







前言
GAN(生成对抗网络)是2014年由Goodfellow大佬提出的一种深度生成模型,适用于无监督学习、监督学习。但是GAN进行生成时是不可控的,所以后来又有人提出可控的CGAN(条件生成对抗网络)。
本文内容摘自原论文要点以及部分个人理解。原论文链接如下:
Generative Adversarial Nets
ConditionalGenerativeAdversarialNets
GAN
Introduce
在以往的模型发展中,判别模型的发展是非常成功的,但是生成模型则没有那么大的影响,这是因为有很多难以计算的问题。
作者提出的GNN是一种全新的架构,生成模型可以被认为是造假团队,而判别模型则被类似认为是警察。它们之间的相互竞争促使其能更好的产生赝品和发现赝品,直到真假难分
In the proposed adversarial nets framework, the generative model is pitted against an adversary: a discriminative model that learns to determine whether a sample is from the model distribution or the data distribution. The generative model can be thought of as analogous to a team of counterfeiters, trying to produce fake currency and use it without detection, while the discriminative model is analogous to the police, trying to detect the counterfeit currency
该架构最大的优势就是,我们可以使用传统的方向传播算法进行训练,而且还可以在网络中使用dropout、maxout等技术。这是因为Generator和Discriminator实际上都是一个是多层感知机。
we can train both models using only the highly successful backpropagation and dropout algorithms [17] and sample from the generative model using only forward propagation
Detail
GNN中的生成模型,我们可以把它视为一个多层感知器,为了能够让生成器学到训练集的分布,我们对生成器的输入都是随机产生的噪声
To learn the generator’s distribution pgover data x, we define a prior on input noise variables pz(z), then represent a mapping to data space as G(z; θg), where G is a differentiable function represented by a multilayer perceptron with parameters θg
判别模型也是一个多层感知机,该模型只输入一个数值,该数值评估了对于输入数据x,其来自训练集data的概率大小。
We also define a second multilayer perceptron D(x; θd) that outputs a single scalar. D(x) represents the probability that x came from the data rather than pg
整个GAN网络,都是在优化如下目标函数
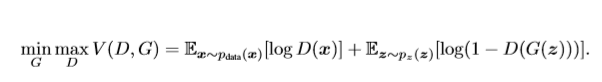
但是为什么这里既有min,又有max呢?
这是因为在训练判别模型的时候,我们希望对于是来自data中的数据,其输出的数值尽量大,不是来自data的数据,其输出的数值尽量小。
而在训练G的时候,我们则希望对于是来自生成器生成的数据集,其D输出的值尽量大
所以这里的min和max是指的两个过程,max是指我们希望在训练discriminator的时候要最大化该目标函数,而在训练Generator的时候要最小化该目标函数
原论文中的算法实现如下:

这里也附上python的tensorflow实现
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from data_util.minist import load
img_length = 784
'''第一步:构造discriminator的参数'''
with tf.variable_scope("Discriminator"):
#输入层占位符
Dx = tf.placeholder(dtype=tf.float64,shape=[None,img_length],name="d_input")
#第一层参数
w1 = tf.get_variable('w1',shape=[img_length,128],initializer=tf.keras.initializers.random_normal(),dtype=tf.float64) #xavier初始化
b1 = tf.get_variable("b1",shape=[128,],initializer=tf.zeros_initializer(),dtype=tf.float64) #0初始化
#第二层参数
w2 = tf.get_variable('w2',shape=[128,1],initializer=tf.keras.initializers.random_normal(),dtype=tf.float64) #xavier初始化
b2 = tf.get_variable("b2",shape=[1,],initializer=tf.zeros_initializer(),dtype=tf.float64) #0初始化
