







文章目录
- 数组篇
- 链表篇
- 哈希表篇
- 字符串篇
- 541. 反转字符串II:纯字符串
- 栈和队列篇
- 二叉树篇
- 回溯篇
- 51. N皇后(t)
- 贪心篇
数组篇
704. 二分查找
LC链接:704
1、题目描述
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
示例 1:
输入: nums = [-1,0,3,5,9,12], target = 9
输出: 4
解释: 9 出现在 nums 中并且下标为 4
示例 2:
输入: nums = [-1,0,3,5,9,12], target = 2
输出: -1
解释: 2 不存在 nums 中因此返回 -1
提示:
你可以假设 nums 中的所有元素是不重复的。
n 将在 [1, 10000]之间。
nums 的每个元素都将在 [-9999, 9999]之间。
2、思路:二分法模版题
(1)前提
- 有序
- 无重复元素
(2)左闭右闭
def binary_search(nums: list[int], target: int) -> int:
"""二分查找(双闭区间)"""
# 初始化双闭区间 [0, n-1] ,即 i, j 分别指向数组首元素、尾元素
i, j = 0, len(nums) - 1
# 循环,当搜索区间为空时跳出(当 i > j 时为空)
while i <= j:
# 理论上 Python 的数字可以无限大(取决于内存大小),无须考虑大数越界问题
m = (i + j) // 2 # 计算中点索引 m
if nums[m] < target:
i = m + 1 # 此情况说明 target 在区间 [m+1, j] 中
elif nums[m] > target:
j = m - 1 # 此情况说明 target 在区间 [i, m-1] 中
else:
return m # 找到目标元素,返回其索引
return -1 # 未找到目标元素,返回 -1
3、代码
class Solution:
def search(self, nums: List[int], target: int) -> int:
left = 0
right = len(nums) - 1
while right >= left:
mid = left + (right - left) // 2
if nums[mid]>target:
right = mid - 1
elif nums[mid]<target:
left = mid + 1
else:
return mid
return -1
- 时间复杂度:O(log n) 每次缩小一半范围 n/2 n/4 n/8 一直到 1 就是logn
- 空间复杂度:O(1) 没有定义数组,只使用了变量
977.有序数组的平方
LC链接:977
1、题目描述
给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。
示例 1:
输入:nums = [-4,-1,0,3,10]
输出:[0,1,9,16,100]
解释:平方后,数组变为 [16,1,0,9,100]
排序后,数组变为 [0,1,9,16,100]
示例 2:
输入:nums = [-7,-3,2,3,11]
输出:[4,9,9,49,121]
提示:
1 <= nums.length <= 104
-104 <= nums[i] <= 104
nums 已按 非递减顺序 排序
进阶:
请你设计时间复杂度为 O(n) 的算法解决本问题
2、思路
(1)暴力法
先平方然后sort
平方时间复杂度o(n)
sort时间复杂度on(logn)
(2)双指针
因为原来数组是排好顺序的,平方之后最小值(负数)有可能变为最大值,但是平方后的最大值一定在原数组的两端

3、代码
class Solution:
def sortedSquares(self, nums: List[int]) -> List[int]:
# 因为原来数组是排好顺序的,平方之后最小值(负数)有可能变为最大值,但是平方后的最大值一定在原数组的两端
# 创建一个结果数组
res = [0]*(len(nums))
# 定义三个指针
left = 0 # 原数组左边
right = len(nums) - 1 # 原数组右边
p = right # 新数组右边
while left <= right:
if nums[left] ** 2 >= nums[right]**2:
res[p] = nums[left] ** 2
left += 1
p -= 1
else:
res[p] = nums[right] ** 2
right -= 1
p -= 1
return res
LC209 长度最小的子数组
题目
找到正整数数组nums的总和大于等于target的 连续子数组,返回字数组长度,不存在,返回0。

代码(python)
class Solution:
def minSubArrayLen(self, target: int, nums: List[int]) -> int:
if nums is None or len(nums) == 0:
return 0
# 滑动窗口(不定长问题)
# Step 1: 定义需要维护的变量们
sum = 0
n = len(nums)
res = n + 1
# Step 2: 定义窗口的首尾端 (start, end), 然后滑动窗口
start = 0
end = 0
while end < n:
# Step 3: 更新需要维护的变量
sum += nums[end]
# Step 4 - 情况2
# 如果当前窗口不合法时, 用一个while去不断移动窗口左指针, 从而剔除非法元素直到窗口再次合法
while sum >= target:
# 在左指针移动之前更新Step 1定义的(部分或所有)维护变量
res = min(res,end-start+1)
sum -= nums[start]
start += 1
end += 1
if res == n + 1:
return 0
else:
return res
LC59螺旋矩阵2(medium)重点
题目描述

方法:循环不变量
在二分法中的循环不变量就是取得区间的两端是开区间还是闭区间,所以分为了两种方法双闭区间法和左闭右开区间
❓在这里这种非常复杂的循环问题,就一定要明确每次循环处理的到底是那一部分?
✔️我们每次只处理每一条边的第一个节点到倒数第二个节点

那么每一个循环将依次处理四条边:
- 上行从左到右
- 右列从上到下
- 下行从右到左
- 左列从下到上
🌟找一下规律:
- n = 1时旋转0次
- n = 2时旋转1次
- n = 3时旋转1次
- n = 4时旋转2次
- n = 5时旋转2次
- n = 6时旋转3次
- …
可以知道无论n是偶数还是奇数,旋转次数= n / / 2 n//2 n//2,但是当n为奇数的时候,会在矩阵的最中心空着一个格子,单独填入就行
具体的处理流程:

可以对照着看代码就会很清晰了
class Solution:
def generateMatrix(self, n: int) -> List[List[int]]:
# 首先先初始化一个全是0的nxn二维矩阵
mat = [[0 for _ in range(n)] for _ in range(n)]
# 定义每一圈的起始点坐标
start_x = 0
start_y = 0
# 定义表示不同圈的每一条边的倒数第二个节点的偏移量
# 比如第1圈是j = (n-1) - 1
# 第2圈就是j = (n-1) - 2
offset = 1
# 定义要往矩阵中填入的数
count = 1
loop = n //2
# 循环开始
for time in range(0,loop):
# 填充上行从左到右:横坐标不变且是start_x,纵坐标从start_y到(n - 1) - 1
for j in range(start_y, n - offset):# 因为range“顾头不顾腚”所以可以少写一个-1
mat[start_x][j] = count
count += 1
# 填充右列从上到下:横坐标从start_x到(n-1)-offset,纵坐标不变且是上行最后一个元素的坐标加一(j = n - offset)
# 此时到达了上行的倒数第二个元素(start_x,j = (n-1)-offset)
# 那么右列的第一个元素就是(start_x,n - offset)
for i in range(start_x, n - offset):
mat[i][n - offset] = count
count += 1
# 填充下行从右到左:横坐标不变是上列最后一个元素的横坐标加一(i = n - offset),纵坐标从上一次的j = n - offset 一直减到start_y + 1
for j in range(n - offset, start_y, -1):
mat[n - offset][j] = count
count += 1
# 填充左列从下到上:横坐标从上一次的i = n - offset一只减到start_x + 1,纵坐标不变就是上一行最后一个元素的纵坐标减一(start_y)
for i in range(n - offset, start_x, -1):
mat[i][start_y] = count
count += 1
# 更新起始点坐标
start_x += 1
start_y += 1
offset += 1
mid = n // 2
if n%2 != 0:
mat[mid][mid] = count
return mat
时间复杂度: O ( n 2 ) O(n^2) O(n2)
空间复杂度: O ( n 2 ) O(n^2) O(n2)
58. 区间和(t,acm)
题目描述
给定一个整数数组 Array,请计算该数组在每个指定区间内元素的总和。
输入描述
第一行输入为整数数组 Array 的长度 n,接下来 n 行,每行一个整数,表示数组的元素。随后的输入为需要计算总和的区间,直至文件结束。
输出描述
输出每个指定区间内元素的总和。
代码
import sys
input = sys.stdin.read
def main():
data = input().split()
index = 0
n = int(data[index])
index += 1
vec = []
for i in range(n):
vec.append(int(data[index + i]))
index += n
p = [0] * n
presum = 0
for i in range(n):
presum += vec[i]
p[i] = presum
results = []
while index < len(data):
a = int(data[index])
b = int(data[index + 1])
index += 2
if a == 0:
sum_value = p[b]
else:
sum_value = p[b] - p[a - 1]
results.append(sum_value)
for result in results:
print(result)
if __name__ == "__main__":
main()
44. 开发商购买土地
在一个城市区域内,被划分成了n * m个连续的区块,每个区块都拥有不同的权值,代表着其土地价值。目前,有两家开发公司,A 公司和 B 公司,希望购买这个城市区域的土地。
现在,需要将这个城市区域的所有区块分配给 A 公司和 B 公司。
然而,由于城市规划的限制,只允许将区域按横向或纵向划分成两个子区域,而且每个子区域都必须包含一个或多个区块。
为了确保公平竞争,你需要找到一种分配方式,使得 A 公司和 B 公司各自的子区域内的土地总价值之差最小。
注意:区块不可再分。
【输入描述】
第一行输入两个正整数,代表 n 和 m。
接下来的 n 行,每行输出 m 个正整数。
输出描述
请输出一个整数,代表两个子区域内土地总价值之间的最小差距。
def main():
import sys
input = sys.stdin.read
data = input().split()
idx = 0
n = int(data[idx])
idx += 1
m = int(data[idx])
idx += 1
sum = 0
vec = []
for i in range(n):
row = []
for j in range(m):
num = int(data[idx])
idx += 1
row.append(num)
sum += num
vec.append(row)
# 统计横向
horizontal = [0] * n
for i in range(n):
for j in range(m):
horizontal[i] += vec[i][j]
# 统计纵向
vertical = [0] * m
for j in range(m):
for i in range(n):
vertical[j] += vec[i][j]
result = float('inf')
horizontalCut = 0
for i in range(n):
horizontalCut += horizontal[i]
result = min(result, abs(sum - 2 * horizontalCut))
verticalCut = 0
for j in range(m):
verticalCut += vertical[j]
result = min(result, abs(sum - 2 * verticalCut))
print(result)
if __name__ == "__main__":
main()
链表篇
LC203移除链表元素
题目描述
给你一个链表的头节点
head和一个整数val,请你删除链表中所有满足Node.val == val的节点,并返回 新的头节点 。

