







文章目录
论文基本信息
《Energy-Efficient Joint Computation Offloading and Resource Allocation Strategy for ISAC-Aided 6G V2X Networks》
《isac辅助6G V2X网络节能联合计算卸载与资源分配策略》
IEEE TRANSACTIONS ON GREEN COMMUNICATIONS AND NETWORKING, VOL. 7, NO. 1, MARCH 2023 IEEE Transactions on Green Communications and Networking期刊基本信息 中科院3区
作者:重庆邮电大学
本文做的是什么?——
具有长期延迟和能源消耗约束的排队延迟的最小化问题。(联合计算卸载决策和资源分配策略来提高融合计算任务的能量效率)
chatPDF:(本文的主要目标是设计一种节能的isac辅助V2X网络的联合计算卸载和资源分配策略,同时考虑系统的能耗需求和有针对性的策略设计。该策略的目标是在满足长期延迟和能耗约束的同时,最小化数据融合计算任务的排队延迟,从而提高系统的能效。)
Q:为什么最小化数据融合计算任务的排队延迟就能提高系统的能效?
A:当计算任务在队列中等待时,它会消耗能量,但不会对系统的整体性能做出贡献。通过最小化排队延迟,我们可以减少计算任务在队列中等待的时间,从而降低系统的能耗,提高系统的能源效率。
摘要
首先引入了一种用于协作感知的数据融合架构,以支持融合来自无线基础设施和车辆的大量感知数据。然后,针对数据融合计算任务,提出了一个具有长期延迟和能耗约束的排队延迟最小化问题。
将延迟和能量约束转化为队列稳定性问题。最后,提出了一种联合计算卸载和资源分配(JCORA)方案,以获得最优的计算卸载和资源分配决策,实现了任务延迟和能量消耗之间的平衡。
1.引言
贡献:
- 介绍了一种协同感知的数据融合架构,以支持在ISAC辅助的V2X网络中的多源感知数据融合。为了满足融合计算任务快速增加的体积和严格的延迟要求的挑战,将MEC技术应用于ISAC辅助(Integrated Sensing and Communications、ISAC:集成感知和通信技术)的V2X网络中,在短距离内提供大量的计算资源。所提出的融合架构是基于ISAC辅助的V2X网络设计的。
- 数据融合计算任务的消耗约束。Lyapunov优化方法进一步重新表述。本文提出了一个具有长时延和能量的排队时延最小化问题,将该问题综合考虑时延和能量效率的联合优化问题。该方法将延迟和能量约束转化为队列稳定性问题。从而降低了计算复杂度,提高了系统的稳定性。
- 本文提出了一种联合计算卸载和资源分配(JCORA)方案,以提高融合计算任务的能量效率,同时保证任务延迟的性能。该方案包括AKTC算法、MDP模型和DCORA算法。与其他基线方案相比,该方案在最小化能耗和降低延迟方面具有优势。
2.相关工作
3.系统模型
A. Network Model 网络模型
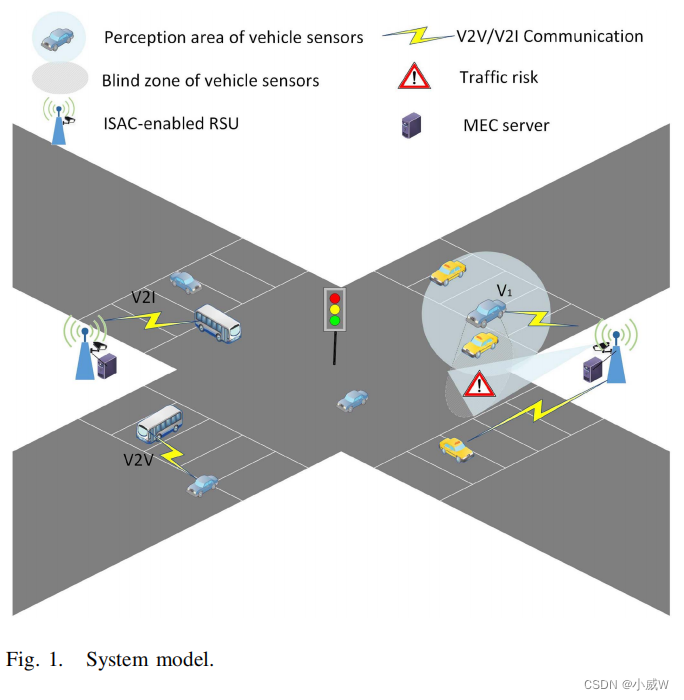
