







一、简介
语法分析任务
- 识别由词法分析得出的单词序列是否是给定文法的句子
语法分析理论基础
- 上下文无关文法和下推自动机
自上而下语法分析的方式
- 反复使用不同产生式进行推导以谋求与输入符号 串相匹配
二、算法
1.消除左递归
问题:什么是左递归 ?
答:文法存在产生式P →Pa,则是直接左递归,文法存在产生式P →Pa ,P →Aa, A→Pb,则是间接左递归。
消除直接左递归的方法
本质上就是将左递归转换为右递归

如果有间接左递归的话该怎么办呢?

直接看定义不好理解,看完例题立马就清楚了。

另外需要注意的是,如果上述的排序顺序不同,最终得到的文法可能不同,但是这些文法是等价的,并且开始符号不能改变。
2.消除回溯
之前所以会产生回溯,是因为可能会产生虚假匹配。
(1)、求候选式的First集
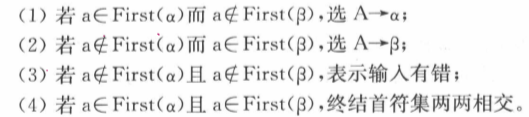

(2)、求候选式的Follow集
First集中可能有空串,但是Follow集中肯定没有空串

(3)、提取左因子

(3)、构造预测分析表

三、代码实现
本程序支持自定义文法,程序会自动分析文法,求出First集合、Follow集合并且算出预测分析表。根据预测分析表,我们可以直接写出PDA进行语法分析,因为时间关系,写的比较粗糙,后面如果有时间会对其进行改良
词法分析程序
该程序是对上节进行改良的
#pragma once
#include <set>
#include <fstream>
#include <stdio.h>
#include <string>
#include <map>
#include <iostream>
#include <vector>
#define END_ACCEPT 20
#define END_NO_ACCEPT 21
#define ERR 22
using namespace std;
namespace Lex {
void init();
};
extern map<string, int> KEYWORD_TAB;
extern map<string, int> TYPE_TAB;
extern map<string, int> BASE_TAB;
extern map<string, int> Operator;
extern map<string, int> Seperator;
#define TYPE_DEFINE 1001
#define CONSTANT 1002
#define IDENTIFIER 1003
#define OPERATOR 1004
#define Separator 1005
#define KeyWord 1005
class Token
{
public:
string token;
int Line;
int TYPE;
Token(int line):Line(line){
token = "";
}
public:
void append(char ch) {
token += ch;
}
public:
bool finished = false;
void finish() {
if (finished) {
finished = true;
return;
}
cout << "Line" << Line << ":";
if (TYPE_TAB.count(token) != 0) {
cout << "类型->";
TYPE = TYPE_DEFINE;
}
else if (isConstant(token)) {
cout << "常量->";
TYPE = CONSTANT;
}
else if (Operator.count(token) != 0) {
cout << "操作符->";
TYPE = OPERATOR;
}
else if (Seperator.count(token) != 0) {
cout << "分隔符->";
TYPE = Separator;
}else if (KEYWORD_TAB.count(token)!=0) {
cout << "关键字->";
TYPE = Separator;
}
else {
cout << "标识符->";
TYPE = IDENTIFIER;
}
cout << token<<endl;
}
public:
bool isConstant(string str) {
for (int i = 0; i < str.size();i++) {
char c = str[i];
if (c != '.' && !(c >= '0' && c <= '9')) {
return false;
}
}
return true;
}
};
class LexAna {
private:
ifstream in;
int cursor = 0;
int Line = 0;
string Line_content;
vector<Token*> Line_vector;
private:
int State = 0;
Token *token=NULL;
public:
LexAna(string filename):in(filename),Line_content(""),Line(0){
next_line();
}
public:
bool next_line() {
if (in.eof()) {
Line_content = "";
return true;
}
cursor=0;
Line++;
token = new Token(Line);
getline(in,Line_content);
Line_content += '\n';
return false;
}
vector<Token*> scanner() {
if (Line_content=="") {
return vector<Token*>();
}
token = new Token(Line);
while (true)