思路
链表移除某一个节点只需要将上一个节点的next指针指向下一个节点就行了

但是如果要移除头节点,头结点可是没有上一个节点的,所以要把头节点直接指向头节点的下一节点。

所以就要把所有节点分成两种情况:是头节点和不是头结点
但是也可以用一种情况来实现删除操作:加入虚拟头结点 ,这样头结点也变成了一般节点。
代码
两种情况分类讨论
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def removeElements(self, head: Optional[ListNode], val: int) -> Optional[ListNode]:
# 不使用虚拟头结点:两种情况
# 判断是否为头结点
while head != None and head.val == val:
head = head.next
# 如果删除的不是头结点是中间的节点
cur = head
while cur != None and cur.next !=None:
if cur.val == val:
cur.next = cur.next.next
else:
cur = cur.next
return head
- 时间复杂度: O(n)
- 空间复杂度: O(1)
💡为什么要循环判断头结点是否是目标节点?
因为如果链表是1->1->1->null,val = 1,那么就需要循环的删除头节点,所以不能简单的判断,而应该是while
💡如果删除规则是前一个节点的next指针指向下一个节点,那为什么不把cur设置为当前要被删除的节点?

使用虚拟头节点
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def removeElements(self, head: Optional[ListNode], val: int) -> Optional[ListNode]:
# 使用虚拟头结点
dummyhead = ListNode(-1) # 首先初始化虚拟头结点
dummyhead.next = head # 让虚拟头结点的next指针指向头节点,这样就把头节点的处理变成了一般节点的处理
cur = dummyhead # 令cur表示要删除的节点的前一个节点
while cur.next != None:
if cur.next.val == val:
cur.next = cur.next.next
else:
cur = cur.next
return dummyhead.next
- 时间复杂度: O(n)
- 空间复杂度: O(1)
💡为什么最后返回的是dummyhead.next不是head?
因为如果头节点是目标值的话,头节点已经被更新了,所以要用一直没有被动过的dummyhead节点来作为返回值,才能返回完整的处理后的链表。
707. 设计链表
题目链接:link
1、题目描述
实现 MyLinkedList 类:
MyLinkedList() 初始化 MyLinkedList 对象。
int get(int index) 获取链表中下标为 index 的节点的值。如果下标无效,则返回 -1 。
void addAtHead(int val) 将一个值为 val 的节点插入到链表中第一个元素之前。在插入完成后,新节点会成为链表的第一个节点。
void addAtTail(int val) 将一个值为 val 的节点追加到链表中作为链表的最后一个元素。
void addAtIndex(int index, int val) 将一个值为 val 的节点插入到链表中下标为 index 的节点之前。如果 index 等于链表的长度,那么该节点会被追加到链表的末尾。如果 index 比长度更大,该节点将 不会插入 到链表中。
void deleteAtIndex(int index) 如果下标有效,则删除链表中下标为 index 的节点。
2、思路
1️⃣ 插入节点:先连接后面的节点,再连接前面的节点
2️⃣删除节点:指针要指向被删除节点的前一个节点
3、code
class LinkNode:
def __init__(self,val,next):
self.val = val
self.next = None
class MyLinkedList:
def __init__(self):
self.dummyhead = LinkNode(-1,None)
self.size = 0
# def print(self):
# cur = self.dummyhead
# for i in range(self.size):
# print(cur.next.val)
# cur = cur.next
def get(self, index: int) -> int:
if index >= self.size:
return -1
# 如果链表是1,2,3,返回index = 1,就是2
cur = self.dummyhead.next
for i in range(0,index):
cur = cur.next
return cur.val
def addAtHead(self, val: int) -> None:
new_node = LinkNode(val,None)
new_node.next = self.dummyhead.next
self.dummyhead.next = new_node
self.size += 1
return
def addAtTail(self, val: int) -> None:
self.addAtIndex(self.size,val)
return
def addAtIndex(self, index: int, val: int) -> None:
if index > self.size:
return
# 原来是1,3,加入index = 1
cur = self.dummyhead
for i in range(index):
cur = cur.next
new_node = LinkNode(val,None)
new_node.next = cur.next
cur.next = new_node
self.size += 1
return
def deleteAtIndex(self, index: int) -> None:
if index >= self.size:
return
# 链表是1,2,3,删除index = 1,链表变成1,3
cur = self.dummyhead
for i in range(index):
cur = cur.next
cur.next = cur.next.next
self.size -= 1
return
# Your MyLinkedList object will be instantiated and called as such:
# obj = MyLinkedList()
# param_1 = obj.get(index)
# obj.addAtHead(val)
# obj.addAtTail(val)
# obj.addAtIndex(index,val)
# obj.deleteAtIndex(index)
LC206反转链表
题目描述
给你单链表的头节点
head,请你反转链表,并返回反转后的链表。

思路1:双指针

# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
# 双指针方法
# 首先初始化双指针
cur = head # 先保存头结点
pre = None # 因为头节点的反转下一个节点就是空节点
# 之后就是一节一节的反转链表,直到cur指向Null
while cur != None:
temp = cur.next # 如果反转链表的next指向的话,会使得正向的指针消失,所以要先保存一下
cur.next = pre # 反转
pre = cur # 要先后移pre
cur = temp # 后移动cur
return pre
# 时间复杂度 O(n)
# 空间复杂度O(1)
思路2:递归(根据双指针写出)

# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
# 递归方法:(根据双指针方法写的)
return self.reverse(head,None)
def reverse(self, cur, pre): # 传入两个指针就把它们反转一下
# 先写终止条件
if cur == None:
return pre
# 写拆解
temp = cur.next
cur.next = pre
return self.reverse(temp,cur)
# 时间复杂度O(n)
# 空间复杂度O(n)
LC160 相交链表(easy)
题目描述
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
思路1:双指针(求长度,同时出发)

# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> Optional[ListNode]:
if headA == None or headB == None:
return None
# 先求出两个链表的长度
lenA = 0
lenB = 0
cur = headA
while cur != None:
cur = cur.next
lenA += 1
cur = headB
while cur != None:
cur = cur.next
lenB += 1
if lenA < lenB: # 想让A是较长的链表
headA, headB = headB, headA
lenA, lenB = lenB, lenA
# 让curA指向两个链表尾部对其的地方
curA = headA
curB = headB
for _ in range(lenA-lenB):
curA = curA.next
# curA和curB同时移动
while curA != curB:
curA = curA.next
curB = curB.next
return curA
思路2:双指针(等比例法)

# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> Optional[ListNode]:
p1 = headA
p2 = headB
while p1 != p2:
if p1 != None:
p1 = p1.next
else:
p1 = headB
if p2 != None:
p2 = p2.next
else:
p2 = headA
return p1
LC707 设计链表
题目描述
你可以选择使用单链表或者双链表,设计并实现自己的链表。
单链表中的节点应该具备两个属性:
val和next。val是当前节点的值,next是指向下一个节点的指针/引用。如果是双向链表,则还需要属性
prev以指示链表中的上一个节点。假设链表中的所有节点下标从 0 开始。实现
MyLinkedList类:
MyLinkedList()初始化MyLinkedList对象。int get(int index)获取链表中下标为index的节点的值。如果下标无效,则返回-1。void addAtHead(int val)将一个值为val的节点插入到链表中第一个元素之前。在插入完成后,新节点会成为链表的第一个节点。void addAtTail(int val)将一个值为val的节点追加到链表中作为链表的最后一个元素。void addAtIndex(int index, int val)将一个值为val的节点插入到链表中下标为index的节点之前。如果index等于链表的长度,那么该节点会被追加到链表的末尾。如果index比长度更大,该节点将 不会插入 到链表中。void deleteAtIndex(int index)如果下标有效,则删除链表中下标为index的节点。
思路
- 获取节点:获取链表中下标为
index的节点
直接创建一个cur指针,逐渐移动到想要的节点
❤️要注意边界条件,可以把index=0带入进去
-
删除节点: 和LC707一样

