









目录
1、什么是LSTM
- LSTM(Long short-term memory)是一种在深度学习中广泛使用的RNN结构,擅长捕捉长期的依赖关系,适合序列预测。(为什么能捕捉长期依赖关系?)
- 和传统的神经网络不同,LSTM包含反馈连接,(带来的好处是)能够处理全部的数据序列,而不是单个的数据点,使得在时间序列、文本、话音等序列数据中有较强的性能。
2、LSTM的结构
- LSTM可以解决RNN反向传播中的梯度消失问题(什么是梯度消失问题?为什么RNN有梯度消失问题?为什么LSTM可以解决?)。
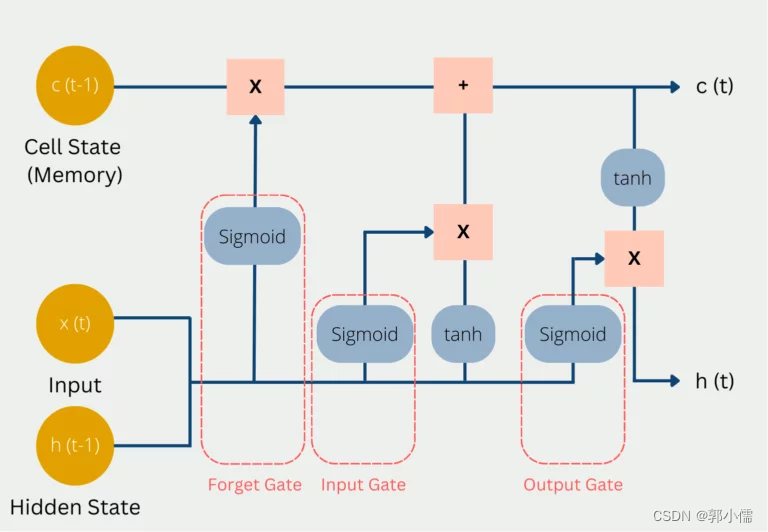
- 下面是LSTM网络的内部结构,包含三个部分:

- 第一部分:选择决定前一个时间戳的信息是记还是不记(遗忘门 the forget gate)
- 第二部分:将新的信息选择性的记录到记忆单元中(输入门 the input gate)
- 第三部分:传递从当前时间戳学习到的新的信息给下一个时间戳(输出门 the output gate)
这三个门控制了lstm cell或者memory cell的信息进出,一个LSTM unit(包括这三个门和一个lstm cell)可以被视为传统的前馈神经网络的一层神经元,每一个神经元都有一个隐藏层和一个当前状态。(什么是lstm cell?)

和RNN一样,LSTM需要前一个时间戳的隐藏层状态 H ( t − 1 ) H(t-1) H(t−1),用来得到当前时间戳的隐藏层状态 H ( t ) H(t) H(t),RNN的公式就是: H ( t ) = f ( U ∗ X ( t ) + W ∗ H ( t − 1 ) ) H(t)=f(U\ast X(t)+W \ast H(t-1)) H(t)=f(U∗X(t)+W∗H(t−1))(短期记忆 short term memery)
和RNN的区别,LSTM引入了一个记忆单元,携带了所有时间戳的所有信息,用
C
(
t
−
1
)
C(t-1)
C(t−1)和
C
(
t
)
C(t)
C(t)表示。(长期记忆 long term memery)

更细节的结构:

3、遗忘门 Forget gate
“Bob is a nice person. Dan, on the Other hand, is evil.
对于使用句号分开的两个句子,很明显,在第一句中,我们谈论的是Bob,一遇到句号(.),我们就开始谈论Dan。
当我们从第一句话转到第二句话时,我们的网络应该意识到我们不再谈论Bob。现在我们的主题是Dan。
在这里,LSTM网络的遗忘门会忘记Bob。
功能:选择决定前一个时间戳的信息是记还是不记