{
if (cursor>=Line_content.size()) {
next_line();
vector<Token*> res = Line_vector;
Token *t=new Token(Line);
t->append('#');
res.push_back(t);
Line_vector.clear();
return res;
}
char ch = Line_content[cursor++];
switch (State)
{
case 0:
S0(ch);
break;
case 1:
S1(ch);
break;
case 2:
S2(ch);
break;
case 3:
S3(ch);
break;
case 4:
S4(ch);
break;
case 5:
S5(ch);
break;
}
if (State !=END_ACCEPT && State!=END_NO_ACCEPT && State!=0) {
token->append(ch);
}else if (State == END_ACCEPT) {
token->append(ch);
end();
}
else if (State == END_NO_ACCEPT) {
end();
back();
}
}
}
void back() {
cursor--;
}
private:
bool isNum(int ch) {
return (ch >= 48 && ch <= 57);
}
bool isNoDisplayCharactor(int ch) {
return (ch >= 0 && ch <= 32) || (ch == 127);
}
private: //终止状态
void end() {
token->finish();
Line_vector.push_back(token);
State = 0;
token = new Token(Line);
}
private: //非终止状态
void S0(char ch) {
if (isalpha(ch)) {
State = 1;
}
else if (isNum(ch)) {
State = 2;
}
else if (ch=='-' || ch == '+') {
State = 4;
}
else if (ch=='*' || ch =='/') {
State = 5;
}
else if (ch==',' || ch==';'||ch=='('||ch=='{'||ch==')'||ch=='}'||ch=='['||ch==']' || ch=='=') {
State = END_ACCEPT;
}
}
//变量名
void S1(char ch) {
if (isalpha(ch) || isNum(ch)) {
//State保持不变
}
else{
State = END_NO_ACCEPT;
}
}
//数字
void S2(char ch) {
if (isNum(ch)) {
//State保持不变
}else if(ch=='.'){
State = 3;
}
else{
State = END_NO_ACCEPT;
}
}
void S3(char ch) {
if (isNum(ch)) {
State = 2;
}
else {
State =ERR;
}
}
void S4(char ch) {
if (isNum(ch)) {
State = 2;
}
else if(ch=='='){
State = END_ACCEPT;
}
else {
State = END_NO_ACCEPT;
}
}
void S5(char ch) {
if (ch=='=') {
State = END_ACCEPT;
}
else {
State = ERR;
}
}
};
文法分析程序
#pragma once
#include <fstream>
#include <string>
#include <list>
#include <vector>
#include <set>
#include<algorithm>
#define T_SYMPLE 2001
#define N_SYMPLE 2002
#define E 2003
#define START_SYMPLE "开始"
using namespace std;
class Symple {
public:
string name;
int ID;
bool empty;
bool start = false;
public:
Symple() {
}
Symple(string n,int i):name(n),ID(i),empty(false){
if (n=="$") {
empty = true;
}
}
bool operator<(const Symple& d) const {
return name < d.name;
}
bool operator==(const Symple& d) const {
return name == d.name;
}
bool operator!=(const Symple& d) const {
return name!=d.name;
}
private:
};
class derivation {
public:
Symple left;
vector<vector<Symple>> right;
derivation() {
}
derivation(pair<vector<Symple>, vector<int>> p):left(p.first.front().name, p.first.front().ID){
vector<Symple> & temp_list = p.first;
vector<int> splitindex = p.second;
int start = 1;
int index = 0;