考虑了由 M M M 表示的 支持ISAC 的RSUs和 I I I 车辆组成的城市交叉口场景。
I 车辆合集,J 卸载可用车辆合集。
R m R_m Rm 表示第 m 个 RSU,其 MEC 服务器的最大计算能力定义为 f m m a x f_m^{max} fmmax
总结:
讲了一下场景,场景中有哪些元素,用什么符号表示这些元素。
B. Data Fusion Architecture of Cooperative Perception 协同感知的数据融合架构
基于上述系统模型,同时从ISAC辅助RSU和车辆侧采集大量和多源感知数据。
来自rsu和车辆的大量多源感知数据不能直接堆叠使用,必须通过数据融合过程进行处理。因此,车辆侧的融合过程将生成计算任务 ψ i ( t ) ψ_i (t) ψi(t)。
由于RUS侧的传感器模块具有更广泛的感知范围,因此 RUS 侧的感知数据量大于车辆侧产生的感知数据量。(一方面,直接将大量的原始数据从rsu传输到车辆上来执行融合任务,将对通信带宽和计算资源构成极大的挑战。另一方面,RSU上的MEC服务器可以为其传感器设备提供计算资源。因此,这些传感器装置可以首先估计原始数据的局部参数,然后将参数估计值传输给车辆进行统一的融合处理。该设计可以减少融合计算任务的输入数据量,提高数据融合处理能力。)
本文提出了一种rsu和车辆之间协同感知的分布式数据融合架构。如下图所示——
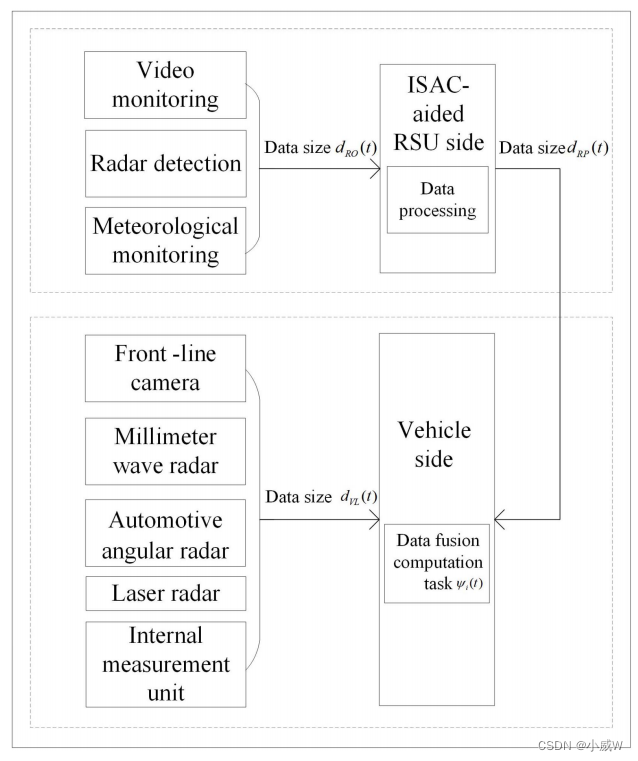
融合计算任务ψi (t)在第i辆车的时隙t处生成,其输入数据由两部分(dRP和dVL)组成。
需要注意的是,实际输入数据量远小于RSU和车辆收集的初始数据量(dRO和dVL),这将显著提高感知数据融合的效率。
由于车辆有限的计算资源无法支持大量的数据融合计算任务,我们必须研究上述网络模型和数据融合架构中相应的计算卸载和资源分配策略。
总结:
RSU 和 Vehicle 都会产生数据,在车辆侧会产生融合,这个融合过程就是一个计算任务。
我们要考虑这个过程中的计算卸载和资源分配策略。
C. Computing Model 计算模型
时隙集 1 , 2 , . . . , T {1,2,... ,T} 1,2,...,T
引入任务模型
ψ
i
(
t
)
=
{
d
i
(
t
)
,
c
i
(
t
)
,
t
i
m
a
x
(
t
)
}
ψ_i (t) = \{d_i (t),c_i (t),t_i ^{max} (t)\}
ψi(t)={di(t),ci(t),timax(t)}
其中
d
i
(
t
)
d_i (t)
di(t)表示输入数据的大小,
c
i
(
t
)
c_i (t)
ci(t)表示处理任务
ψ
i
(
t
)
ψ_i (t)
ψi(t)所需的计算资源,而
t
i
m
a
x
(
t
)
t_i^{max} (t)
timax(t)是最大可容忍的完成延迟。
卸载决策策略表示为
S
(
t
)
=
{
s
i
(
t
)
∣
s
i
(
t
)
=
{
s
i
l
o
c
