







一、题目:
原生python实现knn分类算法,用鸢尾花数据集
二、算法设计

1. 准备数据,对数据进行预处理
2. 选用合适的数据结构存储训练数据和测试元组
3. 设定参数,如k
4.维护一个大小为k的的按距离由大到小的优先级队列,用于存储最近邻训练元组。随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存入优先级队列
5. 遍历训练元组集,计算当前训练元组与测试元组的距离,将所得距离L 与优先级队列中的最大距离Lmax
6. 进行比较。若L>=Lmax,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列。
7. 遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
8. 测试元组集测试完毕后计算误差率,继续设定不同的k值重新进行训练,最后取误差率最小的k 值。
(来源于:百度百科)
三、源代码
编辑器:Spyder(Python3.6)
# -*- coding: utf-8 -*-
"""
Created on Sun Oct 13 10:38:54 2019
"""
from sklearn.datasets import load_iris #导入鸢尾花数据集
from sklearn.model_selection import train_test_split #train_test_split 函数可以打乱数据集并进行拆分
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
#加载鸢尾花数据集
iris_dataset=load_iris()
#分割数据为训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=0)
#设置模型参数,邻居数目为2
knn = KNeighborsClassifier(n_neighbors=2)
#输入训练集数据
knn.fit(X_train,y_train)
#做出预测,预测花萼长5cm宽2.9cm,花瓣长1cm宽0.2cm的花
X_new = np.array([[5,2.9,1,0.2]])
prediction = knn.predict(X_new)
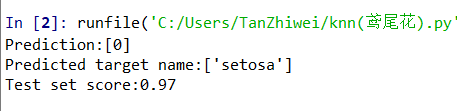
print("Prediction:{}".format(prediction))
print("Predicted target name:{}".format(iris_dataset['target_names'][prediction]))
#评估模型
print("Test set score:{:.2f}".format(knn.score(X_test,y_test)))
四、运行















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