for (int i = 0;i < splitindex.size();i++) {
index= splitindex[i];
vector<Symple>::iterator start_it = temp_list.begin() + start;
vector<Symple>::iterator end_it = temp_list.begin()+index;
vector<Symple> res1 = vector<Symple>(start_it, end_it);
start = index;
right.push_back(res1);
//A ( B ) C void
}
vector<Symple>::iterator start_it = temp_list.begin() + start;
vector<Symple>::iterator end_it = temp_list.end();
vector<Symple> res1 = vector<Symple>(start_it, end_it);
right.push_back(res1);
}
public:
bool Right_contain(Symple symple) {
for (vector<Symple> symples:right) {
for (Symple s : symples) {
if (s==symple) {
return true;
}
}
}
return false;
}
};
map<string,Symple> N_SYMPLE_SET;
map<Symple,derivation> der;
namespace Syntax {
pair<vector<Symple>,vector<int>> parser(string line) {
int cursor = 0;
int state = 0;
string token = "";
vector<int> res;
vector<Symple> res_list;
bool head=false;
while (cursor<line.size())
{
if (line[cursor]==':') {
cursor++;
continue;
}
if (state == 0 && line[cursor]=='<' ) {
state = 1;
}
else if (state==0 && line[cursor]!='<' && line[cursor] != '|') {
token += line[cursor];
state = 2;
}
else if (state ==1&&line[cursor]!='>') {
token += line[cursor];
}
else if (state ==1 && line[cursor]=='>') {
res_list.push_back(Symple(token, N_SYMPLE));
cout<<"非终结符:" << token<<endl;
state = 0;
token = "";
}
else if (state == 2 && line[cursor]!=' ' && line[cursor] != '|' && line[cursor] != '<') {
token += line[cursor];
}
else if(state == 2 &&!(line[cursor] != ' ' && line[cursor] != '|' && line[cursor] != '<')){
res_list.push_back(Symple(token, T_SYMPLE));
cout << "终结符:" << token << endl;
state = 0;
token = "";
if (line[cursor] == '<'|| line[cursor] == '|') cursor--;
}else if (state==0 && line[cursor]=='|') {
res.push_back(res_list.size());
}
cursor++;
}
if (token.size()>0&&line[cursor-1]!='>') {
res_list.push_back(Symple(token, T_SYMPLE));
cout << "终结符:" << token << endl;
}
else if(token.size()>0) {
res_list.push_back(Symple(token, N_SYMPLE));
cout << "非终结符:" << token << endl;
}
return pair<vector<Symple>,vector<int>>(res_list,res);
}
void init() {
ifstream in("C:\\Users\\user\\Desktop\\Message\\简单文法.txt");
string line;
while (getline(in, line))
{
pair<vector<Symple>, vector<int>> res= Syntax::parser(line);
vector<Symple> l1= res.first;
for (vector<Symple>::iterator i = l1.begin();i != l1.end();i++) {
Symple s = *i;
if (s.ID==N_SYMPLE) {
N_SYMPLE_SET[s.name]=s;
}
}
derivation d = derivation(res);
der[d.left] = d;
}
cout << "一共有非终结符:" << N_SYMPLE_SET.size()<<endl;
}
}
//函数:求First集
map<Symple, list<Symple>> ALL_FIRST;
list<Symple> First(Symple symple) {