(
t
)
,
s
i
m
e
c
(
t
)
,
s
i
v
e
(
t
)
}
}
S(t)=\{s_i(t)|s_i(t)=\{s_i^{loc}(t),s_i^{mec}(t),s_i^{ve}(t)\}\}
S(t)={si(t)∣si(t)={siloc(t),simec(t),sive(t)}},
其中,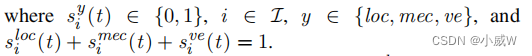
1) Local processing model 本地处理模型
本地总执行时间
t
i
l
o
c
(
t
)
t_i^{loc}(t)
tiloc(t)
本地处理模式的时间消耗
e
i
l
o
c
(
t
)
e_i^{loc}(t)
eiloc(t)

2) MEC processing model MEC处理模型

3) Offloading-available vehicle processing model 可卸载车辆处理模型
任务
ψ
i
ψ_i
ψi 的总执行时间和能耗可以分别表示为——

总结:
定义了任务的计算模型。
定义了三种设备的 延迟、能量消耗、它们之间的传输速率。
D. Queue Model 队列模型
为了描述计算任务的排队延迟,在车辆侧和目标卸载节点(MEC服务器和可卸载车辆)上建立了任务队列模型。
在时隙
t
t
t 时,我们将车辆集
I
I
I 根据车辆是在本地处理计算任务还是将任务卸载给目标节点 重新划分为
G
l
(
t
)
Gl (t)
Gl(t)和
G
o
(
t
)
Go (t)
Go(t)。
另一方面,MEC服务器和卸载可用的车辆构成目标卸载节点集K,可以表示为
K
=
1
,
2
,
.
.
.
,
K
,
K
=
M
+
J
.
K={1,2,...,K},K=M+J.
K=1,2,...,K,K=M+J.
对于车辆
i
∈
G
o
(
t
)
i ∈ Go(t)
i∈Go(t),假设其任务输入数据量在一个时隙的持续时间
τ
τ
τ 中为
A
i
(
t
)
A_i (t)
Ai(t)。
因此,任务队列可以建模如下——
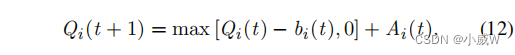
其中
b
i
(
t
)
b_i (t)
bi(t) 表示任务数据大小,在持续时间τ内传输到目标卸载节点。设
x
i
,
k
(
t
)
x_{i,k} (t)
xi,k(t) 表示车辆
i
i
i 在时隙
t
t
t 处的目标卸载节点选择。

在车辆
i
i
i 选择的目标卸载节点
k
k
k 上,任务队列模型可以表示为——
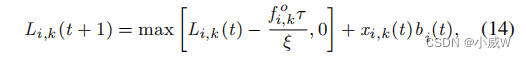
其中,
f
i
,
k
o
f_{i,k}^o
fi,ko 表示目标卸载节点k分配给车辆i的计算能力。
ξ
ξ
ξ 是描述所需计算资源与输入数据大小[14]之间关系的计算任务的服务系数。参考[29],卸载节点
k
k
k 上的计算资源是基于队列积压来分配的——
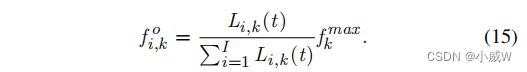
根据 Little 定律,在时隙
