







文件概念
文件是存储在外部存储器中的一组信息集合。
按照文件的数据组织形式,文件分为文本文件和二进制文件两种。
文本文件将数据视为字符,在文件中保存每个字符的编码(ASCII, GBK, UTF-8等)。
常见文本文件: 记事本文件(.txt), 源代码,网页,日志等。
对于字符和编码之间转换的操作函数:
ord() 返回字符对应的编码
chr() 返回编码对应的字符
二进制文件把数据的二进制值存储到文件中。
例如,有一个整数20190306,因为一个整数占4字节,
所以把它保存在外部存储器中也要占4字节。
将这个整数以二进制形式保存到文件中的结果
In: bin(20190306)
Out: '0b1001101000001010001100010'
二进制文件:Word/Excel/图片/音乐等文件。
文本文件和二进制文件存储是不同的。
例如将 12 视为文本字符’12’,存储时需要2个字节,00110001 00110010 。
如视为整数(需4个字节), 00000000 00000000 00000000 00001100。
文件操作
操作文件前一定要先打开文件。内置函数open()可打开文件,格式为 f = open(文件名, 文件模式, 编码方式)
打开文件后,借助文件变量 f 来操作文件。
中间得文件模式的参数

打开文件时需指定是文本文件还是二进制文件(“t"或"b”),默认为"t"。例如:
fw = open(r"d:\test.txt", “wt”) # w写, t文本
该语句的作用是以“w”只写方式打开d盘根目录下的文本文件"test.txt"。
注:此处的r表示原始字符串,这样\t就不会被视为转义字符。如果没有r, d:\test.txt 由于转义不会被理解为正确的文件名,将报错。此处也可写为open(“d:\test.txt”, “w”)
fr = open(r"d:\file1.txt", “r”) # 只读 , “r” 可省略
该语句的作用是以“r”只读方式打开d盘根目录下的文本文件"file1.txt",‘r’ 时要求文件必须事先存在。
fbw = open(r"d:\file2.dat", “wb”) # b 较少用
该语句以“只写”方式打开d盘的二进制文件"file2.dat"。
fr = open(r"d:\test.txt", "r", encoding="utf-8")
该语句以“只读”方式打开d盘下文本文件"test.txt",指定编码方式为"utf-8"。
注:Python默认按操作系统平台的编码处理文件。
Windows系统默认编码为GBK,而test.txt文件是用utf-8编码保存的,
因此打开该文件时需指定这种编码方式。如果不指定,或指定为其他编码方式,
打开文件后读取时将报错。对英文而言, utf-8和ascii是一样的。记事本存盘时可选择保存编码。
Python源文件默认按utf-8编码保存,如果内含中文注释,当用open打开时就应指定encoding='utf-8'。
GBK和utf-8的编码方式是完全不一样的,所以不同编码方式打开会出错
In: '中文'.encode('GBK')
Out: b'\xd6\xd0\xce\xc4' # GBK,1个汉字的编码需2字节
In: '中文'.encode('utf-8')
Out: b'\xe4\xb8\xad\xe6\x96\x87' # utf-8,1个汉字的编码需3字节
文件对象的属性
函数open()返回一个可迭代的文件对象,通过该对象对文件进行操作。文件对象常用属性如下。

文件对象的方法
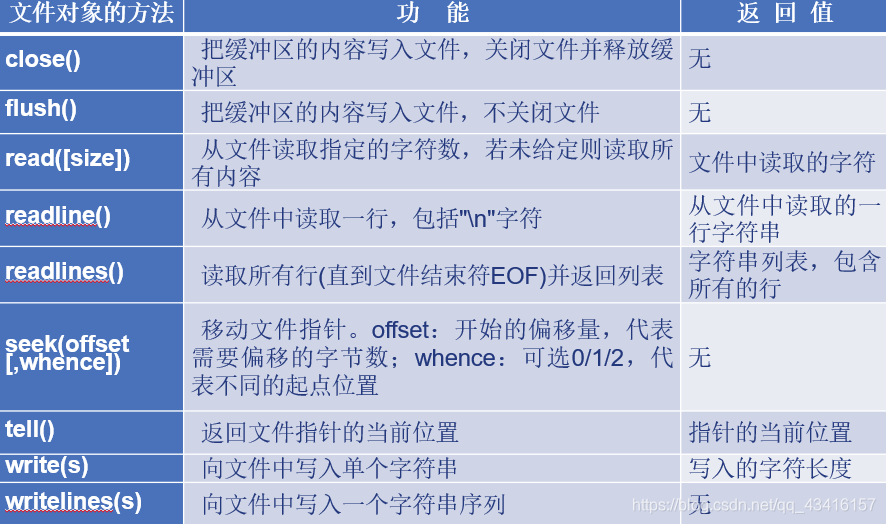
关闭文件
完成文件操作后,一定要关闭文件才能保存修改并释放文件。在fw.write(“123”)此时数据只是在缓存区,还没有存入文件的
关键字with可以自动管理资源,在退出with时会自动关闭文件(省略f.close()语句)。with一般语法如下:
with open(文件名, 文件模式) as fp:
s = fp.read() # with语句结束时,会自动关闭文件
当前文件夹下有一个文件log.txt,其内容如下:
第一行
第二行
编写程序读取其中的前6个字符。程序如下:
with open("./log.txt", "r") as f:
a = f.read(6) # 读6个字符,不指定则读取全部
print(a, end= '')
输出如下:
第一行