if (symple.ID==T_SYMPLE) {
list<Symple> res = list<Symple>();
res.push_back(symple);
return res;
}
if (ALL_FIRST.count(symple)>0) {
return ALL_FIRST[symple];
}
derivation d = der[symple];
vector<vector<Symple>> r= d.right;
list<Symple> first_unin;
bool flag = false;
for (vector<Symple> vec :r) {
int cursor = 0;
while (cursor<vec.size())
{
Symple s = vec[cursor++];
if (s.ID == T_SYMPLE ) {
first_unin.push_back(s);
flag = false;
break;
}
else if (s.ID == N_SYMPLE) {
list<Symple> s_fir = First(s);
list<Symple>::iterator it = find(s_fir.begin(), s_fir.end(), Symple("$", T_SYMPLE));
if (it == s_fir.end()) {
flag = false;
first_unin.splice(first_unin.begin(), s_fir);
break;
}
else {
flag = true;
s_fir.remove(Symple("$", T_SYMPLE));
first_unin.splice(first_unin.begin(), s_fir);
}
}
}
if (cursor==vec.size() && flag==true) {
first_unin.push_back(Symple("$", T_SYMPLE));
}
}
first_unin.unique();
ALL_FIRST[symple] = first_unin;
return first_unin;
}
map<Symple, list<Symple>> ALL_Follow;
//函数求Follow集
list<Symple> Follow(Symple symple_) {
if (ALL_Follow.count(symple_)>0) {
return ALL_Follow[symple_];
}
list<Symple> follow_unin;
if (symple_.start == true) {
follow_unin.push_back(Symple("#",T_SYMPLE));
}
map<Symple, derivation>::iterator it_start=der.begin();
map<Symple, derivation>::iterator it_end = der.end();
vector<derivation> target;
for (;it_start != it_end;it_start++) {
derivation d = (*it_start).second;
if (d.Right_contain(symple_)) {
target.push_back(d);
}
}
for (derivation d : target) {
vector<vector<Symple>> r = d.right;
for (vector<Symple> vec : r) {
for (int i = 0;i < vec.size();i++) {
Symple symple = vec[i];
if (symple.ID == T_SYMPLE && symple != symple_) {
continue;
}
else if (symple == symple_) {
if (i + 1 == vec.size() && d.left!=symple) {
list<Symple> list_symple = Follow(d.left);
list_symple.remove(Symple("$", T_SYMPLE));
follow_unin.splice(follow_unin.begin(), list_symple);
}
else if (i + 1 < vec.size() && vec[i + 1].ID == T_SYMPLE) {
follow_unin.push_back(vec[i+1]);
}
else if (i + 1 < vec.size() && vec[i + 1].ID == N_SYMPLE) {
list<Symple> temp = First(vec[i + 1]);
auto it = find(temp.begin(),temp.end(),Symple("$",T_SYMPLE));
if (it==temp.end()) {
follow_unin.splice(follow_unin.begin(), temp);
}
else{
temp.remove(Symple("$", T_SYMPLE));
follow_unin.splice(follow_unin.begin(), temp);
list<Symple> list_symple = Follow(d.left);
follow_unin.splice(follow_unin.begin(), list_symple);
}
}
}
}
}
}
if (symple_.name==START_SYMPLE) {
follow_unin.push_back(Symple("#",T_SYMPLE));
}
follow_unin.sort();
follow_unin.unique();
ALL_Follow[symple_] = follow_unin;