💡创建虚拟头结点
dummyhead,目的是让头节点也变成一般节点💡创建一个
cur指针指向要被删除的节点的前一个节点 -
插入节点:

💡创建一个cur指针指向要插入位置的节点的前一个节点
💡要先连接后一个节点,再断开前一个节点
代码
# 首先先定义节点类
class LinkNode:
def __init__(self, val = 0, next = None):
self.val = val
self.next = next
class MyLinkedList:
def __init__(self):
# 创建一个虚拟头结点,目的是将头结点也表示为一般节点
self.dummyhead = LinkNode()
self.size = 0
def get(self, index: int) -> int:
# 先处理特殊情况:
if index >= self.size or index < 0:
return -1
cur = self.dummyhead.next
for i in range(index):
cur = cur.next
return cur.val
def addAtHead(self, val: int) -> None:
# 先实例化新节点
newnode = LinkNode(val)
# 先链接后面的节点,再链接前面的节点
newnode.next = self.dummyhead.next
self.dummyhead.next = newnode
self.size += 1
def addAtTail(self, val: int) -> None:
# 先实例化新节点
newnode = LinkNode(val)
# 要找到最后一个节点
cur = self.dummyhead
while cur.next != None:
cur = cur.next
# 更新最后一个节点: 先链接后面的节点,再链接前面的节点
newnode.next = None
cur.next = newnode
self.size += 1
def addAtIndex(self, index: int, val: int) -> None:
# 先实例化新节点
newnode = LinkNode(val)
# 先处理特别情况:index的值超过了链表长度
if index > self.size or self.size < 0:
return
# 要找到第index-1个节点
cur = self.dummyhead
for i in range(index):
cur = cur.next
newnode.next = cur.next
cur.next = newnode
self.size += 1
def deleteAtIndex(self, index: int) -> None:
# 先处理特殊情况
if index >= self.size or index < 0:
return
# 找到下表为index的节点
cur = self.dummyhead
# while index > 0:
# cur = cur.next
# index -= 1
for i in range(index):
cur = cur.next
temp = cur.next.next
cur.next = temp
self.size -= 1
# Your MyLinkedList object will be instantiated and called as such:
# obj = MyLinkedList()
# param_1 = obj.get(index)
# obj.addAtHead(val)
# obj.addAtTail(val)
# obj.addAtIndex(index,val)
# obj.deleteAtIndex(index)
两两交换链表中的节点(medium)
题目描述
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。

思路
- 交换节点的步骤

- 里面的细节分析
💡创建虚拟头结点dummyhead,目的是让头节点也变成一般节点
💡如果要交换节点1和节点2,创建的cur指针指向节点1的前一个节点(原因是单向链表只指向下一个节点)
💡循环的终止条件:两种情况
- 节点为偶数:cur.next == null
- 节点为奇数:cur.next.next == null
💗在终止语句里面一定要先写cur.next == null,因为如果cur.next == null,cur.next就不存在,也就没有next指针,会出现报错
💡创建临时变量:
- 在步骤一之前,要使用临时指针保存cur指向1的路径,因为在步骤二需要使用1
- 在步骤一之前,也要使用临时指针保存2指向3的路径,因为在步骤三要使用3
代码
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def swapPairs(self, head: Optional[ListNode]) -> Optional[ListNode]:
# 创建一个虚拟头结点,为了让处理头节点的方法和处理中间节点的方法保持一致
dummy = ListNode()
dummy.next = head
cur = dummy # 要让cur指向被操作的节点的前一个节点(因为单向链表只指向后一个链表)
while cur.next != None and cur.next.next != None:
# 首先要记录第一个节点和,第三个节点
temp1 = cur.next
temp2 = cur.next.next.next
# 将当前节点指向第二个节点
cur.next = cur.next.next
# 将第二个节点指向第一个节点
cur.next.next = temp1
# 将第一个节点指向第三个
temp1.next = temp2
# 移动cur到第二个节点上
cur = cur.next.next
return dummy.next
- 时间复杂度: O(n)
- 空间复杂度: O(1)
删除链表的倒数第n个节点
题目描述
给你一个链表,删除链表的倒数第
n个结点,并且返回链表的头结点。

思路
❣️快慢指针❣️

动图:

- 里面的细节分析
💡创建虚拟头结点dummyhead,目的是让头节点也变成一般节点
💡快慢指针的含义:
慢指针:就是要指向被删除的节点的前一个
快指针:要保证删除的是倒数第二个节点,就需要有一个指针去前面“探路”,比慢指针要快走(n+1)步
#3# python
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def removeNthFromEnd(self, head: Optional[ListNode], n: int) -> Optional[ListNode]:
# 创建一个虚拟头指针
dummyhead = ListNode()
dummyhead.next = head
# 创建快慢指针
slow = dummyhead
fast = dummyhead
# 先让快指针跑(n+1)步
for _ in range(1,n+2):
fast = fast.next
# 当快指针跑到null时结束
while fast != None:
slow = slow.next
fast = fast.next
# 此时slow指向要被删除的节点的前一个
slow.next = slow.next.next
return dummyhead.next
- 时间复杂度: O(n)
- 空间复杂度: O(1)
LC141环形链表(easy)
题目描述

方法:快慢指针
(1)思路
使用快慢指针特性:每轮移动之后两者的距离会加一。
当一个链表有环时,快慢指针都会陷入环中进行无限次移动,然后变成了追及问题。想象一下在操场跑步的场景,只要一直跑下去,快的总会追上慢的。

💥 如果存在环,如何判断环的长度呢?
快慢指针相遇后继续移动,直到第二次相遇。两次相遇间的移动次数即为环的长度。
(2)python代码
class Solution:
def hasCycle(self, head: Optional[ListNode]) -> bool:
# 快慢指针
# time complexity = O(N)
# space complexity = O(1)
slow = head
fast = head
# 注意判断条件:fast, fast.next都不为None,才能循环
# fast.next不为 None,也是为了使 fast.next.next 能够被定义
while (fast is not None and fast.next is not None):
slow = slow.next
fast = fast.next.next
if slow == fast:
return True
return False
(3)复杂度分析:

LC142环形链表2(medium)
题目描述
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
和LC141区别: 不仅要判断是否有环,还需要返回入环节点
方法:快慢指针
(1)思路
如果有环,如何找到这个环的入口

❤️❤️❤️
x
=
z
x=z
x=z意味着:从头结点出发一个指针,从相遇节点 也出发一个指针,这两个指针每次只走一个节点, 那么当这两个指针相遇的时候就是 环形入口的节点。