# Discriminator的优化参数列表
d_theta = [w1,b1,w2,b2]
'''第二步:构造Generator的参数'''
with tf.variable_scope("Generator"):
#输入层占位符
Gz = tf.placeholder(dtype=tf.float64,shape=[None,100],name="g_input")
#第一层的参数
Gw1 = tf.get_variable('w1',shape=[100,128],initializer=tf.keras.initializers.random_normal(),dtype=tf.float64) #xavier初始化
Gb1 = tf.get_variable("b1",shape=[128,],initializer=tf.zeros_initializer(),dtype=tf.float64) #0初始化
#第二层参数
Gw2 = tf.get_variable('w2',shape=[128,img_length],initializer=tf.keras.initializers.random_normal(),dtype=tf.float64) #xavier初始化
Gb2 = tf.get_variable("b2",shape=[img_length,],initializer=tf.zeros_initializer(),dtype=tf.float64) #0初始化
# Generator的优化参数列表
g_theta = [Gw1,Gb1,Gw2,Gb2]
'''第三步,构造Discriminator'''
def Discriminator(x):
'''
:param x:输入的图片
:return: a single scale
'''
o1 = tf.nn.relu(tf.matmul(x,w1)+b1)
o2 = tf.matmul(o1,w2)+b2
prob = tf.nn.sigmoid(o2)
return prob,o2
def Generator(z):
'''
:param z: 输入的随机噪声
:return: 一张图片
'''
o1 = tf.nn.relu(tf.matmul(z,Gw1)+Gb1)
o2 = tf.nn.sigmoid(tf.matmul(o1, Gw2) + Gb2)
return o2
def sample_z(m,n):
'''
:param m: 噪声数据个数
:param n: 噪声数据的维度
:return:噪声抽样
'''
return np.random.uniform(-1.,1.,size=(m,n))
# Generator生成的数据
G_sample = Generator(Gz)
# Discriminator对真实数据进行判断的结果
D_real,D_logist_real = Discriminator(Dx)
# Discriminator对生成数据进行判断的结果
D_fake,D_logist_fake = Discriminator(G_sample)
#定义Discriminator的损失
D_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logist_real,labels=tf.ones_like(D_logist_real)))
D_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logist_fake,labels=tf.zeros_like(D_logist_fake)))
D_loss = D_loss_fake+D_loss_real
#定义Generator的损失
G_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logist_fake,labels=tf.ones_like(D_logist_fake)))
#定义优化器
Dopt = tf.train.AdamOptimizer().minimize(D_loss,var_list=d_theta)
Gopt = tf.train.AdamOptimizer().minimize(G_loss,var_list=g_theta)
batch_size = 128
z_dim = 100
k = 1
x_train,y_train,x_test,y_test = load()
x_train = x_train/ 255
index = 0
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 整体训练100000次
for i in range(100000):
#训练Discriminator k次
for k in range(0,k):
start = (index * batch_size) % len(x_train)
end = min(start + batch_size, len(x_train))
x_sample = x_train[start:end]
z = sample_z(batch_size, z_dim)
index+=1
sess.run(Dopt,feed_dict={Dx:x_sample,Gz:z})
#训练Generator 1次
start = (index * batch_size) % len(x_train)
end = min(start + batch_size, len(x_train))
x_sample = x_train[start:end]
z = sample_z(batch_size, z_dim)
index += 1
sess.run(Gopt,feed_dict={Gz:z})
#每隔一百次查看一下损失
if i % 1000 == 0:
d_loss_value= sess.run(D_loss,feed_dict={Dx:x_sample,Gz:z})
g_loss_v=sess.run(G_loss,feed_dict={Gz:z})
print("step {},the loss of generator :{},the loss of discriminator :{}".format(i,d_loss_value,g_loss_v))
if i% 3000 == 0:
g_data = sess.run(G_sample,feed_dict={Gz:z})
img = g_data[10].reshape([28,28])
plt.imshow(img,cmap='gray')
plt.show()
作者在进行编码的时候,生成网络使用了relu作为隐藏层激活函数而sigmoid作为输出层的激活函数,判别网络类似,但是额外使用了maxout和dropout
原论文中也证明了,整个GAN网络,实际上是在近似最小化JS divergence。但是如果你想达到理论上的近似,那么前提就是Discriminator训练的足够好且Generator基本保持不变。
所以为了满足上述条件,通常都是训练k次Discriminator,然后训练1次Generator。
具体详细证明如下,挺好懂的。

CGAN
为了希望可以给Generator和Discriminator附加上限制条件,所以MehdiMirza提出了CGAN模型。
对于无条件的生成模型,数据的生成上不可控的。然而通过给模型附加一些信息,就可以引导模型生成我们想要的数据。
实际上,CGAN仅仅是改变了GAN的输入,原始GAN只需要输入数据就可以生成图片。而CGAN还需要输入标签,因此CGAN是输入监督学习
下图,即为CGAN的网络结构
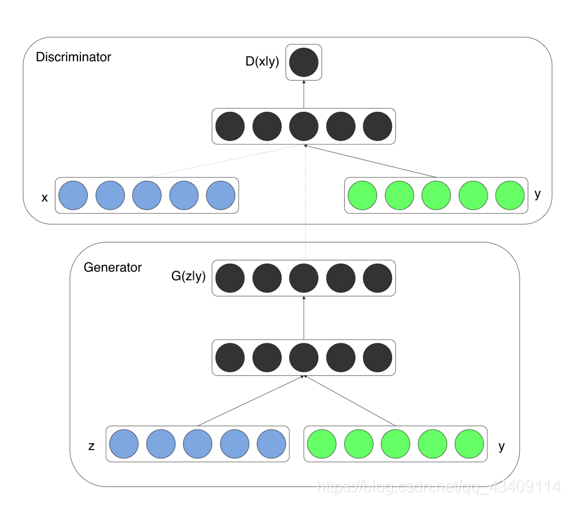
实际上,最简单的做法就是将噪声z和标签y拼接在一起,然后作为输入,但是这样做会有很多缺点。为了具体说明CGAN是如何运作的,下面说一下原始论文中,作者的做法。
- 在生成MINIST的任务中,作者做法是,先生成100维度的均匀分布的噪声和one-hot类别标签y,然后将这两个数据分别映射到隐层(200、1000),然后将其拼接成一个1200维的向量,最后通过输出层输出784维的图片
- 对于Discriminator,则是将G生成的图片和图片标签作为两个隐藏层的输入,然后再将两个隐藏层的输出拼接再一起作为输出层的输入。其详细参数如下(使用了maxout、dropout、学习率衰减、 momentum)


作者还进行了图片标注的任务测试,其思路就是先对语料库进行Embedding,让相关联的词向量距离尽可能近一些。 然后向Generator输入随机噪声和图片。作者的做法是随机生成100维度的噪声,然后其映射到有500个隐藏单元的隐藏层。然后输入的图片为4096维度,然后将其映射到2000个隐藏单元的隐藏层中。最后将这两个隐藏层的输出向量拼接在一起,作为输出层的输出,输出层输出200维的词向量
The best working model’s generator receives Gaussian noise of size 100 as noise prior and maps it to 500 dimension ReLu layer. And maps 4096 dimension image feature vector to 2000 dimension ReLu hidden layer. Both of these layers are mapped to a joint representation of 200 dimension linear layer which would output the generated word vectors
而Discriminator则会将图片和word vector分别映射到1200 dim和500dim,然后将其拼接起来作为输出层的输出。
The discriminator is consisted of 500 and 1200 dimension ReLu hidden layers for word vectors and image features respectively and maxout layer with 1000 units and 3 pieces as the join layer which is finally fed to the one single sigmoid unit.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import os
from data_util.minist import load
'''First step ,we show load the minist data from dir and set base parameters'''
x_train,y_train,x_test,y_test = load()
# in order to get easier way to train the model,we should normalize the input
x_train = x_train / 255
#the batch size
mb_size = 100
#the dimention of noise input
Z_dim = 100
#the input imgage size
X_dim = 28 * 28
#the form of label should be one-hot encode
y_dim = 10
#hidden layers size
h_dim = 128
# 使用xavier初始化
def xavier_init(size):
in_dim = size[0]
xavier_stddev = 1. / tf.sqrt(in_dim / 2.)