第二
注意:
数据文件如不指定保存位置,则默认和程序存放在同一目录中。
第一行后的换行符"\n"也算一个字符,所以 '第一行\n' 有4个字符。
/ 和 \ 都可以作为路径分隔符。r'd:\tmp\f1.txt' 或 'd:/tmp/f1.txt' 都行。
#遍历文件的行
with open("./log.txt", "r") as f:
a = f.readlines() # 读取所有的行,得到字符串列表 a
for line in a:
print(line)
输出结果如下:
第一行 # print()本身要换行,字符串内也含有'\n', 所以输出时有空行
第二行
因为函数open()返回的文件对象是一个可迭代对象,所以用函数readlines()读取文件的语句可以省略。该段程序可简写为:
with open("./log.txt", "r") as f:
for line in f:
print(line)
语法糖格式 s = open("target.py",encoding='utf-8').read()
数值必须转为字符串才能写到文本文件中。
例如:
随机生成一个长度为100的整数列表,其元素范围为1~100,将该列表以每10个一行(元素之间以空格分隔)写入文本文件。(“d:\record.txt”)中。
from random import randint
a = [ ]
for i in range(100):
a.append(randint(1,100))
with open("d:\\record.txt", "w") as f:
str = ""
for i, v in enumerate(a):
str = str + "{} ".format(v) # 数值转字符串,连接起来
if (i + 1) % 10 == 0: # 每满10个写入一行
b = f.write(str + "\n") # 写入时自行添加换行符 '\n'
str = "" # 空字符串
写完后想读出来
b = [ ]
with open("d:\\record.txt") as f: # 文件应存在
for line in f.readlines():
line = line.strip() # strip删除字符串两侧的空格符/换行符等
data = line.split() # split分解得到字符串列表 ['10', '23', ..... '89']
for v in data:
b.append(eval(v)) # 转为整数,添加到列表
print(b)
读写二进制文件
把内存中的数据对象写入二进制文件称为序列化,从二进制文件读出并重建原数据对象称为反序列化。这些操作可借助pickle模块(自带)。模块中的dump()是写入函数,load()是读函数。写入语法:pickle.dump(写入对象, 文件对象)
写入对象:数值、字符串、列表、元组、字典等。
文件对象:函数open()打开的文件对象,将各类数据写入其中。
写:
import pickle
a = 1234 ; b = 3.14159 ; c = "程序" ; d = ['a', 'b', 'c'] ;
e = {"张":60, "王":70, "李":80}
with open("binary.dat", "wb") as f: # b不能省略
pickle.dump(a, f)
pickle.dump(b, f)
pickle.dump(c, f)
pickle.dump(d, f)
pickle.dump(e, f)
读:
import pickle
with open("binary.dat", "rb") as f:
a = pickle.load(f) # 按存入的顺序依次读出
b = pickle.load(f)
c = pickle.load(f)
d = pickle.load(f)
e = pickle.load(f)
print(a, b, c, d, e)
二进制文件的数据格式不统一,所以存入/读出一般应使用同样的库。
dump()和load()会自动处理不同数据之间的边界。这是简单的数据持久化方法。
文件定位
文件指针用于标示文件当前读/写位置。读写时,都从文件指针的当前位置开始,根据读写的数据量向后移动文件指针。文件对象的函数tell()返回文件指针的当前位置。文件刚打开时指向0位置。
文件"log.txt"中保存了字符串"python"。