t
t
t 处的排队延迟可以表示为——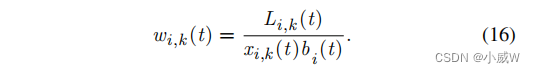
总结:
建立了任务队列模型,推出了排队延迟表达式
4. PROBLEM FORMULATION 问题定义
具有长期延迟和能源消耗约束的排队延迟的最小化问题
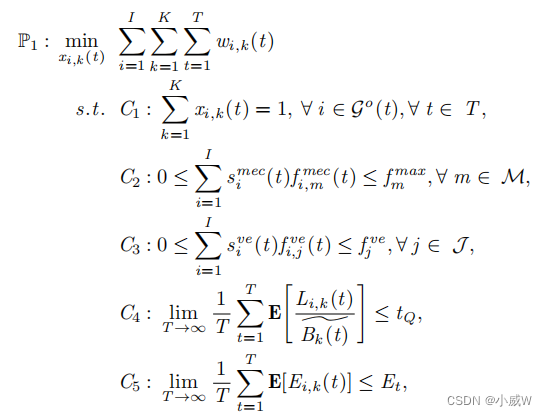
长期排队延迟的限制:具体来说,这个限制是指在一段时间内(例如,一个时隙或一个时间段),任务车辆在MEC服务器节点m处的平均排队延迟不能超过一个预先设定的阈值。( C 4 C_4 C4)
C1表示每辆车在一个时间段内只能选择一个卸载节点。
C2确保分配给所有决定卸载到MEC服务器的任务的计算资源之和不超过该MEC服务器的总计算能力。
C3是计算可用车辆的总计算资源的约束条件。
C4是长期排队延迟约束。
C5是长期能耗的约束条件。
为了得到最优的计算卸载和资源分配决策,我们引入李雅普诺夫优化方法对长期时延约束C4和能耗约束C5进行变换。与传统的凸优化和贪婪算法等方法相比,李雅普诺夫优化具有较低的计算复杂度,并且可以根据当前时隙的状态自适应地处理输入。
在李雅普诺夫优化的基础上,引入两个虚拟队列对长期能耗和长期延迟约束进行重构,将原问题转化为队列稳定控制问题。——
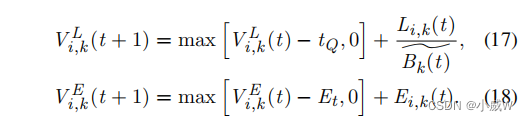
通过构造公式(17)和(18)的加法变换,我们可以得到——

… …
反正后面推推推,最后把初始的优化问题定义转换了一下。
将最初的优化问题重新表述为——
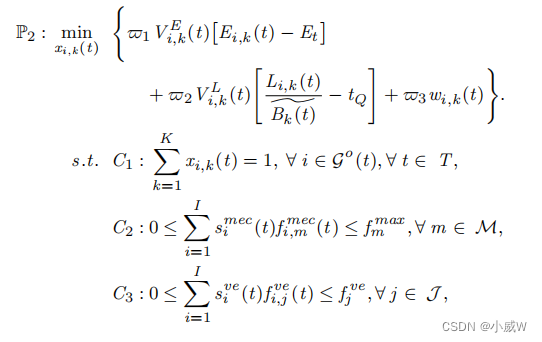
5.JOINT COMPUTATION OFFLOADING AND RESOURCE ALLOCATION SCHEME 联合计算卸载与资源分配方案
A. Task Pre-Classification
Task Pre-Classification使用了一个高级的K-means任务分类( advanced K-means task classi-
fication,AKTC)算法,将任务分成两类:本地计算 和 卸载计算 。具体来说,AKTC算法首先根据任务的延迟约束和计算量,为每个任务做出适当的计算卸载决策。然后,它通过比较样本数据,重复进行聚类操作,直到标准函数收敛并完成聚类操作。最后,AKTC算法选择更合适的初始质量,以解决传统算法收敛到部分最优值的问题。因此,AKTC算法将任务分成两类,以便更好地进行计算卸载和资源分配策略。
AKTC算法可以更好地决定哪些任务应该在本地节点上处理,哪些任务应该卸载到其他设备(如MEC服务器或车辆)上处理。
B. MDP Modeling
在本小节中,提出了一种基于深度强化学习的优化计算资源分配算法,用于需要将任务卸载到MEC服务器或卸载可用车辆的车辆。
MDP过程被定义为一个5元组,即 M = ( S 、 A 、 P 、 R 、 γ ) M =(S、A、P、R、γ) M=(S、A、P、R、γ),包括状态、动作、转移概率、奖励和折扣率向量。
