







1、浅拷贝
浅拷贝就是两个指针指向相同的数据,数据是共享的。在我们之前实现的拷贝构造函数和复制运算符的重载函数系统默认提供的都是浅拷贝。如下图所示:
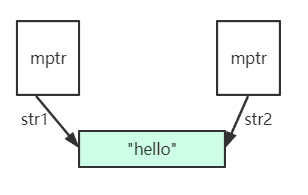
这种拷贝的缺陷就是其中一个对象修改数据,全部数据都修改了
2、深拷贝
深拷贝是指的构造str2的时候拷贝一块儿和跟str1指向数据块一样大的数据块,并将值拷贝下来,这样str1和str2指向各自的数据块.如下图所示:
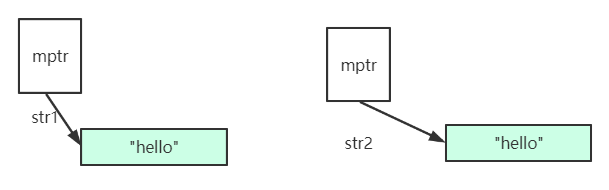
但是他的缺陷就是浪费空间
3、写时拷贝
3.1设计思想
写时拷贝是基于浅拷贝和深拷贝的缺陷,实现的一种更加高效的拷贝方式。他主要是:
- 写之前实现浅拷贝多个对象共享同一个内存提高空间利用率
- 写的过程中实现深拷贝为了避免修改的对象影响其他对象,针对要修改的对象单独开辟内存实现一个深拷贝
在整个过程中需要解决以下几个问题。
【问题一】在写之前实现的浅拷贝,允许多个对象指向该堆内存,但是在整个过程都没有写入的过程,针对于这这个堆内存应该如何释放呢?
我们应该在最后一个对象销毁的时候才释放该堆内存。
【问题二】怎么判断是最后一个对象进行销毁?
我们需要一个计数器,记录该堆内存有多少个对象指向。这种机制叫做引用计数
【问题三】怎么判断是最后一个对象进行销毁?
方式一:计数器做成员变量——不合适
因为在对象析构的时候只改变了本对象的引用计数,其他对象的引用计数没有被改变。

方式二:计数器做静态的成员变量——不合适
虽然静态成员变量针对于所有对象是共享的,但是
【举个栗子】下面这个代码中,str4就是重新来开辟的内存,而不是进行数据共享的。这时就把静态成员变量的count值置为了1,把之前的数据覆盖掉了
String str1("hello");
String str2(str1);
String str3(str3);
String str4("world");

方式三:把计数器放在堆内存里面——合适
这样才能保证一个堆内存对应有一个计数器能计数该内存有多少个对象指向。我们将引用计数的大小是固定的4字节放在数据域的前面,在operator[]里面实现深拷贝。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3022
3022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









