






文章目录
前言
本文是浙江大学CAD&CG国家重点实验室,周晓巍教授的《三位人体姿态估计年度进展综述》的文字版。视频和相关资料地址在参考资料部分。
问题定义
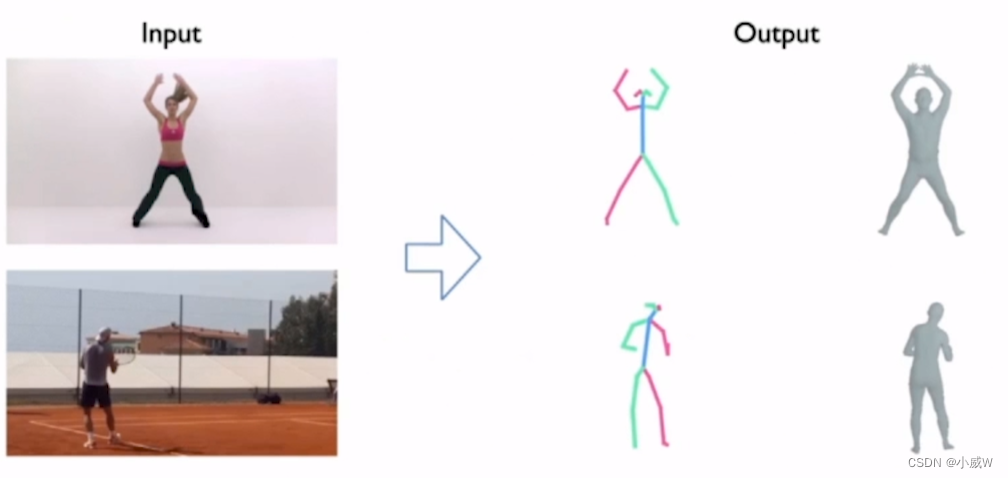
问题的定义:输入一张RGB的图像,恢复图像中人体的三维姿态。
目前常用的三维姿态的表示方式有两种。
一种是骨骼关节点连接成的三维骨架,这样的表示方式需要获得各个关节点在三维空间中的位置。
另一种是参数化的几何模型,如SMPL。通常由一组姿态参数控制它的形变,需要估计姿态的参数和外形的参数。