遗忘门的公式:
f
t
=
σ
(
x
t
⋅
U
f
+
H
t
−
1
⋅
W
f
)
f
t
=
σ
(
W
f
⋅
[
h
t
−
1
,
x
t
]
+
b
f
)
f_t =\sigma(x_t \cdot U_f+H_{t-1} \cdot W_f)\\ f_t =\sigma(W_f \cdot [h_{t-1},x_t]+b_f)\\
ft=σ(xt⋅Uf+Ht−1⋅Wf)ft=σ(Wf⋅[ht−1,xt]+bf)
其中:
- x t x_t xt:当前时间戳的输入
- U f U_f Uf:权重矩阵
- H t − 1 H_{t-1} Ht−1:前一个时间戳的隐藏层状态
- W f W_f Wf:权重矩阵
- σ \sigma σ:限制 f t f_t ft在0到1之间
-
f
t
f_t
ft之后会元素乘上
C
t
−
1
C_{t-1}
Ct−1,如果
f
t
=
1
f_t=1
ft=1,那么说明过去的记忆(上一个时间戳)要保留,否则删除。
C t − 1 ∗ f t = 0 (忘记全部) C t − 1 ∗ f t = C t − 1 (记住全部) C_{t-1} \ast f_t=0 (忘记全部)\\ C_{t-1} \ast f_t=C_{t-1}(记住全部) Ct−1∗ft=0(忘记全部)Ct−1∗ft=Ct−1(记住全部)-
∗
\ast
∗或者
⊙
\odot
⊙:元素乘,哈达玛积(Hadamard product)哈达玛积首先保证矩阵的结构相同,把对应位置的数值相乘。
-
∗
\ast
∗或者
⊙
\odot
⊙:元素乘,哈达玛积(Hadamard product)哈达玛积首先保证矩阵的结构相同,把对应位置的数值相乘。

4、输入门 Input gate
“Bob knows swimming. He told me over the phone that he had served the navy for four long years.”
这两句话谈论的都是Bob,但是谈论的内容是不同的。第一句我们知道了Bob会游泳,第二句我们知道了他是用电话告知他在海军服役四年。
对于第一句我们知道了Bob会游泳的这个内容,在第二句中的两个信息“使用电话告知”和“在海军服役四年”中,他是否使用电话或任何其他通信媒介来传递信息并不重要。他在海军服役的事实是重要的信息,这是我们希望我们的模型在未来的计算中记住的。这是输入门的任务。
功能:量化输入所携带的新信息的重要性,选择性的记录到记忆单元中

包含两个部分:
(1)、sigmoid层(输入门层):从当前输入判断哪些信息比较重要
i
t
=
σ
(
x
t
⋅
U
i
+
H
t
−
1
⋅
W
i
)
(或者)
i
t
=
σ
(
W
i
⋅
[
H
t
−
1
,
x
t
]
+
b
i
)
i_t=\sigma(x_t \cdot U_i+H_{t-1} \cdot W_i)(或者)\\ i_t=\sigma(W_i\cdot [H_{t-1},x_t]+b_i)
it=σ(xt⋅Ui+Ht−1⋅Wi)(或者)it=σ(Wi⋅[Ht−1,xt]+bi)
其中:
- x t x_t xt:当前时间戳的输入
- U i U_i Ui:权重矩阵
- H t − 1 H_{t-1} Ht−1:前一个时间戳的隐藏层状态
- W i W_i Wi:权重矩阵
- σ \sigma σ:限制 i t i_t it在0到1之间,0就代表信息很重要,1就代表信息不重要
(2)、tanh层:对提取的有效信息做出筛选
创建一个候选者向量
C
~
t
\tilde C_t
C~t:
C
~
t
=
t
a
n
h
(
x
t
⋅
U
c
+
H
t
−
1
⋅
W
c
)
(或者)
C
~
t
=
t
a
n
h
(
W
c
⋅
[
h
t
−
1
,
x
t
]
+
b
c
)
\tilde C_t=tanh(x_t \cdot U_c +H_{t-1} \cdot W_c)(或者)\\ \tilde C_t=tanh(W_c \cdot [h_{t-1},x_t]+b_c)
C~t=tanh(xt⋅Uc+Ht−1⋅Wc)(或者)C~t=tanh(Wc⋅[ht−1,xt]+bc)
其中:
- x t x_t xt:当前时间戳的输入
- U c U_c Uc:权重矩阵
- H t − 1 H_{t-1} Ht−1:前一个时间戳的隐藏层状态
- W c W_c Wc:权重矩阵
- t a n h tanh tanh:限制 C ~ t \tilde C_t C~t在-1到1之间,如果 C ~ t < 0 \tilde C_t <0 C~t<0,那么将把信息从记忆单元中删掉,反之则加上这个信息。
(3)、更新记忆单元状态 Cell state

