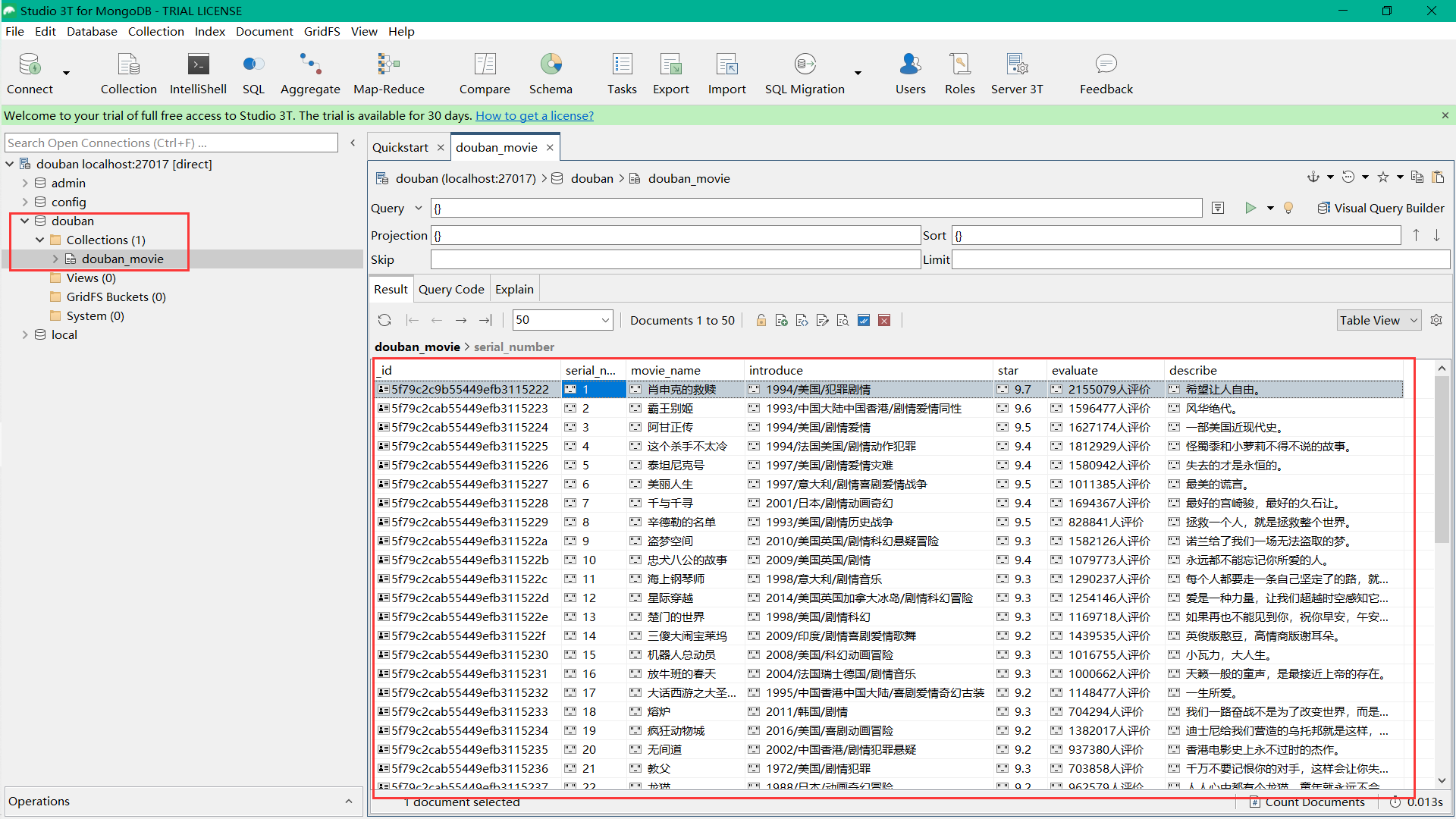
3、在MongoDB中查看我们保存的数据
MongoDB可视化工具下载地址:https://robomongo.org/
以下为扩展内容
八、IP代理中间件的编写
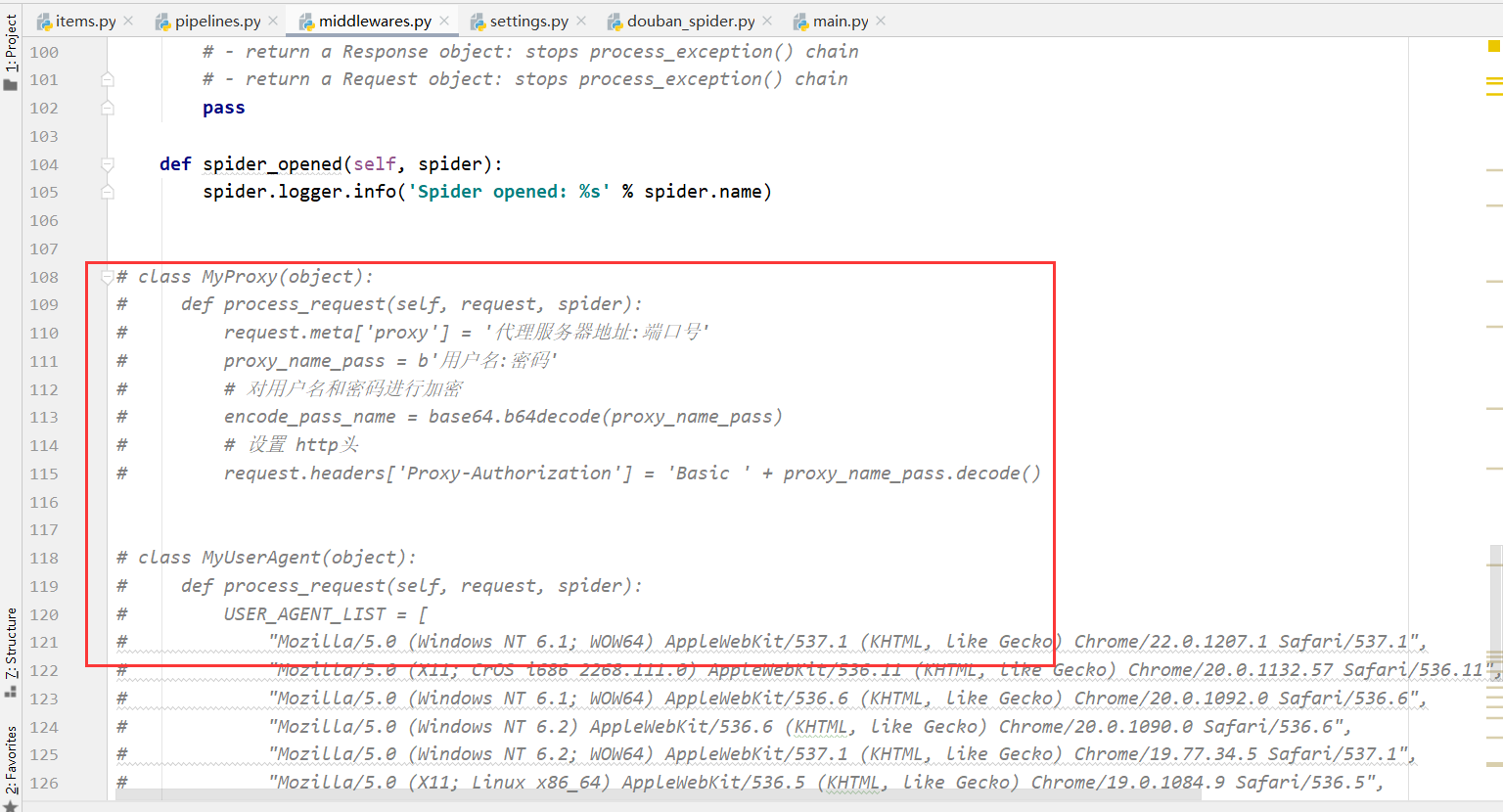
1、在middlewares.py文件中编写
class MyProxy(object):
def process_request(self, request, spider):
request.meta['proxy'] = '代理服务器地址:端口号'
proxy_name_pass = b'用户名:密码'
# 对用户名和密码进行加密
encode_pass_name = base64.b64decode(proxy_name_pass)
# 设置 http头
request.headers['Proxy-Authorization'] = 'Basic ' + proxy_name_pass.decode()
