







前言
本文仅是作为个人学习笔记,对知识进行总结。参考书目:《编译原理及编译程序构造》
基本概念
1. 语法
-
任何语言程序都可以看成是一定字符集(字母表) 上的字符串;语法使得这串字符形成一个形式上正确的程序。
-
语法=词法规则+语法规则
其中词法规则规定了字母表中哪些字符串是单词符号。
其中语法规则规定了如何从单词符号来形成语法单位
语法单位有表达式、子句、语句、函数、过程、程序
2. 字母表、符号串、句子、语言
- 字母表是符号的非空有穷集合
- 符号是语言中最基本的不可分割的单位
- 符号串是由字母表中的符号组成
- 句子是是字母表上符合某种规则构成的串
- 语言是字母表上句子的集合
3. 基础运算
- 连接运算
- 幂运算
- 闭包运算(正闭包指不包含空串)
3. 文法
-
文法是描述语言的语法结构的形式规则
-
终结符 V T V_T VT
-
非终结符 V N V_N VN
-
0形文法(只要产生式左边有一个非终结符即可)
-
1形文法(也称长度增加文法或者上下文有关文法,对非终结符进行替换时务必考虑上下文)
-
2形文法(产生式左部一定是非终结符,对非终结符进行替换时无需考虑上下文)
-
3形文法(称为正规文法,有左线性和右线性之分)
3. 短语、直接短语
- 短语:语法树中,所有的子树根结点构成的就是短语
- 直接短语:只有2层子树构成的短语,是直接短语
4. 文法的二义性
-
如果文法的一个句子存在对应的两棵或两棵以上 的语法树,则该句子是二义的。
-
用某文法推导某个句子,如果有好几种推导方式,那么说明这个文法就是二义性的。
算法
1.构造无ε产生式的上下文无关文法
- 找出所有能够推出ε非终结符
- 对于这些非终结符,如果他们出现在产生式的右部,则用它本身和ε代换
直接看例题比较好理解

2.文法的化简算法
- 消去P->P
- 消去不可达的非终结符
- 消去不能导出终结符的非终结符
看例题比较好理解

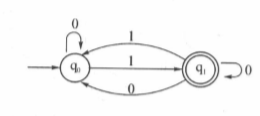
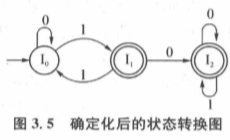
3.NFA的确定化算法
直接看例题比较好理解,如下

4.DFA的最小化
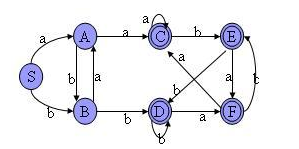
-
将M的状态分为两个子集一个由终态k1={C,D,E,F}组成,一个由非终态k2={S,A,B}组成,
-
考察{S,A,B}是否可分.
-
因为A经过a到达C属于k1.而S经过a到达A属于k2.B经过a到达A属于k2,所以K2继续划分为{S,B},{A},
-
考察{S,B}是否可再分:
-
B经过b到达D属于k1.S经过b到达B属于k2,所以S,B可以划分。划分为{S},{B}
-
考察{C,D,E,F}是否可再分:
-
因为C,D,E,F经过a和b到达的状态都属于{C,D,E,F}=k1所以相同,所以不可再分:
-
{C,D,E,F}以{D}来代替则,因为CDEF相同,你也可以用C来代替。无所谓的最小化的DFA如图,:
总结:先对非终态集进行划分,直到不能划分为止,然后再对终态集进行划分,直到不能划分为止,从所有划分之后的集合中选出一个代表即可。
5. 根据正则表达式构造NFA
即反复应用下面算法

7.确定化含ε弧的NFA
确定化含ε弧的NFA实际上就是多了一个求ε闭包,ε闭包定义如下:

步骤几乎与3一摸一样,只是多了一步求ε闭包

6.根据文法构造NFA
这里指的文法通常是指左线性文法或者右线性文法。


词法分析程序的实现
程序设计步骤
- 画出词法的NFA
- 确定化NFA,生成DFA
- 化简DFA
- 合并DFA
- 编码实现最终实现的DFA
给定输入文件

输出:

ifndef LEX
#define LEX
#include <string>
#include <fstream>
#include "table.h"
#include <map>
#include <vector>
#include<iostream>
using namespace std;
#define STATE_END 20
class LexAnalyzer
{
public:
string content;
int cursor;
map<string, vector<int>> result;
public:
void preprocess(){
string temp = "";
int index = 0;
int s = 0;
while (content[index] != '\0')
{
char ch = content[index];
if (s == 0 && ch != '/'){
temp += ch;
}
else if (s ==0 && ch=='/'){
s = 1;
}
else if (s == 1 && ch == '/'){
s = 2;
}
else if (s == 1 && ch == '*'){
s = 3;
}
else if (s == 1 && (ch != '/'||ch!='*')){
temp = temp + '/' + ch;
s = 0;
}
else if (s==2 && ch !='\n'){
s = 2;
}else if(s==2 && ch=='\n'){
s = 0;
}
else if (s==3 && ch=='*'){
s = 4;
}
else if (s==4 && ch=='/'){
s = 0;
}
else if (s==4 && ch!='/'){
s = 3;
}
index++;
}
cout << temp<<endl;
content = temp;
}
public:
LexAnalyzer(string filename){
ifstream in(filename);
string line;
while (getline(in, line)){
content =content+ line+"\n";
}
cursor = 0;
in.close();
}
~LexAnalyzer(){
}
private:
int state = 0; // 初始化状态
public:
char scanner(){
char res = content[cursor++];
return res;
}
string adscanner(int i){
string res = "";
while (i--)
{
res = content[cursor + i]+res;
}
return res;
}
void parser(){
try{
string token = "";
while (true){
char ch = this->scanner();
if (ch == '\0'){
break;
}
switch (state){
case 0:
state_convet_0(ch);
break;
case 1:
state_convet_1(ch);
break;
case 2:
state_convet_2(ch);
break;
case 3:
state_convet_3(ch);
break;
case 4:
state_convet_4(ch);
break;
case 5:
state_convet_5(ch);
break;
case 6:
state_convet_5(ch);
break;
default:
break;
}
if (state == 0){
}
else if (state != STATE_END){
token += ch;
}
else{
vector<int> v;
if (isBaseField(token)){
v.push_back(getClassId(token));
result[token] = v;
cout << "关键字:";
}
else if (isConstant(token)){
addConstant(token);
cout << "常量:";
}
else{
int innerID;
if (existIdentifier(token)){
innerID = getIdentifierID(token);
}
else{
innerID = addIdentifier(token);
}
v.push_back(getClassId(IDENT));
v.push_back(innerID);
result[token] = v;
cout << "标识符:";
}
cout << token << endl;
token = "";
state = 0;
back();
}
}
}
catch (exception &e){
throw e;
}
}
public:
map<string, vector<int>> getResult(){
int a = 10;
return result;
}
private:
void back(int i=1){
cursor -= i;
}
void skip(){
while (content[cursor] == ' ')
cursor++;
}
private:
bool isCharactor(int ch){
return (ch >= 97 && ch <= 122) || (ch >= 65 && ch <= 90);
}
bool isNum(int ch){
return (ch >= 48 && ch <= 57);
}
bool isNoDisplayCharactor(int ch){
return (ch >= 0 && ch <= 32) || (ch == 127);
}
bool isConstant(string str){
for (int i = 0; i < str.size();i++){
char c = str[i];
if (!(c>='0' && c<='9')){
return false;
}
}
return true;
}
private:
void state_convet_6(char ch){
state = STATE_END;
}
void state_convet_5(char ch){
state = STATE_END;
}
void state_convet_4(char ch){
if (isNoDisplayCharactor(ch) || ch == '='){
state = STATE_END;
}else{
throw exception("词法错误");
}
}
void state_convet_3(char ch){
if (isNum(ch)){
state = 2;
}
else if(ch=='='){
state = 6;
}
else if (isNoDisplayCharactor(ch) || isCharactor(ch)){
state = STATE_END;
}
else{
throw exception("词法错误");
}
}
void state_convet_2(char ch){
if (this->isNum(ch)){
return;
}
else if (isNoDisplayCharactor(ch) || ch == ';'){
state = STATE_END;
}
else{
throw exception("词法错误");
}
}
void state_convet_1(char ch){
if (this->isCharactor(ch) || this->isNum(ch)){
return;
}
state = STATE_END;
}
void state_convet_0(char ch){
if (this->isCharactor(ch)){
state = 1;
}
else if (this->isNum(ch)){
state = 2;
}
else{
switch (ch)
{
case '+':
case '-':
state = 3;
break;
case '*':
case '/':
state = 4;
break;
case '=':
state = 5;
break;
default:
break;
}
}
}
};
#endif
















 8030
8030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