(2)代码
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def detectCycle(self, head: Optional[ListNode]) -> Optional[ListNode]:
# 定义快慢指针
fast = head
slow = head
# 开始循环
while fast != None and fast.next != None:
fast = fast.next.next
slow = slow.next
if fast == slow:
index1 = head
index2 = fast
while index1 != index2:
index1 = index1.next
index2 = index2.next
return index1
return None
哈希表篇
242.有效的字母异位词
1. 题目描述
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
**注意:**若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。
示例 1:
输入: s = "anagram", t = "nagaram"
输出: true
示例 2:
输入: s = "rat", t = "car"
输出: false
2. 思路
(1)暴力法
两层for循环,同时还要记录字符是否重复出现,很明显时间复杂度是 O ( n 2 ) O(n^2) O(n2)
(2)哈希表
定义一个数组,来记录字符串s里字符出现的次数
需要定义一个多大的数组呢?
定一个数组叫做record,大小为26 就可以了,初始化为0,因为字符a到字符z的ASCII也是26个连续的数值。所以字符a映射为下标0,相应的字符z映射为下标25。
遍历 字符串s的时候,只需要将 s[i] - ‘a’ 所在的元素做+1 操作即可,并不需要记住字符a的ASCII,只要求出一个相对数值就可以了。 这样就将字符串s中字符出现的次数,统计出来了。
如何检查字符串t中是否出现了这些字符,同样在遍历字符串t的时候,对t中出现的字符映射哈希表索引上的数值再做-1的操作。
最后检查一下,record数组如果有的元素不为零0,说明字符串s和t一定是谁多了字符或者谁少了字符,return false。
如果record数组所有元素都为零0,说明字符串s和t是字母异位词,return true。
class Solution:
def get_sum(self, n):
# 计算n的每一位的平方值
sum = 0
while n:
r = n % 10
n = int(n / 10)
sum += r ** 2
# print(r)
return sum
def isHappy(self, n: int) -> bool:
record_sum = set()
while True:
sum = self.get_sum(n)
print(sum)
if sum == 1:
return True
if sum in record_sum:
return False
else:
record_sum.add(sum)
n = sum
1. 两数之和
1. 题目描述
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
3. code
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
mapping = {}
for i,x in enumerate(nums):
if target - x in mapping.keys():
return [mapping[target - x], i]
mapping[x] = i
return []
454.四数相加II
1. 题目描述
给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足:
0 <= i, j, k, l < nnums1[i] + nums2[j] + nums3[k] + nums4[l] == 0
示例 1:
输入:nums1 = [1,2], nums2 = [-2,-1], nums3 = [-1,2], nums4 = [0,2]
输出:2
解释:
两个元组如下:
1. (0, 0, 0, 1) -> nums1[0] + nums2[0] + nums3[0] + nums4[1] = 1 + (-2) + (-1) + 2 = 0
2. (1, 1, 0, 0) -> nums1[1] + nums2[1] + nums3[0] + nums4[0] = 2 + (-1) + (-1) + 0 = 0
为了使问题简单化,所有的 A, B, C, D 具有相同的长度 N,且 0 ≤ N ≤ 500 。所有整数的范围在 -2^28 到 2^28 - 1 之间,最终结果不会超过 2^31 - 1 。
2. 思路
- 首先定义 一个哈希表,key放a和b两数之和,value 放a和b两数之和出现的次数。
- 遍历大A和大B数组,统计两个数组元素之和,和出现的次数,放到map中。
- 定义int变量count,用来统计 a+b+c+d = 0 出现的次数。
- 在遍历大C和大D数组,找到如果 0-(c+d) 在map中出现过的话,就用count把map中key对应的value也就是出现次数统计出来。
- 最后返回统计值 count 就可以了
3. code
class Solution:
def fourSumCount(self, nums1: List[int], nums2: List[int], nums3: List[int], nums4: List[int]) -> int:
# 首先将nums1和nums2中各取一个元素,记录所有的结果值,放入到哈希表中
# key:结果,value:出现次数
map = {}
for a in nums1:
for b in nums2:
map[a + b] = map.get(a + b, 0) + 1
# 开始遍历nums3和nums4的值,计算新元素的负数是否在map中的key里面
flag = 0
for c in nums3:
for d in nums4:
if -(c + d) in map.keys():
flag += map[-c - d]
return flag
15. 三数之和
1.题目描述
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请
你返回所有和为 0 且不重复的三元组。
**注意:**答案中不可以包含重复的三元组。
示例 1:
输入:nums = [-1,0,1,2,-1,-4]
输出:[[-1,-1,2],[-1,0,1]]
解释:
nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。
nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0 。
nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。
不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。
注意,输出的顺序和三元组的顺序并不重要。
2. 思路——对撞双指针
为什么会想到对撞指针?
对撞指针就很适合需要把一串数的两个加起来,判断是否小于一个数的情况(LC1两数之和)
对撞指针的特性就是:一定要先排序(time complexity= o(nlogn)
思路:使用对撞双指针,从i开始遍历,然后分别取left = i + 1, right = 最后一个元素,判断是否为0
- 首先将数组排序,然后有一层for循环,i从下标0的地方开始,同时定一个下标left 定义在i+1的位置上,定义下标right 在数组结尾的位置上
- 如果nums[i] + nums[left] + nums[right] > 0 就说明 此时三数之和大了,因为数组是排序后了,所以right下标就应该向左移动,这样才能让三数之和小一些
- 如果 nums[i] + nums[left] + nums[right] < 0 说明 此时 三数之和小了,left 就向右移动,才能让三数之和大一些,直到left与right相遇为止
时间复杂度: O ( n 2 ) O(n^2) O(n2)
3. code
from typing import List
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
# 思路:使用对撞双指针,从i开始遍历,然后分别取left = i + 1, right = 最后一个元素,判断是否为0
# 对撞双指针第一步,永远是先排序
nums.sort() # tc = O(nlogn)
# print(nums)
result = []
# 开始遍历i->a(三个数中的第一个)
for i in range(len(nums)):
# 如果a都大于0,那么后面的bc一定都大于0,不可能相加为0
if nums[i] > 0:
return result
# a去重:指的是如果上一种情况第一个数字和这种情况的一个数字一样了,那么应该跳过
if i >= 1 and nums[i-1] == nums[i]:
continue
# 获得b和c
left = i + 1 # 保证不会同一个数重复的取
right = len(nums) - 1
# 开始遍历b和c
while left < right: # 为什么没有等号:如果相等意味着取了同一个元素,没有意义
k = nums[i] + nums[left] + nums[right]
if k>0: # 说明结果大了,就要变小
right -= 1
elif k<0:
left += 1
else:
# 获得结果
result.append([nums[left],nums[right],nums[i]])
# b和c去重:
while left < right and nums[left + 1] == nums[left]:
left += 1 # 说明b已经取过这个元素了
while left < right and nums[right - 1] == nums[right]:
right -= 1
# 获得结果之后,移动left和right
left += 1
right -= 1
return result
# s = Solution()
# print(s.threeSum([-1,0,1,2,-1,-4]))
字符串篇
344.反转字符串:字符组成的列表
1. 题目描述
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须**原地修改输入数组**、使用 O(1) 的额外空间解决这一问题。
示例 1:
输入:s = ["h","e","l","l","o"]
输出:["o","l","l","e","h"]
2. 思路
(1)双指针
定义两个指针(也可以说是索引下标),一个从字符串前面,一个从字符串后面,两个指针同时向中间移动,并交换元素
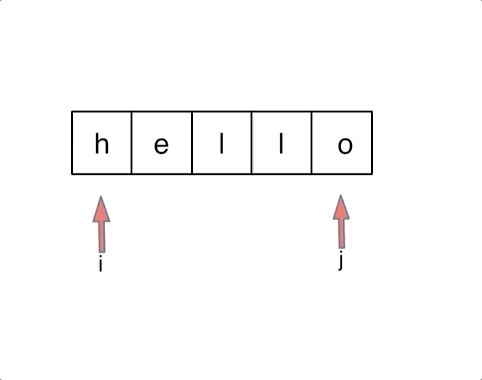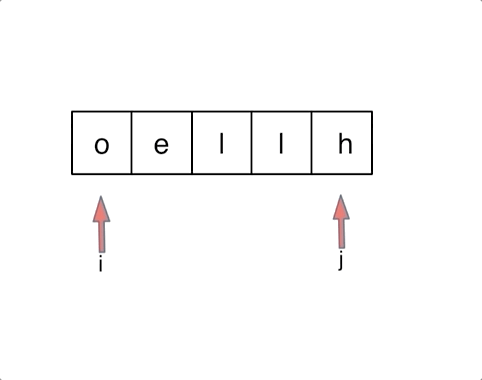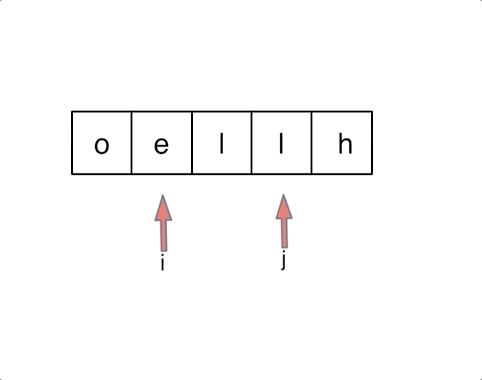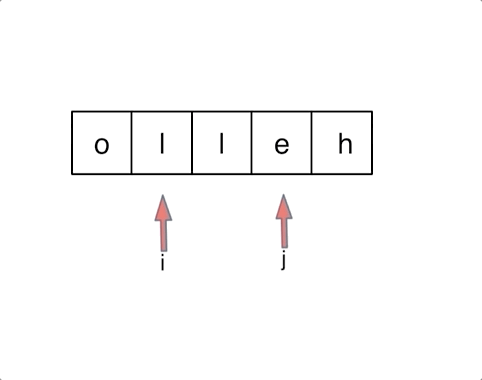
code
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
# 双指针法
left = 0
right = len(s) - 1
# 因为while每次循环需要进行条件判断,而range函数不需要,直接生成数字,因此时间复杂度更低。推荐使用range
while left <= right:
# s[left], s[right] = s[right], s[left]
temp = s[left]
s[left] = s[right]
s[right] = temp
left += 1
right -= 1
(2)栈
code
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
# 栈(先进后出的特点反转字符串)
stack = []
for x in s:
stack.append(x)
for i in range(len(s)):
s[i] = stack.pop()
# time complexity = o(n)
# space complexity = o(n)
(3)list.reverse():原地反转
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
# 原地反转,无返回值
s.reverse()
(4)list_new = reversed(list):生成新列表反转
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
s[:] = reversed(s)
(5)切片反转
class Solution:
def reverseString(self, s: List[str]) -> None:
"""
Do not return anything, modify s in-place instead.
"""
s[:] = s[::-1]
541. 反转字符串II:纯字符串
1. 题目描述
给定一个字符串 s 和一个整数 k,从字符串开头算起,每计数至 2k 个字符,就反转这 2k 字符中的前 k 个字符。
- 如果剩余字符少于
k个,则将剩余字符全部反转。 - 如果剩余字符小于
2k但大于或等于k个,则反转前k个字符,其余字符保持原样。
示例 1:
输入:s = "abcdefg", k = 2
输出:"bacdfeg"
示例 2:
输入:s = "abcd", k = 2
输出:"bacd"
2. 思路
要先把字符串转成list:list(str)
遍历字符串的过程中,只要让 i += (2 * k),i 每次移动 2 * k 就可以了,然后判断是否需要有反转的区间。所以当需要固定规律一段一段去处理字符串的时候,要想想在在for循环的表达式上做做文章。
for cur in range(0, len(s), 2 * k):
res[cur: cur + k] = reverse_substring(res[cur: cur + k])
之后就要调用上一题的反转字符串函数
3. code
class Solution:
def reverseStr(self, s: str, k: int) -> str:
"""
1. 使用range(start, end, step)来确定需要调换的初始位置
2. 对于字符串s = 'abc',如果使用s[0:999] ===> 'abc'。字符串末尾如果超过最大长度,则会返回至字符串最后一个值,这个特性可以避免一些边界条件的处理。
3. 用切片整体替换,而不是一个个替换.
"""
def reverse_substring(text):
left, right = 0, len(text) - 1
while left < right:
text[left], text[right] = text[right], text[left]
left += 1
right -= 1
return text
res = list(s)
for cur in range(0, len(s), 2 * k):
res[cur: cur + k] = reverse_substring(res[cur: cur + k])
return ''.join(res)
栈和队列篇
0、粗解栈和队列
(1)栈:先进后出