with open("log.txt", "r") as f:
h = f.read(2)
print(h)
print("pos = {}".format(f.tell()))
j = f.read(2)
print(j)
print("pos = {}".format(f.tell()))
k = f.read(2)
print(k)
print("pos = {}".format(f.tell()))
结果是:
py
pos=2
th
pos=4
on
pos=6
注:指针指向文件末尾了,继续读入将返回空串,不报错。
文件对象的seek()方法可移动文件指针,
f.seek(偏移值 [,起点] ) 。
偏移值表示移动的距离;起点表示从哪里开始移动:
0(默认值)表示从文件头开始;
1表示从当前位置开始;
2表示从文件尾开始。
f.seek(10) # 移动到距离文件头部10个字符处
f.seek(4, 1) # 从当前位置再向后(尾部)移动4字节
f.seek(-3, 1) # 从当前位置再向前(头部)移动3字节
f.seek(-6, 2) # 移到距离文件尾部 6个字节处
注:文本文件仅支持起点0和正偏移值, 二进制文件支持起点0/1/2。
读/写docx文件和xlsx文件
Python和Word结合可完成一些文档自动生成的工作。包docx是读写word文件的第三方包。安装命令 pip install python-docx
建立新Word文档及添加段落
(1) doc = Document() 建立一个新文档对象doc。
(2) p = doc.add_paragraph(字符串) 创建一个段落对象p。
(3) run = p.add_run(字符串) 将产生一个Run对象,通过run对象设置排版格式。
(4) doc.save('文件.docx') 保存为word文件。
这里写个例子
from docx import Document
from docx.shared import Pt, RGBColor # 字号,颜色
from docx.oxml.ns import qn # 字体
doc = Document() #生成一个空的docx对象
#设置字体需要这两句
doc.styles['Normal'].font.name = '宋体' #全局默认字体
doc.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), '宋体')
doc.add_heading('标题1', level=1) #添加标题
p = doc.add_paragraph() #添加段落
run=p.add_run('红色宋体24磅')
run.font.size = Pt(24) #设置字号
run.font.color.rgb = RGBColor(255,0,0) #设置红色, RGB(红,绿,蓝)
run = p.add_run('绿色微软雅黑12磅')
run.font.name = '微软雅黑' # 局部字体
run._element.rPr.rFonts.set(qn('w:eastAsia'), '微软雅黑')
run.font.size = Pt(12) #设置字号
run.font.color.rgb = RGBColor(0,255,0) #设置绿色
run.bold = True; run.italic = True # 设置粗体和斜体
p2 = doc.add_paragraph('第2个段') #添加段落
doc.save('test.docx') #覆盖保存到test.docx
结果:

读取文档的所有段落
Document对象的paragraphs属性是一个包含文档所有Paragraph对象的列表对象,一个Paragraph对象代表文档的一个段落。对paragraphs属性进行循环遍历可以操作文档的所有段落。Paragraph对象的text属性代表该段落的文字
from docx import Document
doc = Document("test.docx") # 文件应存在
for p in doc.paragraphs:
print(p.text)
读取文档表格中的文字
Document对象的tables属性是一个包含文档所有Table对象的列表对象,一个Table对象代表文档的一个表格。
Table对象的_cells属性是一个包含表格所有单元格对象的列表。对表格的_cells属性进行循环遍历可以操作表格的所有单元格。