return tf.random_normal(shape=size, stddev=xavier_stddev)
""" Discriminator Net model """
X = tf.placeholder(tf.float32, shape=[None, 784]) # 输入占位符
y = tf.placeholder(tf.float32, shape=[None, y_dim]) # 输出占位符
D_W1 = tf.Variable(xavier_init([X_dim + y_dim, h_dim])) # 第一层隐藏层参数
D_b1 = tf.Variable(tf.zeros(shape=[h_dim])) # 第二层隐藏层偏置
D_W2 = tf.Variable(xavier_init([h_dim, 1])) #最后一层参数
D_b2 = tf.Variable(tf.zeros(shape=[1])) # 第二层隐藏层偏置
theta_D = [D_W1, D_W2, D_b1, D_b2] #训练变量
def discriminator(x, y):
inputs = tf.concat(axis=1, values=[x, y]) # 输入很简单,直接将image拉直,然后将其标签拼接到尾部即可
D_h1 = tf.nn.relu(tf.matmul(inputs, D_W1) + D_b1)
D_logit = tf.matmul(D_h1, D_W2) + D_b2
D_prob = tf.nn.sigmoid(D_logit)
return D_prob, D_logit
#Discriminator 一共有三层:输入层-->隐藏层-->输出层
""" Generator Net model """
Z = tf.placeholder(tf.float32, shape=[None, Z_dim]) #随机噪声输入
G_W1 = tf.Variable(xavier_init([Z_dim + y_dim, h_dim])) #隐藏层参数
G_b1 = tf.Variable(tf.zeros(shape=[h_dim])) #隐藏层偏置
G_W2 = tf.Variable(xavier_init([h_dim, X_dim])) #输出层参数
G_b2 = tf.Variable(tf.zeros(shape=[X_dim])) # 隐藏层偏置
theta_G = [G_W1, G_W2, G_b1, G_b2]
def generator(z, y):
inputs = tf.concat(axis=1, values=[z, y]) # Generator也是如此,直接将image拉直,然后将其标签拼接到尾部即可
G_h1 = tf.nn.relu(tf.matmul(inputs, G_W1) + G_b1)
G_log_prob = tf.matmul(G_h1, G_W2) + G_b2
G_prob = tf.nn.sigmoid(G_log_prob)
return G_prob
#生成器模型一共有3层:输入层-->隐藏层-->输出层
# 下面函数是用于随机生成噪声的
def sample_Z(m, n):
return np.random.uniform(-1., 1., size=[m, n])
def plot(samples):
fig = plt.figure(figsize=(4, 4))
gs = gridspec.GridSpec(4, 4)
gs.update(wspace=0.05, hspace=0.05)
for i, sample in enumerate(samples):
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
plt.imshow(sample.reshape(28, 28), cmap='Greys_r')
return fig
G_sample = generator(Z, y)
D_real, D_logit_real = discriminator(X, y)
D_fake, D_logit_fake = discriminator(G_sample, y)
D_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logit_real, labels=tf.ones_like(D_logit_real)))
D_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logit_fake, labels=tf.zeros_like(D_logit_fake)))
D_loss = D_loss_real + D_loss_fake
G_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logit_fake, labels=tf.ones_like(D_logit_fake)))
D_solver = tf.train.AdamOptimizer().minimize(D_loss, var_list=theta_D)
G_solver = tf.train.AdamOptimizer().minimize(G_loss, var_list=theta_G)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
if not os.path.exists('out/'):
os.makedirs('out/')
i = 0
# 一共训练100w次
for it in range(1000000):
# 每隔1000次输出一下模型效果
if it % 1000 == 0:
n_sample = 16 #每次采样16个
Z_sample = sample_Z(n_sample, Z_dim)
y_sample = np.zeros(shape=[n_sample, y_dim])
value_symple = np.array([2,9,3,7,0,3,3,0,1,2,2,7,9,7,1,2])
y_sample[:, 8] = 1
samples = sess.run(G_sample, feed_dict={Z: Z_sample, y:y_sample})
fig = plot(samples)
plt.savefig('out/{}.png'.format(str(i).zfill(3)), bbox_inches='tight')
i += 1
plt.close(fig)
# 进行批量采样
start = (it * mb_size) % len(x_train)
end = min(start+mb_size,len(x_train))
X_mb = x_train[start:end]
y_mb = y_train[start:end]
Z_sample = sample_Z(mb_size, Z_dim)
# 喂数据
_, D_loss_curr = sess.run([D_solver, D_loss], feed_dict={X: X_mb, Z: Z_sample, y:y_mb})
_, G_loss_curr = sess.run([G_solver, G_loss], feed_dict={Z: Z_sample, y:y_mb})
if it % 1000 == 0:
print('Iter: {}'.format(it))
print('D loss: {:.4}'. format(D_loss_curr))
print('G_loss: {:.4}'.format(G_loss_curr))
print()


















 616
616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