(2)栈操作时间复杂度
| 栈操作 | 时间复杂度 |
|---|---|
| 访问(栈顶元素) access | O ( 1 ) O(1) O(1) |
| 搜索 search | O ( N ) O(N) O(N) |
| 插入(栈顶元素)insert | O ( 1 ) O(1) O(1) |
| 删除(栈顶元素) delete | O ( 1 ) O(1) O(1) |
(3)python中栈的操作
- 创建栈:使用列表(list)创建栈
stack = []
- 入栈操作:将元素添加到栈顶
stack.append(1)
- 出栈操作:从栈顶删除元素
top_element = stack.pop()
- 查看栈顶元素:查看但不删除
top_element = stack[-1]
- 判断栈是否为空:判断栈长度是否为0
is_empty = len(stack) == 0
- 遍历栈
while len(stack) != 0:
temp = stack.pop()
# 对temp进行操作
(4)队列:先进先出

(5)队列操作时间复杂度 = 链表
| 队列操作 | 时间复杂度 |
|---|---|
| 访问 access | O ( N ) O(N) O(N) |
| 搜索 search | O ( N ) O(N) O(N) |
| 插入(队尾)insert | O ( 1 ) O(1) O(1) |
| 删除(队头) delete | O ( 1 ) O(1) O(1) |
(6)python中队列的操作
collections.deque
from collections import deque

- 获取出队元素:deque[0]
- 获取入队元素:deque[-1]
(1)LC232用栈实现队列(easy)
题目描述
实现 MyQueue 类:
- void push(int x) 将元素 x 推到队列的末尾
- int pop() 从队列的开头移除并返回元素
- int peek() 返回队列开头的元素
- boolean empty() 如果队列为空,返回 true ;否则,返回 false
思路:使用两个栈
使用两个栈, 一个栈模拟队列的输入,一个栈模拟队列的输出
- 输入数据:直接将数据放入输入栈
- 输出数据:
- 输出栈中还有数据:直接输出
- 输出栈中没有数据:将输入栈中的数据全部导入到输出栈,再输出输出栈的栈顶元素
执行语句:
queue.push(1);
queue.push(2);
queue.pop(); 注意此时的输出栈的操作
queue.push(3);
queue.push(4);
queue.pop();
queue.pop();注意此时的输出栈的操作
queue.pop();
queue.empty();

class MyQueue:
def __init__(self):
self.stackin = []
self.stackout = []
def push(self, x: int) -> None:
self.stackin.append(x)
def pop(self) -> int:
# 判断出栈有没有元素
if len(self.stackout) != 0:
return self.stackout.pop()
else:
while len(self.stackin) != 0:
self.stackout.append(self.stackin.pop())
return self.stackout.pop()
def peek(self) -> int:
temp = self.pop()
self.stackout.append(temp)
return temp
def empty(self) -> bool:
if len(self.stackin) == 0 and len(self.stackout) == 0:
return True
else:
return False
# Your MyQueue object will be instantiated and called as such:
# obj = MyQueue()
# obj.push(x)
# param_2 = obj.pop()
# param_3 = obj.peek()
# param_4 = obj.empty()
(2)LC225用队列实现栈(easy)
题目描述
使用队列实现栈的下列操作:
- push(x) – 元素 x 入栈
- pop() – 移除栈顶元素
- top() – 获取栈顶元素
- empty() – 返回栈是否为空
思路:一个队列vs两个队列
两个队列
要用两个队列来模拟栈,只不过没有输入和输出的关系,而是另一个队列完全用来备份的!
用两个队列que1和que2实现队列的功能,que2其实完全就是一个备份的作用,把que1最后面的元素以外的元素都备份到que2,然后弹出最后面的元素,再把其他元素从que2导回que1
- 输入数据:直接将数据放入que1
- 输出数据:
- que1中还有数据(代表这些数据还没有备份到que2):把这些数据都依次输出到que2中,留下最后一个输出
- que1中没有数据(代表之前的数据已经备份到que2):把这些数据都依次输出到que1中,留下最后一个输出
执行语句:
queue.push(1);
queue.push(2);
queue.pop(); // 注意弹出的操作
queue.push(3);
queue.push(4);
queue.pop(); // 注意弹出的操作
queue.pop();
queue.pop();
queue.empty();

from collections import deque
class MyStack:
def __init__(self):
self.queuein = deque()
self.queueout = deque()
def push(self, x: int) -> None:
self.queuein.append(x)
def pop(self) -> int:
if len(self.queuein) == 0 :
while len(self.queueout) != 1:
self.queuein.append(self.queueout.popleft())
return self.queueout.popleft()
else:
while len(self.queuein) != 1:
self.queueout.append(self.queuein.popleft())
return self.queuein.popleft()
def top(self) -> int:
temp = self.pop()
self.queuein.append(temp)
return temp
def empty(self) -> bool:
if len(self.queuein) == 0 and len(self.queueout) == 0:
return True
else:
return False
# Your MyStack object will be instantiated and called as such:
# obj = MyStack()
# obj.push(x)
# param_2 = obj.pop()
# param_3 = obj.top()
# param_4 = obj.empty()
一个队列
- 输入数据:直接将数据放入que
- 输出数据:将队列头部的元素(除了最后一个元素外) 重新添加到队列尾部,此时再去弹出元素就是栈的顺序
from collections import deque
class MyStack:
def __init__(self):
self.queue = deque()
def push(self, x: int) -> None:
self.queue.append(x)
def pop(self) -> int:
for _ in range(len(self.queue) - 1):
self.queue.append(self.queue.popleft())
return self.queue.popleft()
def top(self) -> int:
temp = self.pop()
self.queue.append(temp)
return temp
def empty(self) -> bool:
return True if len(self.queue) == 0 else False
# Your MyStack object will be instantiated and called as such:
# obj = MyStack()
# obj.push(x)
# param_2 = obj.pop()
# param_3 = obj.top()
# param_4 = obj.empty()
(3)LC20有效的括号(easy)
题目描述
给定一个只包括 ‘(’,‘)’,‘{’,‘}’,‘[’,‘]’ 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。
思路
- 创建一个栈:保存左括号,遇到右括号时,就从栈中取栈顶元素判断是否匹配
- 出现FALSE的三种情况:
1️⃣取出来的左括号和右括号不匹配:“[” 和 “}”
2️⃣遍历之后,栈内还有左括号
3️⃣遍历时,遇到右括号但是栈里已经没有元素与其匹配
class Solution:
def isValid(self, s: str) -> bool:
stack = []
false = False
true = True
for x in s:
if x == '(' or x == '{' or x == '[':
stack.append(x)
else:
if len(stack) == 0:
return false
else:
temp = stack.pop()
if temp == '(' and x != ')':
return false
elif temp == '[' and x !=']':
return false
elif temp == '{' and x!='}':
return false
if len(stack) != 0:
return false
else:
return true
💡2个小trick💡
遇到右括号时,就从栈中取栈顶元素判断是否匹配,这个操作有点点麻烦:
✔️当开始遇到左括号时,在栈中直接保存匹配的右括号,然后取出栈顶元素只需要与遇到的右括号判断是否一致即可。
✔️匹配:可以将左括号和右括号的匹配写成一个字典,key就是左括号,value就是右括号😘
改进的Python代码:
# 方法二,使用字典
class Solution:
def isValid(self, s: str) -> bool:
stack = []
mapping = {
'(': ')',
'[': ']',
'{': '}'
}
for item in s:
if item in mapping.keys():
stack.append(mapping[item])
elif not stack or stack[-1] != item:
return False
else:
stack.pop()
return True if not stack else False
(4)LC1047删除字符串中的相邻重复项(easy)
题目描述
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。
输入:“abbaca”
输出:“ca”
解释:
例如,在 “abbaca” 中,我们可以删除 “bb” 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 “aaca”,其中又只有 “aa” 可以执行重复项删除操作,所以最后的字符串为 “ca”。
思路
创建一个栈: 存放遍历过的元素,当遍历当前的这个元素的时候,去栈里看一下我们是不是遍历过相同数值的相邻元素。