基本解法
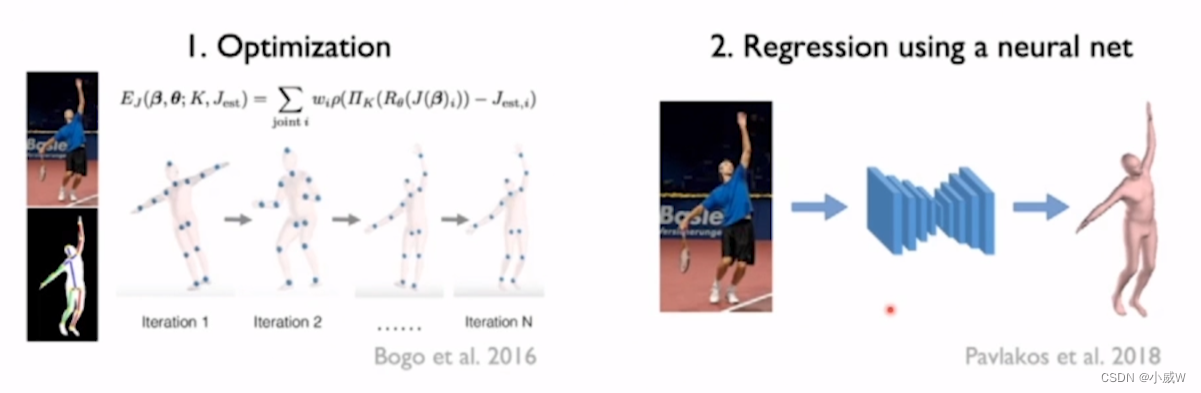
- Optimization
通过变化三维人体时的参数,使模型在图像平面里的投影跟图像的特征对齐,比如二维的关键点的轮廓。
局限:需要一个比较好的初始化,优化的过程也比较慢,比较容易陷入局部最优。 - Regression using a neural net
基于深度学习,从输入的图像回归姿态的参数,比较快,使用端到端的学习方式可以更好地利用图像的信息。