单元格对象的text属性代表该单元格的文字。
from docx import Document
doc = Document("Python.docx")
for t in doc.tables: # 只含所有表,不含非表格内的文字
for c in t._cells: # 单个表的所有单元格
print(c.text) # 单元格内的文字
编程实例:
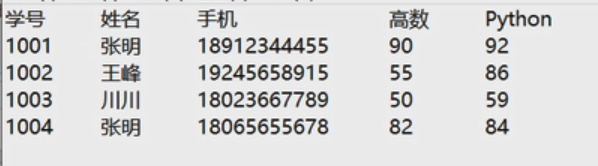
读取文件score.txt中的名单和成绩(格式如下),为每个学生生成一个成绩通知,通知都保存在 stu.docx文档中。
from docx import Document
from docx.shared import Pt,RGBColor
from docx.oxml.ns import qn
stu=[ ]
with open('score.txt') as f:
field = f.readline().split() # 第一行 列名
for line in f:
stu.append(line.split()) # 学生列表
doc = Document() #生成空文档docx对象
doc.styles['Normal'].font.name = '宋体' #全局默认字体
doc.styles['Normal']._element.rPr.rFonts.set(qn('w:eastAsia'), '宋体')
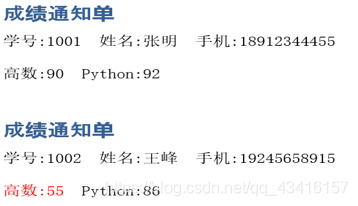
for lst in stu:
doc.add_heading('成绩通知单',level=1) # 添加标题
s=''
for i in range(3):
s = s +field[i]+':'+lst[i]+' ' # 学号 姓名 手机
doc.add_paragraph(s)
p = doc.add_paragraph() # 成绩段
for i in range(3,5):
run = p.add_run(field[i]+':'+lst[i]+' ') # 两门成绩
if float(lst[i])<60:
run.font.color.rgb = RGBColor(255,0,0) #不及格则红色
doc.add_paragraph() # 空行
doc.save('stu.docx') # 保存到stu.docx
结果这样
包openpyxl是读写xlsx文件的第三方包,安装命令为:
pip install openpyxl
步骤:
创建Excel工作簿和工作表
(1)wb =Workbook( ) # 新的工作簿
(2)wb.create_sheet("first") # 工作表
(3)wb.save('文件.xlsx') # 保存为Excel文件
那么工作簿就有两张表,默认的Sheet表和first表
修改单元格的数据
要修改表格数据,需要先调用load_workbook()函数获取工作簿。
有三种方法从工作簿中得到其中的一个工作表:
第一种是用Workbook对象的get_sheet_by_name方法(旧方法),其参数是工作表的名称;
第二种是用Workbook对象的worksheets属性,该属性是一个Worksheet 对象列表,如ws = wb.worksheets[1];
第三种是通过索引方式,下标为工作表的名字,如ws=wb[‘first’]。
例子:
from openpyxl import Workbook, load_workbook
wb = load_workbook("test.xlsx") # 文件存在且不能已被Excel打开,被Excel打开就被它锁定着,
#其他的程序不能访问,而这个方法打开Excel表不会锁着这个表,而是将它加载在内存里面,然后释放锁
ws = wb["first"] # first表应存在
# 各种访问单元格的语法
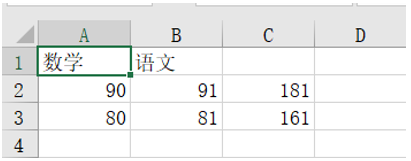
ws['A1'] = "数学" # 行列坐标
ws['b1'] = "语文"
ws.cell(2, 1, 90) # 第2行第1列
ws.cell(2, 2, 91) # 第2行第2列
ws.append([80, 81])
ws['c2'] = "=sum(A2:B2)"
ws['c3'] = "=sum(A3:B3)"
wb.save("test.xlsx") # 保存即更新文件