2、在settings.py文件中开启DOWNLOADER_MIDDLEWARES
DOWNLOADER_MIDDLEWARES = {
#'douban.middlewares.DoubanDownloaderMiddleware': 543,
'douban.middlewares.MyProxy': 300,
# 300为设置的优先级,数字越小,优先级越高
}
九、User-Agent中间件的编写
1、在middlewares.py文件中进行编写
class MyUserAgent(object):
def process_request(self, request, spider):
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
agent = random.choice(USER_AGENT_LIST)
request.headers['User-Agent'] = agent
2、在settings.py文件中引入
DOWNLOADER_MIDDLEWARES = {
# 'douban.middlewares.DoubanDownloaderMiddleware': 543,
'douban.middlewares.MyProxy': 543,
'douban.middlewares.MyUserAgent': 544
}
十、注意事项
- 中间件定义完要在settings文件内启用
- 爬虫文件名和爬虫名称不能相同,spiders目录内不能存在相同爬虫名称的项目文件
- 做一个文明守法的好网民,不要爬取公民的隐私数据,不要给对方的系统带来不必要的麻烦
补充、解决content切割只有最后一组(年份/地区/类型)字符串的问题
- 解决前

- 改写代码
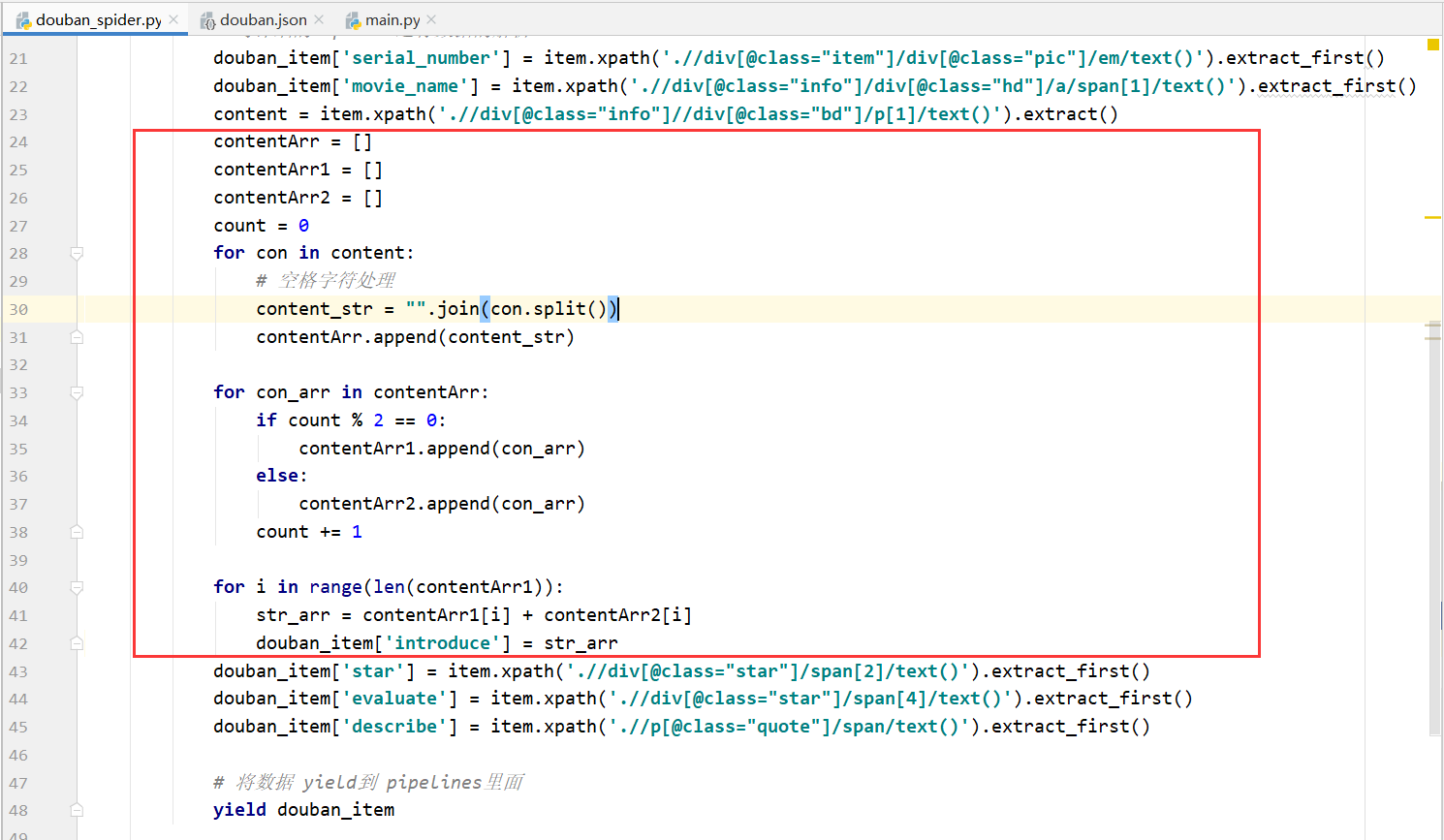
- 解决后

Scrapy框架补充 :
https://blog.csdn.net/qq_43401941/article/details/109165761















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