以上两种解法也可以结合在一起,利用网络预测出一个比较好的初始化,进一步利用图像的特征对姿态进行优化。
最近的动态趋势
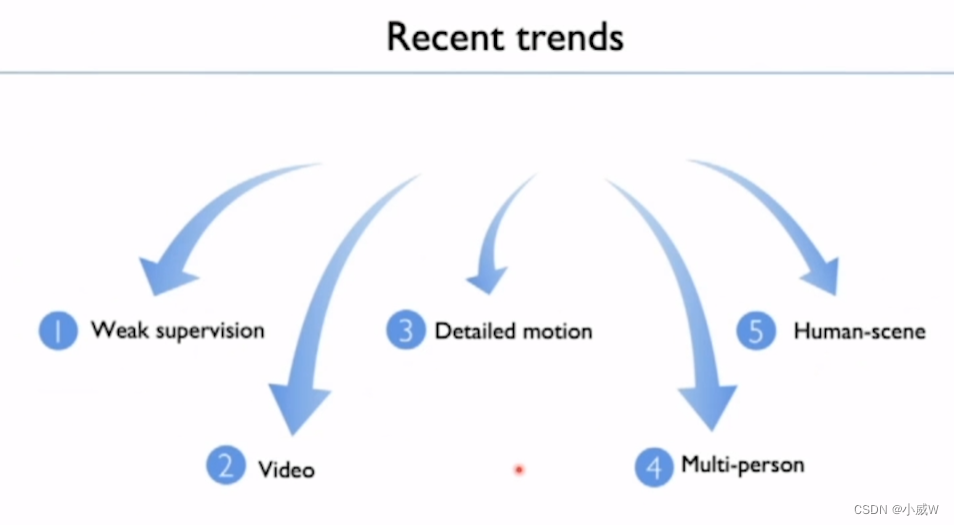
Weak supervision(弱监督学习)
Q:为什么需要弱监督学习?
A:因为不可能人工地标注。现在常用的数据来源于运动捕捉系统

Using optimized results
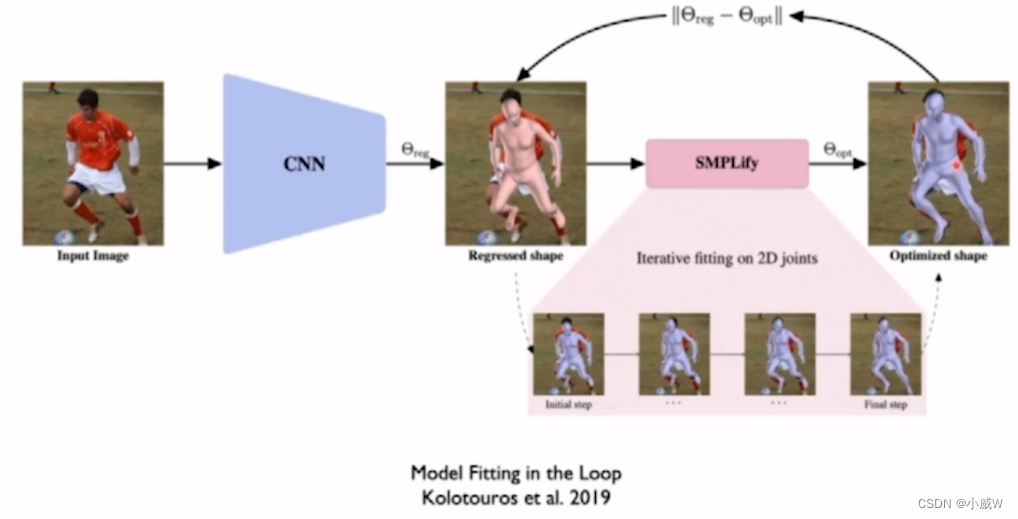
Using unpaired data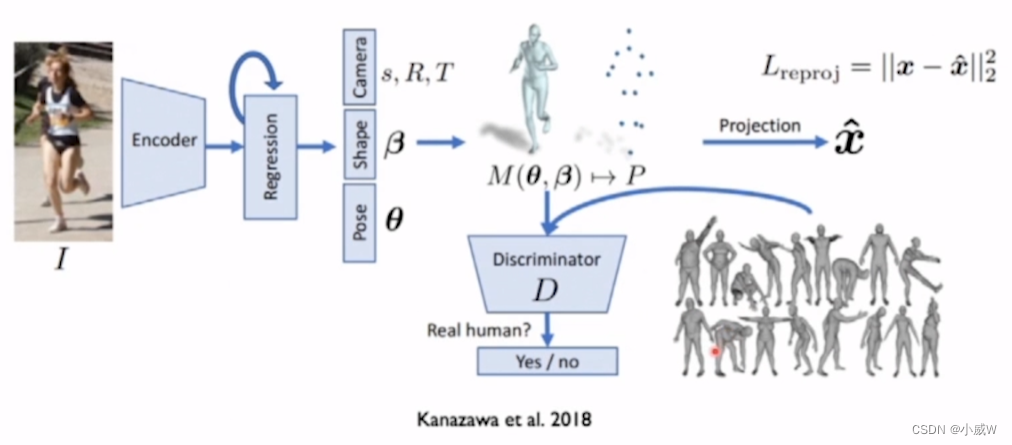