结果:
读取Excel单元格中的数据
获取一个Cell对象后,访问Cell对象的value属性即可读取数据。
os模块
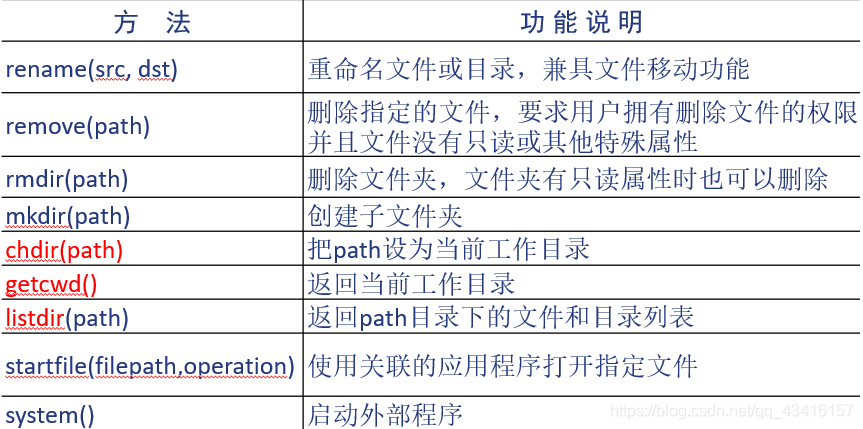
import os
os.rename("wt.txt", "tmh\\wtt.txt")
将当前文件夹下的文件"wt.txt"改名并移动到子文件夹"tmh"中。
os.remove("tmh\\wtt.txt" )
删除当前文件夹的子文件夹"tmh"中的文件"wtt.txt"。
os.rmdir("tmh") 删除当前目录下的子文件夹tmh(要求为空)
os.mkdir("d:\\tmh") 在d盘根目录下建一个文件夹tmh
os.chdir("d:\\tmh") 把d:\\tmh设置为当前工作目录
os.getcwd() 返回当前工作目录名
os.system('notepad.exe') 启动记事本程序
os.startfile('1.2.mp4') 启动相应的视频播放程序
import shutil
shutil.rmtree('tmh') 删除子文件夹tmh(不为空也可)
shutil.copyfile('log.txt', 'b.txt') 将log.txt复制得到b.txt
os.listdir(path)的功能是返回path目录下的文件和目录列表。对该列表进行递归遍历可以遍历文件夹path下的所有文件和子文件夹。
os.path模块
提供了关于路径判断、连接及切分的方法。
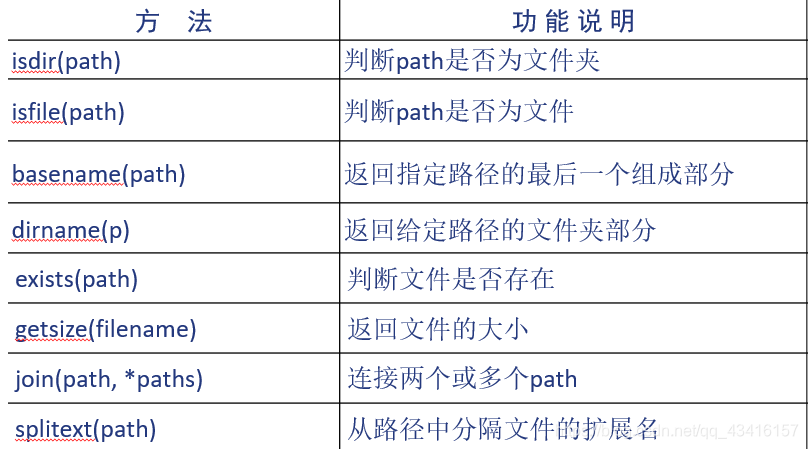
import os.path
os.path.dirname('D:\\Workspace\\tmh\\t7.txt')
返回该路径的文件夹部分'D:\\Workspace\\tmh'。
os.path.basename('D:\\Workspace\\tmh\\t7.txt')
返回路径的最后一个组成部分't7.txt'
os.path.basename('D:\\Workspace\\tmh')
返回该路径的最后一个组成部分'tmh'
os.path.join('D:\\Workspace', 'tmh')
将两个路径连接成一个路径,即'D:\\Workspace\\tmh'。
os.path.splitext('D:\\Workspace\\tmh\\t7.txt')
从路径中分割出文件的扩展名,它的返回值是一个包含两个元素的元组 ('D:\\Workspace \\tmh\\t7', '.txt')。
例子:D:\tmh文件夹中存放了一批文件,要求用数字序号对其中的.png, .jpg, .jpeg等图片文件重新命名,例如 1.png, 2.png, 3.jpg, 4.jpeg等,将新文件保存在 D:\pic 目录中。
import os, sys, os.path
oldpath = r'D:\tmh'
newpath = r'D:\pic'
if not (os.path.exists(oldpath) and os.path.exists(newpath)):
print('目录不存在')
sys.exit() # 退出程序
i = 0
for p in os.listdir(oldpath):
fpath = oldpath+'\\'+p # 完整路径
if os.path.isfile(fpath):
fname, ext = os.path.splitext(p) # 主文件名 扩展名
ext = ext.lower()
if ext in ('.png', '.jpg', '.jpeg'):
i += 1
newname = newpath+'\\'+str(i)+ext # 新的文件路径
os.rename(fpath, newname) # 重命名兼移动文件
print('共修改文件名 {} 个'.format(i))
现在再说一下collections模块中的Counter函数
这个函数就是统计一个列表里面每个元素出现的次数,
返回的结果是一个类似字典的数据,键是元素,值是元素出现的次数
返回的结果还可以调用most_common(x)这个函数,返回出现次数排名的前x位















 5015
5015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