class Solution:
def removeDuplicates(self, s: str) -> str:
# 初始化栈,用来保存不是重复项的元素
stack = []
for x in s:
# 首先要判断栈里面有没有元素
if len(stack) == 0:
stack.append(x)
# 如果有元素,取出栈顶元素和准备放入的元素x对比
else:
temp = stack.pop()
# 如果栈顶元素和新放入的元素不同
if temp != x:
# 依次放入取出的元素和x
stack.append(temp)
stack.append(x)
# 如果相同,说明就是重复项,这两个元素都不需要放入栈中
res = "".join(x for x in stack)
return res
(5)逆波兰表达式求值(medium)
题目描述
给你一个字符串数组 tokens ,表示一个根据 逆波兰表示法 表示的算术表达式。
请你计算该表达式。返回一个表示表达式值的整数。
思路
和有效的括号以及删除相邻重复项一样,也是个对对碰问题,就是遇到摸一个元素判断是“加减乘除”符号就从栈里面取出两个元素进行运算,再把运算的结果放入栈中。

class Solution:
def evalRPN(self, tokens: List[str]) -> int:
# 创建一个字典从来存放加减乘除运算
mapping = {"+":add,"-":sub,"*":mul,"/":lambda x,y :int(x/y)}
# 创建stack,存储数据
stack =[]
for x in tokens:
# 判断是否是数字
if x not in mapping:
stack.append(int(x))
# 如果是操作符,要取出栈顶两个元素
else:
# 先取出的是在计算时后面的元素
x2 = stack.pop()
x1 = stack.pop()
res = mapping[x](x1,x2)
stack.append(res)
return stack.pop()
(6)LC239滑动窗口最大值(hard)
题目描述
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。

思路
我先写一下我的思路历程:
- 暴力法:遍历一遍的过程中每次从窗口中再找到最大的数值,这样很明显是 O ( n × k ) O(n × k) O(n×k)的算法。
- 之前有写过滑动窗口的操作模板:滑动窗口问题汇总(有解决模板)
滑动窗口就是为了减少两个窗口相交部分的重复计算 ,思考一下我觉得不能用到这个题中,因为这个题在每个窗口中是做取最大值的操作,每次不能不判断交叠部分,所以和暴力法的复杂度无异。 - 🔅正确方法:(自定义的)单调队列🔅
- 队列的作用:放进去窗口里的元素,然后随着窗口的移动,队列也一进一出,每次移动之后,队列告诉我们里面的最大值是什么
- 所以队列应该由三个函数组成:
1️⃣push(value):加入队列的元素,在加入时要判断从队列头部一直到队列尾部,是否队列中的值是大于value的,如果不是,就将队列中的元素移除(首部移除pop)保证队列是单调的,且最大值元素放在了队尾的位置
2️⃣pop(value):移除队列的元素,正常是应该移除掉出窗口的内个元素,但是内个元素有可能已经被push移除掉了,只有当出窗口的内个元素就是最大值元素的时候,才需要此时的pop进行删除
3️⃣maxValue():获取最大值元素,就是队尾元素

具体流程:

from collections import deque
class my_deque:
def __init__(self):
self.queue = deque()
def pop(self, value):
# 删除掉移动窗口后前面的值
# 但是,在push函数中已经把小于max的值删掉了,此时的队尾元素可能不是要删除的元素
# 只有当最大值就是要删除的元素的时候才会删除
if len(self.queue) != 0 and self.queue[0] == value:
self.queue.popleft()
def push(self,value):
# 当加入一个新元素的时候,要判断前面的元素是否小于value
# 如果小于value,那么前面的元素就没有存在的必要了,需要删除
# 这种从前到后删除的做法出现的问题:队尾元素可能比value大,但是中间的元素是没有value大的
# 这样就会使得队列不是单调队列 ,例子:[1,3,1,2,0,5]
# self.queue.append(value)
# while self.queue[0] < value:
# self.queue.popleft()
# 正确做法,从后往前删除:删除掉在队列中比value小的值,再把value加进去
while len(self.queue) != 0 and self.queue[-1] < value:
self.queue.pop()# 删除队首元素
self.queue.append(value)
def maxValue(self):
return self.queue[0]
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
queue_s = my_deque()
res = []
for i in range(k):
queue_s.push(nums[i])
res.append(queue_s.maxValue())
for i in range(k,len(nums)):
queue_s.pop(nums[i-k])
queue_s.push(nums[i])
res.append(queue_s.maxValue())
return res
(7)LC347前k个高频元素(medium)
题目描述
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
思路
- 要统计元素出现频率:哈希表
- 对频率排序:sort函数 time complexity = O ( n l o g n ) O(nlogn) O(nlogn)最大堆 time complexity = O ( n ) O(n) O(n)
- 找出前K个高频元素
# hashmap + heap
import heapq
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
mapping = {}
for num in nums:
if num not in mapping.keys():·
mapping[num] = 1
else:
mapping[num] += 1
maxheap = []
heapq.heapify(maxheap)
for num,freq in mapping.items():
heapq.heappush(maxheap,(freq*(-1),num))
max_k = []
for freq1,num1 in maxheap:
if k > 0:
max_k.append(num1)
k -= 1
else:
break
return max_k
二叉树篇
0、基础
深度和高度

满二叉树和完全二叉树
满二叉树:除了根节点,每个节点都有两个孩子
完全二叉树:除了最底下的右侧节点可能没填满外,其余每层节点数都达到最大值。
平衡二叉树
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1
二叉搜索树和平衡二叉搜索树
二叉搜索树:左节点小于根节点,有节点大于根节点
平衡二叉搜索树:在二叉搜索树的基础上,左右两个子树的高度差的不超过1
二叉树节点定义
class TreeNode:
def __init__(self, val, left = None, right = None):
self.left = left
self.right = right
self.val = val
前中后序遍历
- 前序遍历:中左右
- 中序遍历:左中右
- 后序遍历:左右中

递归遍历
前序递归遍历—144. 二叉树的前序遍历
题目链接:添加链接描述

class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
def dfs(node,res):
if node == None:
return
# 前序:中左右
res.append(node.val)
dfs(node.left,res)
dfs(node.right,res)
return res
res = dfs(root,[])
return res
迭代遍历
前序遍历是中左右,每次先处理的是中间节点,再处理左节点,最后右节点
设计一个栈:先将根节点放入栈中,然后将右孩子加入栈,再加入左孩子
Q:为什么要先加入 右孩子,再加入左孩子呢?
A:因为这样出栈的时候才是中左右的顺序
thon
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
# 前序遍历:中左右
# 迭代法:使用栈
if not root:
return []
stack = []
vec = []
# 先把根节点压入栈中
stack.append(root)
while len(stack) != 0:
# 先弹出栈首
node = stack.pop()
# 把栈首弹出节点的val记录到vec中
vec.append(node.val)
# 然后压入此时栈首的左右孩子
# 要先压入右孩子,才能先弹出左孩子
if node.right:
stack.append(node.right)
if node.left:
stack.append(node.left)
return vec
层序遍历


116. 填充每个节点的下一个右侧节点指针
1、题目描述
输入:root = [1,2,3,4,5,6,7]
输出:[1,#,2,3,#,4,5,6,7,#]
解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。序列化的输出按层序遍历排列,同一层节点由 next 指针连接,‘#’ 标志着每一层的结束。
2、思路
层序遍历
3、code
"""
# Definition for a Node.
class Node:
def __init__(self, val: int = 0, left: 'Node' = None, right: 'Node' = None, next: 'Node' = None):
self.val = val
self.left = left
self.right = right
self.next = next
"""
from collections import deque
class Solution:
def connect(self, root: 'Optional[Node]') -> 'Optional[Node]':
queue = deque()
if root != None:
queue.append(root)
else:
return root
while len(queue)!=0:
size = len(queue)
while size != 0:
node = queue.popleft()
if size == 1:
node.next = None
else:
node_next = queue[0] # 查看队列出队元素
node.next = node_next
if node.left is not None:
queue.append(node.left)
if node.right is not None:
queue.append(node.right)
size -= 1
return root
226. 翻转二叉树
题目链接:link
1、题目描述
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
示例 1:
输入:root = [4,2,7,1,3,6,9]
输出:[4,7,2,9,6,3,1]
2、思路
😺翻转就是交换左右孩子,那就可以在遍历的过程中进行交换
🌟前序(中左右)和后序都是可以的
❌中序不可以,why?因为中序遍历会把某些节点的左右孩子翻转了两次!
3、code(后序递归)
class Solution:
def invertTree(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
if root is None:
return root
# 思路:后续遍历,在中的时候翻转
def dfs(node):
if node is None:
return
dfs(node.left)
dfs(node.right)
node.left, node.right = node.right, node.left
return node
new_root = dfs(root)
return new_root
101. 对称二叉树
题目链接:link
1、题目描述
给你一个二叉树的根节点
root, 检查它是否轴对称。
示例 1:
输入:root = [1,2,2,3,4,4,3]
输出:true