状态:在每个时隙的开始处,队列信息决定了系统的网络的状态。我们将状态向量定义为——
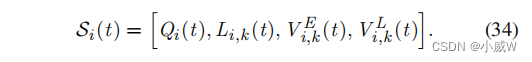
动作:在我们的车辆网络环境中,每辆车都选择一个卸载节点进行计算卸载。车辆的动作向量可以表示为——
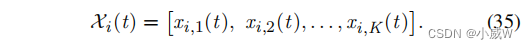
奖励:我们的MDP的奖励函数被定义为基于李亚普诺夫优化的P2变换目标的负值。
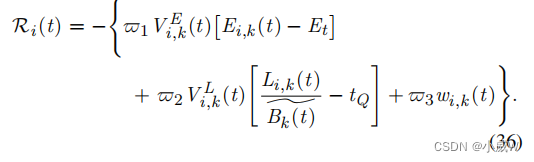
转移概率:车辆
i
i
i从
S
i
(
t
)
S_i (t)
Si(t)开始,选择
X
i
(
t
)
X_i (t)
Xi(t),然后转向
S
i
(
t
+
1
)
S_i(t + 1)
Si(t+1),可以计算为
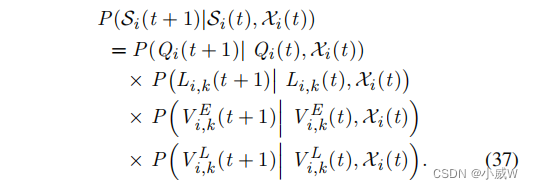
考虑到队列积压是由所有车辆的卸载决策和资源分配策略决定的,转移概率
P
(
S
i
(
t
+
1
)
∣
S
i
(
t
)
,
X
i
(
t
)
)
P(S_i(t + 1)|S_i (t),X_i (t))
P(Si(t+1)∣Si(t),Xi(t))是未知的。
提出了一种基于深度强化学习的优化计算资源分配算法。
这小节主要介绍了 状态、动作、奖励、转移概率 这些定义。
C. The DDQN-Based Computation Offloading and Resource Allocation Algorithm 基于DDQN的计算卸载和资源分配算法
在MDP模型中,状态空间随着卸载数据量的增加而呈指数增长,这导致了“维数诅咒”问题。因此,我们使用一种深度强化的方法来解决这个联合计算卸载和资源分配问题。我们提出了一种基于DDQN的计算卸载和资源分配(DCORA)算法。
与DQN不同的是,双DQN(DDQN)算法使用网络参数设置为 θ θ θ 的主网络来选择一个动作,并使用网络参数设置为 θ − θ^− θ− 的目标网络来评估所选动作的值。
6.仿真结果
7.总结
提出了一种联合计算卸载决策和资源分配策略来提高融合计算任务的能量效率,同时保持任务延迟的性能。
由于每个短期决策对整个系统的长期延迟和能源消耗都有很大的影响,但短期决策必须在没有未来信息的情况下做出。因此,采用李亚普诺夫优化方法将长期能量约束和延迟约束转化为队列稳定性问题。
设计了一种先进的K-means任务分类(AKTC)算法来决定计算任务是应该在本地处理还是卸载到MEC服务器或其他卸载可用的车辆。
如果考虑了一个计算任务的卸载,则采用MDP模型对其卸载处理进行建模,通过基于DDQN的计算卸载和资源分配(DCORA)算法可以找到最优的卸载和计算资源分配决策。
仿真结果表明,与基准计算方案相比,该联合计算和资源分配方案的能耗降低了57.14%。




























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