return follow_unin;
}
bool contain_NULLSymle(list<Symple> &fi) {
auto it = find(fi.begin(),fi.end(), Symple("$", T_SYMPLE));
return it != fi.end();
}
// 创建Select集合
map<Symple, vector<Symple>> select;
map<string, map<Symple, vector<Symple>>> predict_table;
// 创建预测分析表
void CreatePredictiveAnalysisTable(list<Symple> input, Symple nsym, vector<Symple> predict) {
for (Symple i : input) {
map < Symple, vector<Symple>> p2 = predict_table[i.name];
p2[nsym] = predict;
predict_table[i.name] = p2;
}
}
void createSelect() {
auto it = der.begin();
auto it_e = der.end();
for (;it != it_e;it++) {
derivation d= (*it).second;
vector<vector<Symple>> s = d.right;
list<Symple> sub_select;
for (vector<Symple> symples:s) {
for (Symple s_:symples) {
if (contain_NULLSymle(sub_select)) {
sub_select.remove(Symple("$", T_SYMPLE));
}
list<Symple> fi = First(s_);
sub_select.splice(sub_select.begin(), fi);
if (!contain_NULLSymle(fi)) {
break;
}
}
if (contain_NULLSymle(sub_select)) {
list<Symple> fi = Follow(d.left);
sub_select.splice(sub_select.begin(), fi);
sub_select.remove(Symple("$", T_SYMPLE));
}
CreatePredictiveAnalysisTable(sub_select,d.left,symples);
sub_select.clear();
}
}
}
语法分析程序
复制的地方主要就在于自动分析文法。有了预测分析表之后可以非常轻松的实现PDA
#include <stack>
namespace Syntax{
class PDA {
stack<Symple> H;
deque<Token> input;
public:
PDA() {
H.push(Symple("#", T_SYMPLE));
H.push(Symple("开始", N_SYMPLE));
}
public:
void parser(vector<Token*> line) {
try
{
for (Token* t : line) {
input.push_back(*t);
}
while (input.size()>0)
{
Symple s = H.top();
if (s.ID == N_SYMPLE) {
s1(s);
}
else {
s2(s);
}
}
}
catch (const const char *s)
{
throw s;
}
cout << "语法正确" << endl;
}
private:
// 处理终结符号
void s1(Symple s) {
Token t= input.front();
string token =t.token;
if (token == "#") {
input.pop_front();
return;
}
if (predict_table.count(token)==0) {
cout << token << ",";
throw "输入未知符号";
}
else {
map<Symple,vector<Symple>> mvs= predict_table[token];
if (mvs.count(s)==0) {
cout << token << "不应该被输入" <<",应该输入"<<s.name <<endl;
throw "语法错误!";
}
H.pop();
vector<Symple> vs = mvs[s];
for (int i = vs.size() - 1;i >=0;i--) {
if (vs[i].name!="$") {
H.push(vs[i]);
}
}
}
}
// 处理非终结符号
void s2(Symple s) {
Token t = input.front();
string token = t.token;
if (token == "#") {
input.pop_front();
return;
}
if (s.name == token) {
input.pop_front();
H.pop();
}
else {
cout << "应该输入:" << s.name << ",但是您确输入" << token << endl;
throw "语法错误!";
}
}
};
}
文法定义
文法定义实在太烦了,只写了下面部分文法,以后有时间了再完善。
<开始>:<函数定义>
<函数定义>:<类型><变量>(<参数声明>) {<函数块>}
<参数声明>:<声明>|$
<赋初值>:=<右值>|$
<右值>:<表达式>
<表达式>:<因子><项>
<数字闭包>:<数字><数字闭包>|$
<因子>:<因式><因式递归>