2、思路
❌最开始的错误思路:后续遍历,把得到的数组出去最后一个看看是否是对称的,但是这样的话会判断出错这样的情况:
✅判断节点的左右子树是否能相互翻转


3、code
class Solution:
# 判断对称二叉树:判断根节点的左右树是否是可以翻转的->也就是判断两颗数的外侧和内侧的节点值是否是相等的
# 左树的外侧是左孩子,右数的外侧是右孩子
# 左树的内侧是右孩子,右树的内侧是左孩子
def compare(self, left, right):
# 首先要判断左右孩子是否是空节点的情况也就是终止条件
if left is None and right is not None: # 左孩子是空的,右孩子不是空的
return False
elif left is not None and right is None: # 左孩子不是空的,右孩子是空的
return False
elif left is None and right is None: # 如果左右孩子都为空,说明是对称的
return True
elif left.val != right.val: # 此时左右孩子都不为空,且值不相等
return False
else: # 还剩一个情况:左右孩子不为空,且值相等
# 下一步比较这个节点的左右孩子的外侧和内侧节点
flag1 = self.compare(left.left, right.right)
flag2 = self.compare(left.right, right.left)
result = flag1 and flag2
return result
def isSymmetric(self, root: Optional[TreeNode]) -> bool:
return self.compare(root.left, root.right)
104. 二叉树的最大深度
题目链接:link
1、题目描述
给定一个二叉树 root ,返回其最大深度。
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
💜深度:节点到根节点的节点数
💚高度:节点到叶子节点的节点数
2、思路
🟪🟪🟪树的最大深度就是根节点的最大高度🟪🟪🟪
此时,题目就变成了求根节点的最大高度,那就是
m
a
x
(
左子树的高度,右子树的高度
)
+
1
max(左子树的高度,右子树的高度)+1
max(左子树的高度,右子树的高度)+1
这样的话就需要先知道左右子树的高度➡️ 后序遍历(左右中)
3、code
class Solution:
# 计算节点的高度,要统计左右两个子树的高度,后序,左右中
def dfs(self,node):
if node is None:
return 0
left_height = self.dfs(node.left)
right_height = self.dfs(node.right)
height = max(left_height,right_height)+1
return height
def maxDepth(self, root: Optional[TreeNode]) -> int:
# 根节点的高度就是最大深度
return self.dfs(root)
111. 二叉树的最小深度
题目链接:link
1、题目描述
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明:叶子节点是指没有子节点的节点。
2、思路
求最大高度:树的最大深度就是根节点的最大高度
此时,题目就变成了求根节点的最大高度,那就是 m a x ( 左子树的高度,右子树的高度 ) + 1 max(左子树的高度,右子树的高度)+1 max(左子树的高度,右子树的高度)+1
那求最小高度就应该是:
m
i
n
(
左子树的高度,右子树的高度
)
+
1
min(左子树的高度,右子树的高度)+1
min(左子树的高度,右子树的高度)+1
😡要单独考虑左子树或者右子树高度为0的情况

3、code
class Solution:
def minDepth(self, root: Optional[TreeNode]) -> int:
# 根节点的最小高度就是最小深度
return self.dfs(root)
# 计算节点的高度,要统计左右两个子树的高度,后序,左右中
def dfs(self,node):
if node is None:
return 0
left_height = self.dfs(node.left)
right_height = self.dfs(node.right)
if left_height ==0 and right_height!=0:
height = right_height + 1
elif left_height != 0 and right_height == 0:
height = left_height + 1
else:
height = min(left_height,right_height)+1
return height
回溯篇
77. 组合
给定两个整数 n 和 k,返回 1 … n 中所有可能的 k 个数的组合。
示例: 输入: n = 4, k = 2 输出: [ [2,4], [3,4], [2,3], [1,2], [1,3], [1,4], ]

from typing import List
class Solution:
def __init__(self):
self.path = [] # 存放路径
self.result = [] # 存放符合条件(k个数)的结果的二维数组
def backtracking(self, n, k, startindex): # 参数n:树的宽度、参数k:遍历的深度、startindex:记录本层递归中集合从哪里开始遍历
# 终止条件:到达递归深度:叶子节点:path已经收集到了k个元素
if len(self.path) == k:
self.result.append(self.path[:])
return
# 单层逻辑:for从starindex开始遍历,将结果加入path中,然后递归下一层,一直到找到叶子节点,然后返回答案,并撤销处理过程
for i in range(startindex, n+1):
self.path.append(i)
self.backtracking(n, k, i+1)
self.path.pop()
# 正常情况每一层[i,n]
# 但是要考虑到剩余元素不满足k的情况,n = 4 ,k = 4 ,i = 2, 剩余元素个数为n-i+1 = 3,现在记录的个数为len(path)
# n - i +1 + len(path)>= k -> i <= n - k + 1 +len(path)
# i \in [startindex,n - k + 1 +len(path)]
for i in range(startindex, n - (k - len(self.path)) + 2):
self.path.append(i)
self.backtracking(n,k,i+1)
self.path.pop()
def combine(self, n: int, k: int) -> List[List[int]]:
self.backtracking(n, k, 1)
return self.result
🌟在for i in range(startindex, n+1):这里面的startindex保证的是树层去重(防止出现[1,2]和[2,1]的情况,组合问题特性 )
🌟在 self.backtracking(n, k, i+1):这里面的i+1保证的是树枝去重(防止出现[1,1]的情况,也就是同一个元素取了两次,这是一个元素只能出现一次的特性 )
😙剪枝优化:当目前剩余可以选择的元素不够k的时候就没必要继续了,n - i +1 + len(path)>= k -> i <= n - k + 1 +len(path)

❤️为什么是path[:]不是path?
- 浅拷贝vs引用
- path[:] 是浅拷贝,之后对 self.path 的修改不会影响已经存储在 self.res 中的结果
- path是引用,如果 self.path 在之后的递归中被修改,那么 self.res 中的结果也会被修改,因为它们指向的是同一个列表对象。
216.组合总和III
找出所有相加之和为 n 的 k 个数的组合。组合中只允许含有 1 - 9 的正整数,并且每种组合中不存在重复的数字。
说明:
- 所有数字都是正整数。
- 解集不能包含重复的组合。