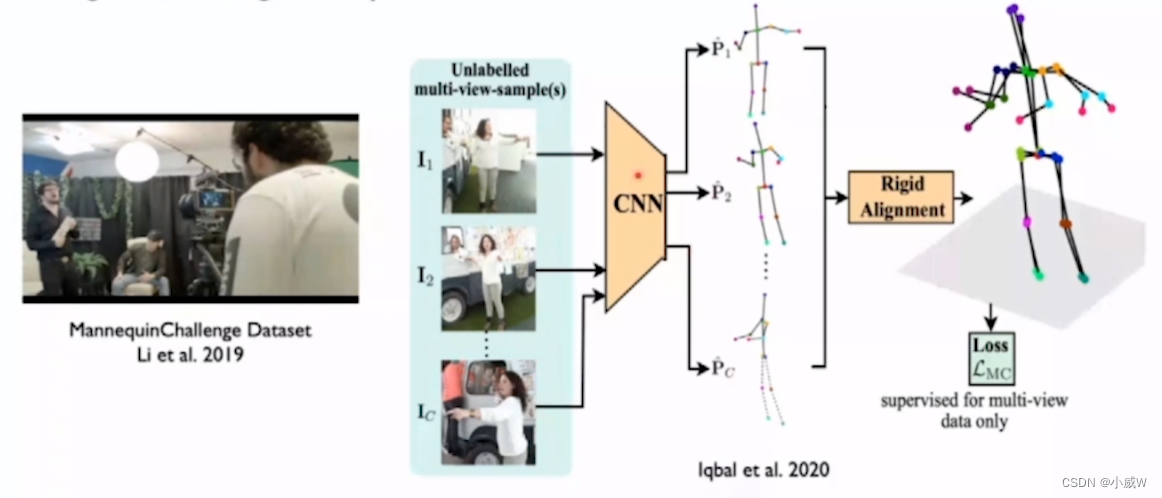
Using multi-view geometry
From image to video(视频中的姿态估计)

Temporal encoder
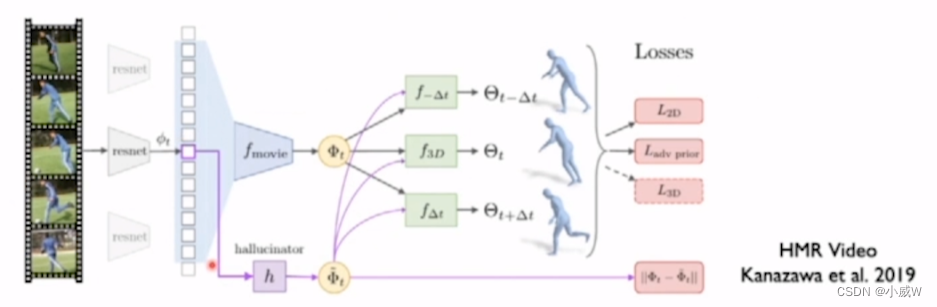
Motion discriminator

Total capture of detailed motion(对全身的精细的运动捕捉)


Multiple people(多人的3D姿态估计)