<因式递归>:*<因式><因式递归>|/<因式><因式递归>|$
<因式>:(<表达式>)|<变量>|<数字>
<数字>:1|2|3|4|5|6|7|8|9|0
<项>:+<因子><项>|-<因子><项>|$
<声明>:<类型><变量>
<类型>:int|void|double|long|short|
<取地址>:$
<变量>:<标志符>
<标志符>:regan|CNN|RNN|main|a|b|c
<函数块>:<声明语句闭包><函数块闭包>
<声明语句闭包>:<声明语句><声明语句闭包>|$
<声明语句>:<声明>;
<声明>:<类型><变量><赋初值>
<函数块闭包>:<赋值函数><函数块闭包> |<for循环><函数块闭包>|<条件语句><函数块闭包>|<函数返回><函数块闭包>|$
<函数返回>:return<因式>;
<for循环>:for (<赋值函数><逻辑表达式>;<后缀表达式>) {<函数块>}
<赋值函数>:<变量>=<右值>;
<逻辑表达式>:<表达式><逻辑运算符><表达式>
<逻辑运算符>:=|!=
<后缀表达式>:<变量><后缀运算符>
<后缀运算符>:+|-
程序输入与输出
int main(){
int a=1 + 2 + (3 + 1);
for(regan=0;regan=8;regan+){
int c=8;
}
return a;
}
非终结符:开始
非终结符:函数定义
非终结符:函数定义
非终结符:类型
非终结符:变量
终结符:(
非终结符:参数声明
终结符:)
终结符:{
非终结符:函数块
终结符:}
非终结符:参数声明
非终结符:声明
终结符:$
非终结符:赋初值
终结符:=
非终结符:右值
终结符:$
非终结符:右值
非终结符:表达式
非终结符:表达式
非终结符:因子
非终结符:项
非终结符:数字闭包
非终结符:数字
非终结符:数字闭包
终结符:$
非终结符:因子
非终结符:因式
非终结符:因式递归
非终结符:因式递归
终结符:*
非终结符:因式
非终结符:因式递归
终结符:/
非终结符:因式
非终结符:因式递归
终结符:$
非终结符:因式
终结符:(
非终结符:表达式
终结符:)
非终结符:变量
非终结符:数字
非终结符:数字
终结符:1
终结符:2
终结符:3
终结符:4
终结符:5
终结符:6
终结符:7
终结符:8
终结符:9
终结符:0
非终结符:项
终结符:+
非终结符:因子
非终结符:项
终结符:-
非终结符:因子
非终结符:项
终结符:$
非终结符:声明
非终结符:类型
非终结符:变量
非终结符:类型
终结符:int
终结符:void
终结符:double
终结符:long
终结符:short
非终结符:取地址
终结符:$
非终结符:变量
非终结符:标志符
非终结符:标志符
终结符:regan
终结符:CNN
终结符:RNN
终结符:main
终结符:a
终结符:b
终结符:c
非终结符:函数块
非终结符:声明语句闭包
非终结符:函数块闭包
非终结符:声明语句闭包
非终结符:声明语句
非终结符:声明语句闭包
终结符:$
非终结符:声明语句
非终结符:声明
终结符:;
非终结符:声明
非终结符:类型
非终结符:变量
非终结符:赋初值
非终结符:函数块闭包
非终结符:赋值函数
非终结符:函数块闭包
终结符:
非终结符:for循环
非终结符:函数块闭包
非终结符:条件语句
非终结符:函数块闭包
非终结符:函数返回
非终结符:函数块闭包
终结符:$
非终结符:函数返回
终结符:return
非终结符:因式
终结符:;
非终结符:for循环
终结符:for
终结符:(
非终结符:赋值函数
非终结符:逻辑表达式
终结符:;
非终结符:后缀表达式
终结符:)
终结符:{
非终结符:函数块
终结符:}
非终结符:赋值函数
非终结符:变量
终结符:=
非终结符:右值
终结符:;
非终结符:逻辑表达式
非终结符:表达式
非终结符:逻辑运算符
非终结符:表达式
非终结符:逻辑运算符
终结符:=
终结符:!=
非终结符:后缀表达式
非终结符:变量
非终结符:后缀运算符
非终结符:后缀运算符
终结符:+
终结符:-
一共有非终结符:29
输入: 替换:函数块闭包->$
输入:!=替换:逻辑运算符->!= 项->$ 因式递归->$
输入:(替换:表达式->因子 项 逻辑表达式->表达式 逻辑运算符 表达式 因式->( 表达式 )
右值->表达式
输入:)替换:参数声明->$ 赋初值->$ 项->$ 因式递归->$
输入:*替换:因式递归->* 因式 因式递归
输入:+替换:后缀运算符->+ 项->+ 因子 项 因式递归->$
输入:-替换:后缀运算符->- 项->- 因子 项 因式递归->$
输入:/替换:因式递归->/ 因式 因式递归
输入:0替换:表达式->因子 项 逻辑表达式->表达式 逻辑运算符 表达式 数字->0 数字
->数字 因子->因式 因式递归 右值->表达式
输入:1替换:表达式->因子 项 逻辑表达式->表达式 逻辑运算符 表达式 数字->1 数字
->数字 因子->因式 因式递归 右值->表达式
输入:2替换:表达式->因子 项 逻辑表达式->表达式 逻辑运算符 表达式 数字->2 数字
->数字 因子->因式 因式递归 右值->表达式
输入:3替换:表达式->因子 项 逻辑表达式->表达式 逻辑运算符 表达式 数字->3 数字
->数字 因子->因式 因式递归 右值->表达式
输入:4替换:表达式->因子 项 逻辑表达式->表达式 逻辑运算符 表达式 数字->4 数字
->数字 因子->因式 因式递归 右值->表达式
输入:5替换:表达式->因子 项 逻辑表达式->表达式 逻辑运算符 表达式 数字->5 数字
->数字 因子->因式 因式递归 右值->表达式
输入:6替换:表达式->因子 项 逻辑表达式->表达式 逻辑运算符 表达式 数字->6 数字
->数字 因子->因式 因式递归 右值->表达式
输入:7替换:表达式->因子 项 逻辑表达式->表达式 逻辑运算符 表达式 数字->7 数字
->数字 因子->因式 因式递归 右值->表达式