class Solution:
def __init__(self):
self.res = []
self.path = []
def backtracking(self, n , k, sum, startindex):
# 剪枝:当前sum已经超过n的节点就不需要继续遍历了
if sum > n:
return
# 终止条件:path的长度为k
if len(self.path) == k:
if sum == n: # 如果此时计算的path路径上的值的和为n,就是一种结果组合
self.res.append(self.path[:])
return
# for循环横向遍历,不能有重复的数
for i in range(startindex, 10):
sum += i
self.path.append(i)
self.backtracking(n, k, sum, i+1)
sum -= i
self.path.pop()
def combinationSum3(self, k: int, n: int) -> List[List[int]]:
self.backtracking(n,k,0,1)
return self.res
🌟组合问题:for i in range(startindex,n)
🌟无重复元素:backtracking(n,k,i+1)
😙剪枝优化:
1️⃣ 当前总和已经超过n:if sum > n:
2️⃣ 当前剩余元素的数量加上已经记录的元素数量要保证超过k个:9-i+1 + len(path) >=k ➡️ i<=9 - (k - path.size()) + 1
17. 电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
输入:digits = “23”
输出:[“ad”,“ae”,“af”,“bd”,“be”,“bf”,“cd”,“ce”,“cf”]
class Solution:
def __init__(self):
self.s = ""
self.result = []
self.lettermap = [
"", # 0
"", # 1
"abc", # 2
"def", # 3
"ghi", # 4
"jkl", # 5
"mno", # 6
"pqrs", # 7
"tuv", # 8
"wxyz" # 9
]
def backtracking(self, digits, index):
if index == len(digits):
self.result.append(self.s)
return
# 把当前处理的字符“2”变成数字2
digit = int(digits[index])
stringletter = self.lettermap[digit]
for letter in stringletter:
self.s += letter
self.backtracking(digits, index + 1)
self.s = self.s[:-1]
def letterCombinations(self, digits: str) -> List[str]:
if not digits:
return []
self.backtracking(digits, 0)
return self.result
39. 组合总和:
给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的数字可以无限制重复被选取。
说明:
所有数字(包括 target)都是正整数。
解集不能包含重复的组合。
class Solution:
def __init__(self):
self.path = []
self.res = []
self.sum = 0
def backtracking(self,candidates,target,startindex):
if self.sum > target:
return
if self.sum == target:
self.res.append(self.path[:])
return
for i in range(startindex,len(candidates)):
self.sum += candidates[i]
self.path.append(candidates[i])
self.backtracking(candidates,target,i)
self.sum -= candidates[i]
self.path.pop()
def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:
self.backtracking(candidates,target,0)
return self.res
🌟组合问题:for i in range(startindex,n)
🌟可以重复元素:backtracking(n,k,i)
40.组合总和II
给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用一次。
说明: 所有数字(包括目标数)都是正整数。解集不能包含重复的组合。
🔴数组中含有重复元素
🔴每个元素只能用一次➡️组合中同一元素不能重复
🔴组合问题
class Solution:
def backtracking(self, candidates, target, total, startIndex, used, path, result):
if total == target:
result.append(path[:])
return
for i in range(startIndex, len(candidates)):
# 对于相同的数字,只选择第一个未被使用的数字,跳过其他相同数字
if i > startIndex and candidates[i] == candidates[i - 1] and not used[i - 1]:
continue
if total + candidates[i] > target:
break
total += candidates[i]
path.append(candidates[i])
used[i] = True
self.backtracking(candidates, target, total, i + 1, used, path, result)
used[i] = False
total -= candidates[i]
path.pop()
def combinationSum2(self, candidates, target):
used = [False] * len(candidates)
result = []
candidates.sort()
self.backtracking(candidates, target, 0, 0, used, [], result)
return result
🌟组合问题:for i in range(startindex,n)
🌟无重复元素:backtracking(n,k,i+1)
☀️因为初始数组[1,1,2,3]存在重复元素,有可能出现这样的情况,[1(0),2,3]和[1(1),2,3]、虽然满足无重复元素(原数组的不同元素),但是生成的新组合还是重复了,so,需要删除这种重复
if i > 0 and candidates[i] == candidates[i - 1] and used[i - 1] == false:
分割回文串(t)
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。
返回 s 所有可能的分割方案。
示例: 输入: “aab” 输出: [ [“aa”,“b”], [“a”,“a”,“b”] ]
class Solution:
def partition(self, s: str) -> List[List[str]]:
'''
递归用于纵向遍历
for循环用于横向遍历
当切割线迭代至字符串末尾,说明找到一种方法
类似组合问题,为了不重复切割同一位置,需要start_index来做标记下一轮递归的起始位置(切割线)
'''
result = []
self.backtracking(s, 0, [], result)
return result
def backtracking(self, s, start_index, path, result ):
# Base Case
if start_index == len(s):
result.append(path[:])
return
# 单层递归逻辑
for i in range(start_index, len(s)):
# 此次比其他组合题目多了一步判断:
# 判断被截取的这一段子串([start_index, i])是否为回文串
if self.is_palindrome(s, start_index, i):
path.append(s[start_index:i+1])
self.backtracking(s, i+1, path, result) # 递归纵向遍历:从下一处进行切割,判断其余是否仍为回文串
path.pop() # 回溯
def is_palindrome(self, s: str, start: int, end: int) -> bool:
i: int = start
j: int = end
while i < j:
if s[i] != s[j]:
return False
i += 1
j -= 1
return True
93.复原IP地址(t)
给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。
有效的 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 ‘.’ 分隔。
例如:“0.1.2.201” 和 “192.168.1.1” 是 有效的 IP 地址,但是 “0.011.255.245”、“192.168.1.312” 和 “192.168@1.1” 是 无效的 IP 地址。
示例 1:
输入:s = “25525511135”
输出:[“255.255.11.135”,“255.255.111.35”]
示例 2:
输入:s = “0000”
输出:[“0.0.0.0”]
示例 3:
输入:s = “1111”
输出:[“1.1.1.1”]
示例 4:
输入:s = “010010”
输出:[“0.10.0.10”,“0.100.1.0”]
示例 5:
输入:s = “101023”
输出:[“1.0.10.23”,“1.0.102.3”,“10.1.0.23”,“10.10.2.3”,“101.0.2.3”]
提示:
0 <= s.length <= 3000
s 仅由数字组成
class Solution:
def restoreIpAddresses(self, s: str) -> List[str]:
result = []
self.backtracking(s, 0, 0, "", result)
return result
def backtracking(self, s, start_index, point_num, current, result):
if point_num == 3: # 逗点数量为3时,分隔结束
if self.is_valid(s, start_index, len(s) - 1): # 判断第四段子字符串是否合法
current += s[start_index:] # 添加最后一段子字符串
result.append(current)
return
for i in range(start_index, len(s)):
if self.is_valid(s, start_index, i): # 判断 [start_index, i] 这个区间的子串是否合法
sub = s[start_index:i + 1]
self.backtracking(s, i + 1, point_num + 1, current + sub + '.', result)
else:
break
def is_valid(self, s, start, end):
if start > end:
return False
if s[start] == '0' and start != end: # 0开头的数字不合法
return False
num = 0
for i in range(start, end + 1):
if not s[i].isdigit(): # 遇到非数字字符不合法
return False
num = num * 10 + int(s[i])
if num > 255: # 如果大于255了不合法
return False
return True
90.子集II(t)
给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
示例:
输入: [1,2,2]
输出: [ [2], [1], [1,2,2], [2,2], [1,2], [] ]
class Solution:
def subsetsWithDup(self, nums):
result = []
path = []
used = [False] * len(nums)
nums.sort() # 去重需要排序
self.backtracking(nums, 0, used, path, result)
return result
def backtracking(self, nums, startIndex, used, path, result):
result.append(path[:]) # 收集子集
for i in range(startIndex, len(nums)):
# used[i - 1] == True,说明同一树枝 nums[i - 1] 使用过
# used[i - 1] == False,说明同一树层 nums[i - 1] 使用过
# 而我们要对同一树层使用过的元素进行跳过
if i > 0 and nums[i] == nums[i - 1] and not used[i - 1]:
continue
path.append(nums[i])
used[i] = True
self.backtracking(nums, i + 1, used, path, result)
used[i] = False
path.pop()
491.递增子序列(t)
给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2。
示例:
输入: [4, 6, 7, 7]
输出: [[4, 6], [4, 7], [4, 6, 7], [4, 6, 7, 7], [6, 7], [6, 7, 7], [7,7], [4,7,7]]
说明:
给定数组的长度不会超过15。
数组中的整数范围是 [-100,100]。
给定数组中可能包含重复数字,相等的数字应该被视为递增的一种情况。
class Solution:
def findSubsequences(self, nums):
result = []
path = []
self.backtracking(nums, 0, path, result)
return result
def backtracking(self, nums, startIndex, path, result):
if len(path) > 1:
result.append(path[:]) # 注意要使用切片将当前路径的副本加入结果集
# 注意这里不要加return,要取树上的节点
uset = set() # 使用集合对本层元素进行去重
for i in range(startIndex, len(nums)):
if (path and nums[i] < path[-1]) or nums[i] in uset:
continue
uset.add(nums[i]) # 记录这个元素在本层用过了,本层后面不能再用了
path.append(nums[i])
self.backtracking(nums, i + 1, path, result)
path.pop()
46.全排列
给定一个 没有重复 数字的序列,返回其所有可能的全排列。
示例:
输入: [1,2,3]
输出: [ [1,2,3], [1,3,2], [2,1,3], [2,3,1], [3,1,2], [3,2,1] ]
class Solution:
def permute(self, nums):
result = []
self.backtracking(nums, [], [False] * len(nums), result)
return result
def backtracking(self, nums, path, used, result):
if len(path) == len(nums):
result.append(path[:])
return
for i in range(len(nums)):
if used[i]:
continue
used[i] = True
path.append(nums[i])
self.backtracking(nums, path, used, result)
path.pop()
used[i] = False
47.全排列 II
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
输入:nums = [1,1,2]
输出: [[1,1,2], [1,2,1], [2,1,1]]
示例 2:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
class Solution:
def permuteUnique(self, nums):
nums.sort() # 排序
result = []
self.backtracking(nums, [], [False] * len(nums), result)
return result
def backtracking(self, nums, path, used, result):
if len(path) == len(nums):
result.append(path[:])
return
for i in range(len(nums)):
if (i > 0 and nums[i] == nums[i - 1] and not used[i - 1]) or used[i]:
continue
used[i] = True
path.append(nums[i])
self.backtracking(nums, path, used, result)
path.pop()
used[i] = False
51. N皇后(t)
n 皇后问题 研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案。
每一种解法包含一个不同的 n 皇后问题 的棋子放置方案,该方案中 ‘Q’ 和 ‘.’ 分别代表了皇后和空位。
示例 1:

输入:n = 4
输出:[[“.Q…”,“…Q”,“Q…”,“…Q.”],[“…Q.”,“Q…”,“…Q”,“.Q…”]]
class Solution:
def solveNQueens(self, n: int) -> List[List[str]]:
result = [] # 存储最终结果的二维字符串数组
chessboard = ['.' * n for _ in range(n)] # 初始化棋盘
self.backtracking(n, 0, chessboard, result) # 回溯求解
return [[''.join(row) for row in solution] for solution in result] # 返回结果集
def backtracking(self, n: int, row: int, chessboard: List[str], result: List[List[str]]) -> None:
if row == n:
result.append(chessboard[:]) # 棋盘填满,将当前解加入结果集
return
for col in range(n):
if self.isValid(row, col, chessboard):
chessboard[row] = chessboard[row][:col] + 'Q' + chessboard[row][col+1:] # 放置皇后
self.backtracking(n, row + 1, chessboard, result) # 递归到下一行
chessboard[row] = chessboard[row][:col] + '.' + chessboard[row][col+1:] # 回溯,撤销当前位置的皇后
def isValid(self, row: int, col: int, chessboard: List[str]) -> bool:
# 检查列
for i in range(row):
if chessboard[i][col] == 'Q':
return False # 当前列已经存在皇后,不合法
# 检查 45 度角是否有皇后
i, j = row - 1, col - 1
while i >= 0 and j >= 0:
if chessboard[i][j] == 'Q':
return False # 左上方向已经存在皇后,不合法
i -= 1
j -= 1
# 检查 135 度角是否有皇后
i, j = row - 1, col + 1
while i >= 0 and j < len(chessboard):
if chessboard[i][j] == 'Q':
return False # 右上方向已经存在皇后,不合法
i -= 1
j += 1
return True # 当前位置合法
















 2235
2235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