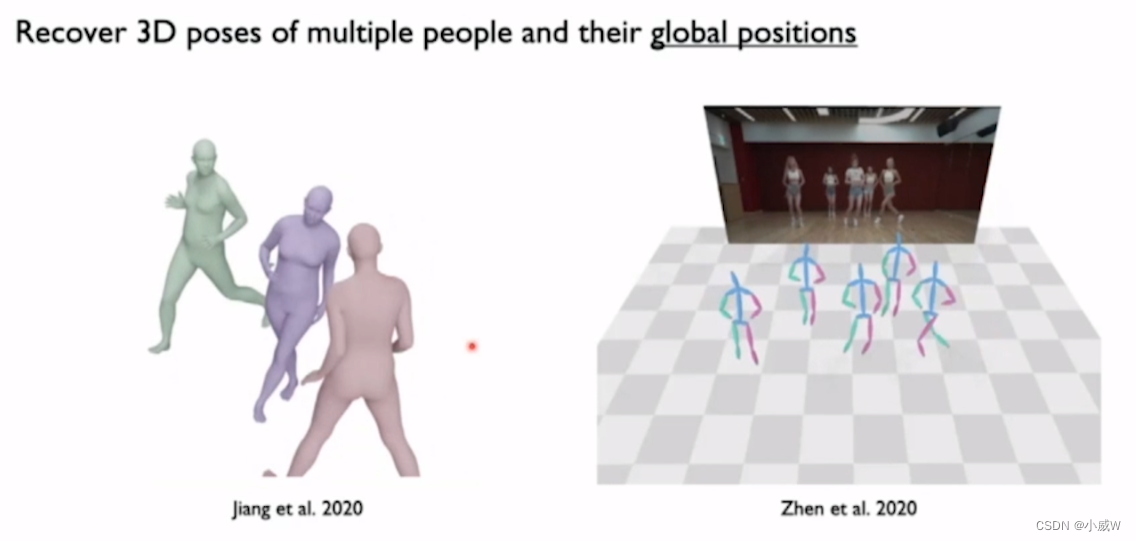
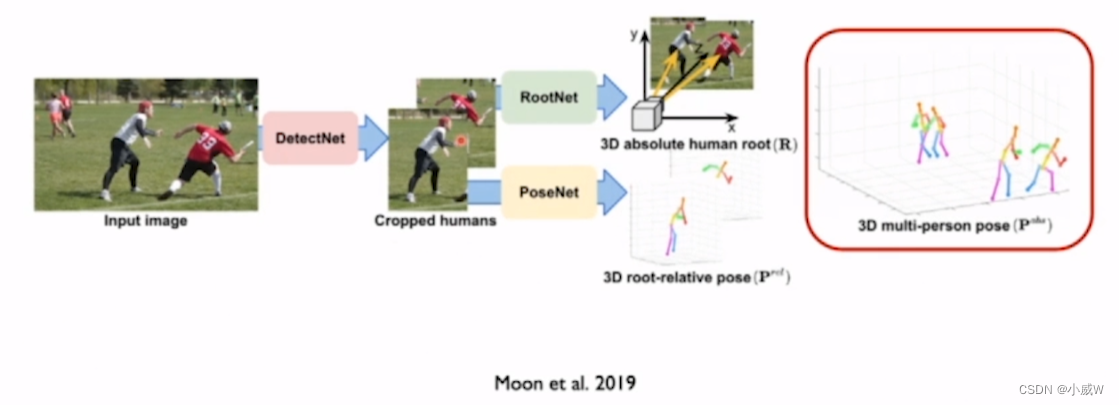
Top-down framework
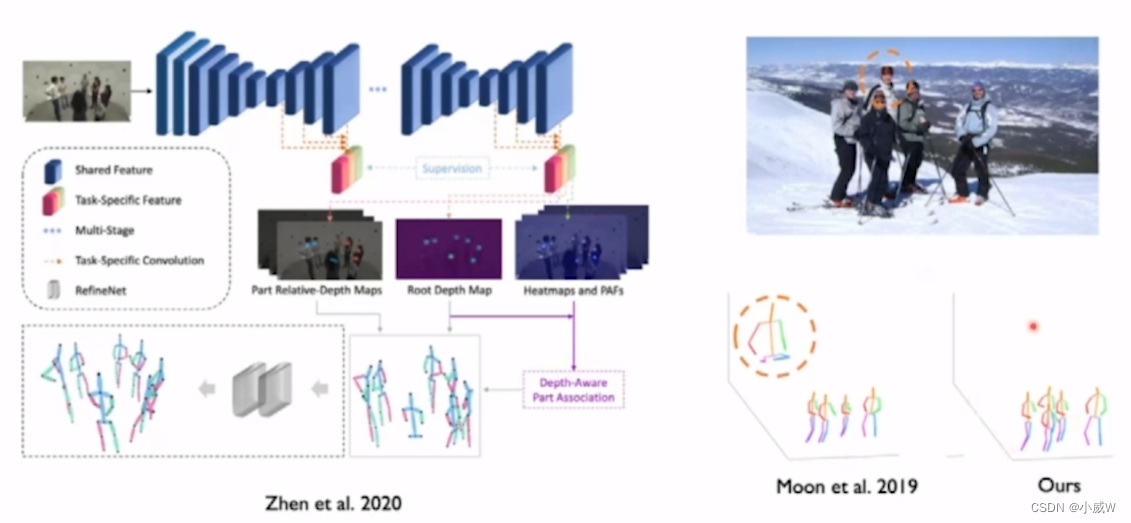
Bottom-up framework
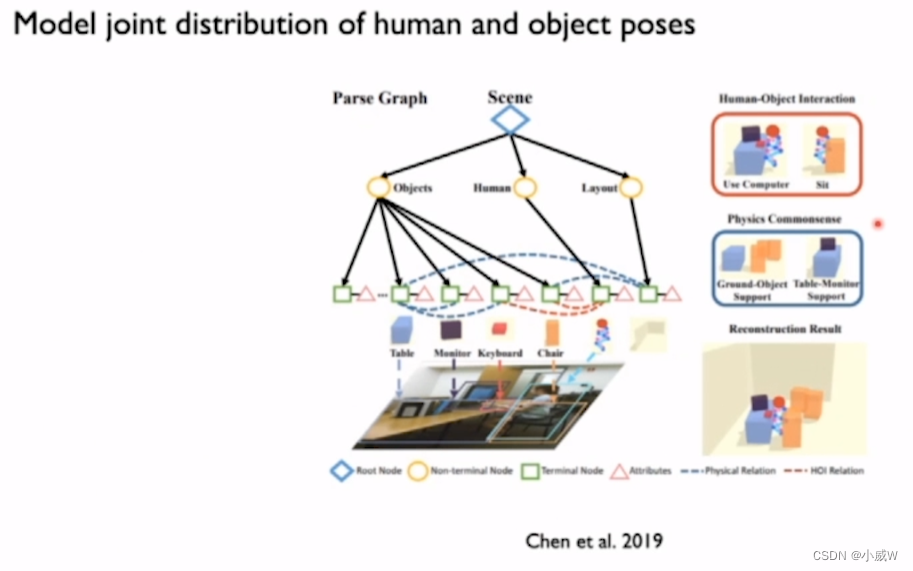
Human-scene interaction(人体与场景的交互)

Discussion

如何收集更多训练数据?