输入:8替换:表达式->因子 项 逻辑表达式->表达式 逻辑运算符 表达式 数字->8 数字
->数字 因子->因式 因式递归 右值->表达式
输入:9替换:表达式->因子 项 逻辑表达式->表达式 逻辑运算符 表达式 数字->9 数字
->数字 因子->因式 因式递归 右值->表达式
输入:;替换:赋初值->$ 项->$ 因式递归->$
输入:=替换:赋初值->= 右值 逻辑运算符->= 项->$ 因式递归->$
输入:CNN替换:变量->标志符 标志符->CNN 表达式->因子 项 赋值函数->变量 = 右值
函数块闭包 后缀表达式->变量 后缀运算符 逻辑表达式->表达式 逻辑运算符 表达式
变量 因子->因式 因式递归 右值->表达式
输入:RNN替换:变量->标志符 标志符->RNN 表达式->因子 项 赋值函数->变量 = 右值
函数块闭包 后缀表达式->变量 后缀运算符 逻辑表达式->表达式 逻辑运算符 表达式
变量 因子->因式 因式递归 右值->表达式
输入:a替换:变量->标志符 标志符->a 表达式->因子 项 赋值函数->变量 = 右值 ;
块闭包 后缀表达式->变量 后缀运算符 逻辑表达式->表达式 逻辑运算符 表达式 声
因子->因式 因式递归 右值->表达式
输入:b替换:变量->标志符 标志符->b 表达式->因子 项 赋值函数->变量 = 右值 ;
块闭包 后缀表达式->变量 后缀运算符 逻辑表达式->表达式 逻辑运算符 表达式 声
因子->因式 因式递归 右值->表达式
输入:c替换:变量->标志符 标志符->c 表达式->因子 项 赋值函数->变量 = 右值 ;
块闭包 后缀表达式->变量 后缀运算符 逻辑表达式->表达式 逻辑运算符 表达式 声
因子->因式 因式递归 右值->表达式
输入:double替换:参数声明->声明 函数定义->类型 变量 ( 参数声明 ) { 函数块 } 函数块
开始->函数定义 类型->double 声明->类型 变量 赋初值 声明语句->声明 ;
句闭包
输入:for替换:for循环->for ( 赋值函数 逻辑表达式 ; 后缀表达式 ) { 函数块 } 函数块闭包-
语句闭包->$
输入:int替换:参数声明->声明 函数定义->类型 变量 ( 参数声明 ) { 函数块 } 函数块->
开始->函数定义 类型->int 声明->类型 变量 赋初值 声明语句->声明 ; 声明语
输入:long替换:参数声明->声明 函数定义->类型 变量 ( 参数声明 ) { 函数块 } 函数块-
开始->函数定义 类型->long 声明->类型 变量 赋初值 声明语句->声明 ; 声明
包
输入:main替换:变量->标志符 标志符->main 表达式->因子 项 赋值函数->变量 = 右
函数块闭包 后缀表达式->变量 后缀运算符 逻辑表达式->表达式 逻辑运算符 表达式
>变量 因子->因式 因式递归 右值->表达式
输入:regan替换:变量->标志符 标志符->regan 表达式->因子 项 赋值函数->变量 =
数 函数块闭包 后缀表达式->变量 后缀运算符 逻辑表达式->表达式 逻辑运算符 表达式
式->变量 因子->因式 因式递归 右值->表达式
输入:return替换:函数返回->return 因式 ; 函数块闭包->函数返回 函数块闭包 声明语句
输入:short替换:参数声明->声明 函数定义->类型 变量 ( 参数声明 ) { 函数块 } 函数块
开始->函数定义 类型->short 声明->类型 变量 赋初值 声明语句->声明 ; 声
闭包
输入:void替换:参数声明->声明 函数定义->类型 变量 ( 参数声明 ) { 函数块 } 函数块-
开始->函数定义 类型->void 声明->类型 变量 赋初值 声明语句->声明 ; 声明
包
输入:}替换:函数块->声明语句闭包 函数块闭包 函数块闭包->$ 声明语句闭包->$
Line1:类型->int
Line1:标识符->main
Line1:操作符->(
Line1:操作符->)
Line1:分隔符->{
语法正确
------------------
Line2:类型->int
Line2:标识符->a
Line2:操作符->=
Line2:常量->1
Line2:操作符->+
Line2:常量->2
Line2:操作符->+
Line2:操作符->(
Line2:常量->3
Line2:操作符->+
Line2:常量->1
Line2:操作符->)
Line2:分隔符->;
语法正确
------------------
Line3:关键字->for
Line3:操作符->(
Line3:标识符->regan
Line3:操作符->=
Line3:常量->0
Line3:分隔符->;
Line3:标识符->regan
Line3:操作符->=
Line3:常量->8
Line3:分隔符->;
Line3:标识符->regan
Line3:操作符->+
Line3:操作符->)
Line3:分隔符->{
语法正确
------------------
Line4:类型->int
Line4:标识符->c
Line4:操作符->=
Line4:常量->8
Line4:分隔符->;
语法正确
------------------
Line5:分隔符->}
语法正确
------------------
Line6:关键字->return
Line6:标识符->a
Line6:分隔符->;
语法正确
------------------
Line7:分隔符->}
语法正确
------------------
F:\All_C++_Pro\语法_词法分析结合\Debug\语法_词法分析结合.exe (进程 8828)已退出,代码为 0。
按任意键关闭此窗口. . .
















 5322
5322











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