- 将 f t f_t ft元素乘上上一个时间戳的记忆单元 C t − 1 C_{t-1} Ct−1,如果值为0,那么记忆单元的值就要被丢弃。
- 将 i t i_t it元素乘上候选值 C ~ t \tilde C_t C~t,如果值为0,代表记忆单元的值不大重要,就被丢弃掉
- 最后将上面两个输出结果元素加,更新记忆单元状态
C
t
C_t
Ct
C t = f t ∗ C t − 1 + i t ∗ C ~ t C_t=f_t \ast C_{t-1}+i_t \ast \tilde C_t Ct=ft∗Ct−1+it∗C~t
f t f_t ft表示忘记上一次的信息 C t − 1 C_{t-1} Ct−1的程度
i t i_t it表示要将候选值 C ~ t \tilde C_t C~t加入的程度
这一步我们真正实现了移除哪些旧的信息(比如上一句的主语),增加哪些新信息(海军),最后得到了记忆单元的状态 C t C_t Ct
5、输出门 Output gate
Bob single-handedly fought the enemy and died for his country. For his contributions, brave______.”
在这项任务中,我们必须完成第二句话。现在,当我们看到brave这个词的那一刻,我们就知道我们在谈论一个人。在句子中,只有Bob是brave的,我们不能说enemy是勇敢的或country是勇敢的。因此,基于目前的推测,我们必须给出一个相关的词来填补空白。
功能:确定下一个隐藏状态的值

(1)、sigmoid层(输出门层):决定哪些信息可以通过输出门
o
t
=
σ
(
x
t
⋅
U
o
+
H
t
−
1
⋅
W
o
)
(或者)
o
t
=
σ
(
W
t
⋅
[
H
t
−
1
,
x
t
]
+
b
t
)
o_t=\sigma(x_t \cdot U_o+H_{t-1} \cdot W_o)(或者)\\ o_t=\sigma(W_t \cdot [H_{t-1},x_t]+b_t)
ot=σ(xt⋅Uo+Ht−1⋅Wo)(或者)ot=σ(Wt⋅[Ht−1,xt]+bt)
其中:
- x t x_t xt:当前时间戳的输入
- U o U_o Uo:权重矩阵
- H t − 1 H_{t-1} Ht−1:前一个时间戳的隐藏层状态
- W o W_o Wo:权重矩阵
- σ \sigma σ:限制 o t o_t ot在0到1之间
(2)、tanh层:获得最终的输出
h t = o t ∗ t a n h ( C t ) h_t=o_t \ast tanh(C_t) ht=ot∗tanh(Ct)
最后,新的记忆单元状态和新的隐藏层状态被转移到下一个时间戳。
6、LSTM的更直观的结构图
各个变量的关系图:

补充知识:
(1)、tanh函数

- 非线性函数
- 值在-1到1之间
(2)、sigmoid函数

- 非线性函数
- 值在0到1之间
- 它有助于网络更新或忘记数据。如果相乘结果为0,则认为该信息已被遗忘。类似地,如果值为1,则信息保持不变。
参考链接:
1、元素乘法
2、LSTM结构讲解
3、Introduction to LSTM Units in RNN
4、What is LSTM? Introduction to Long Short-Term Memory


















 3918
3918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