Markerless motion capture
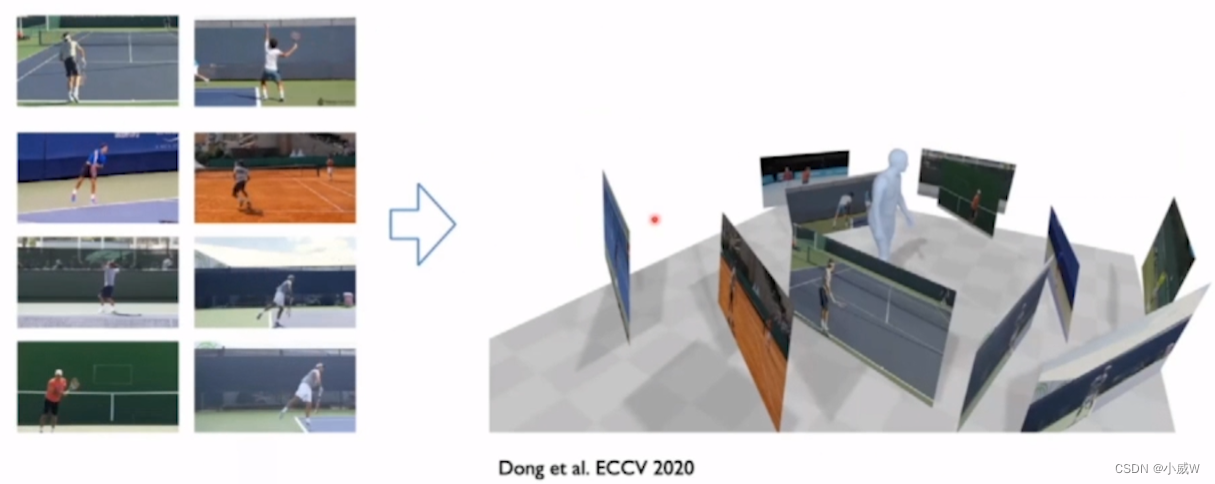
Motion capture from Internet videos
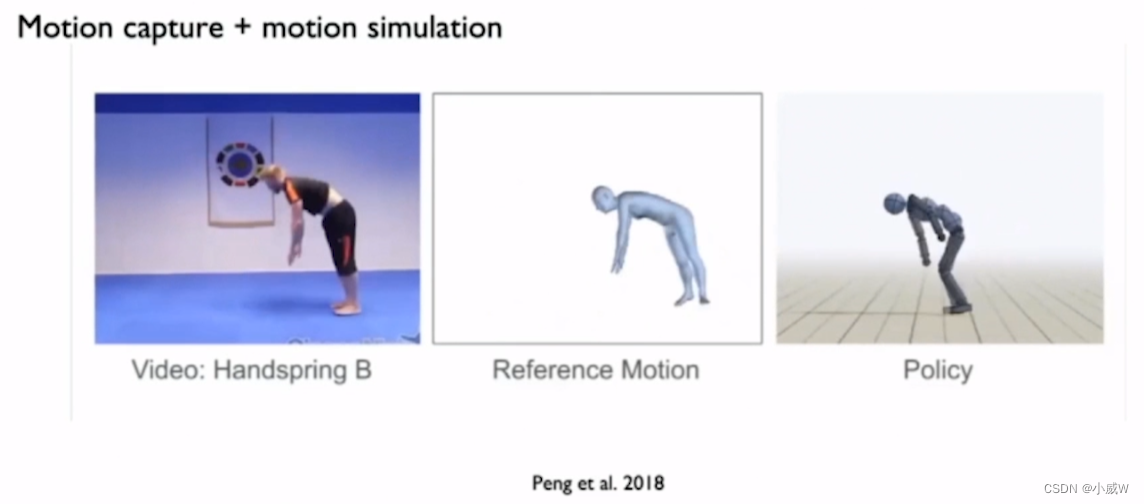
Computer graphics


















 648
648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











